21 继承和多态:完善面向对象编程的两大特征
你好,我是海纳。
封装、继承和多态是面向对象编程的三大特征。从第 18 课开始,我们专注于构建类的定义和对象初始化能力,也就是说,只是完成了封装这一特征,这一节课,我们就会进一步实现方法重载和复写,以及类的继承特征。
第 20 课中我们介绍了操作符的重载,Python 除了可以对操作符进行重载之外,还可以对各种特殊方法进行重载。接下来,我们实现方法的重载。
内建方法重载
Python 里有很多内建方法,比如 len 方法、pow 方法等。len 方法可以支持字符串、列表、字典等类型。如果想让 len 方法也支持自建类型,就必须为自定义类型添加 __len__ 方法的实现,例如:
class Vector(object):
def __init__(self, x, y):
self.x = x
self.y = y
def __add__(self, v):
return Vector(self.x + v.x, self.y + v.y)
def __len__(self):
return self.x * self.x + self.y * self.y
print(len(Vector(3, 4)))
print(len("hello"))
为任意对象增加 len 方法,步骤和增加 add 方法是一样的。
第一步,在 HiObject 类中增加 len 方法,并实现为调用对应 _klass 的 len 方法。
// vm/runtime/interpreter.cpp
_builtins->put(new HiString("len"), new FunctionObject(object_len));
// vm/runtime/functionObject.cpp
HiObject* object_len(HiList* args, HiDict* kwargs) {
return args->get(0)->len();
}
// vm/object/hiObject.cpp
HiObject* HiObject::len() {
return klass()->len(this);
}
第二步,在 Klass 类中尝试调用 __len__ 方法。下面的代码直接使用上节课所定义的 find_and_call 方法就可以很轻松地实现这个功能。
第三步,同步修改内建的字符串类、字典类、列表类的 len 方法。这里只列出了字符串类的实现。字典和列表也实现得也差不多,这里就不再赘述了。
经过了以上修改,前面的测试用例就可以顺利执行了。测试用例的最后,可以正确地打印二维向量的长度。
