22 自动内存管理:把程序员从内存缺陷的海洋里解放出来
你好,我是海纳。
在前边的课程中,我们对于对象的创建和释放是比较随意的,完全没有理会内存泄漏的问题。现在,虚拟机的大部分功能都已经搭建完了,是时候回过头来解决这个问题了。
之前,我曾提到过,解释器并不知道一个对象从操作数栈上拿出来以后,是不是还在其他地方被引用着(例如全局变量表等),所以就无法武断地使用 delete 来释放一个对象。为了解决这个问题,这节课我们就引入自动内存管理技术。
自动内存管理
自动内存管理的研究开始得比较早。上个世纪60年代,就已经有很多优秀的成果了。经过不断发展,直到今天,自动内存管理技术仍然是一个很热门也很重要的研究方向,每年都有不同的改进在各种会议上被提出来,在各种带有自动内存管理的编程语言社区里(如Java、Go),这也是一个大家普遍关心的技术点。
在研究自动内存管理算法的时候,人们经常把不存活的对象叫做垃圾(Garbage),所以自动内存管理技术在很多时候也被大家叫做垃圾回收技术(GC, Garbage Collection)。
GC算法中最重要的两个角色就是Mutator和Collector。
- Mutator
Mutator的本义是改变者。这个词所表达的是通过程序来改变对象之间的引用关系。因为我们所写的所有 Python 代码,都有可能改变对象的存活和死亡状态,以及它们之间的引用关系,那么这些 Python 代码就是Mutator。
在多线程场景中,这些代码往往运行在业务线程中,所以在某些情况下,Mutator和业务线程这两个术语是可以混用的。在这节课中,我们使用Mutator这个术语。
- Collector
Collector用于回收空间中的垃圾,所以叫做收集者。根据不同的GC算法,Collector的作用不仅仅是收集,比如在Mark-Sweep中,它还负责标记存活对象、识别垃圾对象。执行Collector的线程,一般叫做Collector线程或者GC线程。在某些GC算法中,业务线程也有可能帮助做垃圾回收的工作。所以,Mutator和Collector只是一种相对的说法,而不是精确的概念。
此外我们还需要理解堆的概念。由编程语言虚拟机管理起来的内存统称为虚拟机堆,在 Python 这个场景中,人们就会简称为 Python 堆,便于和进程堆进行区分。
进程堆是指进程中可以使用malloc和free进行分配和释放的一块用户态内存区域。而 Python 堆则专指创建普通 Python 对象的地方,这一段内存是由虚拟机所管理的。
最后一个要深入理解的概念是栈。函数调用的时候,虚拟机会不断地创建函数栈帧,每一层调用对应一个栈帧,这部分内存是栈空间。mutator 其实就活跃在这些内存空间里。你可以结合第 8 节课的内容,深入理解栈的概念。
