05 Server性能提升:设计多个Processor
你好,我是郭屹。今天我们继续手写MiniTomcat。
学完前几节课的内容之后,现在我们已经做到接口满足Servlet规范,而且功能模块拆分成了Connector和Processor两部分,它们各司其职,一个负责网络连接,一个负责Servlet调用处理。
但现在这个Server的运行模式是,一个Connector服务于一个Processor,而且每次创建Processor的时候都是重新实例化一个新的对象,Processor还不支持多线程处理,所以我们在HttpServer性能方面还有提升的空间。
这节课,我们计划引入池的概念,增强Processor的复用性,同时将Processor异步化,支持一个Connector服务于多个Processor。
项目结构
这节课,我们只针对原有的HttpConnector和HttpProcessor类进行改造,所以项目结构和maven引入依赖保持不变,还是延续下面的结构和配置。
MiniTomcat
├─ src
│ ├─ main
│ │ ├─ java
│ │ │ ├─ server
│ │ │ │ ├─ HttpConnector.java
│ │ │ │ ├─ HttpProcessor.java
│ │ │ │ ├─ HttpServer.java
│ │ │ │ ├─ Request.java
│ │ │ │ ├─ Response.java
│ │ │ │ ├─ ServletProcessor.java
│ │ │ │ ├─ StatisResourceProcessor.java
│ │ ├─ resources
│ ├─ test
│ │ ├─ java
│ │ │ ├─ test
│ │ │ │ ├─ HelloServlet.java
│ │ ├─ resources
├─ webroot
│ ├─ test
│ │ ├─ HelloServlet.class
│ ├─ hello.txt
├─ pom.xml
pom.xml参考如下:
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>day3</groupId>
<artifactId>day3</artifactId>
<version>0.0.1-SNAPSHOT</version>
<dependencies>
<dependency>
<groupId>javax.servlet</groupId>
<artifactId>javax.servlet-api</artifactId>
<version>4.0.1</version>
</dependency>
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-lang3</artifactId>
<version>3.4</version>
</dependency>
</dependencies>
</project>
池化技术引入
现在我们在HttpConnector里获取到Socket后,每次都是创建一个全新的HttpProcessor对象,如下所示:
socket = serverSocket.accept();
HttpProcessor processor = new HttpProcessor();
processor.process(socket);
在并发请求逐步增加后,构造新对象会对服务器的性能造成负担,所以我们打算引入池,把对象初始化好之后,需要用的时候再拿出来使用,不需要使用的时候就再放回池里,不用再构造新的对象。
因此,接下来我们先改造HttpConnector类,使用ArrayDeque存放构造完毕的HttpProcessor对象。改造如下:
public class HttpConnector implements Runnable {
int minProcessors = 3;
int maxProcessors = 10;
int curProcessors = 0;
//存放多个processor的池子
Deque<HttpProcessor> processors = new ArrayDeque<>();
public void run() {
ServerSocket serverSocket = null;
int port = 8080;
try {
serverSocket = new ServerSocket(port, 1, InetAddress.getByName("127.0.0.1"));
} catch (IOException e) {
e.printStackTrace();
System.exit(1);
}
// initialize processors pool
