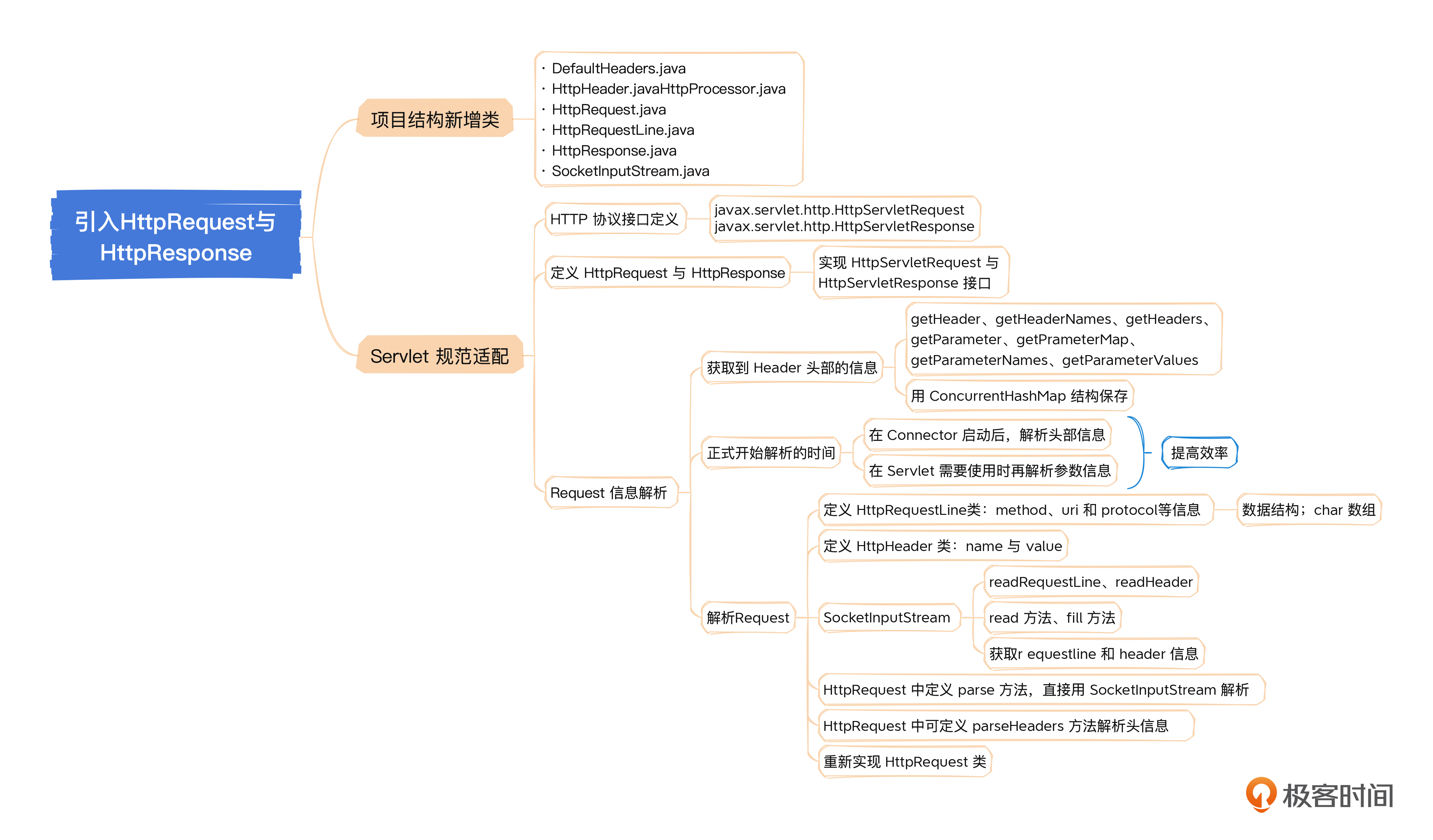
06 规范化:引入HttpRequest与HttpResponse
你好,我是郭屹。今天我们继续手写MiniTomcat。
在前面的学习结束之后,我们引入了池化技术,还实现Processor的异步化。前者复用对象,减少构造新对象的时间开销;后者使Connector能同时服务于多个Processor。这些都是提升性能和吞吐量的常用技术手段。
这节课我们继续研究Servlet规范,对我们现有的代码进行改造,使之适配这个规范。同时我们还要解析HTTP协议中的请求信息,并把它存储到服务器内存之中。
下面就让我们一起来动手实现。
项目结构
这节课因为需要进行Servlet规范适配工作,还要解析头部信息,因此会新增几个类,整体结构如下:
MiniTomcat
├─ src
│ ├─ main
│ │ ├─ java
│ │ │ ├─ server
│ │ │ │ ├─ DefaultHeaders.java
│ │ │ │ ├─ HttpConnector.java
│ │ │ │ ├─ HttpHeader.java
│ │ │ │ ├─ HttpProcessor.java
│ │ │ │ ├─ HttpRequest.java
│ │ │ │ ├─ HttpRequestLine.java
│ │ │ │ ├─ HttpResponse.java
│ │ │ │ ├─ HttpServer.java
│ │ │ │ ├─ Request.java
│ │ │ │ ├─ Response.java
│ │ │ │ ├─ ServletProcessor.java
│ │ │ │ ├─ SocketInputStream.java
│ │ │ │ ├─ StatisResourceProcessor.java
│ │ ├─ resources
│ ├─ test
│ │ ├─ java
│ │ │ ├─ test
│ │ │ │ ├─ HelloServlet.java
│ │ ├─ resources
├─ webroot
│ ├─ test
│ │ ├─ HelloServlet.class
│ ├─ hello.txt
├─ pom.xml
Servlet规范适配
在Servlet规范中,对Request请求和Response返回提供了对应的HTTP协议接口定义,分别是javax.servlet.http.HttpServletRequest和javax.servlet.http.HttpServletResponse。接下来我们实现定义的接口,并逐步开始解析工作。
首先,定义HttpRequest与HttpResponse,分别实现HttpServletRequest与HttpServletResponse接口。实现了这个接口之后,就会要求实现很多接口里面的方法,绝大部分我们都没有用到,所以这里我只列举出几个基本的,不过后面我也给出了完整的代码链接,你可以参考。
package server;
public class HttpRequest implements HttpServletRequest {
public Object getAttribute(String arg0) {
return null;
}
public Enumeration<String> getAttributeNames() {
return null;
}
public String getCharacterEncoding() {
return null;
}
public int getContentLength() {
return 0;
}
public String getContentType() {
return null;
}
public ServletInputStream getInputStream() throws IOException {
return null;
}
public String getParameter(String arg0) {
return null;
}
public Map<String, String[]> getParameterMap() {
return null;
}
public Enumeration<String> getParameterNames() {
return null;
}
public String[] getParameterValues(String arg0) {
return null;
}
public RequestDispatcher getRequestDispatcher(String arg0) {
return null;
}
public ServletContext getServletContext() {
return null;
}
public void setAttribute(String arg0, Object arg1) {
}
public void setCharacterEncoding(String arg0) throws UnsupportedEncodingException {
}
public Cookie[] getCookies() {
return null;
}
public String getQueryString() {
return null;
}
public String getRequestURI() {
return null;
}
public StringBuffer getRequestURL() {
return null;
}
public String getServletPath() {
return null;
}
public HttpSession getSession() {
return null;
}
public HttpSession getSession(boolean arg0) {