明确了这些概念以后,我们就可以学习 GC 算法并从中找一个最合适的,然后实现它,让它帮我们把虚拟机里的内存全部掌管起来。
引用计数算法
我们介绍的第一种垃圾回收算法是引用计数。引用计数法是实现起来最简单的GC算法。在流行的编程语言中,CPython 虚拟机以及 swift 里都使用了引用计数法。
GC 算法一个重要的功能是要识别出内存中的哪些对象是垃圾。从定义来看,所谓垃圾对象,就是不再被其他对象所引用的对象。从这个定义出发,我们可以想办法统计一个对象是否被引用。如果它被引用的次数大于0,那它就是一个活跃对象;如果它被引用的次数为0,那它就是一个垃圾对象。
为了记录一个对象有没有被其他对象引用,我们可以在每个对象的头上添加一个叫做计数器的东西,用来记录有多少其他对象引用了它。Mutator在执行的时候会改变这个计数值,你可以看一下示例代码。
执行到第三行的时候,它的引用关系就是这样的:
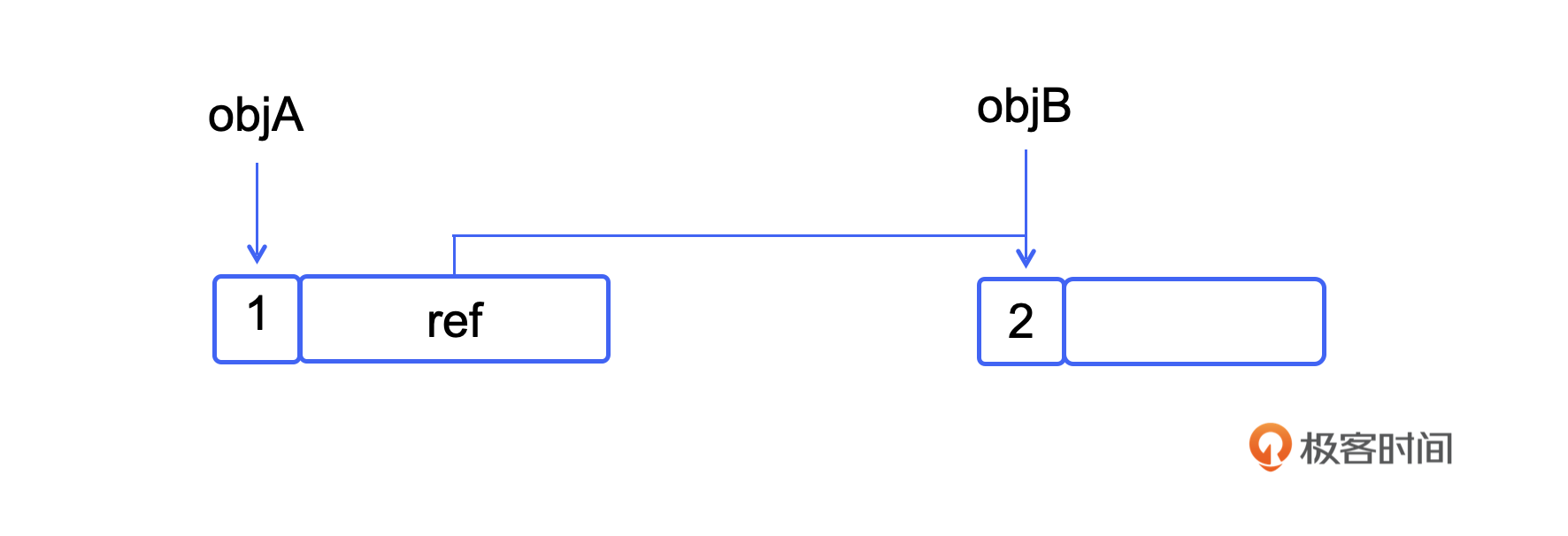
在这段代码中,第1行创建了一个对象,我们记为对象a,objA这个变量指向对象a,所以这个对象的引用计数就是1。第2行创建了一个B对象,记为对象b,objB变量指向对象b,这个时候,它的引用计数为1;第3行objA的ref属性也指向对象b,所以对象b的引用计数最终是2。
Mutator在运行中还会不断地修改对象之间的引用关系,我们知道这种引用关系的变化都是发生在赋值的时候。比如,接着上面的例子,我们再执行这样一行代码:
那么从objA到objB的引用就消失了,也就是图里那个从A的ref指向B的箭头就消失了。
以Python为例,赋值语句最终会被翻译成 STORE_XX 指令,那么我们就可以在执行 STORE 指令的时候,做一些手脚了。如果使用伪代码表示出来,就是这样的:
void do_oop_store(Value * obj, Value value) {
inc_ref(&value);
dec_ref(obj);
obj = &value;
}
void inc_ref(Value * ptr) {
ptr->ref_cnt++;
}
void dec_ref(Value * ptr) {
ptr->ref_cnt--;
if (ptr->ref_cnt == 0) {
collect(ptr);
for (Value * ref = ptr->first_ref; ref != null; ref=ref->next)
dec_ref(ref);
}
}
也就是说,在把 value 赋值给 obj 这个指针之前,我们可以先改变一下这两个对象的引用计数。
