大家好,我是轩脉刃。
在专栏第 34 章,完成问答系统的开发后,我们使用 GoConvey、SQLite 写了一些单元测试,对问答系统进行测试验证。当时,我们主要聚焦于专栏中开发的系统,详细描述了如何开发单测,并且展示了单测的代码。但单元测试是一套完整的方法论,不是如此简单就能描述完备的。
因此在这里,我想和你系统地讨论 Golang 业务中的单元测试,包括它的重要性、设计思路,以及编写单测的方法技巧。
在正常开发过程中,我发现一个很有意思的现象,所有开发同学都会说单元测试有用,但鲜少见到有人在开发过程中编写单元测试。究其原因,大致会是如下几种:
- 我是来写功能的,不是来写测试的
- 我写的代码不会出错,用不着单元测试
- 后面的集成测试会帮我测试出问题的
- 写单元测试太浪费时间了
- 我不知道怎么写单元测试
这些问题,我希望能在今天给出完美的解答。
为单元测试“正名”
业务代码对单元测试的接纳,首先必须是思想上的接纳。即思想上必须要想清楚一件事:为什么要有单元测试。
单元测试是将 Bug 控制在编码阶段的唯一手段

上图出自 Capers Jones 在 1996 年出版的 《Applied Software Measurement》,它是一张经典图表,展示了软件开发生命周期中的缺陷发现和修复成本。这张图在软件工程领域非常有影响力,经常被用来说明“尽早测试、尽早发现问题”的重要性。那接下来,我们就一起来分析这张图上的重要信息。
从这张图上,我们可以总结出缺陷分布的规律:
- 编码阶段发现缺陷的比例最高(约85%)
- 后续阶段发现缺陷的比例逐渐降低
我们注意到,85% 的缺陷Bug 都是在编码阶段出现的。我从业这么多年,还从来没见过一位资深开发者从未写出过 Bug 的。这里的 Bug 不仅局限于语法错误这种简单问题,还包括业务逻辑错误、配置不合理等。对于那些声称“我写的代码不会出错,用不着单元测试”的开发同学,我只能说盲目自信带来的只能是“世界级”的灾难。
因此,在业务功能开发过程中,我们应当保持一种“悲观”的心态,按照代码行数百分比来预估你的缺陷数量。比如这次功能开发完成,我们使用了 1000 行代码。此时,我们可以按照每 200 行出现一个 Bug 的频率进行预估(这个数值应该根据自身的经验值调整)。你心里需要有个数,对于这个功能,至少有 5 个 Bug 需要自己和测试同学一起查出来。
此外,这张图还告诉我们:Bug 修复的成本随着时间推移越来越高。我们可以看到:
- 黑色曲线表示修复缺陷的成本($)。
- 曲线显示越晚发现缺陷,修复成本越高,从编码阶段的 $$25$ 上升到发布后的 $$16000$。
我们可以把一个业务看成一架飞机,如果没有完备的单元测试,就像在组装这架飞机时,各个组件没有经过严格的检验,只是单纯地将它组装完成,然后通过试飞来检验飞机是否正常运行。
平时,这架飞机看起来或许可以正常飞行。但恐怖的是,我们根本无法预知什么时候飞机会出问题,又会在什么时候发生解体。等到飞机进入生产环境,一旦发生解体,后果就是机毁人亡,由此带来的成本和代价无疑是极其巨大的。
所以我才说,单元测试是将Bug 控制在编码阶段的唯一手段!