return null;
}
}
同样的,HttpServletResponse接口也会有很多实现方法。我们先定义,然后再开始慢慢实现,并不是每个方法都需要用到,绝大多数方法暂时可以不理会。下面是HttpResponse的定义,和前面一样,也只列出几个基本的方法。
package server;
public class HttpResponse implements HttpServletResponse {
public String getCharacterEncoding() {
return null;
}
public String getContentType() {
return null;
}
public ServletOutputStream getOutputStream() throws IOException {
return null;
}
public PrintWriter getWriter() throws IOException {
return null;
}
public void setCharacterEncoding(String arg0) {
}
public void setContentLength(int arg0) {
}
public void setContentType(String arg0) {
}
public void addCookie(Cookie arg0) {
}
public String getHeader(String arg0) {
return null;
}
public Collection<String> getHeaderNames() {
return null;
}
public Collection<String> getHeaders(String arg0) {
return null;
}
}
Request信息解析
我们期望从Servlet的Request请求中能方便地获取到Header头部的信息,所以我们只需要先关注一下定义里的几个方法:getHeader、getHeaderNames、getHeaders、getParameter、getPrameterMap、getParameterNames、getParameterValues。
在HttpRequest的实现中,我们可以用下面这个结构保存这些头信息。
protected HashMap<String, String> headers = new HashMap<>();
protected Map<String, String> parameters = new ConcurrentHashMap<>();
结构中,headers用来存储头的信息,而parameters存储参数信息,采用ConcurrentHashMap结构也是考虑到允许Servlet并发进行增加删除修改操作。
在正式开始解析这些参数信息之前,我们先考虑一个问题:什么时候解析?目前可以考虑两种方案:一是在Connector中预先全部解析完毕,但这种方式性价比并不高,因为Header信息有数十个,甚至上百个,而一个Servlet中实际用到的可能只有寥寥数个;另外一种是在Servlet实际读取Request的时候,根据Request传入的Header信息每次都进行解析。
因此我们可以考虑做出选择:在Connector启动后,解析头部信息,而参数信息则在Servlet需要使用时再解析。放在不同的时间点解析头部和参数信息,主要是为了提高效率。这个选择是参考了Tomcat的做法。
下面我们就开始着手解析Request。
在此之前我们都是用InputStream进行解析,以字节为单位依次读取,效率不高。这里我们自己准备一个类——SocketInputStream,直接按行读取,获取Request line与Header。
首先定义HttpRequestLine类。这个类是Http Request头行的抽象,格式是method uri protocol,如 GET /hello.txt HTTP/1.1。
package server;
public class HttpRequestLine {
public static final int INITIAL_METHOD_SIZE = 8;
public static final int INITIAL_URI_SIZE = 128;
public static final int INITIAL_PROTOCOL_SIZE = 8;
public static final int MAX_METHOD_SIZE = 32;
public static final int MAX_URI_SIZE = 2048;
public static final int MAX_PROTOCOL_SIZE = 32;
//下面的属性对应于Http Request规范,即头行格式method uri protocol
//如:GET /hello.txt HTTP/1.1
//char[] 存储每段的字符串,对应的int值存储的是每段的结束位置
public char[] method;
public int methodEnd;
public char[] uri;
public int uriEnd;
public char[] protocol;
public int protocolEnd;
public HttpRequestLine() {
this(new char[INITIAL_METHOD_SIZE], 0, new char[INITIAL_URI_SIZE], 0,
new char[INITIAL_PROTOCOL_SIZE], 0);
}
public HttpRequestLine(char[] method, int methodEnd,
char[] uri, int uriEnd,
char[] protocol, int protocolEnd) {