for (int i = 0; i < minProcessors; i++) {
HttpProcessor processor = new HttpProcessor();
processors.push(processor);
}
curProcessors = minProcessors;
while (true) {
Socket socket = null;
try {
socket = serverSocket.accept();
//得到一个新的processor,这个processor从池中获取(池中有可能新建)
HttpProcessor processor = createProcessor();
if (processor == null) {
socket.close();
continue;
}
processor.process(socket); //处理
processors.push(processor); //处理完毕后放回池子
// Close the socket
socket.close();
} catch (Exception e) {
e.printStackTrace();
}
}
}
public void start() {
Thread thread = new Thread(this);
thread.start();
}
//从池子中获取一个processor,如果池子为空且小于最大限制,则新建一个
private HttpProcessor createProcessor() {
synchronized (processors) {
if (processors.size() > 0) {
//获取一个
return ((HttpProcessor) processors.pop());
}
if (curProcessors < maxProcessors) {
//新建一个
return (newProcessor());
}
else {
return (null);
}
}
}
//新建一个processor
private HttpProcessor newProcessor() {
HttpProcessor initprocessor = new HttpProcessor();
processors.push(initprocessor);
curProcessors++;
return ((HttpProcessor) processors.pop());
}
}
从上述代码中,我们可以看到,run()方法中先进行了processors池的初始化,就是循环创建新的HttpProcessor对象后,push到processors这个ArrayDeque里,processors作为HttpProcessor对象的存储池使用。
之后,每次接收到一个socket,就用createProcessor()方法获取到一个processor。看一下createProcessor()方法的代码,可以发现当processors内元素不为空的时候,直接从ArrayDeque内获取HttpProcessor对象,每次从池里获取一个processor。如果池子里没有processor,就新创建一个。
无论池子里有没有,最后的结果都是拿到了一个processor,然后执行它,任务执行完之后再把它放回池里。完成了一次请求响应。
但是我们要注意,到现在为止,HttpProcessor并没有做到多线程,也没有实现NIO,只是在池中放置了多个对象,做到了多路复用。目前整体架构还是阻塞式运行的,Socket每次用之后也关闭丢弃了。
所以我们要继续改造,优化HttpProcessor的性能。
多线程HttpProcessor
接下来,我们计划设置多线程Processor,通过这个手段继续优化它的性能。这可以使一个Connector同时服务于多个Processor。
基本的思路是使用多个线程,让Connector和Processor分别由不同的线程来运行。工作的基本流程是由Connector接收某个Socket连接后交给某个Processor线程处理,而Processor线程等待某个Socket连接到来后进行处理,处理完毕之后要交回给Connector。因此,这里的核心是要设计一个线程之间的同步机制。
首先我们让HttpProcessor实现Runnable接口,这样每一个HttpProcessor都可以在独立的线程中运行。改造如下:
public class HttpProcessor implements Runnable{
@Override
public void run() {
while (true) {
// 等待socket分配过来
Socket socket = await();
if (socket == null) continue;