单元测试是所有测试中最底层的一类测试,是第一个环节,也是最重要的一个环节,是唯一一次能够保证代码覆盖率达到100%的测试。作为开发人员,同时也是单元测试的主要执行者,在交付生产环境代码时,你就应该编写足够的单元测试,以便将 Bug 控制在编码阶段,避免后期在生产环境中出现无可挽回的事故。
测试金字塔
测试金字塔是由 Mike Cohn 在 2009 年出版的著作《Succeeding with Agile》一书中正式提出的,它描述的是不同测试之间的模式。
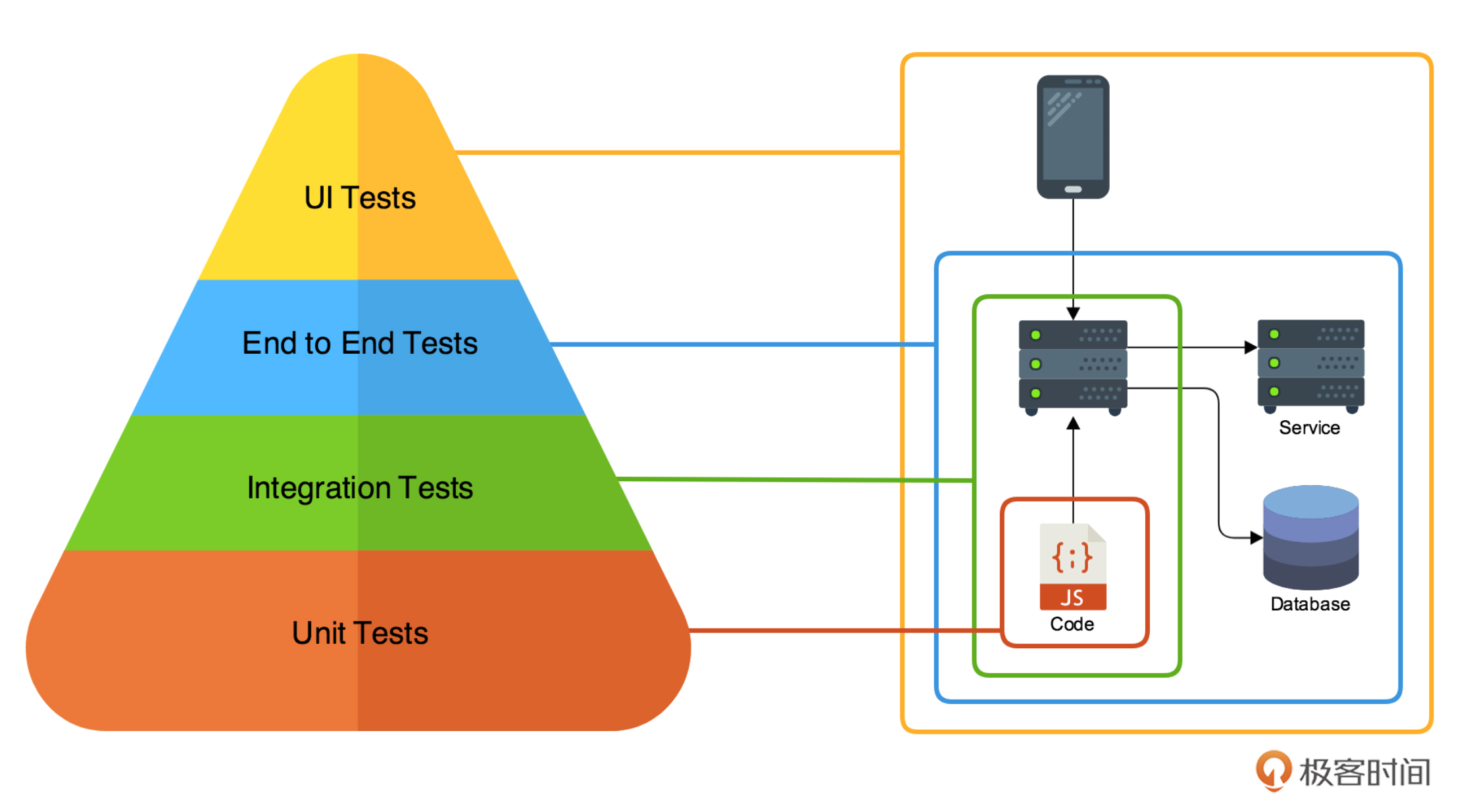
测试金字塔的最底层是单元测试,它是对代码进行测试。再上一层是集成测试,它是对一个服务的接口进行测试。再上一层是端到端的测试,我也称它为链路测试,它负责从一个链路的入口输入测试用例,将测试运行在链路上的多个服务中,以此来验证整个链路的运行结果。位于顶层的是我们最常用的 UI 测试,即测试同学在 UI 界面上根据功能进行点击,以此来完成测试。
那如果不编写单元测试,后面的集成测试能够帮我测试出问题吗?
从测试的角度来看,后面进行的集成测试、全链路测试、UI 测试都属于黑盒测试。对于测试同学来说,代码就是一个无法看到内部的黑盒。由于业务的逻辑代码繁多且分支错综复杂,测试同学是无法设计出完善的集成测试用例的,一定会存在覆盖不到的分支。而这些覆盖不到的分支产生的严重后果,不应该只有测试同学来承担,其实更多是开发同学没有完备的单元测试导致的。
而且这种思想也是一种懒惰的表现,并且逐渐和现在的大厂业务模式相背离。现在的大厂越来越推崇 DevOps 的开发模式,在这种模式下,开发同学会承担越来越多的角色,开发、测试、运维这些角色的职责都集中在开发同学身上。DevOps 推崇开发同学对自己的代码负责,同时对代码运行在生产环境中的运维情况负责。记住,自己的代码质量,永远不要依赖他人,包括测试同学。
单元测试的时间计算
不写单元测试还有一个理由,那就是写单元测试太浪费时间了。
这其实存在一个很大的误区,我们一方面需要承认单测会增加开发量,但是另外一个方面,开发时间并不是你接到需求,编写完第一遍代码并提交测试后就结束了。其实真正的开发时间应该包括提交测试后,测试同学提交 Bug 的定位时间,测试 Bug 的修复时间,甚至包括上线后发现 Bug,为了修复 Bug 或者脏数据所需要的数据修复时间、Bug 修改时间、兼容逻辑开发时间等。从整个迭代周期的角度来看,这些都算“开发时间”。那在这个过程中,单元测试到底是提高还是降低了“软件开发时间”呢?
