24 标记和回收:完成对象的搬移以整理内存
你好,我是海纳。
第 22 课我给你介绍了垃圾回收的基本算法原理,第23课我们通过修改代码实现了在堆中分配虚拟机对象的功能,从而把所有的对象都放置在堆里。
然而,这些工作实际上只完成了垃圾回收器一半的工作。除了可以分配空间,垃圾回收器还有一个重要功能是回收空间。复制算法是通过把存活对象搬到幸存者空间(Survivor Space)来实现空间回收功能的。所以这一节课,我们就重点实现搬移存活对象的功能。
搬移对象
最适合完成搬移对象功能的结构就是访问者模式。我们定义一个 ScavengeOopClosure 类,它在访问每一个堆内的对象时,就可以完成对象的搬移和指针修改。
// [memory/heap.cpp]
void Heap::copy_live_objects() {
ScavengeOopClosure(eden, survivor, metaspace).scavenge();
}
// [memory/oopClosure.hpp]
class OopClosure {
public:
virtual void do_oop(HiObject** obj) = 0;
virtual void do_array_list(ArrayList<Klass*>** alist) = 0;
virtual void do_array_list(ArrayList<HiObject*>** alist) = 0;
virtual void do_array_list(ArrayList<HiString*>** alist) = 0;
virtual void do_map(Map<HiObject*, HiObject*>** amap) = 0;
virtual void do_raw_mem(char** mem, int length) = 0;
virtual void do_klass(Klass** k) = 0;
};
class ScavengeOopClosure : public OopClosure {
private:
Space* _from;
Space* _to;
Space* _meta;
Stack<HiObject*>* _oop_stack;
HiObject* copy_and_push(HiObject* obj);
public:
ScavengeOopClosure(Space* from, Space* to, Space* meta);
virtual ~ScavengeOopClosure();
virtual void do_oop(HiObject** oop);
virtual void do_array_list(ArrayList<Klass*>** alist);
virtual void do_array_list(ArrayList<HiObject*>** alist);
virtual void do_array_list(ArrayList<HiString*>** alist);
template <typename T>
void do_array_list_nv(ArrayList<T>** alist);
virtual void do_map(Map<HiObject*, HiObject*>** amap);
virtual void do_raw_mem(char** mem, int length);
// CAUTION : we do not move Klass, because they locate at MetaSpace.
virtual void do_klass(Klass** k);
void scavenge();
void process_roots();
};
这段代码定义了 ScavengeOopClosure 和它的父类 OopClosure。我们来回忆一下访问者模式,OopClosure 是访问者的接口类,所以里面定义的方法都是纯虚方法。
ScavengeOopClosure 是访问者的具体实现类,针对不同的被访问者提供了具体的访问方法。如果对象是 HiObject,就使用 do_oop 进行访问,如果对象是 Map,就使用 do_map 进行访问。
当然,具体实现类不仅仅是 ScavengeOopClosure 这一种,我们也可以通过继承 OopClosure 实现其他的 GC 算法,例如标记清除和标记压缩等。
ScavengeOopClosure 中的 _from 指针和 _to 指针,在第 22 课我们分析算法理论的时候就已经介绍过了,它们本质上只是 survivor space 和 eden space 的别名。_meta 就是 MetaSpace。
_oop_stack 是为了实现非递归的深度优先搜索而引入的。注意它的类型是 Stack,而没有使用已知的 ArrayList,或者是 HiList。
之前 Frame 对象中的操作数栈,我们就是使用了 HiList,为什么这里还要再实现一个 Stack 呢?因为无论是 HiList 还是 ArrayList,它们都是在堆里分配的,当 GC 在执行的时候,很难保证堆中的对象不受影响。所以,最简单的做法是 GC 需要使用的数据结构在堆外创建,保证在 GC 进行的过程中不在堆内分配空间。
Stack 的实现也非常简单,接口只有 push、pop 等几个,数量不多,没有动态扩展容量、查找等其他功能。当然,在一个真实场景中运行的虚拟机,栈结构动态扩容的功能是必备的,作为示例,这里我们就只提供一个最简实现。你可以看一下具体的实现代码。
template<typename V>
class Stack {
private:
V* vector;
int _capacity;
int _length;
public:
Stack(int n = 16) {
_capacity = n;
vector = new V[n];
_length = 0;
}
~Stack() {
delete[] vector;
_capacity = 0;
_length = 0;
}
void push(V v);
V pop() {
return vector[--_length];
}
V top() {
return vector[_length - 1];
}
V peek(int index) {
return vector[_length - index - 1];
}
int capacity() {
return _capacity;
}
int length() {
return _length;
}
bool empty() {
return _length == 0;
}
void copy(const Stack<V>* stack);
void oops_do(OopClosure* f);
};
scavenge 方法是整个 GC 算法的入口,是开始的地方。这个方法分两步,第一步是处理根集合。第二步是以根集合为起始,遍历整个堆中的所有存活对象。我们先来讨论一下如何处理根集合。
处理根集合(roots)
根集合 roots 是所有不在堆里指向堆内对象的引用的集合。
void ScavengeOopClosure::scavenge() {
// step 1, mark roots
process_roots();
// step2, process all objects;
while (!_oop_stack->empty()) {
_oop_stack->pop()->oops_do(this);
}
}
到目前为止,有哪些引用是 roots 里的呢?
