02 初出茅庐:构造一个极简的HttpServer
你好,我是郭屹,今天我们继续学习手写 MiniTomcat,从这里开始要同步写代码了。
与MiniSpring相同,我们也会从一个最简单的程序开始,一步步地演化迭代,最终实现Tomcat的核心功能。这节课,我们就来构造第一个简单的Web服务器应用程序。结构如图所示:
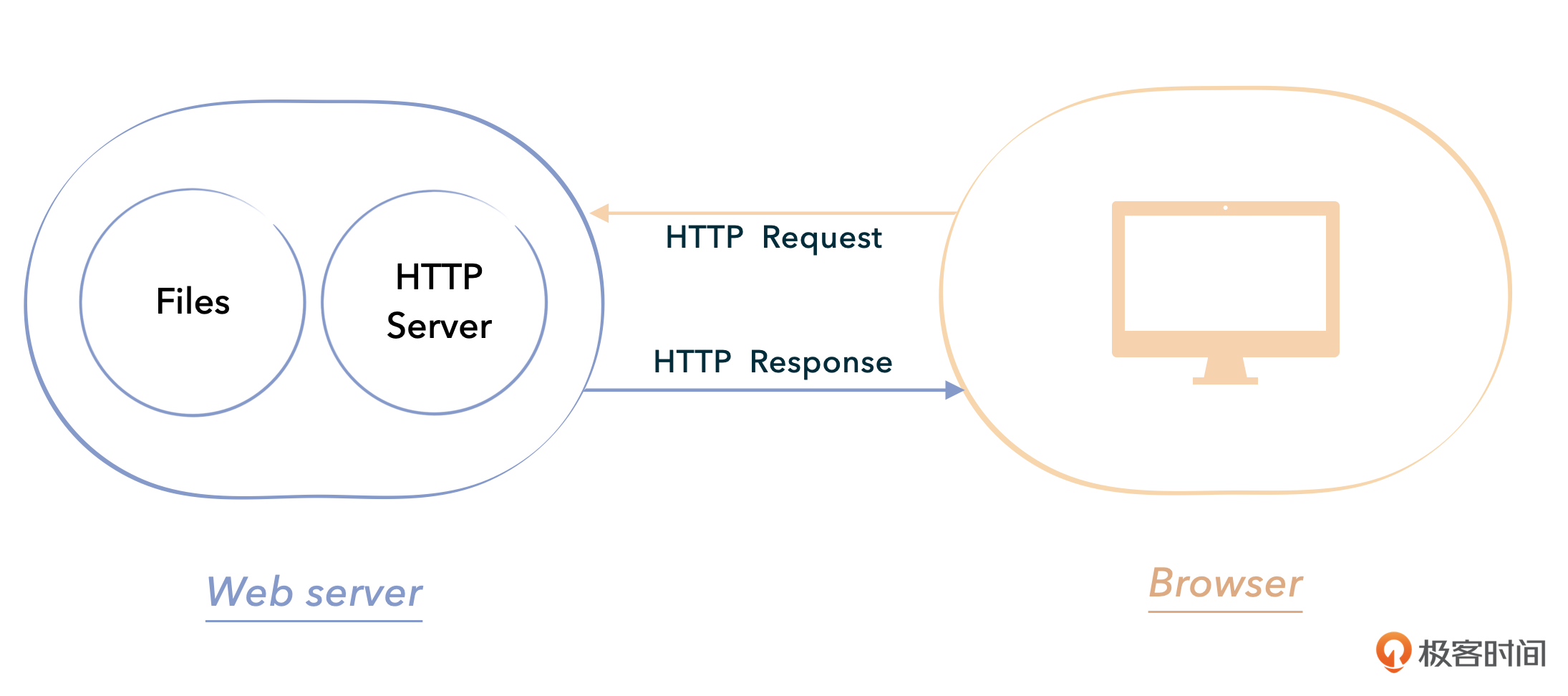
可以看出,当用户从浏览器这端发起一个静态的请求时,这个极简HTTP Server仅仅是简单地将本地的静态文件返回给客户端。这也正是我们手写MiniTomcat的第一步。
Web请求流程
一个Web服务器,简单来讲,就是要按照HTTP协议的规范处理前端发过来的Request并返回Response。在这节课中,我们计划请求 http://localhost:8080/test.txt 这个地址,实现一个最简单的Web应用服务器。
我们简单回顾一下,在浏览器中输入一个网页地址,键入回车的那一刻,从请求开始到请求结束这个过程会经历几步。
- DNS解析,将域名解析为IP地址。
- 与目标端建立TCP连接。
- 发送HTTP请求。
- 服务器解析HTTP请求并返回处理后的报文。
- 浏览器解析返回的报文并渲染页面。
- TCP连接断开。
在这个过程中,还有很多诸如三次握手,DNS解析顺序等具体技术细节,因为不是这节课的主要论题,所以这里不再详细说明。在上述Web请求流程中,我们重点关注“发送HTTP请求”“服务器解析HTTP请求并返回处理后的报文”以及“浏览器解析返回的报文并渲染页面”这三步。
项目结构
首先我们定义项目的结构,为减少阅读Tomcat实际源码的障碍,项目结构以及类的名字会仿照Tomcat源码中的定义。作为起步,在这节课中项目结构简单定义如下:
MiniTomcat
├─ src
│ ├─ server
│ │ ├─ HttpServer.java
│ │ ├─ Request.java
│ │ ├─ Response.java
├─ webroot
│ ├─ hello.txt
和应用服务器有关的代码放在 src/server 目录下,而webroot目录下目前放了一个名叫hello.txt的文本文件,这个目录下计划存放返回给浏览器的静态资源。
Request请求类
我们打开浏览器,尝试输入 http://localhost:8080/hello.txt, 看看请求参数有哪些内容。
GET /hello.txt HTTP/1.1
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7
Accept-Encoding: gzip, deflate, br
Accept-Language: zh-CN,zh;q=0.9
Cache-Control: max-age=0
Connection: keep-alive
Host: localhost:8080
Sec-Fetch-Dest: document
Sec-Fetch-Mode: navigate
Sec-Fetch-Site: none
Sec-Fetch-User: ?1
Upgrade-Insecure-Requests: 1
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Safari/537.36
sec-ch-ua: "Google Chrome";v="113", "Chromium";v="113", "Not-A.Brand";v="24"
以上是HTTP协议规定的请求标准格式。由上述内容可以看出,请求按行划分,首先可以分为两部分:第一行与其他行。第一行的内容中包含请求方法(GET)、请求路径(/hello.txt)、使用的协议以及版本(HTTP/1.1)。从第一行往下就是具体的请求头了,以Key-Value键值对的形式按行列出。一般关注较多的Key是Accept、Host、Content-Type、Authorization等。
现在我们就有了作为参考的Request示例,接下来我们就参考标准格式,对Request参数进行解析,提取我们需要的关键元素与信息。
我们定义Request.java类,用来构造请求参数对象。
package src.server;
public class Request {
private InputStream input;
private String uri;
public Request(InputStream input) {
this.input = input;
}
public void parse() {
StringBuffer request = new StringBuffer(2048);
int i;
byte[] buffer = new byte[2048];
try {
i = input.read(buffer);
} catch (IOException e) {
e.printStackTrace();
i = -1;
}
for (int j = 0; j < i; j++) {
request.append((char) buffer[j]);
}
uri = parseUri(request.toString());
}