《单元测试的艺术》这本书中给出过答案,他们找了开发能力相近的两个团队,同时开发相近的需求。一个进行单元测试,另一个不进行单元测试,最后比较两个团队各个阶段的耗时。下表是详细的数据:
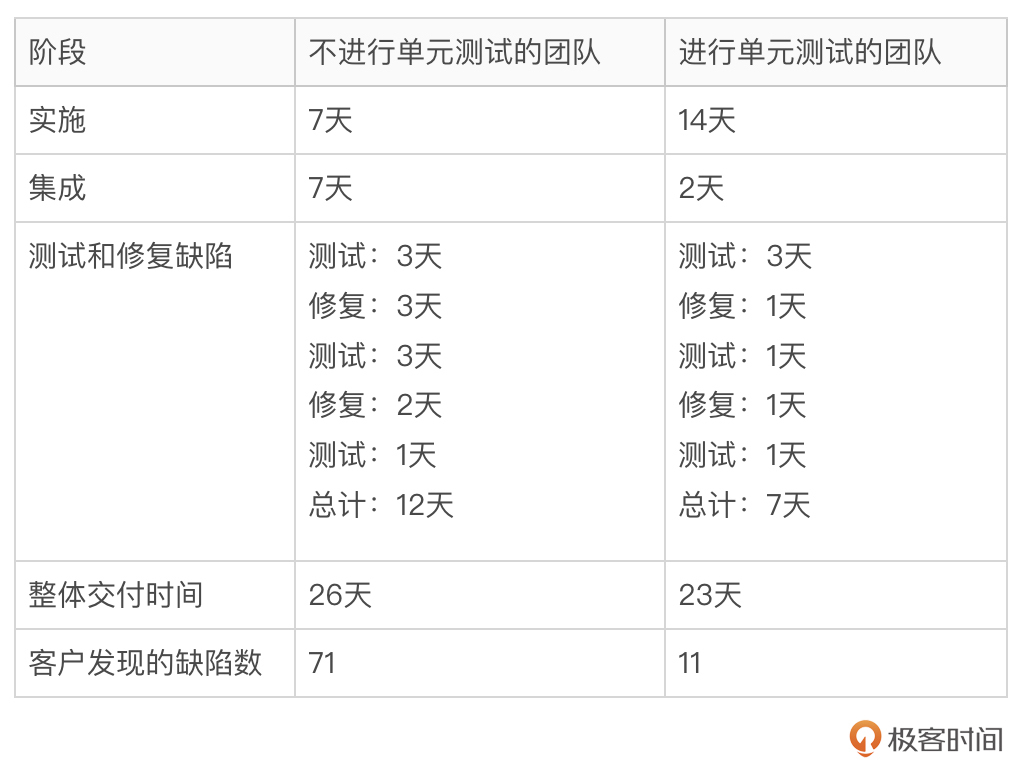
我们看到,进行单测的团队,虽然在编码阶段所需时长增加了一倍,达到了 14 天,但这个团队在集成测试阶段的表现非常顺畅,不仅 Bug 量较少,定位 Bug 也很迅速。从最终的效果来看,进行单测的团队的整体交付时间最短,并且缺陷数也是最少的。
所以,如果你真的对最终软件交付时间负责,请不要以“没有时间开发单元测试”为理由了。
如何写可测试的代码
刚才我们讲的都是单元测试的“道”,各种数据都在告诉我们单元测试的必要性。下面,我们再来讨论单元测试的“术”,即怎么编写单元测试。
我们要明白,并不是所有的代码都叫做“可测试的代码”。编写可测试的代码是软件开发的一个重要前提,对任何语言都是如此。所以接下来,我就给出一系列编写可测试代码的最佳实践。
避免全局状态
尽量避免使用全局变量,因为它们会使测试变得复杂。如果必须使用全局状态,可以考虑使用其他方式来控制全局状态。
比如下面这段代码:
这段代码中的 Foo 函数依赖了全局变量 Global,这个函数的可测试性很低,因为 Foo 函数的返回值依赖一个全局变量 GlobalPrice,而我们不知道这个全局变量在 Foo 函数调用之前是否被其他函数修改过。
相对比较好的代码是:
函数要有稳定的输入和输出
函数应该接收参数并返回结果,并且这种输出是稳定的,不是有随机性的。
比如下面的代码:
这段代码返回的结构和当前运行的时间有关,即使每次输入一样,返回值也是不一样的,有一定随机性,所以这样的函数是无法测试的。
依赖注入
使用依赖注入将外部依赖(如数据库连接、HTTP 客户端等)传递给函数或结构体,而不是在函数内部创建这些依赖。这使得我们在测试阶段可以传入模拟(Mock)对象。
我们在定义一个结构体的时候,尽量将它的外部依赖项,比如它依赖什么存储、什么缓存,作为结构体的元素。下面的结构体就比较合适:
// 缓存服务
type CacheService struct {
redisClient *redis.Client
}
// 初始化
func NewCacheService(redisClient *redis.Client) *CacheService {
return &CacheService{
redisClient: redisClient
}
}
// 从缓存中获取个数
func (s *CacheService) GetCount(ctx context.Context) (uint64, err) {
return this->redisClient->Get("foo:count")
}
在测试这个 GetCount 方法时,我们可以 mock 一个 redisClient,然后使用 NewCacheService 的方法初始化一个 CacheService 进行测试。
你可以比较下面这个函数:
// 缓存服务
type CacheService struct {
}
// 初始化
func NewCacheService() *CacheService {
return &CacheService{ }
}
// 从缓存中获取个数
func (s *CacheService) GetCount(ctx context.Context) (uint64, err) {
redisClient := client.NewConnect("username", "password")
redisClient->connect()