除了 len 之外,我还列出了其他几个方法,这些方法都会自动对应自定义类型里的特定方法,你可以看一下。
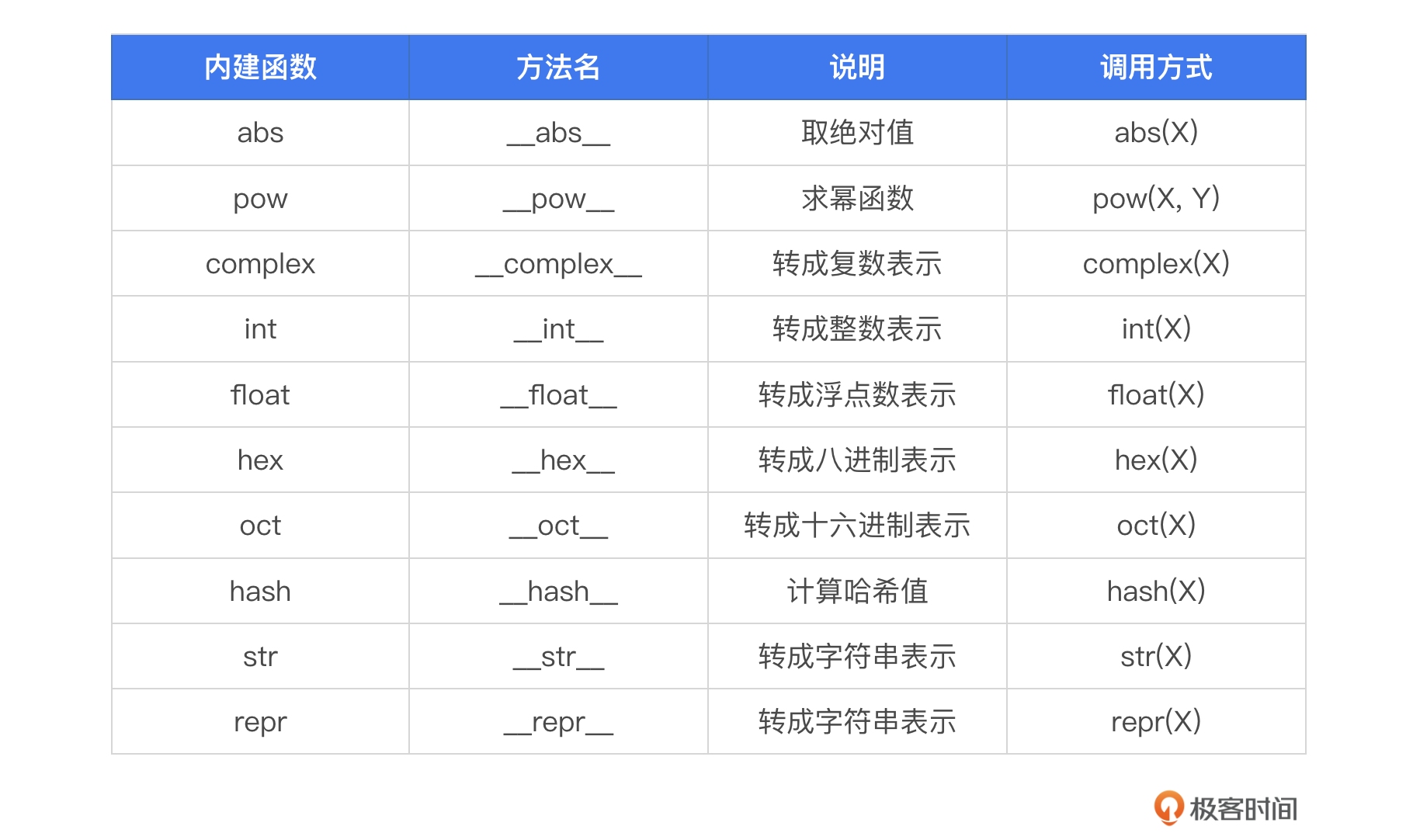
这个表里的 str 函数和 repr 函数的作用很接近。实际上,大多数自定义类,这两个函数的实现也是相同的。但这里也请你注意它们之间的细微区别。
首先,使用 print 函数打印一个对象时,虚拟机默认调用它的 str 方法,如果对象的类型里没有定义 str 方法,就继续调用 repr 方法。如果还没有定义,则打印对象的内存地址。
其次,str 方法更倾向于输出面向用户的信息,可读性尽量高。repr 方法则更倾向于输出面向开发者的信息,要尽可能地打印对象内部信息帮助开发者调试。
所以,我们可以使用对象的 str 方法和 repr 方法来修改 print 方法的逻辑,你可以看一下修改之后的代码。
void Klass::print(HiObject* x) {
HiObject* func = x->getattr(ST(str));
if (func != Universe::HiNone) {
HiObject* s = Interpreter::get_instance()->call_virtual(func, nullptr);
s->as<HiString>()->print();
return;
}
func = x->getattr(ST(repr));
if (func != Universe::HiNone) {
HiObject* r = Interpreter::get_instance()->call_virtual(func, nullptr);
r->as<HiString>()->print();
return;
}
printf("<object at %p>", x);
}
除了 str 和 repr 之外,表里的大多数函数的实现都很简单,你可以自己实现。
支持特殊操作符
可以重载的操作符,除了上节课所介绍的一元、二元操作符之外,还有一些特殊操作符。比如函数调用、取下标等操作,接下来,我们就继续重载这些特殊的操作符。
函数调用操作符
在 C++ 中,开发者可以重载 () 操作符,这样,就可以把对象当做函数一样调用了。STL 中的 Functor 正是依赖函数调用操作符重载才能够实现。
在 Python 中,开发者也可以通过在类中定义 __call__ 方法来实现 () 操作符的重载,例如:
class Functor(object):
def __init__(self):
pass
def __call__(self):
print("calling.")