首先,Universe 中的 HiTrue、HiFalse 等全局对象指针肯定属于 roots,同理,StringTable 中定义的字符串也可以看做是全局对象,它们也是 roots 集合中的。
另外,最重要根引用位于程序栈上,也就是 Interpreter 中使用的 Frame 对象,其中记录的局部变量表、全局变量表、操作数栈等,都有可能是一个普通的 HiObject 对象的引用,这些都属于 roots 集合。
void ScavengeOopClosure::process_roots() {
Universe::oops_do(this);
Interpreter::get_instance()->oops_do(this);
StringTable::get_instance()->oops_do(this);
}
// [runtime/universe]
class Universe {
public:
...
static CodeObject* main_code;
};
CodeObject* Universe::main_code = NULL;
void Universe::oops_do(OopClosure* closure) {
closure->do_oop((HiObject**)&HiTrue);
closure->do_oop((HiObject**)&HiFalse);
closure->do_oop((HiObject**)&HiNone);
closure->do_oop((HiObject**)&main_code);
closure->do_array_list(&klasses);
}
// [main.cpp]
int main(int argc, char** argv) {
...
Universe::genesis();
BufferedInputStream stream(argv[1]);
BinaryFileParser parser(&stream);
Universe::main_code = parser.parse();
Universe::heap->gc();
Interpreter::get_instance()->run(Universe::main_code);
return 0;
}
我们先来分析 Universe 的 oops_do 方法。
第一个需要注意的点是 CodeObject。我们知道 CodeObject 也继承自 HiObject,为了能让回收器正确地维护它,可以在 Universe 类里把它引用起来。就像代码里展示的那样,在 Universe 中增加声明和定义,在 main 方法里增加初始化。
第二,Universe 的 oops_do 是典型的访问者模式的实现,它接受一个访问者基类类型的对象作为参数,然后对自己所引用的每一个对象,都调用访问者的访问方法,也就是 do_XXX 方法。
访问者模式的优点再一次展现得淋漓尽致,访问者对于被访问者的内部结构完全不必知情,访问动作的具体实现完全由被访问者决定。由于 Universe 对自己引用了哪些对象十分清楚,所以在 oops_do 中,它分别对这些对象调用了相应类型的 do_XXX 方法。