private String parseUri(String requestString) {
int index1, index2;
index1 = requestString.indexOf(' ');
if (index1 != -1) {
index2 = requestString.indexOf(' ', index1 + 1);
if (index2 > index1) return requestString.substring(index1 + 1, index2);
}
return null;
}
public String getUri() {
return uri;
}
}
Request类中目前有两个域,一个是input,类型为InputStream,另外一个是URI,类型为String。我们希望以此接收请求来的输入流,并提取出其中的URI来。因此,Request对象必须由传入的InputStream这一输入流对类进行初始化。在Request类中,最核心的当数 parse() 方法,主要的工作都由这个过程完成。
在 parse() 方法中,主要将I/O的输入流转换成固定的请求格式(参见前面列出的请求类)。InputStream先用byte数组接收,执行 input.read(buffer) 后,input的内容会转换成byte数组,填充buffer。这个方法的返回值表示写入buffer中的总字节数(代码中的2048)。随后将byte数组的内容通过循环拼接至StringBuffer中,转换成我们熟悉的请求格式。
然后我们用parseUri方法,获取Uri。
private String parseUri(String requestString) {
int index1, index2;
index1 = requestString.indexOf(' ');
if (index1 != -1) {
index2 = requestString.indexOf(' ', index1 + 1);
if (index2 > index1)
return requestString.substring(index1 + 1, index2);
}
return null;
}
前面我们说过,HTTP协议规定,在请求格式第一行的内容中,包含请求方法、请求路径、使用的协议以及版本,用一个空格分开。上述代码的功能在于,获取传入参数第一行两个空格中的一段,作为请求的 URI。如果格式稍微有点出入,这个解析就会失败。从这里也可以看出,遵守协议的重要性。
构造服务器
在构造了HTTP请求类之后,我们来看看服务器是如何处理这个HTTP请求以及如何传输返回报文的。
在src/server目录下,定义HttpServer.java类。
package src.server;
public class HttpServer {
public static final String WEB_ROOT = System.getProperty("user.dir") + File.separator + "webroot";
public static void main(String[] args) {
HttpServer server = new HttpServer();
server.await();
}
public void await() { //服务器循环等待请求并处理
ServerSocket serverSocket = null;
int port = 8080;
try {
serverSocket = new ServerSocket(port, 1, InetAddress.getByName("127.0.0.1"));
} catch (IOException e) {
e.printStackTrace();
System.exit(1);
}
while (true) {
Socket socket = null;
InputStream input = null;
OutputStream output = null;
try {
socket = serverSocket.accept(); //接收请求连接
input = socket.getInputStream();
output = socket.getOutputStream();
// create Request object and parse
Request request = new Request(input);
request.parse();
// create Response object
Response response = new Response(output);
response.setRequest(request);
response.sendStaticResource();
// close the socket
socket.close();
} catch (Exception e) {
e.printStackTrace();
}
}
}
}
首先我们看一下 main() 方法,这也是我们整个程序的核心启动方法。
可以看到启动类很简单,实例化一个HTTP Server对象后,调用 await() 方法。随后我们看看 await() 方法内有什么奥秘吧!