a = Functor()
a()
在上述测试用例中,a 是一个普通对象,但是却可以像函数一样被调用。为了实现这个功能,我们需要实现 Klass 类的 call 方法。
HiObject* Klass::call(HiObject* x, HiList* args, HiDict* kwargs) {
HiObject* callable = x->getattr(ST(call));
if (callable == Universe::HiNone) {
x->print();
printf(" is non-callable\n");
assert(false);
}
return Interpreter::get_instance()->call_virtual(callable, args);
}
在原有的基础上,添加 call 方法是非常容易的,只需要在目标对象上查找 __call__ 方法并调用它就可以了。
下面我们继续研究取下标操作符。
取下标和取属性操作符
取下标操作符是 [],Python 中也支持对这个操作符进行重载。另外,Python 也支持重载点号操作符,点号在 Python 中用于取属性。
在 Python 中,可以通过在类里定义 __getitem__ 方法来实现 [] 操作符的重载,定义 __getattr__ 方法来实现取属性操作符的重载。我们可以看一个例子。
class A(object):
def __init__(self, *args):
self.attrs = dict()
n = len(args)
i = 0
while (i < n):
a = args[i]
i += 1
b = args[i]
i += 1
self.attrs[a] = b
def __getitem__(self, key):
if key in self.attrs:
return self.attrs[key]
else:
return "Error"
def __setitem__(self, key, value):
self.attrs[key] = value
def __delitem__(self, key):
del self.attrs[key]
def __str__(self):
return "object of A"
a = A("hello", "hi", "how are you", "fine")
print(a)
print(a["hello"])
print(a["how are you"])
a["one"] = 1
print(a["one"])
del a["one"]
print(a["one"])
print(a.attrs)
中括号所对应的取下标操作会被翻译成 BINARY_SUBSCR 字节码,这个字节码的实现是调用 HiObject 的 subscr 方法。所以,我们只需要在 Klass 中实现这个方法就可以了。
HiObject* Klass::subscr(HiObject* x, HiObject* y) {
HiList* args = new HiList();
args->append(y);
return find_and_call(x, args, ST(getitem));
}
相应的,如果要对下标进行赋值,所对应的字节码是 STORE_SUBSCR。重载下标赋值操作,需要在类定义中添加 __setitem__ 方法,而删除下标操作,则需要添加 __delitem__ 方法,我们也把这两个方法添加到 Klass 里。
void Klass::store_subscr(HiObject* x, HiObject* y, HiObject* z) {
HiList* args = new HiList();
args->append(y);
args->append(z);
find_and_call(x, args, ST(setitem));
}
void Klass::del_subscr(HiObject* x, HiObject* y) {
HiList* args = new HiList();
args->append(y);
find_and_call(x, args, ST(delitem));
}
取下标的机制虽然特殊,但究其根源,与数值计算并没有什么区别。接下来我们继续研究取属性操作。不管是自定义类里的 __getattr__ 方法,还是在虚拟机中实现 getattr 都必须十分小心,要避免进入无穷递归中。我们先看一个测试用例。
class B(object):
def __init__(self):
self.keys = {}
def __getattr__(self, k):
if k in self.keys:
return self.keys[k]
else:
return None
b = B()
print(b.value)
测试代码的最后一行是一个取对象属性的操作,前边我们介绍了,这个操作可以被 __getattr__ 方法重载。因此执行这一行的时候,虚拟机就会转而调用 b 的 __getattr__ 方法。
在这个方法里,又使用了一次取对象属性的操作,查找 self 对象的 keys 属性,这又会产生一次对 __getattr__ 方法的调用。无穷递归调用就产生了,所以虚拟机很快就会崩溃退出。
实际上,不管是取下标操作,还是普通的数值计算,都可能写出无穷递归,只是那种情况相对少一些。而取对象属性的操作太常见,所以写出上面错误代码的可能性就更大一些。
下面我们再看一个正确的示例。
keys = []
values = []
class B(object):
def __setattr__(self, k, v):
if k in keys:
index = keys.index(k)
values[index] = v
else:
keys.append(k)
values.append(v)
def __getattr__(self, k):
if k in keys:
index = keys.index(k)
return values[index]
else:
return None
b = B()
b.foo = 1
b.bar = 2
print(b.foo)
print(b.bar)
b.foo = 3
print(b.foo)
设置对象属性会被翻译成 STORE_ATTR(第 24 和 25 行),所以我们就在 Klass 中增加调用 __setattr__ 的逻辑。Klass 中已经有 setattr 方法了,只需要在这个方法里增加重载的逻辑即可。
// setattr for normal object.