return redisClient->Get("foo:count")
}
这个代码中的 GetCount 函数,在函数内部直接初始化了一个 Redis 的连接,所以,当我们在用这个函数写测试用例时,如果想用 mock redis 来执行这个函数是无能为力的。这就是一种不好的函数实现方式。
写出可以“依赖注入”的代码对于单元测试非常重要。
你可以回想一下,我们专栏中实现的 Hade 框架是不是一直在强调“依赖注入”。在专栏第 10 章和第 11 章中,我们定义了一个服务容器 container,所有服务模块都作为服务提供者,在服务容器中注册自己的服务凭证和服务接口,在具体使用的时候,通过服务凭证来获取具体的服务实例。
Hade 框架中的服务容器就是一个提供单元测试注入 Mock 服务的绝佳设计。不仅如此,我们在使用这个框架开发时,就已经习惯从容器中获取一切服务了。这就意味着,所有服务都是可以“依赖注入”的。
小函数和单一职责
将代码拆分成小函数,每个函数只做一件事。这样可以更容易地编写单元测试,并且测试覆盖率更高。
这个原则其实不只是为了代码可测性,对于代码可读性等都有增益。我演示一个很差的代码函数你就能理解了。
// bad_example.go
func ProcessOrder(userID int64, items []OrderItem, couponCode string, addressID int64) error {
// 一个大函数包含了所有逻辑
db, err := sql.Open("mysql", "user:password@/dbname")
if err != nil {
return fmt.Errorf("数据库连接失败: %w", err)
}
defer db.Close()
// 查询用户信息
var user User
err = db.QueryRow("SELECT id, email, balance FROM users WHERE id = ?", userID).
Scan(&user.ID, &user.Email, &user.Balance)
if err != nil {
return fmt.Errorf("查询用户失败: %w", err)
}
// 计算商品总价
var total float64
for _, item := range items {
var price float64
var stock int
err = db.QueryRow("SELECT price, stock FROM products WHERE id = ?", item.ProductID).
Scan(&price, &stock)
if err != nil {
return fmt.Errorf("查询商品失败: %w", err)
}
if stock < item.Quantity {
return fmt.Errorf("商品 %d 库存不足", item.ProductID)
}
total += price * float64(item.Quantity)
}
// 优惠券处理
if couponCode != "" {
var discount float64
var minAmount float64
var used bool
err = db.QueryRow(`
SELECT discount, min_amount, used
FROM coupons
WHERE code = ? AND user_id = ? AND expire_time > NOW()`,
couponCode, userID).