搞清楚了这个基本的结构,我们再来分析 do_XXX 方法是如何实现的。你看一下我给出的代码。
void ScavengeOopClosure::do_oop(HiObject** oop) {
if (oop == NULL || *oop == NULL)
return;
// this oop has been handled, since it may be
// refered by Klass
if(!_from->has_obj((char*)*oop))
return;
(*oop) = copy_and_push(*oop);
}
HiObject* ScavengeOopClosure::copy_and_push(HiObject* obj) {
char* target = obj->new_address();
if (target) {
return (HiObject*)target;
}
// copy
size_t size = obj->size();
target = (char*)_to->allocate(size);
memcpy(target, obj, size);
obj->set_new_address(target);
// push
_oop_stack->push((HiObject*)target);
return (HiObject*)target;
}
do_oop 的逻辑除了一些必要的检查之外,就是调用了 copy_and_push 方法。并且把这次调用的返回值更新到 (*oop) 的位置去。
如图所示,图中展示了对象 A 从 eden 空间复制到 survivor 空间以后,(*oop) 处的指针将会指向新空间中的对象 A’。
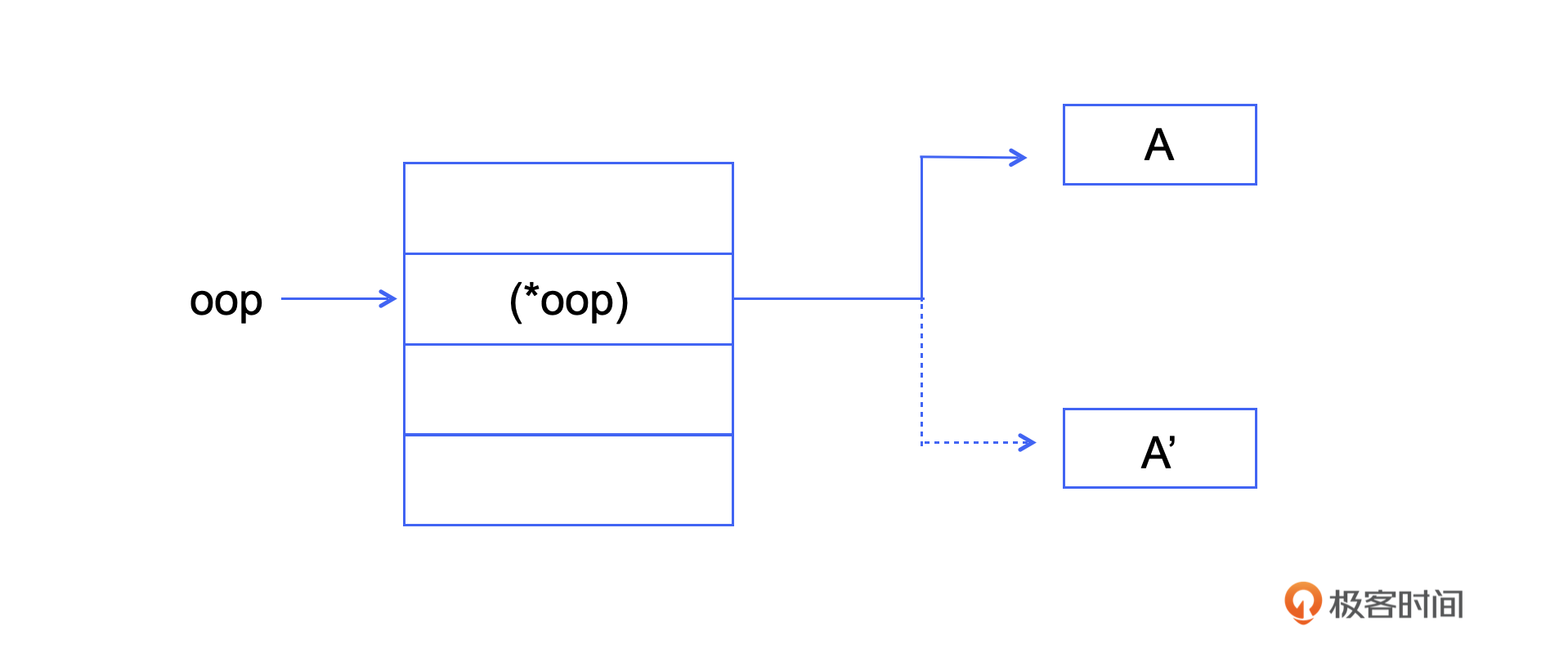
copy_and_push 这个方法主要做了三件事情。
第一,检查该对象是否已经被搬到 to 空间中了,如果已经被搬的话,那么老的位置就会留下 forwarding 指针。如果 forwarding 不为空,那就直接返回 forwarding 指针。
第二,如果该对象没有被搬到 to 空间中,就进行复制操作(第 20 至第 23 行),先取得要搬移对象的大小,然后在 to 空间中申请这样一块内存,再使用 memcpy 把对象从 from 空间搬到 to 空间中,最后把新的地址留在老的对象上。
第三,就是把这个已经搬移完的对象放到 _oop_stack 中。在深度优先搜索算法里,人们经常使用三种不同的颜色表示三种类型的结点,如果完全未被访问,就使用白色表示;如果自己已经被处理完,但是它对其他对象的引用还未被处理,就使用灰色表示,代表尚未扩展;如果自己已经被复制,并且它对其他对象的所有引用也被处理完,就使用黑色表示。
显然,在 _oop_stack 里的对象就是刚刚提到的灰色对象。
这段代码中使用了 HiObject 的 size 和 new_address 方法,我们来看下它们的具体实现。
class HiObject {
private:
long _mark_word;
Klass* _klass;
HiDict* _obj_dict;
public:
...