HiObject* Klass::setattr(HiObject* obj, HiObject* x, HiObject* y) {
HiObject* func = obj->klass()->klass_dict()->get(ST(setattr));
// 如果未定义__setattr__方法,就直接放到对象的obj_dict中
if (func == Universe::HiNone) {
obj->obj_dict()->put(x, y);
return Universe::HiNone;
}
func = new MethodObject(func->as<FunctionObject>(), obj);
HiList* args = new HiList();
args->append(x);
args->append(y);
return Interpreter::get_instance()->call_virtual(func, args);
}
上述代码中,setattr 一开始就是判断 x 的类定义中是否有 __setattr__ 方法。如果没有的话,就沿着原来的逻辑继续去对象的属性字典里查找。如果有这个方法,就通过 call_virtual 执行这个方法。
在测试用例里取对象上的 foo 属性(第 26 行),会被翻译为 LOAD_ATTR。我们需要在 Klass 的 getattr 方法中增加重载取属性操作的逻辑。
HiObject* Klass::getattr(HiObject* x, HiObject* y) {
HiObject* func = x->klass()->klass_dict()->get(ST(getattr));
// 如果类里定义了__getattr__方法,就先调用这个方法
if (func != Universe::HiNone) {
func = new MethodObject(func->as<FunctionObject>(), x);
HiList* args = new HiList();
args->append(y);
return Interpreter::get_instance()->call_virtual(func, args);
}
// 如果没有定义 __getattr__方法,优化去对象字典里找
if (x->obj_dict()->has_key(y)) {
return x->obj_dict()->get(y);
}
// 如果对象字典里也没有,就去类里找
HiObject* result = _klass_dict->get(y);
// Only klass attribute needs bind.
if (!MethodObject::is_method(result) &&
MethodObject::is_function(result)) {
result = new MethodObject(result->as<FunctionObject>(), x);
}
return result;
}
这段代码结合注释应该不难理解。到这里,取下标操作和取属性操作就都能支持了,编译执行测试用例,就可以打印出正确的值。
重载操作符还有很多知识,比如原位计算、右结合运算等。但根本性的问题都已经介绍完了,更多的方法重载你可以自己实现。
实现类的继承
这部分我们来实现类的继承,先看第一个例子。
class A(object):
def say(self):
print("I am A")
class B(A):
def say(self):
print("I am B")
class C(A):
pass
b = B()
c = C()
b.say() # "I am B"
c.say() # "I am A"
代码中对象 c 的类型是 C,C 中没有定义 say 方法,虚拟机就会从它的超类中查找,发现 A 中有定义 say 方法,所以第 16 行的运行结果是打印 "I am A"。
而对象 b 的类型是 B,B 中定义了自己的 say 方法,虚拟机就会直接执行这个方法,所以第 15 行的运行结果是打印 "I am B"。
根据这个例子我们可以得到结论,Python 在调用某个对象的方法时,会先检查它所对应的类型中,是否定义了该方法。如果没有定义,就转而去查找它的父类,如果父类还是没有,就要继续查找它的祖先类,直到找到方法定义为止。
如果 Python 像 Java 语言那样只支持单继承,每个类只能有一个父类,那这个查找方法定义的过程也会非常简单。但实际上,Python 是支持多继承的。如果一个类有多个父类的时候,要想从父类中查找方法定义,应该按照怎样的顺序查找呢?