public void await() {
ServerSocket serverSocket = null;
int port = 8080;
try {
serverSocket = new ServerSocket(port, 1, InetAddress.getByName("127.0.0.1"));
} catch (IOException e) {
e.printStackTrace();
System.exit(1);
}
while (true) {
Socket socket = null;
InputStream input = null;
OutputStream output = null;
try {
socket = serverSocket.accept();
input = socket.getInputStream();
output = socket.getOutputStream();
// create Request object and parse
Request request = new Request(input);
request.parse();
// create Response object
Response response = new Response(output);
response.setRequest(request);
response.sendStaticResource();
// close the socket
socket.close();
} catch (Exception e) {
e.printStackTrace();
}
}
}
从上面的代码中可以看出,这其实就是一个简单的网络服务器程序。如果你熟悉Java网络I/O的话,一眼就能看出来,整个过程就是启动了一个ServerSocket接收客户端的请求,生成Socket连接后包装成Request/Response进行处理。
我们看看具体代码。
使用ServerSocket监听8080端口,为方便测试,在这个地方直接写死127.0.0.1这个值,我们可以在本地进行测试。
通过 serverSocket.accept() 为每一个连接生成一个socket。通过 socket.getInputStream() 获取通过浏览器传入的输入流,包装成前面提到的Request对象,调用 parse() 解析URI。在这一步我们完成了对Request请求的解析工作。然后创建一个Response,通过Response输出,具体实现后面再说。最后关闭 socket.close(),中断这次TCP连接,然后程序循环,等待下一次连接。
到此为止我们就构建出了一个最简单的HTTP Server,即构建Request -> 解析 -> 构建Response输出,这样我们就模拟实现了一个最简单的Web应用服务器。现在我们还需要构造Response对象,就可以完成一次完整的HTTP交互。
Response返回对象
和构造Request请求对象一样,我们用同样的方法来构造Response返回对象,将HTTP返回对象处理成浏览器可渲染,便于用户浏览的数据。
先定义Response.java类。
package src.server;
public class Response {
private static final int BUFFER_SIZE = 1024;
Request request;
OutputStream output;
public Response(OutputStream output) {
this.output = output;
}
public void setRequest(Request request) {
this.request = request;
}
public void sendStaticResource() throws IOException {
byte[] bytes = new byte[BUFFER_SIZE];
FileInputStream fis = null;
try {
File file = new File(HttpServer.WEB_ROOT, request.getUri());
if (file.exists()) {
fis = new FileInputStream(file);
int ch = fis.read(bytes, 0, BUFFER_SIZE);
while (ch != -1) {
output.write(bytes, 0, ch);
ch = fis.read(bytes, 0, BUFFER_SIZE);
}
output.flush();
}
else {
String errorMessage = "HTTP/1.1 404 FIle Not Found\r\n" +
"Content-Type: text/html\r\n" +
"Content-Length: 23\r\n" +
"\r\n" +
"<h1>File Not Found</h1>";
output.write(errorMessage.getBytes());
}
}
catch (Exception e) {
System.out.println(e.toString());
}
finally {
if (fis != null) {
fis.close();
}
}
}
}
Response类和Request类有些类似,不一样的地方在于Response通过OutputStream输出内容。我们可以看到,现在这个Response其实只能返回静态文件数据。在 sendStaticResource() 方法中,我们的实现非常简单粗糙,就是直接把webroot下的文件内容完整地输出了。