// 处理请求
process(socket);
// 回收processor
connector.recycle(this);
}
}
}
上述Processor的run()方法执行过程是,等待某个Socket,收到Connector交过来的Socket后,Process方法处理这个Socket,处理完毕之后交回给Connector回收,并重新把这个processor放入池里。
这是Processor接收者这一边,而另一边就是作为分配者的Connector。类似地,我们提供一个assign方法让Connector分配Socket给Processor。
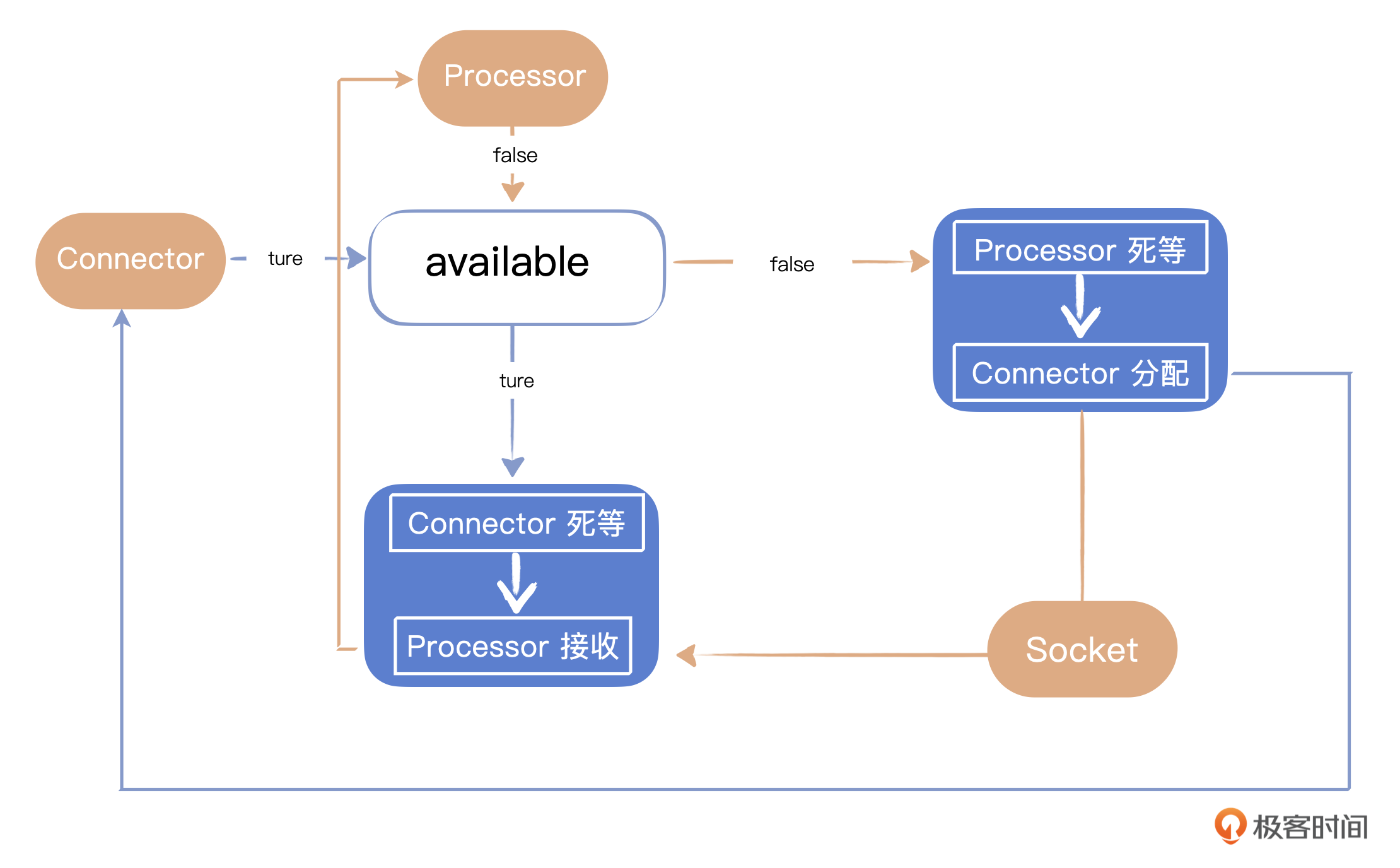
接下来我们重点解决分配者和接收者如何同步的问题。因为这是两个线程,一定需要同步才能协同工作。基本的思路就是 await() 方法里等着Socket,而assign()方法里分配Socket,中间通过一个标志来表示分配和接收状态,以此进行同步。
这个同步的机制内部其实就是用的Java自身提供的notify和wait。
看程序代码,如下所示:
synchronized void assign(Socket socket) {
// 等待connector提供一个新的socket
while (available) {
try {
wait();
} catch (InterruptedException e) {
}
}
// 获取到这个新的Socket
this.socket = socket;
// 把标志设置回去
available = true;
//通知另外的线程
notifyAll();
}
private synchronized Socket await() {
// 等待connector提供一个新的socket
while (!available) {
try {
wait();
}catch (InterruptedException e) {
}
}
// 获得这个新的Socket
Socket socket = this.socket;
//设置标志为false
available = false;
//通知另外的线程
notifyAll();
return (socket);
}
首先看 assign(socket) 方法,在这里,我们用一个标志available来标记,如果标志为true,Connetor线程就继续死等。到了某个时候,Processor线程把这个标志设置为false,Connector线程就跳出死等的循环,然后把接收到的Socket交给Processor。然后要立刻重新把available标志设置为true,再调用 notifyAll() 通知其他线程。
再看 await(),这是作为接收者Processor的线程使用的方法。反过来,如果avaliable标志为false,那么Processor线程继续死等。到了某个时候,Connector线把这个标志设置为true,那么Processor线程就跳出死等的循环,拿到Socket。然后要立刻重新把avaiable标志设置为false,再调用 notifyAll() 通知其他线程。
这个线程互锁机制保证了两个线程之间的同步协调。图示如下:
下面我列出HttpProcessor的完整代码,因为HttpProcessor构造函数调整,增加了HttpConnector的参数,所以我把HttpConnector类调整后的代码一并列出了,随后我们统一说明调整步骤还有调整的理由。
HttpProcessor代码:
public class HttpProcessor implements Runnable{
Socket socket;
boolean available = false;
HttpConnector connector;
public HttpProcessor(HttpConnector connector) {
this.connector = connector;
}
@Override
public void run() {
while (true) {
// 等待分配下一个 socket
Socket socket = await();
if (socket == null) continue;
// 处理来自这个socket的请求
process(socket);
// 完成此请求
connector.recycle(this);
}
}
public void start() {
Thread thread = new Thread(this);
thread.start();
}
public void process(Socket socket) {
try {
Thread.sleep(3000);
} catch (InterruptedException e1) {