Python 在父类中查找方法的过程也被叫做方法解析的过程,这个查询父类的顺序就被叫做方法解析顺序(Method Resolution Order,MRO)。
Python 发展到今天经历了 3 种 MRO 算法,分别是:
- 从左往右,采用深度优先搜索(DFS)的算法,叫做旧式类的 MRO。
- 从 Python 2.2 版本开始,新式类在采用深度优先搜索算法的基础上做了优化,解决菱形继承问题。
- Python 2.3 版本对新式类采用了 C3 算法。由于 Python 3.x 仅支持新式类,所以这个版本只使用 C3 算法。
Python 2.7 中所使用的基于深度优先搜索的算法,在我所写的《自己动手写Python虚拟机》中有论述,如果你感兴趣的话,可以去读一读,我们这个课程只关注 C3 算法。
C3 算法
如果 B 类型有 class B(A):pass 的继承关系,就记 B 的mro序列为 [B,A]。
如果 B 类型继承自多个基类 class B(A1,A2,...,An): pass,就记 B 的 mro 序列为:
其中,merge 操作用来合并 B 所有父类的 mro 序列。我们来看一下它的算法步骤。
- 遍历所有父类的 mro 序列,如果一个序列的第一个元素,在其他序列中也是第一个元素,或不在其他序列出现,那么这个元素就是一个合法的元素。
- 如果找不到合法元素,说明类定义不合法,算法结束。
- 从所有 mro 序列中删除第一步找到的合法元素,并把它合并到 B 类型的 mro 里。
- 所有的非空 mro 序列重新组成一个序列,重复第一步的算法。直到所有 mro 序列都变成空序列。
你可以看一下我给出的几个定义。
class A(object):pass
class B(object):pass
class C(object):pass
class E(A,B):pass
class F(B,C):pass
class G(E,F):pass
A、B、C都继承自一个基类,所以 mro 序列依次为 [A, O]、[B, O]、[C, O]。计算 E 的 mro 序列的步骤是:
mro(E) = [E] + merge(mro(A), mro(B), [A, B])
= [E] + merge([A, O], [B, O], [A, B]) (1)
= [E, A] + merge([O], [B,O], [B]) (2)
= [E, A, B] + merge([O], [O]) (3)
= [E, A, B, O]
公式(1)处,A是序列 [A, O] 中的第一个元素,在序列 [B, O] 中不出现,在序列 [A, B] 中也是第一个元素,所以从全体序列 ([A, O]、[B, O]、[A, B]) 中删除A,并把 A 合并到当前 mro 中,得到 [E, A]。
公式(2)处,O 是序列 [O] 中的第一个元素,但 O 在序列 [B, O] 中出现并且不是第一个元素,所以 O 不满足条件。继续查看 [B, O] 的第一个元素 B,B 满足条件,所以从全部序列中删除B,并将 B 合并到序列 [E, A] 中,得到 [E, A, B]。
我们再看一个例子。
class X(object): pass
class Y(object): pass
class A(X,Y): pass
class B(Y,X): pass
class C(A, B): pass
给这些类的定义套用 C3 算法,我们看得到的结果。
mro(X) = [X, O]
mro(Y) = [Y, O]
mro(A) = [A] + merge(mro(X), mro(Y))
= [A] + [X, O] + [Y, O]
= [A, X] + [O] + [Y, O]
= [A, X, Y] + [O] + [O]
= [A, X, Y, O]
mro(B) = [B, Y, X, O]
这个演算过程比较简单,我就不再解释了。接下来,我们重点关注 C 的 mro 序列的计算过程。
mro(C) = [C] + merge(mro(A), mro(B))
= [C] + merge([A, X, Y, O], [B, Y, X, O])
= [C, A] + merge([X, Y, O], [B, Y, X, O])
= [C, A, B] + merge([X, Y, O], [Y, X, O])
演算到这一步的时候,就发生问题了,不管是第一个序列的首元素 X 还是第二个序列的首元素 Y,都不满足条件,所以算法无法使 merge 的各个序列变为空序列,只能报错退出。
由此可见,使用 C3 算法既可以很好地解决菱形继承的问题,也可以检查出继承顺序不一致的情况。接下来,我们就来实现这个算法。
实现 C3 算法
为了实现多继承,我们可以在 Klass 中定义 super 属性,它是一个列表,记录了某个类型的所有父类。同时为每个类型再创建一个属性,记录该类型的方法解析顺序,我们把这个属性起名为 _mro。
// [object/klass.hpp]
class Klass {
private:
HiList* _super;
HiList* _mro;
...