// interfaces for GC.
void oops_do(OopClosure* closure);
size_t size();
char* new_address();
void set_new_address(char* addr);
};
char* HiObject::new_address() {
if ((_mark_word & 0x2) == 0x2)
return (char*)(_mark_word & ((long)-8));
return NULL;
}
void HiObject::set_new_address(char* addr) {
if (!addr)
return;
_mark_word = ((long)addr) | 0x2;
}
size_t HiObject::size() {
return klass()->size();
}
请注意,我们在 HiObject 中增加了一个名为 _mark_word 的属性,而且把它放在了 HiObject 定义的开始位置,也就是偏移为 0 的位置。
在 HiObject 中添加一个域,意味着它的所有子类就都有这个域了,所以对于整型、字符串、列表、字典等类型,它们也可以使用 copy_and_push 这个方法进行复制回收。
set_new_address 方法(第 23 至 27 行)中,并没有直接把新的地址赋值给 _mark_word,而是把地址与 2 做了二进制或运算以后,再赋值。这样做是为了区分 forwarding 指针。在实现堆的时候,我们强调了对齐的问题,当时提到对齐可以保证每个对象都是 8 字节对齐的,这就决定了指向它们的指针的低 3 位就一定是 0,所以这里把从低位开始的第 2 位,置为 1 用来表示当前对象已经被搬移到了新地址。
同样的道理,在 new_address 方法中,如果发现了当前的 forwarding 不为空,就需要把这个指针的低 3 位重新置为 0,也就是和 -8 进行与操作。只有这样才能拿到新空间中相应对象的正确地址。
在代码的最后,实现了 size 方法,这个方法必须得正确实现,然后复制才能正确执行。与 HiObject 上定义的 add、sub、print 等操作类似,我们把这个明显需要多态实现的方法转移到 klass 里去了。你可以看一下相应的代码。
class Klass {
public:
...
virtual size_t size();
};
size_t IntegerKlass::size() {
return sizeof(HiInteger);
}
size_t DictKlass::size() {
return sizeof(HiDict);
}
....
在 Klass 里定义虚方法 size,然后为每一个可能被复制的类型实现它的 size 方法就可以了。这个动作很简单,但比较烦琐,因为要为所有的类型添加 size 方法。一旦某个类型没有实现,那么在执行垃圾回收的过程中,它就不能被正确地复制。
到这里,复制一个对象,并设置它的 forwarding 指针的工作就全部完成了。这些对象对其他对象的引用还没有被处理,所以它们都在 _oop_stack 中等待进一步处理。
我们再回到 process_roots 方法中来,Universe 已经处理完了,接着就要处理 Interpreter。我们看一下 Interpreter 的 oops_do 的实现。
void Interpreter::oops_do(OopClosure* f) {
f->do_oop((HiObject**)&_builtins);
f->do_oop((HiObject**)&_ret_value);
if (_frame)