e1.printStackTrace();
}
InputStream input = null;
OutputStream output = null;
try {
input = socket.getInputStream();
output = socket.getOutputStream();
// 创建请求对象并解析
Request request = new Request(input);
request.parse();
// 创建响应对象
Response response = new Response(output);
response.setRequest(request);
// response.sendStaticResource();
// 检查这是对servlet还是静态资源的请求
// a request for a servlet begins with "/servlet/"
if (request.getUri().startsWith("/servlet/")) {
ServletProcessor processor = new ServletProcessor();
processor.process(request, response);
}
else {
StaticResourceProcessor processor = new StaticResourceProcessor();
processor.process(request, response);
}
// 关闭 socket
socket.close();
} catch (Exception e) {
e.printStackTrace();
}
}
synchronized void assign(Socket socket) {
// 等待 connector 提供新的 Socket
while (available) {
try {
wait();
} catch (InterruptedException e) {
}
}
// 存储新可用的 Socket 并通知我们的线程
this.socket = socket;
available = true;
notifyAll();
}
private synchronized Socket await() {
// 等待 connector 提供一个新的 Socket
while (!available) {
try {
wait();
}catch (InterruptedException e) {
}
}
// 通知Connector我们已经收到这个Socket了
Socket socket = this.socket;
available = false;
notifyAll();
return (socket);
}
}
要注意available标志和 assign() 方法都是写在Processor类里的。
但是这并不表示 assign() 是Processor线程来执行,因为这个方法的调用者是Connector。
HttpConnector代码:
public class HttpConnector implements Runnable {
int minProcessors = 3;
int maxProcessors = 10;
int curProcessors = 0;
//存放Processor的池子
Deque<HttpProcessor> processors = new ArrayDeque<>();
public void run() {
ServerSocket serverSocket = null;
int port = 8080;
try {
serverSocket = new ServerSocket(port, 1, InetAddress.getByName("127.0.0.1"));
} catch (IOException e) {
e.printStackTrace();
System.exit(1);
}
// 初始化池子initialize processors pool
for (int i = 0; i < minProcessors; i++) {
HttpProcessor initprocessor = new HttpProcessor(this);
initprocessor.start();
processors.push(initprocessor);
}
curProcessors = minProcessors;
while (true) {
Socket socket = null;
try {
socket = serverSocket.accept();
//对每一个socket,从池子中拿到一个processor