上面的代码展示了在把 value 赋值给 obj 这个指针之前,我们必须先改变两个对象的引用计数。一个是obj指针原来指向的对象,它的引用计数要减一,另一个是value对象,它的引用计数加一。如果某个对象的引用计数为0,就把这个对象回收掉,然后把这个对象所引用的所有对象的引用计数减1。注意,collect方法负责回收内存,根据GC算法的不同,collect的实现会有所不同,所以这里我们只要知道它的功能即可,不必在意它的实现。
我们在写一个对象的域的时候做了一些工作,就好比在更新对象域的时候,对这个动作进行了拦截。所以,GC中对这种特殊的操作起了一个比较形象的名字叫write barrier。这里的barrier是屏障、拦截的意思,中文翻译就是写屏障。
那在do_oop_store里,可不可以先做减,后做加呢?就是说第2行和第3行的先后顺序换过来有没有影响呢?答案是不行。因为当obj和value是同一个对象的时候,如果先减后加的话,这个对象就会被回收,内存有可能会被破坏。那么,这个对象就有可能发生数据错误。
到这里,引用计数算法的基本原理就讲完了。接下来,我们分析一下这种GC算法有什么样的优缺点,这样我们就能知道它适合用在什么场景中了。
从算法描述中容易推断出来,引用计数可以立即回收垃圾。因为每个对象在被引用次数为0的时候,是立即就可以知道的,所以一旦一个对象成为垃圾,它将立即被释放。此外,引用计数没有暂停时间。对象的回收根本不需要另外的GC线程专门去做,业务线程自己就搞定了,所以引用计数算法不需要停顿时间。
同时,引用计数也存在一些缺点。比如在每次赋值操作的时候都要做额外的计算。在多线程的情况下,为了正确地维护引用计数,需要同步和互斥操作,这往往需要通过锁来实现,这会给多线程程序性能带来比较大的损失。
其次,会有链式回收的情况。比如多个对象对链表形式串在一起,它们的引用计数都为1,当链表头被回收时,整个链表都会回收,这可能会导致一次回收所使用的时间过长。
另外,引用计数还容易引起循环引用的问题。如果 objA引用了objB,objB也引用了objA,但是除此之外,再没有其他的地方引用这两个对象了,这两个对象的引用计数就都是1。这种情况下,这两个对象是不能被回收的。如果说上面两条缺陷还可以克服的话,那么循环引用就是比较致命的。
在使用引用计数算法进行内存管理的语言中,比如Python和Swift,都会存在循环引用的问题。Python在引用计数之外,另外引入了三色标记算法,保证了在出现循环引用的情况下,垃圾对象也能被正常回收。
为了系统性地解决循环引用的问题,一类基于引用追踪的垃圾回收算法便应运而生了。