_frame->oops_do(f);
}
void FrameObject::oops_do(OopClosure* f) {
f->do_oop((HiObject**)&_stack);
f->do_oop((HiObject**)&_consts);
f->do_oop((HiObject**)&_names);
f->do_oop((HiObject**)&_locals);
f->do_oop((HiObject**)&_globals);
f->do_oop((HiObject**)&_closure);
f->do_oop((HiObject**)&_fast_locals);
f->do_oop((HiObject**)&_codes);
if (_sender)
_sender->oops_do(f);
}
在 Interpreter 的实例中,只有三个指向对象的引用,所以它的 oops_do 方法里就对这三个对象分别进行访问。
有一个地方是需要特别注意的,就是 FrameObject,虽然命名上它是一个 Object,但实际上它并没有继承自 HiObject。所以我们不必复制这个对象,也就是没有使用 f->do_oop 这种方式去访问 _frame。
frame 对象的引用情况下图所示,可以看到,frame 对象的 sender 并不指向堆内,但 globals、locals 等都是指向堆内的。所以,只需要直接调用 FrameObject 的 oops_do 方法即可。
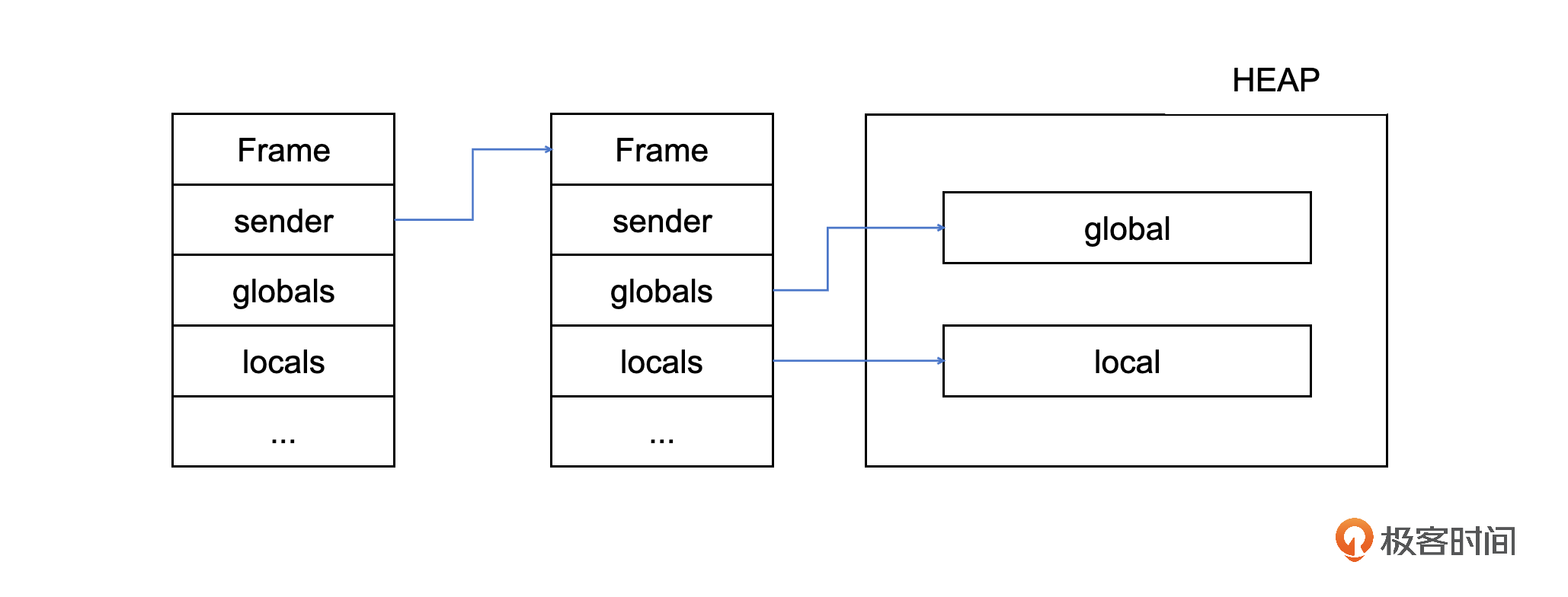
在 FrameObject 的 oops_do 方法中,OopClosure 对 FrameObject 的所有引用进行访问。当访问到 _sender 的时候,和第一次访问 FrameObject 一样,不必再使用 do_oop 进行访问,而是直接调用 _sender 的 oops_do 方法。
当 process_roots 结束以后,根对象就全部复制完了,由于它们的引用还没有完全访问完,所以它们都会被存储在 _oop_stack 中,等待被进一步处理。
处理普通对象
scavenge 方法的第二步,就是不断地从 _oop_stack 中取出对象,然后调用这个对象的 _oops_do 方法。
注意,由于这些对象自身是已经复制完了的,所以我们就不能再调用 OopClosure 的 do_oop 方法了,而是像程序中展示的那样,直接调用对象的 _oops_do 方法。
在 scavenge 方法中,调用 HiObject 的 _oops_do 方法时,我们不需要去管这个对象的实际类型是什么,它的实际类型会在 _oops_do 方法执行的时候自动决定。
void HiObject::oops_do(OopClosure* closure) {
// object does not know who to visit, klass knows
closure->do_oop((HiObject**)&_obj_dict);
klass()->oops_do(closure, this);
}
HiObject 的 oops_do 方法先访问了 _obj_dict,因为这是所有 HiObject 都具有的属性,所以放在 HiObject 的 oops_do 方法中是最合适的。
然后,就像注释所说,我们转而调用对象所对应的 klass 的 oops_do 方法。在不同的类型中,分别执行不同的逻辑。我们以字符串类型为例看一看。
class HiString : public HiObject {
private:
char* _value;
int _length;
public:
...