this.method = method;
this.methodEnd = methodEnd;
this.uri = uri;
this.uriEnd = uriEnd;
this.protocol = protocol;
this.protocolEnd = protocolEnd;
}
public void recycle() {
methodEnd = 0;
uriEnd = 0;
protocolEnd = 0;
}
public int indexOf(char[] buf) {
return indexOf(buf, buf.length);
}
//这是主要的方法
//在uri[]中查找字符串buf的出现位置
public int indexOf(char[] buf, int end) {
char firstChar = buf[0];
int pos = 0; //pos是查找字符串buf在uri[]中的开始位置
while (pos < uriEnd) {
pos = indexOf(firstChar, pos); //首字符定位开始位置
if (pos == -1) {
return -1;
}
if ((uriEnd - pos) < end) {
return -1;
}
for (int i = 0; i < end; i++) { //从开始位置起逐个字符比对
if (uri[i + pos] != buf[i]) {
break;
}
if (i == (end - 1)) { //每个字符都相等,则匹配上了,返回开始位置
return pos;
}
}
pos++;
}
return -1;
}
public int indexOf(String str) {
return indexOf(str.toCharArray(), str.length());
}
//在uri[]中查找字符c的出现位置
public int indexOf(char c, int start) {
for (int i = start; i < uriEnd; i++) {
if (uri[i] == c) {
return i;
}
}
return -1;
}
}
HttpRequestLine里,包含method、uri和protocol等信息,这是根据HTTP协议来定义的。在实现的过程中,用的数据结构是一个char数组,这样可以从inputstream中直接读取下来,不用经过String的转换,提高了效率,但也因此要提供xxxEnd几个属性来标识最后一个字符的位置,程序的复杂度提高了一些。
这个工具类里面提供了 indexOf() 方法来匹配uri,实现方法是char数组的双重循环匹配。具体可以看上面代码里的注释。
接下来再定义HttpHeader类。
package server;
public class HttpHeader {
public static final int INITIAL_NAME_SIZE = 64;
public static final int INITIAL_VALUE_SIZE = 512;
public static final int MAX_NAME_SIZE = 128;
public static final int MAX_VALUE_SIZE = 1024;
public char[] name;
public int nameEnd;
public char[] value;
public int valueEnd;
protected int hashCode = 0;
public HttpHeader() {
this(new char[INITIAL_NAME_SIZE], 0, new char[INITIAL_VALUE_SIZE], 0);
}
public HttpHeader(char[] name, int nameEnd, char[] value, int valueEnd) {
this.name = name;
this.nameEnd = nameEnd;
this.value = value;
this.valueEnd = valueEnd;
}
public HttpHeader(String name, String value) {
this.name = name.toLowerCase().toCharArray();
this.nameEnd = name.length();
this.value = value.toCharArray();
this.valueEnd = value.length();
}
public void recycle() {
nameEnd = 0;
valueEnd = 0;
hashCode = 0;
}
}
根据上面的实现可以看到,HttpRequestLine里包含method、uri与protocol,HttpHeader中包含name与value。实现的类里面还包含xxxEnd类型的域定义,用来标识某一属性最后的位置。
在HttpRequestLine与HttpHeader类定义完毕之后,我们可以在SocketInputStream中定义两个方法,直接获取Request line与Headers。
public void readRequestLine(HttpRequestLine requestLine){}
public void readHeader(HttpHeader header){}
可以回忆一下我们之前解析Header首行的经过:按行读取成一个字符串,依据空格分隔,获取method、uri和protocol。现在我们参考Tomcat,在SocketInputStream里提供一个更专业、更高效的实现。
protected void fill() throws IOException {
pos = 0;
count = 0;