基于引用追踪的垃圾回收算法
接下来,我们重点关注垃圾回收的另外一个大类,也就是基于引用追踪的垃圾回收算法,简称Tracing GC。这类算法的特点是以根集合(root sets)作为起始点进行图的遍历,如果从根集合到某个对象是可达的,那么这个对象就叫做可达对象,也就是还活着的对象,否则就是不可达对象,可以被回收。
可以说主流的垃圾回收器都全部或者部分地使用了 Tracing GC,比如Hotspot、CPython、V8、ART等等。
我们在讨论 GC 算法时,都会遇到根集合这个概念。根集合是 GC 算法开始的地方,是指向对象的指针的起始点。在垃圾回收算法开始的时候,我们明确地知道某个对象是存活的,那它就可以认为是一个根对象。比如,所有的 FrameObject 就肯定是活跃对象,虚拟机的各种内建类型对象也是活跃对象,所以它们就应该被加入到根集合里。
根集合可以这样定义:所有不在堆里,指向堆内对象的引用的集合。我们来看个具体的例子。
在这个例子中,当虚拟机执行到 buildObj 函数的时候,objA、objB、objC 在内存中的实际情况,你可以看一下示意图。
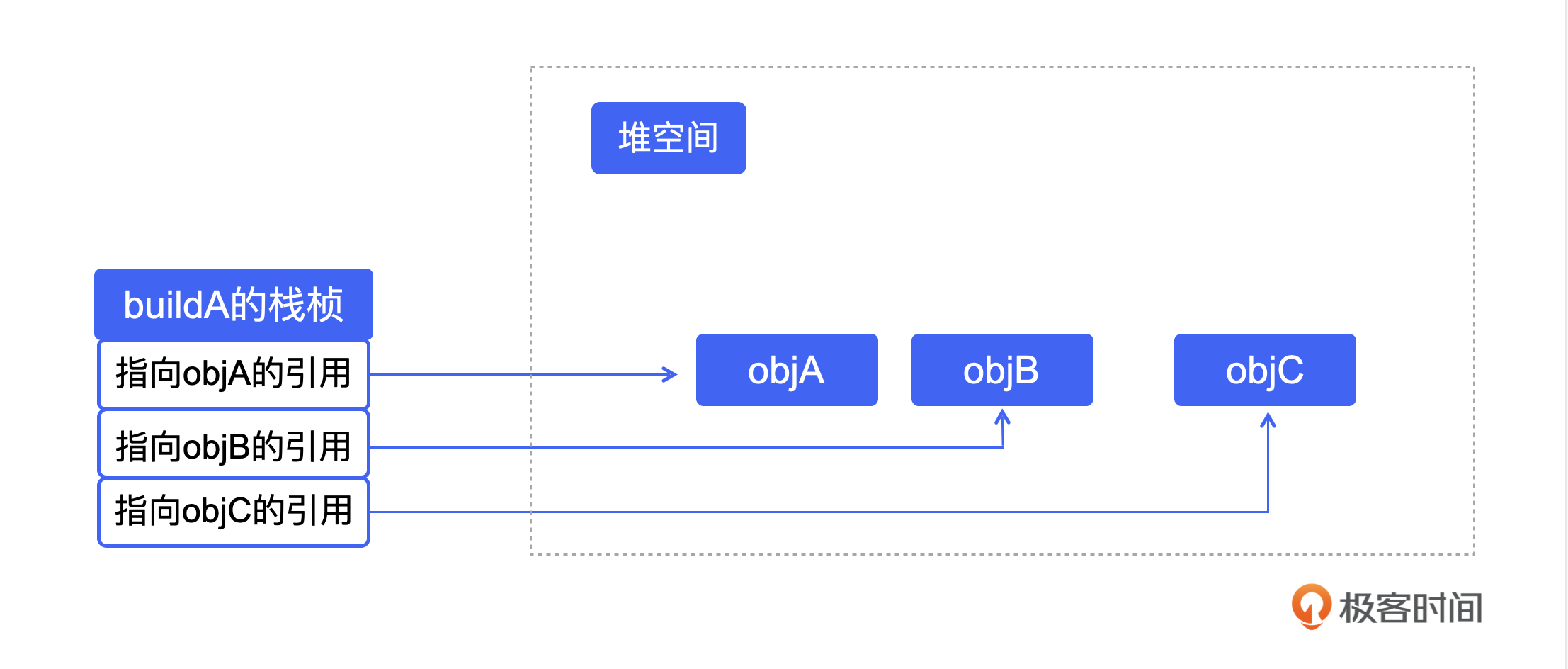
左边代表了栈空间,从栈上出发有三个指针指向堆里。前面我们已经解释过,栈里的对象都是活跃对象,所以从栈上出发,指向堆里的引用,就应该被放到根集合中。从根集合开始进行深度优先搜索,所有可以访问到的对象都是活跃对象,而访问不到的对象就是垃圾了,需要及时释放掉。
当 buildObj 执行完了以后,buildObj 所对应的栈空间就全部被回收掉了,也就是说图里的三个指针都消失了,那么堆里的这些对象,也就是 objA、objB、objC 就再也访问不到了。
Mark-Sweep 算法是 Tracing GC 的一个典型的算法。接下来,我就以这个算法为例来讲解 Tracing GC 的具体思路。就像它的名字所指示的,这个算法分为标记和清除两个步骤。
- 标记(Mark)
标记就是从根集合出发,根据对象之间的引用关系在整个图中进行搜索,能访问到的对象就标记为活跃的。基于此,我们就为每个对象添加一个额外的域来记录这个对象是否存活。
搜索的过程可以是深度优先遍历,也可以是广度优先遍历。等到遍历结束的时候,所有存活的对象就都被标记过了,而所有的不可达对象,也就是变成垃圾的对象都没有被标记。
这就是 Tracing GC 的标记阶段。这部分的核心在于对象图的遍历。
- 清除(Sweep)
清除阶段的主要任务是回收未标记的那些对象所占的空间。具体来说,看下面这张图,假如灰色的对象都是存活对象,而白色的对象都是垃圾。那么我们该怎样回收这两块空间呢?