char** value_address() { return &_value; }
};
void StringKlass::oops_do(OopClosure* closure, HiObject* obj) {
HiString* str_obj = obj->as<HiString>();
closure->do_raw_mem(str_obj->value_address(), str_obj->length());
}
字符串类型有两个属性,一个是代表长度的整型,这个值已经随着字符串对象一起复制到 to 空间中了。现在所要做的,只是把代表字符串内容的 char 类型的数组也复制到 to 空间中。
对于普通的字符串数组,我们是使用 do_raw_mem 方法进行复制的。
void ScavengeOopClosure::do_raw_mem(char** mem, int length) {
if (*mem == NULL)
return;
char* target = (char*)_to->allocate(length);
memcpy(target, (*mem), length);
(*mem) = target;
}
do_raw_mem 的逻辑仅仅是在 to 空间中分配一块内存,然后把 from 空间中的内容复制到 to 空间中。再修改引用的内容,让它指向 to 空间中的地址即可。
其它的虚拟机内建对象,如 HiInteger、HiTypeObject、HiDict 等,实现思路和 HiString 十分相似,我们就不再展开演示了,你可以自己实现。
处理列表
在 ScavengeOopClosure 中比较有难度的是用于访问 ArrayList 的方法,也就是 do_array_list 方法。它的难点在于,ArrayList 是一个泛型类,所以对它的访问必须十分小心。我们来看一个具体的场景。
void ScavengeOopClosure::do_array_list(ArrayList<Klass*>** alist) {
do_array_list_nv<Klass*>(alist);
}
void ScavengeOopClosure::do_array_list(ArrayList<HiObject*>** alist) {
do_array_list_nv<HiObject*>(alist);
}
void ScavengeOopClosure::do_array_list(ArrayList<char>** alist) {
do_array_list_nv<char>(alist);
}
template <typename T>
void ScavengeOopClosure::do_array_list_nv(ArrayList<T>** alist) {
if (alist == NULL || *alist == NULL)
return;
assert(_from->has_obj((char*)*alist));
size_t size = sizeof(ArrayList<T>);
char* target = (char*)_to->allocate(size);
memcpy(target, (*alist), size);
(*(char**)alist) = target;
(*alist)->oops_do(this);
}
在这个场景下,ArrayList<Klass> 和 ArrayList<HiObject> 这两种类型的处理逻辑其实是一样的。所以最好办法是把 do_array_list 方法实现为泛型方法。但是由于C++ 中的虚方法不可以是模板方法,所以这里我采用一点小技巧做了一次转换。
首先,我们引入了 do_array_list_nv 这个泛型方法。它是一个非虚方法,结尾处的 nv 代表 non-virtual,表明这是一个非虚方法。处理对象的具体逻辑就在这个方法中实现。而处理 HiOjbect 列表和 Klass 列表的方法,则手动进行重载。这样就可以解决虚方法不可以是模板方法的问题。
do_array_list 的逻辑和 do_raw_mem 的逻辑很相似,都是在 to 空间中申请一块内存,把对象从 from 空间复制到 to 空间,并更新引用处的指针。
ArrayList 不是 HiObject,所以就没有 forwarding 机制,由于 ArrayList 基本都是作为 HiObject 对象的内部属性,只会被一个对象所引用,所以这也不会有什么问题。
do_array_list 的最后,还要调用 ArrayList 的 oops_do 方法,把 ArrayList 里所引用的对象全部拷贝到 to 空间中去。
template <>
void ArrayList<Klass*>::oops_do(OopClosure* closure) {
closure->do_raw_mem((char**)(&_array),
_length * sizeof(Klass*));
for (int i = 0; i < size(); i++) {
closure->do_klass((Klass**)&_array[i]);
}
return;
}
template <>
void ArrayList<HiObject*>::oops_do(OopClosure* closure) {
closure->do_raw_mem((char**)(&_array),
_length * sizeof(HiObject*));
for (int i = 0; i < size(); i++) {
closure->do_oop((HiObject**)&_array[i]);
}
}
在 ArrayList 中,我们除了要把数组通过 do_raw_mem 复制到 to 空间,还要再遍历数组 _array,把其中的元素都访问一遍。
需要注意的是,由于 ArrayList 类本身是一个模板类,元素类型是 Klass 指针与元素类型是 HiObject 指针,所使用的方法是不一样的(注意比较第 7 行和第 18 行)。所以我们必须使用模板偏特化的技巧来实现这两个方法。这已经是我们第二次使用模板偏特化来处理类型不相同的时候不同逻辑了,上一次是在第 15 课处理字典的遍历问题时使用的。
针对列表的垃圾回收改造完成以后,我们再来看字典的。
处理map
字典中所使用的 Map 类型和 ArrayList 的道理是一样的,而且更简单,因为我们只用到了一种实例的 Map,那就是 Map<HiObject*, HiObject*>。
// [memory/oopClosure.cpp]
void ScavengeOopClosure::do_map(Map<HiObject*, HiObject*>** amap) {