HttpProcessor processor = createProcessor();
if (processor == null) {
socket.close();
continue;
}
//分配给这个processor
processor.assign(socket);
// Close the socket
// socket.close();
} catch (Exception e) {
e.printStackTrace();
}
}
}
public void start() {
Thread thread = new Thread(this);
thread.start();
}
//从池子中获取一个processor,池子为空且数量小于最大限制则会新建一个processor
private HttpProcessor createProcessor() {
synchronized (processors) {
if (processors.size() > 0) {
return ((HttpProcessor) processors.pop());
}
if (curProcessors < maxProcessors) {
return (newProcessor());
}
else {
return (null);
}
}
}
private HttpProcessor newProcessor() {
HttpProcessor initprocessor = new HttpProcessor(this);
initprocessor.start();
processors.push(initprocessor);
curProcessors++;
return ((HttpProcessor) processors.pop());
}
void recycle(HttpProcessor processor) {
processors.push(processor);
}
}
我们再回顾一下HttpProcessor类中的assign方法与await方法。在HttpProcessor的线程启动之后,available的标识一直是false,这个时候这个线程会一直等待。在HttpConnector类里构造Processor,并且调用 processor.assign(socket) 给HttpProcessor分配Socket之后,标识符available改成true,并且调用notifyAll这个本地方法通知唤醒所有等待的线程。
而在await方法里,HttpProcessor拿到HttpConnector传来的Socket之后,首先会接收Socket,并且立即把available由true改为false,最后以拿到的这个Socket为基准继续进行Processor中的处理工作。
这也意味着,一旦Connector分配了一个Socket给到Processor,后者就能立即结束等待,拿到Socket后调用Process方法继续后面的工作。这时available的状态立刻修改,进而用notifyAll方法唤醒Connector的等待线程,Connector就可以全身而退,去处理下一个HttpProcessor了。
Tomcat中两个线程互锁的这种机制很经典,在后续版本的NIO和Servlet协调的设计中都用到了。
这样也就做到了HttpProcessor的异步化,也正因为做到了异步化,我们就不能再利用Connector去关闭Socket了,因为Connector是不知道Processor何时处理完毕的,Socket的关闭任务就交给Processor自己处理了。
因此在Connector类里,socket.close()这一行被注释掉了,而在Processor类里新增了那一行代码。
测试
在src/test/java/test目录下,修改HelloServlet。
package test;
import java.io.IOException;
import javax.servlet.Servlet;
import javax.servlet.ServletConfig;
import javax.servlet.ServletException;
import javax.servlet.ServletRequest;
import javax.servlet.ServletResponse;
public class HelloServlet implements Servlet{
@Override
public void service(ServletRequest req, ServletResponse res) throws ServletException, IOException {
res.setCharacterEncoding("UTF-8");