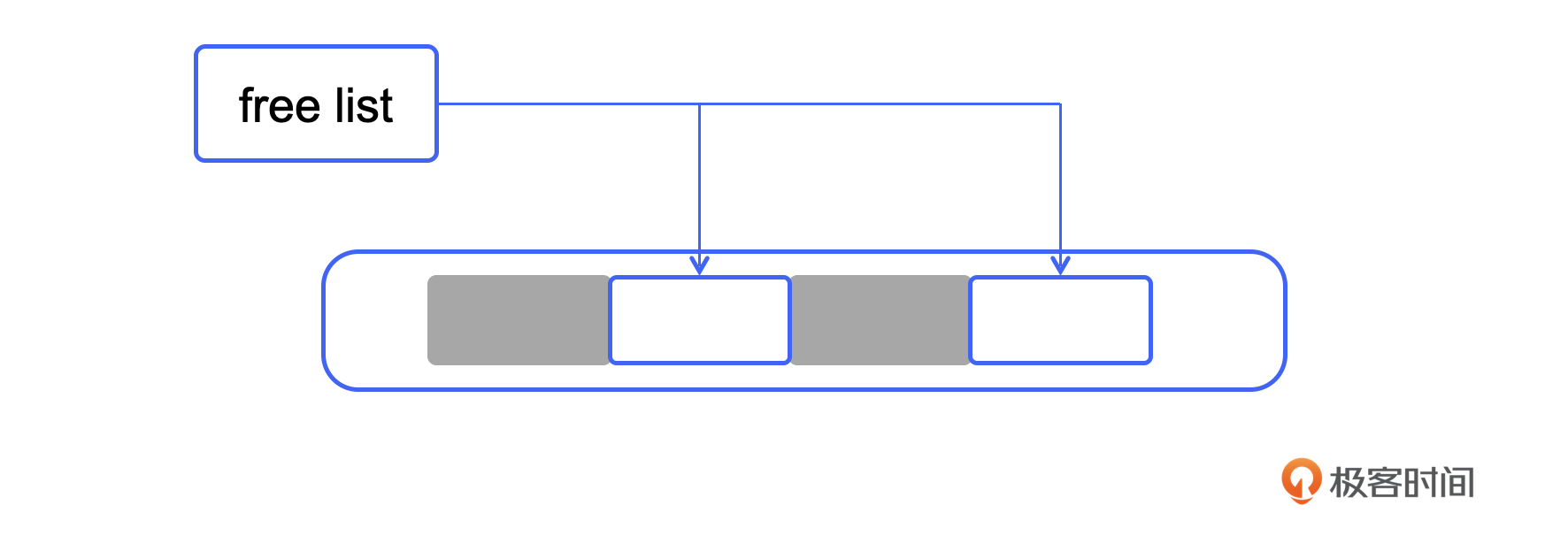
维护这个信息最合适的数据结构应该就是链表了。在清除的阶段,我们从头开始逐个访问对象,如果一个对象被标记了,那就什么也不做(当然,要把标记信息清除一下,以备下一次 GC 时可用)。如果一个对象未被标记,例如图里的两个白色对象,那就把它们的起始地址和大小记录到一个链表中去就可以了。由于这个链表记录了未使用的空间,所以它有一个专门的名字叫 freelist。
这个算法,可以用以下伪代码来描述。
sweep() {
p = heap_start;
while (p < heap_end) {
if (p.is_mark())
p.clear_mark();
else
collect(p);
p += p.size();
}
}
collect(obj) {
last_free_chunk = free_list.last_chunk();
if (last_free_chunk.end() == obj)
last_free_chunk.inc_size(obj.size());
else
free_list.add_chunk(new chunk(obj, obj.size()));
}
collect 函数会把一块不使用的内存放到链表里,如果这块内存与链表中的最后一项靠在一起,也就是说有连续的两个对象一起被回收了,那就只要相应地增加 free_chunk 的 size 就可以了,这样就可以把两个对象的空间合并在一起。如果是分离的,那就再创建一个新的chunk,挂到链表中。
最后,我们再看一下对象的分配的问题。由于堆里未使用的空间都使用freelist管理起来了。在创建对象的时候去堆里分配内存,就需要去空闲链表中找一块可用的空间,分配给这个新的对象。
在找可用空间的时候,又有几种常见的策略。
- 遍历链表,找到第一块size大于或等于所需空间的,就立即返回这块chunk。这种方式叫做first-fit。
- 从链表中找到符合条件的所有chunk,并从中挑选最小的那个。这种方式叫做best-fit。
- 从链表中找到符合条件的所有chunk,并从中挑选最大的那个。这种方式叫做worst-fit。
这三种方式在某些特定情况下都会有比较好的表现,但并不能满足所有情况。关于这三种算法的优劣我们就不具体深入讨论了,欢迎你在评论区交流。
通过刚刚的分析我们知道 Mark-Sweep 算法的内存分配相对复杂。另外,Mark-Sweep 还有一个比较大的缺点,就是内存的碎片化。你可以看一下示意图。
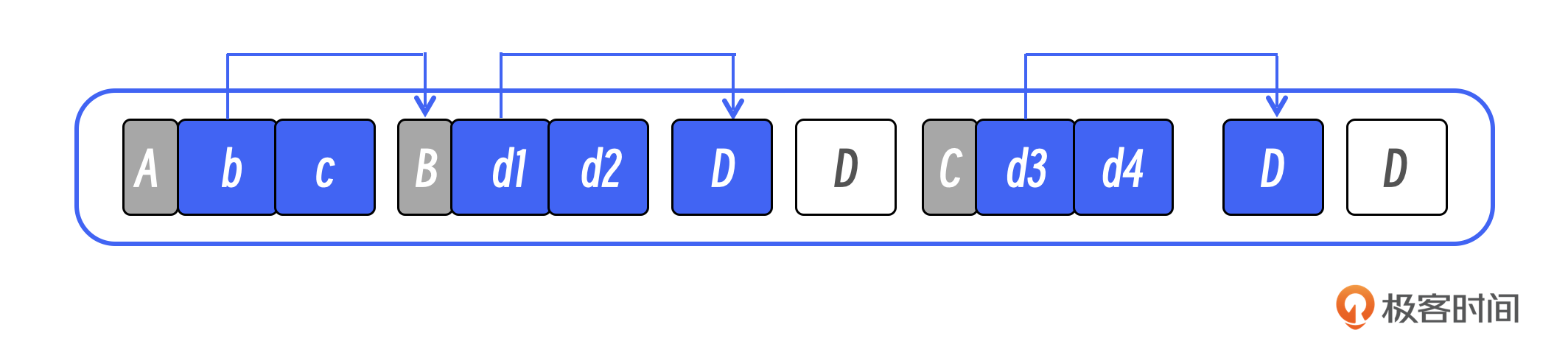