if (amap == NULL || *amap == NULL)
return;
assert(_from->has_obj((char*)*amap));
size_t size = sizeof(Map<HiObject*, HiObject*>);
char* target = (char*)_to->allocate(size);
memcpy(target, (*amap), size);
(*(char**)amap) = target;
(*amap)->oops_do(this);
}
// [util/map.cpp]
template <typename K, typename V>
void Map<K, V>::oops_do(OopClosure* closure) {
closure->do_raw_mem((char**)(&_entries),
_length * sizeof(MapEntry<K, V>));
for (int i = 0; i < _size; i++) {
closure->do_oop(&(_entries[i]._k));
closure->do_oop(&(_entries[i]._v));
}
}
这段代码的逻辑相对比较简单,你可以自己研究一下,这里就不再讲解了。
除此之外,还有处理 Klass 相关的实现,这里留给你自己动手实现,你可以拿它来练手。
处理虚拟机栈帧中的引用
如果在虚拟机栈帧里(即 C++ 代码所创建的栈帧)引用了堆中的对象,在这个对象的生命周期中发生了垃圾回收,这个对象的引用就没办法被正确维护。我们来看一个例子。
void FrameObject::initialize(FunctionObject* func,
HiList* args, HiList* kwargs) {
// .....
// 处理闭包中的cell vars
HiList* cells = _codes->_cell_vars;
if (cells && cells->length() > 0) {
_closure = HiList::new_instance();
for (int i = 0; i < cells->length(); i++) {
_closure->append(nullptr);
}
}
// ...
}
当程序执行到第 7 行的时候,cells 变量所对应的指针会出现在 initialize 函数的栈帧,并且指向堆中。如果这时堆的空间不足以再创建一个列表,就会发生垃圾回收。
可是,由于垃圾回收器并不知道堆上还有这样一个指针,所以在进行对象搬移的时候,就会遗漏,这就是活跃对象的漏标。当垃圾回收结束以后,再访问 cells 变量的时候就会发生严重的错误,因为 cells 所指向的位置已经被垃圾回收器清空了。
为了解决这个问题,我们就需要使用一种机制,把生命周期会跨越垃圾回收的指针变量记录下来,并通知垃圾回收器及时正确地维护这个指针。为此,我们引入了 Handle 类型,以双向链表的方式把所有的指针变量记录下来。你可以看一下Handle 的定义。
class LinkedList {
friend class HandleMark;
private:
LinkedList* _next;
LinkedList* _prev;
public:
LinkedList();
virtual void oops_do(OopClosure* f) = 0;
};
template <typename T>
class Handle : public LinkedList {
protected:
T _value;
public:
Handle(T t);
Handle(const Handle<T>& t);
~Handle();
virtual void oops_do(OopClosure* f);
T operator ->();
T operator ()() { return _value; }
operator T() { return _value; }
void operator =(T v) { _value = v; }
void operator =(Handle<T>& v) { _value = v(); }
bool operator ==(Handle<T>& v) { return _value == v(); }
bool operator ==(T v) { return _value == v; }
bool operator !=(Handle<T>& v) { return _value != v(); }
bool operator !=(T v) { return _value != v; }
};
class HandleMark {
private:
static HandleMark* instance;
LinkedList* _head;
public:
HandleMark();
static HandleMark* get_instance();
void oops_do(OopClosure* f);
LinkedList* head() { return _head; }
void set_head(LinkedList* x);
void del_handle(LinkedList* x);
};
其中,Handle 的定义看上去很像一个智能指针,支持括号操作符、箭头号操作符等等。
在它的构造函数里,会把自己添加到 HandleMark 的 _head 变量所记录的双向链表中。你可以看一下它的具体实现。
void HandleMark::set_head(LinkedList* node) {
if (_head) {
_head->_prev = node;
}
node->_next = _head;
_head = node;
}
void HandleMark::del_handle(LinkedList* node) {
LinkedList* prev = node->_prev;
LinkedList* next = node->_next;
if (prev) {
prev->_next = next;
}
if (next) {
next->_prev = prev;
}
if (_head == node) {
_head = next;
}
}
template<typename T>
Handle<T>::Handle(T t) : LinkedList() {
_value = t;
HandleMark::get_instance()->set_head(this);
}
template<typename T>