int nRead = is.read(buf, 0, buf.length);
if (nRead > 0) {
count = nRead;
}
}
上述代码显示,fill方法会从InputStream里读取一批字节,存储到byte数组的buf属性中。
而 fill() 被调用到 read() 方法内,每次从buf中读到当前的字节返回,如果 pos >= count 表示当前的byte已获取完毕,内部就调用fill方法获取新的字节流。因此,对上层程序员来说,使用 read() 就相当于可以连续读取缓存中的数据。
read方法实现如下:
@Override
public int read() throws IOException {
if (pos >= count) {
fill();
if (pos >= count) {
return -1;
}
}
return buf[pos++] & 0xff;
}
其中这个方法返回-1表示读取出错。
有了这些铺垫,我们再来看SocketInputStream的完整实现。简单地说,这个类的作用就是从输入流中读出request line和header信息来。
package server;
public class SocketInputStream extends InputStream {
private static final byte CR = (byte) '\r';
private static final byte LF = (byte) '\n';
private static final byte SP = (byte) ' ';
private static final byte HT = (byte) '\t';
private static final byte COLON = (byte) ':';
private static final int LC_OFFSET = 'A' - 'a';
protected byte buf[];
protected int count;
protected int pos;
protected InputStream is;
public SocketInputStream(InputStream is, int bufferSize) {
this.is = is;
buf = new byte[bufferSize];
}
//从输入流中解析出request line
public void readRequestLine(HttpRequestLine requestLine)
throws IOException {
int chr = 0;
//跳过空行
do {
try {
chr = read();
} catch (IOException e) {
}
} while ((chr == CR) || (chr == LF));
//第一个非空位置
pos--;
int maxRead = requestLine.method.length;
int readStart = pos;
int readCount = 0;
boolean space = false;
//解析第一段method,以空格结束
while (!space) {
if (pos >= count) {
int val = read();
if (val == -1) {
throw new IOException("requestStream.readline.error");
}
pos = 0;
readStart = 0;
}
if (buf[pos] == SP) {
space = true;
}
requestLine.method[readCount] = (char) buf[pos];
readCount++;
pos++;
}
requestLine.methodEnd = readCount - 1; //method段的结束位置
maxRead = requestLine.uri.length;
readStart = pos;
readCount = 0;
space = false;
boolean eol = false;
//解析第二段uri,以空格结束
while (!space) {
if (pos >= count) {
int val = read();
if (val == -1)
throw new IOException("requestStream.readline.error");
pos = 0;
readStart = 0;
}
if (buf[pos] == SP) {
space = true;
}
requestLine.uri[readCount] = (char) buf[pos];
readCount++;
pos++;
}
requestLine.uriEnd = readCount - 1; //uri结束位置
maxRead = requestLine.protocol.length;
readStart = pos;
readCount = 0;
//解析第三段protocol,以eol结尾
while (!eol) {
if (pos >= count) {
int val = read();
if (val == -1)
throw new IOException("requestStream.readline.error");
pos = 0;
readStart = 0;
}
if (buf[pos] == CR) {
// Skip CR.
} else if (buf[pos] == LF) {
eol = true;
} else {
requestLine.protocol[readCount] = (char) buf[pos];
readCount++;
}
pos++;
}
requestLine.protocolEnd = readCount;