String doc = "<!DOCTYPE html> \n" +
"<html>\n" +
"<head><meta charset=\"utf-8\"><title>Test</title></head>\n"+
"<body bgcolor=\"#f0f0f0\">\n" +
"<h1 align=\"center\">" + "Hello World 你好" + "</h1>\n";
res.getWriter().println(doc);
}
@Override
public void destroy() {
}
@Override
public ServletConfig getServletConfig() {
return null;
}
@Override
public String getServletInfo() {
return null;
}
@Override
public void init(ServletConfig arg0) throws ServletException {
}
}
这一次我们的测试类还是和之前差不多,但在Processor的process方法中,我们新增了Thread.sleep方法。
在准备工作进行完毕之后,我们运行HttpServer服务器,在浏览器中可以连续打开多个页面,键入 http://localhost:8080/hello.txt 后,等待一小段时间(这个时间由Thread.sleep传入参数timeout决定,timeout以毫秒为单位),随后我们可以发现hello.txt里的所有文本内容,都作为返回体展示在浏览器页面上了。
再以同样的方法测试HelloServlet,输入 http://localhost:8080/servlet/test.HelloServlet 后等待一小会儿还是可以看到浏览器显示:Hello World 你好。这也是我们在HelloServlet里定义的返回资源内容。
这些结果可以证明,我们整体的改造已经做到Processor异步化的改造,在客户端连续输入多次请求后,能做到并发执行,互不影响。
小结
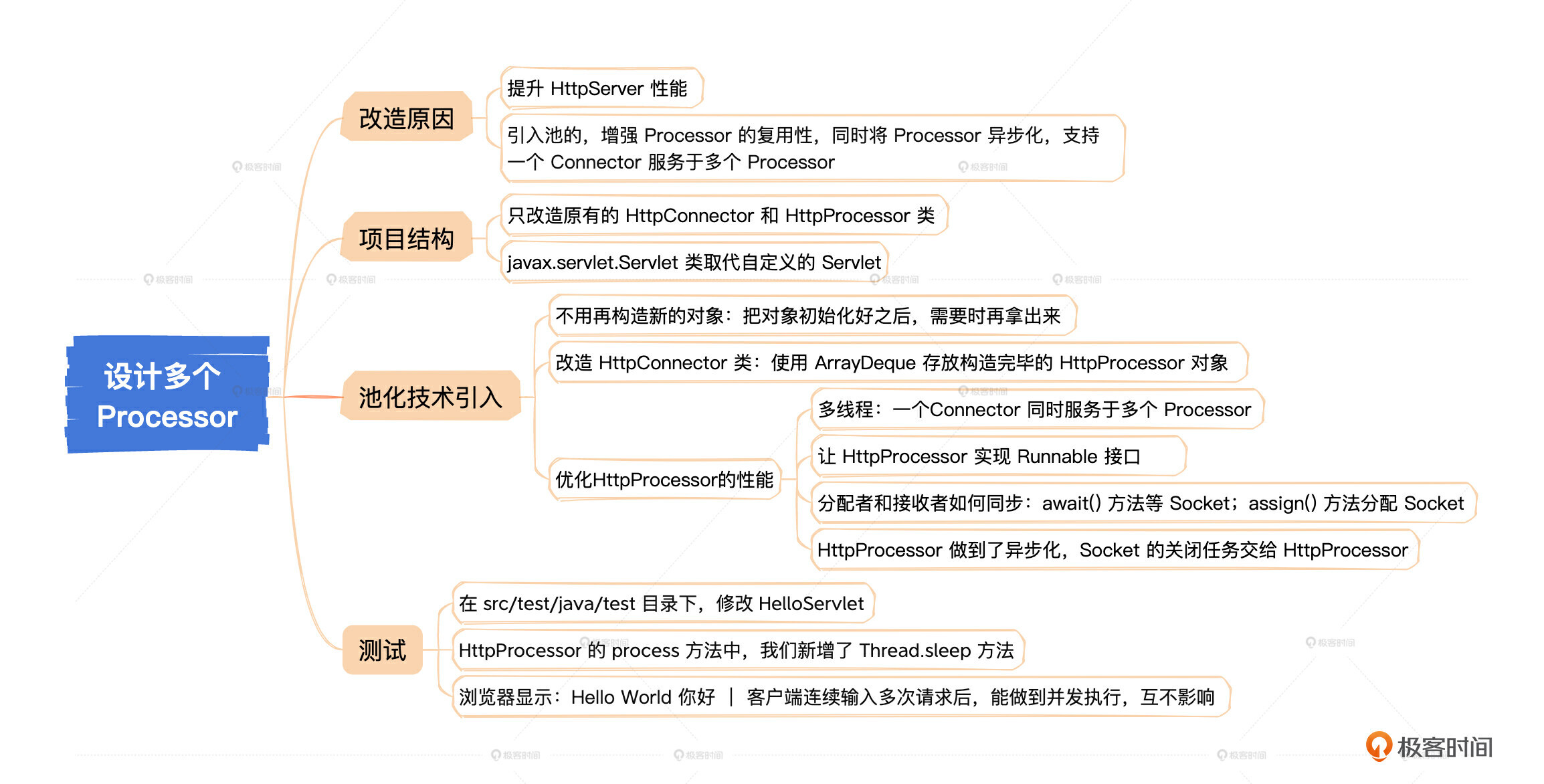
这节课我们主要做了两件事:引入池化技术以及Processor多线程。前者我们从优化对象构造,持续复用的角度,做到了性能的优化提升,压缩了构造对象的性能开销;而后者则从并发的角度,使Connector能同时服务于多个Processor,减少了原来因等待Processor处理而产生的时间消耗,但是也需要仔细编写线程同步代码。
本节课完整代码参见:https://gitee.com/yaleguo1/minit-learning-demo/tree/geek_chapter05
思考题
学完了这节课的内容,我们来思考一个问题:Tomcat为什么用一个简单的queue来实现多线程而不是用JDK自带的线程池?
欢迎你把你思考后的结果分享到评论区,也欢迎你把这节课的内容分享给其他朋友,我们下节课再见!
- 马以 👍(5) 💬(4)
思考题:tomcat的线程池模型和JDK自带线程池模型在核心线程池用完后的实现方式上是不同的;JDK的线程池在达到核心线程池数量后,后续的请求会进入到等待队列(微观上看属于阻塞),因为tomcat作为servlet服务请求,本质上只能并发处理有限个(核心线程数)的并发数,这显然是不合理的;所以tomcat的线程池模型是达到核心线程池后会继续启动新线程处理请求,直到达到最大线程数;
2024-01-04 - Geek_ac5e30 👍(4) 💬(3)
这里 available 变量是否使用 volatile 修饰会好一些呢?这里涉及到两个线程之间的可见性问题
2024-03-13 - so long 👍(2) 💬(1)
jdk线程池,在并发数超过核心线程数后,会先将请求任务添加到队列中,而不是创建新的线程处理请求任务,所以会存在一定的延迟
2023-12-18 - 像少年样飞驰 👍(1) 💬(1)
这里面线程同步机制需要这样写么? 直接参考线程池的设计,用一个阻塞队列是不是就可以了? 本质上还是一个生产和消费的模型吧
2023-12-24 - peter 👍(1) 💬(4)
请教老师几个问题: Q1:用notifyAll唤醒所有线程,不对吧。 假如有5个线程,connector同时启动这5个线程,5个线程处于wait状态。假设此时来了一个连接请求,由其中的一个线程A处理,那么,connector应该只唤醒这线程A吧。用notifyall会唤醒全部5个线程,难道5个线程处理同一个请求吗? Q2:recycle方法有多线程问题吗? 假设有5个线程在处理5个请求,这5个线程都会调用recycle方法,此时会存在并发问题吗? Q3:线程池的大小一般为多大? 有经验公式吗?