Handle<T>::Handle(const Handle<T>& t) : LinkedList() {
_value = t._value;
HandleMark::get_instance()->set_head(this);
}
template<typename T>
Handle<T>::~Handle() {
_value = 0x0;
HandleMark::get_instance()->del_handle(this);
}
set_head 方法的作用是把一个新的结点加入到链表中,而且每次都是添加到链表的头上。del_handle 方法则用于从双向链表中删除一个结点。这是非常常见的双向链表操作。
在 Handle 的构造函数(第 26 至 30 行)和复制构造函数(第 32 至 36 行)中,会把自己添加到双向链表。而析构函数(第 38 至 42 行)则负责从链表中删除。
最后,再通过 HandleMark 遍历链表里的所有元素,让垃圾回收器可以正确地维护 Handle 中所记录的指针。
void HandleMark::oops_do(OopClosure* f) {
LinkedList* cur = _head;
while (cur) {
cur->oops_do(f);
cur = cur->_next;
}
}
通过这种方式,虚拟机栈帧的引用就都可以被正确地维护了。最后,可以通过以下用例来测试我们这个 GC 算法的可靠性,你可以调整一下堆的大小,然后观察这个程序的输出情况以及性能变化情况。
到这里,我们就为虚拟机实现好了 GC。这个复制算法是比较基础的,自动内存管理还有很多优秀的算法,你可以尽情地尝试实现。我们使用访问者模式构建的这一套 GC 的框架,未来扩展非常方便。
总结
第 23 课我们介绍了复制算法的基本步骤,这一节课就聚焦于代码实现。实现复制算法主要主要有四步。
- 处理根集合。把 Universe、FrameObject 中的引用做为根,对它们所引用的对象都进行搬移,并且把这些对象放入栈中。
- 对栈中的对象进行非递归的深度优先遍历,从而把所有的活跃对象都搬移到新空间中去。
- 使用 forwarding 指针解决多个对象引用同一个对象的情况。
- 使用 Handle 记录虚拟机栈帧上的引用。
完成了这些步骤,垃圾回收的功能就基本完备了。
思考题
请你从代码实现的层面比较复制算法和引用计数法各自的优劣,欢迎你把你总结出的内容分享到评论区,也欢迎你把这节课的内容分享给需要的朋友,我们下节课再见!
- ifelse 👍(0) 💬(0)
学习打卡
2024-11-08 - Geek_66a783 👍(0) 💬(0)
我认为class LinkedList还可以进行进一步的抽象封装(类似于Linux kernel中提供的struct list_head),这样后续虚拟机中如果还需要添加其他基于链表的功能,就非常方便省事了。 以下是我的实现: #include <iostream> #include <cassert> class LinkedList { private: LinkedList* _prev; LinkedList* _next; public: LinkedList() { _prev = _next = this; } ~LinkedList() = default; void insert_between(LinkedList* prev, LinkedList* next) { assert(prev != nullptr); assert(next != nullptr); prev->_next = this; next->_prev = this; this->_prev = prev; this->_next = next; } void add_before(LinkedList* other) { assert(other != nullptr); assert(other->_prev != nullptr); insert_between(other->_prev, other); } void add_after(LinkedList* other) { assert(other != nullptr); assert(other->_next != nullptr); insert_between(other, other->_next); } void del() { assert(_prev != nullptr); assert(_next != nullptr); _prev->_next = this->_next; _next->_prev = this->_prev; } inline LinkedList* next() { return _next; } inline LinkedList* prev() { return _prev; } template<class T> inline T as() { return static_cast<T>(this); } }; class MyNode : public LinkedList { public: int value; MyNode(int v) : value(v) {} }; int main() { LinkedList head; for (int i = 0; i < 10; ++i) { MyNode* cur_node = new MyNode(i); cur_node->as<LinkedList*>()->add_before(&head); } LinkedList* cur = &head; while ((cur = cur->next()) != &head) { MyNode* cur_node = cur->as<MyNode*>(); std::cout << cur_node->value << std::endl; } cur = head.prev(); while (cur != &head) { MyNode* cur_node = cur->as<MyNode*>(); std::cout << cur_node->value << std::endl; cur = cur->prev(); delete cur_node; } }
2024-09-22 - Geek_66a783 👍(0) 💬(0)
直接把Universe 中的 HiTrue、HiFalse还有stringtable中的字符串常量在分配内存的时候直接放到meta区,会不会更合理?
2024-09-21 - Geek_66a783 👍(0) 💬(0)
如果在python虚拟机中也引入v8那样的small integer的概念,应该就能从根本上避免文章中最后一个测试代码那样的频繁gc了吧
2024-09-21