Scan(&discount, &minAmount, &used)
if err != nil {
return fmt.Errorf("查询优惠券失败: %w", err)
}
if used {
return errors.New("优惠券已使用")
}
if total < minAmount {
return fmt.Errorf("订单金额未达到优惠券使用门槛 %.2f", minAmount)
}
total = total * (1 - discount)
}
// 检查用户余额
if user.Balance < total {
return errors.New("用户余额不足")
}
// 查询收货地址
var address Address
err = db.QueryRow("SELECT province, city, detail FROM addresses WHERE id = ? AND user_id = ?",
addressID, userID).
Scan(&address.Province, &address.City, &address.Detail)
if err != nil {
return fmt.Errorf("查询地址失败: %w", err)
}
// 开启事务
tx, err := db.Begin()
if err != nil {
return fmt.Errorf("开启事务失败: %w", err)
}
defer tx.Rollback()
// 扣减库存
for _, item := range items {
_, err = tx.Exec("UPDATE products SET stock = stock - ? WHERE id = ?",
item.Quantity, item.ProductID)
if err != nil {
return fmt.Errorf("更新库存失败: %w", err)
}
}
// 扣减余额
_, err = tx.Exec("UPDATE users SET balance = balance - ? WHERE id = ?",
total, userID)
if err != nil {
return fmt.Errorf("扣减余额失败: %w", err)
}
// 标记优惠券已使用
if couponCode != "" {
_, err = tx.Exec("UPDATE coupons SET used = true WHERE code = ?",
couponCode)
if err != nil {
return fmt.Errorf("更新优惠券状态失败: %w", err)
}
}
// 创建订单
orderResult, err := tx.Exec(`
INSERT INTO orders (user_id, total_amount, address_id, status, created_at)
VALUES (?, ?, ?, 'pending', NOW())`,
userID, total, addressID)
if err != nil {
return fmt.Errorf("创建订单失败: %w", err)
}
orderID, _ := orderResult.LastInsertId()
// 创建订单详情
for _, item := range items {
_, err = tx.Exec(`
INSERT INTO order_items (order_id, product_id, quantity, price)
VALUES (?, ?, ?, ?)`,
orderID, item.ProductID, item.Quantity, item.Price)
if err != nil {
return fmt.Errorf("创建订单详情失败: %w", err)
}
}
// 提交事务
if err = tx.Commit(); err != nil {
return fmt.Errorf("提交事务失败: %w", err)
}
// 发送订单确认邮件
smtp.SendMail("smtp.example.com:587", nil,
"shop@example.com", []string{user.Email},
[]byte(fmt.Sprintf("您的订单 %d 已创建,总金额: %.2f", orderID, total)))
// 发送通知给库存系统
kafka.Send("stock_update", map[string]interface{}{
"order_id": orderID,
"items": items,
})
return nil
}
这个函数有 150 行左右,其中包括了订单的所有流程,同时涉及多个 SQL 请求和一个大事务。
遇到这种函数时,你一定会产生这样的想法:这怎么写测试用例啊?确实,这不是你的问题,而是这个函数过于庞大导致的。它应该将其中逻辑相近的几个子步骤合并,进而抽象出子函数。这样不仅可读性变高,这些子函数的测试用例也就可以写了。
如何为代码写单元测试
其实,一旦我们的代码遵循了上述的可测试规范,真正编写的时候就简单很多了。接下来,我们讨论一下实战中遇到大型项目测试用例编写的思路。
使用什么测试库?