2023-12-18 - 无心 👍(0) 💬(2)
avaliable的 ture 和 false 语意是不是反了
2024-03-09 - Geek_b7bd01 👍(0) 💬(2)
为什么connector调用processor.assign()方法,这样不会导致connector线程进行等待吗?为何不直接将任务丢给processor。
2024-01-31 - Geek_b7bd01 👍(0) 💬(1)
这样connector不是必须得等待processor执行完成之后才能继续往下走吗,不影响效率吗?
2024-01-31 - ctt 👍(0) 💬(1)
HttpProcessor initprocessor = new HttpProcessor(); processors.push(initprocessor); curProcessors++; return ((HttpProcessor) processors.pop()); 请问这段代码为什么push完就立即pop了呢
2023-12-24 - C. 👍(0) 💬(2)
Tomcat 为什么用一个简单的 queue 来实现多线程而不是用 JDK 自带的线程池? 1.自定义可以更好地控制,还有后期的优化 2.历史原因,可能当时内置线程池功能没那么完善 现在,应该也支持使用JDK自带的线程池 交个作业:https://github.com/caozhenyuan/mini-tomcat
2023-12-19 - HH🐷🐠 👍(0) 💬(1)
🌝🌝自带JDK线程池初始化指定线程数, 共用这些线程, 可能这次在A线程执行, 下次在B线程执行,上下文切来切去造成性能不必要的开销,在网络中这点开销算是很大了。 只能想到这个点,不知道是否正确
2023-12-18 - 小树 👍(1) 💬(1)
想请教一下老师,实际上是不是不会有 “如果available标志为 true,Connetor 线程就继续死等”这个情况呢。 因为每个processor线程的available初始是false的,等connector接收了新连接、assign了socket、更新了available变量以后,processor才能执行;processor执行完了以后这个processor也就被回收了,又进入了新一轮的上述过程。 所以我觉得,好像永远是各个processor等待connector来执行assign,而connector实际并没有机会进入到assign里的wait()的部分?
2024-06-20 - 夙夜SEngineer 👍(0) 💬(0)
发现个不太合理的地方,newProcessor方法正确逻辑应该如下才对: private HttpProcessor newProcessor() { HttpProcessor initprocessor = new HttpProcessor(this); initprocessor.start(); processors.push(initprocessor); curProcessors++; // return ((HttpProcessor) processors.pop()); return (HttpProcessor) initprocessor; }
2025-02-11 - 夙夜SEngineer 👍(0) 💬(0)
虽然Connctor和Proccessor是两个线程了,但本质还是同步模型,感觉性能没有提升。不知道我哪里理解的不对,请指教
2025-02-11 - wild wings.Luv 👍(0) 💬(0)
老师您好,看了您的文章收获满满。其中关于并发处理请求的架构我有一些问题。由于connector和processor是一对多的关系,所以每个processor要单独维护自己的信号,connector在分配socket时,调用processor的同步块assign。但是这个同步这里的代码我好像不是很理解。connector和processor之间实际上没有”同步的生产消费关系“:首先,createProcessor处有空余的processor时才会分配给connector,所以connector并不需要等待某个processor消费完了再给他socket,当没有空余的processor时直接放弃处理(这里也是我觉得设计的不足之处)。其次,processor中的同步块也并不是等待processor处理完请求释放socket之后,才把状态设置为false,而是拿到socket之后就马上更改状态。这样做的目的我不是很清楚,也就是这样的同步机制,我没有理解到它的用处。
2024-09-12