public:
...
void add_super(Klass* x);
void order_supers();
HiList* super() { return _super; }
void set_super_list(HiList* x) { _super = x; }
HiList* mro() { return _mro; }
...
};
// [object/klass.cpp]
void Klass::add_super(Klass* klass) {
if (_super == nullptr)
_super = new HiList();
_super->append(klass->type_object());
}
为了实现继承,我们在 Klass 里添加了 5 个方法,除了 order_super 之外的其他方法的实现,逻辑都非常简单,在代码中已经列出来了,你可以看一下。
order_super 方法是 C3 算法的具体实现,用来计算类型的 mro,我们来重点看一下它的代码。
HiList* Klass::linear(HiTypeObject* obj) {
HiList* result = new HiList();
HiList* mro = obj->mro();
for (int i = 0; i < mro->length(); i++) {
result->append(mro->get(i));
}
return result;
}
HiList* Klass::merge(HiList* supers) {
if (supers->empty()) {
return new HiList();
}
for (int i = 0; i < supers->length(); i++) {
bool valid = true;
// head = supers[i][0]
HiTypeObject* head = supers->get(i)->as<HiList>()->get(0)->as<HiTypeObject>();
for (int j = 0; j < supers->length(); j++) {
if (j == i) continue;
// if head in supers[j][1:]
if (supers->get(j)->as<HiList>()->index(head) > 0) {
valid = false;
break;
}
}
if (!valid) {
continue;
}
HiList* next = new HiList();
for (int j = 0; j < supers->length(); j++) {
HiList* item = supers->get(j)->as<HiList>();
item->remove(head);
if (!item->empty()) {
next->append(item);
}
}
HiList* result = merge(next);
result->insert(0, head);
return result;
}
printf("Should not reach here\n");
assert(false);
return nullptr;
}
void Klass::order_supers() {
if (_super == nullptr) {
_mro = new HiList();
_mro->append(_type_object);
return;
}
HiList* all = new HiList();
for (int i = 0; i < _super->length(); i++) {
all->append(linear(_super->get(i)->as<HiTypeObject>()));
}
_mro = merge(all);
_mro->insert(0, _type_object);
_klass_dict->put(ST(mro), _mro);
}
order_supers 的作用是将本类型的所有父类的 mro 序列进行合并。变量 all 里记录了父类的 mro 序列(第 59 至 63 行)。
合并的具体动作是由 merge 方法完成的。merge 通过一个大循环来找到合法元素(第 16 行至 32 行)。如果所有序列都遍历完了,还没有找到合法元素,就会报错退出(第 47 至 49 行)。
如果找到合法元素,就把它从全部序列中删除,将剩下的序列再重新组成一个列表,再次调用 merge 方法进行合并(第 33 至 41 行)。同时,合法元素会被合并至结果列表中(第 42 行)。
整个算法全部结束以后,再把 mro 序列和 __mro__这个字符串关联起来。这样,在程序中就可以通过类型的 __mro__ 属性访问到这个列表了。
最后,我们要在每个类的初始化里完成 mro 的排序工作,以 HiList 类为例,你可以看一下它的代码。
void ListKlass::initialize() {
HiDict * klass_dict = new HiDict();
//...