Golang 官方提供了 testing 的测试库,但我还是强烈推荐一个已经有 8.3 k stars 数的项目:GoConvey。
GoConvey 是一个用于 Go 语言的测试框架,它在官方的 testing 库基础上提供了一些额外的功能和改进,使得编写和运行测试更加方便和高效。相较于官方的 testing 库,它让我喜欢的原因有 2 个。
首先,GoConvey提供了丰富的断言函数,如 ShouldEqual、ShouldBeNil、ShouldResemble 等。这些断言函数让我们的测试用例代码可读性直线提升,读起来和口语一样。比如:
Convey("初始化整数", t, func() {
x := 1
Convey("整数自增", func() {
x++
Convey("结果验证", func() {
So(x, ShouldEqual, 2)
})
})
})
其次,GoConvey 提供了一个Web 界面,可以自动检测文件变化并重新运行测试。这个界面可以实时显示测试结果,极大地提高了开发效率。
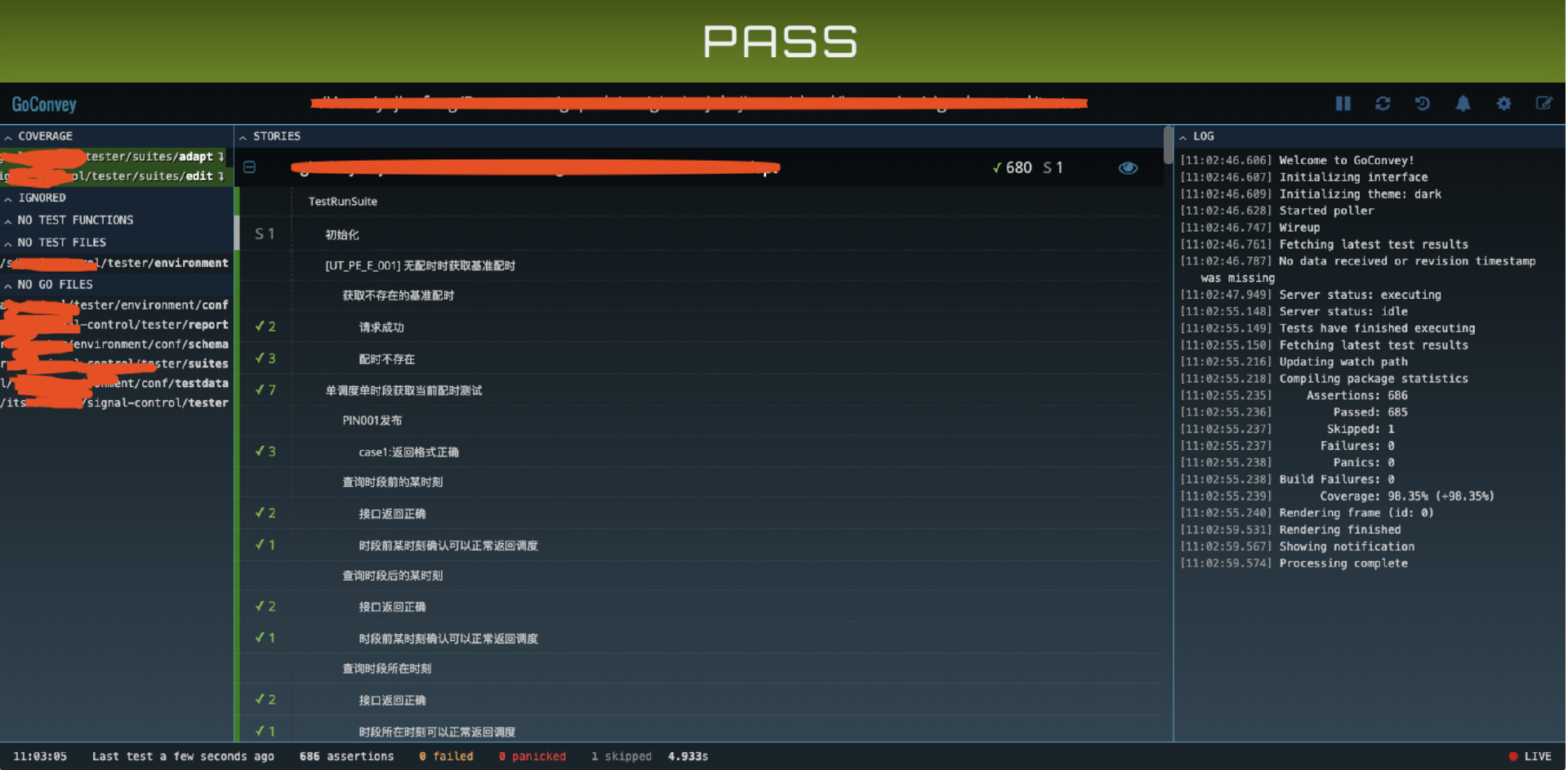
你在修改单元测试的时候,这个页面在浏览器打开后,会实时扫描所有的测试用例,告诉你这次修改的测试用例是通过还是没有通过,你可以根据反馈再进行测试用例修改,效率非常高。
存储注入
Golang 的 Web 项目大都是 IO 密集型的服务,即包含大量的存储类型操作,如数据库操作、缓存操作。所以,如何为这些有存储操作的函数编写单元测试是我们面临的又一个问题。
对于外部存储依赖,我的建议是找到可运行于单机的存储进行替换。
比如,在我的业务中,最常用到 MySQL 存储,会在 MySQL 中进行建表、查询表、删除表的操作。
那在编写单元测试的时候,我会选择使用内存类型的 SQLite 来替换 MySQL,作为单元测试中数据库的存储介质。使用 SQLite 的内存模式进行单元测试具有显著的优势:
- 因为所有数据都存储在内存中,所以测试速度非常快。
- SQLite 设置起来很简单,不需要启动和配置实际的数据库服务器。
- 这样的测试具有独立性,可以在任何环境中运行,不依赖于外部数据库服务。
package main
import (
"database/sql"
"testing"
. "github.com/smartystreets/goconvey/convey"
_ "github.com/mattn/go-sqlite3"
)
// setupTestDB 创建一个 SQLite 内存数据库,并初始化测试数据
func setupTestDB() (*sql.DB, error) {
// 使用 SQLite 内存模式
db, err := sql.Open("sqlite3", ":memory:")
if err != nil {
return nil, err
}
// 创建表和插入测试数据
_, err = db.Exec(`
CREATE TABLE users (
id INTEGER PRIMARY KEY AUTOINCREMENT,
name TEXT
);
INSERT INTO users (name) VALUES ('Alice'), ('Bob');
`)
if err != nil {
return nil, err
}
return db, nil
}
// TestUserQueries 使用 GoConvey 测试查询用户表的功能
func TestUserQueries(t *testing.T) {
// 使用 Convey 块组织测试用例
Convey("Given a SQLite database in memory", t, func() {
// 设置测试数据库
db, err := setupTestDB()
// 断言数据库设置没有错误
So(err, ShouldBeNil)
// 确保测试结束时关闭数据库连接
defer db.Close()
// 描述测试操作
Convey("When querying the users table", func() {
// 执行查询操作
rows, err := db.Query("SELECT name FROM users")
// 断言查询操作没有错误
So(err, ShouldBeNil)
// 确保测试结束时关闭结果集
defer rows.Close()
var names []string
// 遍历查询结果