}
public void readHeader(HttpHeader header)
throws IOException {
int chr = read();
if ((chr == CR) || (chr == LF)) { // Skipping CR
if (chr == CR)
read(); // Skipping LF
header.nameEnd = 0;
header.valueEnd = 0;
return;
} else {
pos--;
}
// 正在读取 header name
int maxRead = header.name.length;
int readStart = pos;
int readCount = 0;
boolean colon = false;
while (!colon) {
// 我们处于内部缓冲区的末尾
if (pos >= count) {
int val = read();
if (val == -1) {
throw new IOException("requestStream.readline.error");
}
pos = 0;
readStart = 0;
}
if (buf[pos] == COLON) {
colon = true;
}
char val = (char) buf[pos];
if ((val >= 'A') && (val <= 'Z')) {
val = (char) (val - LC_OFFSET);
}
header.name[readCount] = val;
readCount++;
pos++;
}
header.nameEnd = readCount - 1;
// 读取 header 值(可以跨越多行)
maxRead = header.value.length;
readStart = pos;
readCount = 0;
int crPos = -2;
boolean eol = false;
boolean validLine = true;
while (validLine) {
boolean space = true;
// 跳过空格
// 注意:仅删除前面的空格,后面的不删。
while (space) {
// 我们已经到了内部缓冲区的尽头
if (pos >= count) {
// 将内部缓冲区的一部分(或全部)复制到行缓冲区
int val = read();
if (val == -1)
throw new IOException("requestStream.readline.error");
pos = 0;
readStart = 0;
}
if ((buf[pos] == SP) || (buf[pos] == HT)) {
pos++;
} else {
space = false;
}
}
while (!eol) {
// 我们已经到了内部缓冲区的尽头
if (pos >= count) {
// 将内部缓冲区的一部分(或全部)复制到行缓冲区
int val = read();
if (val == -1)
throw new IOException("requestStream.readline.error");
pos = 0;
readStart = 0;
}
if (buf[pos] == CR) {
} else if (buf[pos] == LF) {
eol = true;
} else {
// FIXME:检查二进制转换是否正常
int ch = buf[pos] & 0xff;
header.value[readCount] = (char) ch;
readCount++;
}
pos++;
}
int nextChr = read();
if ((nextChr != SP) && (nextChr != HT)) {
pos--;
validLine = false;
} else {
eol = false;
header.value[readCount] = ' ';
readCount++;
}
}
header.valueEnd = readCount;
}
@Override
public int read() throws IOException {
if (pos >= count) {
fill();
if (pos >= count) {
return -1;
}
}
return buf[pos++] & 0xff;
}
public int available() throws IOException {
return (count - pos) + is.available();
}
public void close() throws IOException {
if (is == null) {
return;
}
is.close();
is = null;
buf = null;
}
protected void fill() throws IOException {
pos = 0;
count = 0;
int nRead = is.read(buf, 0, buf.length);
if (nRead > 0) {
count = nRead;
}
}
}
从代码可以看出,Tomcat在这里就是用的最简单的扫描方法,从inputstream里读一个个的字节,放到buf里,buf有长度限制,读到尾后就从头再来。然后从buf里一个字节一个字节地判断,pos变量代表当前读取的位置,根据协议规定的分隔符解析到requestline和header里。
拥有了工具类后,Request内获取Request line就比较容易了,在HttpRequest中定义parse方法,直接用SocketInputStream解析。
public void parse(Socket socket) {