代码如下所示:
File file = new File(HttpServer.WEB_ROOT, request.getUri());
if (file.exists()) {
fis = new FileInputStream(file);
int ch = fis.read(bytes, 0, BUFFER_SIZE);
while (ch != -1) {
output.write(bytes, 0, ch);
ch = fis.read(bytes, 0, BUFFER_SIZE);
}
output.flush();
}
我们看到,Response它就是根据解析到的URI在内部创建一个file,逐个字节读取file的内容,然后写入output里。中间并没有进行任何处理,也没有按照HTTP协议拼接格式串。也正因如此,这就需要我们自己手动在文件中写出完整的返回数据格式,在webroot下创建hello.txt。
如上所示,这个文本文件的内容就是按照HTTP规定的返回格式手工写好的。因为这是第一步,实现极简,我们先这么写,这也是后面需要优化改造的点。不过从这里我们可以感受到HTTP协议本身的简单,就是一些文本字符串的格式约定。
可以看到,返回格式和请求格式有些不一样,区别在于第一行先展示协议及其版本(HTTP/1.1)、HTTP状态码(200)与HTTP状态内容(OK)。在返回头设置完毕后空一行,显示返回体 Hello World!。
测试
在上述准备工作完毕后,在HttpServer类中运行 main() 方法,程序会在本地8080端口启动一个Socket持续监听请求。这时我们在浏览器中键入 http://localhost:8080/hello.txt,可以看到浏览器页面上返回了 Hello World!字样,说明我们的第一个HTTP服务器构建成功了,顺利返回了hello.txt中的返回体内容。
小结
这节课我们构造了第一个可运行的HttpServer。我们按照Java网络编程的规程,启动了一个ServerSocket在8080端口进行监听,对HTTP请求的传入串进行了封装,且实现了对输入串的解析,提取出了URI,并根据URI创建文件,读取文件中的内容,然后写入到outputStream中。
虽然极为简单粗糙,功能也极简,但是确实是做到响应HTTP Request -> 解析 -> 构建Response输出全闭环。当然,我们也知道,这个闭环中请求这个环节是依靠的浏览器的功能,不是我们自己实现的,响应的格式也是由用户自己在文件中写好的,不是我们的服务器完成的,后面我们再来改进。
注:由于许多学员反映GitHub从国内访问太慢甚至出现访问不了的状况,我请助手帮我将代码搬到国内的 Gitee 上来了,感谢。
思考题
学完了这节课的内容,我们来思考一个问题:我们的这个HTTP Server只能返回静态资源,没有动态内容,所以不能叫做应用服务器Application Server,那么从原理上如何将它变成一个应用服务器呢?
欢迎你把你思考后的结果分享到评论区,也欢迎你把这节课的内容分享给其他朋友,我们下节课再见!
- 猛禽不是鸟 👍(1) 💬(1)
在应用服务器中维护一个请求地址和对应处理类【方法】的映射关系,然后在parse解析出来uri之后,通过映射关系找到对应的处理方法。
2024-02-19 - 听风有信 👍(1) 💬(2)
应用服务器的话,要根据客户端的请求,然后执行相应的业务处理程序,最后将业务程序的输出返回给客户端,这种输出的内容是动态生成的。
2023-12-18 - 阿加西 👍(1) 💬(1)
参考了《How Tomcat Works》
2023-12-12 - Xiaosong 👍(0) 💬(1)
好奇为什么parseUri要写的这么麻烦,直接requestString.split(' '),检查一下length,然后 取第二个不就行了吗
2024-01-25 - 健康的小牛犊 👍(0) 💬(3)
Spring和tomcat是如何结合在一起的呢,按理说tomcat本身就可以作为一个web服务器了,那spring的作用是啥呢
2024-01-02 - Geek_50a5cc 👍(0) 💬(1)
如果将读取的文件内容,放在message里面返回过去; String Message = "HTTP/1.1 404 FIle Not Found\r\n" + "Content-Type: text/html\r\n" + "Content-Length: 23\r\n" + "\r\n" + "<h1>"+ result.toString() + "</h1>"; output.write(Message.getBytes()); 如果文件里 字符 很多的时候,这个是否都会完全输出显示出来呢; (result就是文件字节流转换的字符串)
2023-12-15 - Koyi 👍(0) 💬(1)
Request类 第13行 读取数据时,使用一个while循环判断返回值是否大于0以保证成功读取完数据是不是好些
2023-12-13 - 斜杠青年 👍(0) 💬(0)
我自己在学习 http 协议的时候,就想到了,可以直接基于字节码来进行开始到 socket 进而到 http 协议,到多路复用,异步IO,到 tomcat 的知识点串起来,但是一直没有决心进行梳理,看到这个课程如获珍宝,学会此课程可以明白理解为什么压测的时候,无论如何提升服务器规格,数据库规格,吞吐还是上不去,以及各种状态码代表什么,瓶颈在TCP层还是Tomcat层,都会得到答案。
2024-09-19 - 旷野之希 👍(0) 💬(2)
我遇到一个问题,当时随便使用了一个端口号7000,会报403 forbidden的异常,但是换一个端口,比如8888就可以正常访问hello.txt了,这可能是什么原因呢?
2024-03-07