for rows.Next() {
var name string
// 扫描每一行的结果
err := rows.Scan(&name)
// 断言扫描操作没有错误
So(err, ShouldBeNil)
// 将结果添加到 names 列表中
names = append(names, name)
}
// 描述预期的测试结果
Convey("Then the result should contain two users: Alice and Bob", func() {
// 断言查询结果的长度为 2
So(len(names), ShouldEqual, 2)
// 断言查询结果包含 "Alice"
So(names, ShouldContain, "Alice")
// 断言查询结果包含 "Bob"
So(names, ShouldContain, "Bob")
})
})
})
}
对于 Redis 这个缓存存储的替换库,我也找到了一个拥有 3.2k stars 的项目 miniredis 来进行替换。
miniredis 是一个用 Go 语言编写的 Redis 服务器的模拟实现。它主要用于测试目的,允许开发者在不需要连接到实际 Redis 服务器的情况下,模拟 Redis 的行为。miniredis 提供了简单易用的 API,开发者可以轻松地启动和停止模拟的 Redis 服务器,并可以进行各种操作。它非常适合与 Go 项目集成,开发者可以在测试代码中启动一个 miniredis 实例,并在测试结束后关闭它。
// TestSetAndGet 使用 miniredis 和 Goconvey 测试 SetAndGet 函数
func TestSetAndGet(t *testing.T) {
Convey("Given a miniredis server", t, func() {
// 创建并启动一个 miniredis 实例
s, err := miniredis.Run()
So(err, ShouldBeNil)
defer s.Close()
// 创建一个 Redis 客户端,连接到 miniredis
rdb := redis.NewClient(&redis.Options{
Addr: s.Addr(),
})
Convey("When a key-value pair is set and retrieved", func() {
key := "testkey"
value := "testvalue"
// 调用 SetAndGet 函数
result, err := SetAndGet(rdb, key, value)
So(err, ShouldBeNil)
Convey("Then the retrieved value should be the same as the set value", func() {
So(result, ShouldEqual, value)
})
Convey("And the key should exist in Redis", func() {
// 检查键是否存在
exists, err := rdb.Exists(context.Background(), key).Result()
So(err, ShouldBeNil)
So(exists, ShouldEqual, 1)
})
})
})
}
这个测试用例做了以下几件事:
- 创建并启动一个 miniredis 实例:模拟一个 Redis 服务器。
- 创建一个 Redis 客户端:连接到 miniredis 实例。
- 调用 SetAndGet 函数:测试设置和获取键值对的功能。
- 验证返回值:检查返回的值是否与设置的值相同。
- 检查键是否存在:验证键是否成功存储在 Redis 中。
外部 RPC 服务
作为业务代码,肯定也有很多外部的 RPC 服务。那么,在写单元测试的时候,如何实现这些外部服务的测试呢?
我们在进行单元测试时,不大可能直接对外部服务发起一次调用。首先,外部 RPC 调用会降低我们单元测试运行的速度,跑一次单测需要几分钟而不是几秒钟时,你就会觉得这个单元测试犹如鸡肋。其次,在很多情况下,外部 RPC 服务是不允许单元测试调用的。因为外部 RPC 并不区分你的请求是来自业务还是单元测试,所以要正确获取返回数据,在单元测试中就要设置真实的数据请求,这无疑会大大增加单元测试的编写难度。
无法直接在单元测试中调用外部 RPC 服务,那该怎么办呢?