this.sis.readRequestLine(requestLine);
this.uri = new String(requestLine.uri, 0, requestLine.uriEnd);
}
这个时候HttpProcessor中就不用Request类构建对象了,改用HttpRequest。
所以ServletProcessor和StaticResourceProcessor里的process方法,传入的Request类型参数都改成HttpRequest。
同理,我们来解析Header。和前面一样,在SocketInputStream里已定义了 readHeader(HttpHeader header) 方法,将头信息读入header属性中。我们先定义DefaultHeaders常量类,假设支持下面这些头信息。
package server;
public class DefaultHeaders {
static final String HOST_NAME = "host";
static final String CONNECTION_NAME = "connection";
static final String ACCEPT_LANGUAGE_NAME = "accept-language";
static final String CONTENT_LENGTH_NAME = "content-length";
static final String CONTENT_TYPE_NAME = "content-type";
static final String TRANSFER_ENCODING_NAME = "transfer-encoding";
}
接下来在HttpRequest中可定义parseHeaders方法解析头信息。
private void parseHeaders() throws IOException, ServletException {
while (true) {
HttpHeader header = new HttpHeader();
sis.readHeader(header);
if (header.nameEnd == 0) {
if (header.valueEnd == 0) {
return;
} else {
throw new ServletException("httpProcessor.parseHeaders.colon");
}
}
String name = new String(header.name,0,header.nameEnd);
String value = new String(header.value, 0, header.valueEnd);
// Set the corresponding request headers
if (name.equals(DefaultHeaders.ACCEPT_LANGUAGE_NAME)) {
headers.put(name, value);
} else if (name.equals(DefaultHeaders.CONTENT_LENGTH_NAME)) {
headers.put(name, value);
} else if (name.equals(DefaultHeaders.CONTENT_TYPE_NAME)) {
headers.put(name, value);
} else if (name.equals(DefaultHeaders.HOST_NAME)) {
headers.put(name, value);
} else if (name.equals(DefaultHeaders.CONNECTION_NAME)) {
headers.put(name, value);
} else if (name.equals(DefaultHeaders.TRANSFER_ENCODING_NAME)) {
headers.put(name, value);
} else {
headers.put(name, value);
}
}
目前实现也比较简单,判断是否是我们支持的头信息,支持后直接存入headers这个map数据结构里。parse方法则支持解析Request Line与Header。
综合以上内容,我们来重新实现HttpRequest类,HttpServletRequest接口的那些现在没有用到的方法暂时不列出来。
package server;
public class HttpRequest implements HttpServletRequest {
private InputStream input;
private SocketInputStream sis;
private String uri;
InetAddress address;
int port;
protected HashMap<String, String> headers = new HashMap<>();
protected Map<String, String> parameters = new ConcurrentHashMap<>();
HttpRequestLine requestLine = new HttpRequestLine();
public HttpRequest(InputStream input) {
this.input = input;
this.sis = new SocketInputStream(this.input, 2048);
}
public void parse(Socket socket) {
try {
parseConnection(socket);
this.sis.readRequestLine(requestLine);
parseHeaders();
} catch (IOException e) {
e.printStackTrace();