假如现在 D 对象的大小为 2,这个空间内的空闲大小就是 4。如果现在要新建一个大小为 3 的对象,其实是放不下的,因为这两块空闲空间并不连续。虽然总的空闲空间是 4,但却无法分配出一块连续的大小为 3 的空间。这就造成了内存空间的浪费。
针对这两个缺点,下节课我将重点介绍一种可以解决这两个问题的算法,那就是复制算法。而复制算法也是我们的虚拟机最终所选择的算法。
总结
这节课我们介绍了自动内存管理,也就是垃圾回收算法的基础概念,带你理解了自动内存管理的基本思路。其中有几个非常重要的概念,我们来回顾一下。
- Mutator,所有会修改对象之间的引用关系的代码都可以被叫做 Mutator。
- Collector,负责回收对象,释放内存。
- 引用计数算法,通过记录有多少对象引用了本对象,来确定某个对象是否是垃圾对象。
- 循环引用,两个对象相互引用对方,且无其他活跃对象再引用它们,它们的引用计数都是 1,这将导致这两个对象无法释放。
- 基于 Tracing 的垃圾回收,使用图遍历的方式对全体对象进行遍历,能够到达的对象就是活跃对象,不能到达的就是垃圾对象。
- Mark-Sweep 算法,典型的两阶段垃圾回收算法,使用 freelist 维护空闲区域。分配时从 freelist 中找到可用区域,标记阶段使用深度优先算法对可达对象进行标记,回收阶段将不可达对象的内存区域再交还给 freelist 管理。
这节课我们分析了主流的垃圾回收算法的思想,下一节课我会重点介绍另外一个基于 Tracing 的垃圾回收算法,来解决 Mark-Sweep 算法的缺陷。
思考题
为了解决循环引用问题,人们提出了很多改进算法,这样引用计数算法也可以用于商用工程中,你知道有哪些解决循环引用的方法吗?欢迎你把你的解决方案分享到评论区,也欢迎你把这节课的内容分享给其他朋友,我们下节课再见!
- 冯某 👍(0) 💬(0)
记录一下
2024-12-10 - ifelse 👍(0) 💬(0)
学习打卡
2024-11-06 - 骨汤鸡蛋面 👍(0) 💬(0)
从之前文章提到, python 代码上新建一个对象往往意味着在解释器c++ 层面有一个对应的HiObject,那么 1. new HiObject(xx) 如何让其使用的内存就是free list里的内存呢?或者说如何基于free list分配的内存创建HiObject对象。 2. new HiObject(xx) 之后,其使用的内存脱离free list的管理,是不是可以认为没有一个类似free list专门的内存结构 来维护HiObject的内存,也就是已经分配出去的内存,只是说这些HiObject对象都可以被 roots 遍历到,所以可以认为 对象引用关系图同时也是已分配内存的串联图?
2024-07-17