其实答案就在我们的专栏中,第 10 章和第 11 章中的 “一切皆服务,服务基于协议”就是这个问题的答案和具体的解决方法。
具体来说就是,我们要将这些 RPC 服务接口化,然后使用 Mock 的方式伪造这些 RPC 服务的行为。
我们先来看 RPC 服务怎么进行接口化。得益于 Golang 的接口设计- 鸭子类型(Duck Typing)。鸭子类型定义,一个结构体是否实现了某个接口,不是通过显式声明,而是通过该结构体是否实现了这个接口中定义的所有方法来决定的。
也就是说,如果我现在已经有了一个 RPC 第三方调用类,只要补充定义一个接口,且接口符合这个 RPC 调用结构体定义的方法, 这个 RPC 调用结构体就会被 “接口化”(符合鸭子类型描述),我们也就可以用接口来替代这个 RPC 结构体的调用。
是不是很简单?事实就是如此。我们来看一个具体的例子,如下是一个 RPC 调用结构体:
type RealRPCService struct {
client *rpc.Client
}
func NewRealRPCService(client *rpc.Client) *RealRPCService {
return &RealRPCService{client: client}
}
func (s *RealRPCService) Call(method string, args interface{}, reply interface{}) error {
return s.client.Call(method, args, reply)
}
我们将它接口化:
那么,我们在定义一个业务的 client 结构体时,就可以使用依赖注入的方式,将这个外部依赖接口注入到我们的业务结构体中。
// client.go
package client
import "rpcservice"
type Client struct {
service rpcservice.RPCService
}
func NewClient(service rpcservice.RPCService) *Client {
return &Client{service: service}
}
func (c *Client) PerformAction(method string, args interface{}, reply interface{}) error {
return c.service.Call(method, args, reply)
}
接口化改造结束之后,该怎么应用到测试用例中呢?
我建议可以使用一个 9.3k stars 的 Mock 库。这个库能根据我们定义的接口,生产出 Mock 代码,在 Mock 代码中,我们可以使用类似 EXPECT、Return 类型的代码来描述你希望 Mock 的代码返回值。
我们先用 Mock 库带的工具 mockgen 生产出 Mock 实现:
然后,你就可以编写测试用例来测试 PerformAction 了,代码如下:
func TestPerformAction(t *testing.T) {
ctrl := gomock.NewController(t)
defer ctrl.Finish()
mockService := rpcservice.NewMockRPCService(ctrl)
appClient := client.NewClient(mockService)
// 设置期望值和返回值
method := "Calculator.Add"
args := struct{ A, B int }{A: 1, B: 2}
reply := struct{ Result int }{Result: 3}
mockService.EXPECT().Call(method, args, &reply).Return(nil)
var actualReply struct{ Result int }
err := appClient.PerformAction(method, args, &actualReply)
assert.NoError(t, err)
assert.Equal(t, reply, actualReply)
}
注意,在上述代码的第 13 行,我们定义:当 mockService 被调用了 Calculator.Add 方法,且输入的参数是 args 和 reply 时 ,就会返回 nil。这个定义是我们在单元测试中希望函数来进行的行为。
至此,一个完整的 Mock RPC 服务的单元测试示例就完成了。
总结
今天我们深入探讨了 Go 语言中单元测试的价值和实践方法。
首先,我们揭示了一个关键事实:85%的程序缺陷都产生在编码阶段,而且修复成本会随着时间推移呈指数级增长。这告诉我们,单元测试是在代码编写阶段发现并控制 Bug 的最有效手段。
接着,我们讨论了如何编写可测试的代码。好的代码设计应当避免使用全局状态,保持函数输入输出的稳定性,采用依赖注入的方式处理外部依赖,并遵循单一职责原则编写精简的函数。这些原则不仅有助于提高代码的可测试性,也能显著提升代码的可维护性和可读性。
在实践部分,我推荐使用 GoConvey 测试框架,它能让单元测试的编写和运行更加方便和高效。同时,我建议使用 SQLite 内存数据库来替代 MySQL 进行数据库测试,使用 miniredis 模拟 Redis 环境,以及通过接口化和 Mock 技术来处理外部 RPC 服务的测试。这些实践经验都在实际项目中验证过,能够帮助开发者更好地进行单元测试。
最后,感谢你的阅读,希望这篇文章对你有所帮助!如果有任何问题或建议,欢迎在评论区留言讨论。