} catch (ServletException e) {
e.printStackTrace();
}
this.uri = new String(requestLine.uri, 0, requestLine.uriEnd);
}
private void parseConnection(Socket socket) {
address = socket.getInetAddress();
port = socket.getPort();
}
private void parseHeaders() throws IOException, ServletException {
while (true) {
HttpHeader header = new HttpHeader();
sis.readHeader(header);
if (header.nameEnd == 0) {
if (header.valueEnd == 0) {
return;
} else {
throw new ServletException("httpProcessor.parseHeaders.colon");
}
}
String name = new String(header.name,0,header.nameEnd);
String value = new String(header.value, 0, header.valueEnd);
// 设置相应的请求头
if (name.equals(DefaultHeaders.ACCEPT_LANGUAGE_NAME)) {
headers.put(name, value);
} else if (name.equals(DefaultHeaders.CONTENT_LENGTH_NAME)) {
headers.put(name, value);
} else if (name.equals(DefaultHeaders.CONTENT_TYPE_NAME)) {
headers.put(name, value);
} else if (name.equals(DefaultHeaders.HOST_NAME)) {
headers.put(name, value);
} else if (name.equals(DefaultHeaders.CONNECTION_NAME)) {
headers.put(name, value);
} else if (name.equals(DefaultHeaders.TRANSFER_ENCODING_NAME)) {
headers.put(name, value);
} else {
headers.put(name, value);
}
}
}
public String getUri() {
return this.uri;
}
}
可以看到这个HttpRequest已经相对简单了。
测试
我们这一节课的实现只是内部的程序结构变动,并不影响用户的Servlet和客户端的访问。所以还是可以沿用上一节课的测试办法进行验证,这里我就不重复说了。
小结
这节课我们主要做了两件事:一是进一步适配Servlet规范,实现HttpServletRequest和HttpServletResponse两个接口。我们看到接口中有很多方法,目前我们绝大部分都没有实现,是留空状态,只是先实现最基本的几个方法就可以让程序运行起来了。
二是引入SocketInputStream,按行读取Request信息,解析Request line与header信息,提高效率和性能,摒弃了我们原有的解析模式。我们可以看到这是一种更加高效的实现办法。
这两件事情本身并没有扩展我们服务器的功能,目的是符合规范并且高效,这一点我们要向Tomcat学习。
本节课完整代码参见:https://gitee.com/yaleguo1/minit-learning-demo/tree/geek_chapter06
思考题
学完了这节课的内容,我们来思考一个问题:我们在 SocketInputStream的read() 方法中,用到了ketInputStream的read()方法中,用到了 buf[pos++] & 0xff 这个操作,它的作用是什么?
欢迎你把你思考后的结果分享到评论区,也欢迎你把这节课的内容分享给其他朋友,我们下节课再见!
- C. 👍(4) 💬(3)
buf[pos++]:表示buf的pos索引加一,以便后续read操作,是个后缀递增的操作。 & 0xff:位操作,字节在Java的中的范围为-128到127,是个有符号数,执行& 0xff是在做一个按位与操作,转换为一个无符号数,返回的值在0-255。0xff等于十进制的255,二进制位11111111。buf[pos]字节会与11111111进行按位与操作,基本保持了原始字节的值不变。
2023-12-20 - Clark Chen 👍(1) 💬(1)
老师好, 关于`SocketInputStream .readRequestLine(HttpRequestLine requestLine)` 方法的这段代码
有些地方没想明白, 为什么要在这个方法里面对手动控制pos++,直接获取buf[]里面的值 ,而不是通过read 方法来获取值。如下面这样 是有效率上的原因吗?2023-12-24 - peter 👍(0) 💬(1)
请教老师两个问题: Q1:parameters用来做什么? HttpRequest类中定义了parameters,但好像并没有使用,这个类是用来存什么的? Q2:parseHeaders函数用if区分有意义吗? HttpRequest类中的parseHeaders用if … else来区分各个部分,但其实最后都是调用headers.put(name, value); 所有的分支,最后的处理结果都是一样的,这个区分还有意义吗?
2023-12-20 - HH🐷🐠 👍(0) 💬(1)
😄感觉像是纠正什么数据
2023-12-20