set_klass_dict(klass_dict);
(new HiTypeObject())->set_own_klass(this);
set_name(new HiString("list"));
add_super(ObjectKlass::get_instance());
order_supers();
}
而对于用户自定义类型,则应该在 klass 创建的时候构建它的 mro,也就是 create_klass 中,你可以自己添加。
最后,类的多继承对于方法的查找是有影响的,主要是在 getattr 中,如果在本类型中查找不到,还要去自己的 mro 列表中的类型里去查找,所以 getattr 就变成了这个样子。
HiObject* Klass::find_in_mro(HiObject* obj, HiString* name) {
HiObject* x = obj->klass()->klass_dict()->get(name);
if (x != Universe::HiNone) {
return x;
}
for (int i = 0; i < obj->klass()->mro()->length(); i++) {
x = obj->klass()->mro()->get(i)->getattr(name);
if (x != Universe::HiNone) {
return x;
}
}
return x;
}
HiObject* Klass::getattr(HiObject* x, HiObject* y) {
HiObject* func = find_in_mro(x, ST(getattr));
// 如果类里定义了__getattr__方法,就先调用这个方法
if (func != Universe::HiNone) {
func = new MethodObject(func->as<FunctionObject>(), x);
HiList* args = new HiList();
args->append(y);
return Interpreter::get_instance()->call_virtual(func, args);
}
// 如果没有定义 __getattr__方法,就去对象字典里找
if (x->obj_dict()->has_key(y)) {
return x->obj_dict()->get(y);
}
// 如果对象字典里也没有,就去类里找
HiObject* result = find_in_mro(x, y->as<HiString>());
// Only klass attribute needs bind.
if (MethodObject::is_function(result) ||
MethodObject::is_native(result)) {
result = new MethodObject(result->as<FunctionObject>(), x);
}
return result;
}
经过不断地增加功能,我们最终将 getattr 的功能全部补齐了。
首先,虚拟机在对象所对应的类型中查找是否有 __getattr__ 方法(第 19 行),如果找到了这个方法就直接调用这个方法。如果没有找到,就转而在对象字典里查找是否有 y 属性(第 30 至 32 行)。如果失败,再去对象所对应的类型中查找是否有 y 属性。这个逻辑就比较清晰了。
经过了这些改造以后,我们虚拟机的行为终于和 CPython 3.8 的行为一致了。开始时的例子也能正确执行了。
到此为止,我们的虚拟机中的对象系统就构建得差不多了,这为虚拟机的下一步开发奠定了坚实的基础,还有一些与对象系统相关的功能,比如异常的定义和处理等,我们等模块功能实现了以后再来添加。
总结
这节课我们先实现了内建方法重载,主要以 len、str 和 repr 三个函数为例,说明了如何实现内建方法重载。然后我们介绍了三个比较特殊的操作符。
- 第一个是 () 操作符,用于模拟函数调用的,如果一个对象定义了
__call__方法,那么这个对象作为 CALL_FUNCTION 指令的操作数时,它的__call__方法就会被执行。 - 第二个是下标操作符 [],分别使用
__setitem__、__getitem__、__delitem__来支持设置、读取和删除操作。 - 第三个是属性操作符点号,我们通过
__getattr__和__setattr__方法来说明了如何进行对象属性的操作。
第三部分我们实现了 Python 的多继承,以及如何确定继承顺序。这部分,我们重点介绍了 C3 算法的原理和实现。
通过这四节课的努力,我们终于将对象系统构建得基本完备了。到目前为止,我们在写代码的时候,需要什么对象都是直接通过 new 操作符来创建的,从来没有释放过,这必然会带来大量的内存泄漏。从下一节课起,我们该把内存好好梳理一遍了。
思考题
多继承机制会如何影响 type、isinstance 等几个和类型相关的函数?应该如何改写才能使它们正确工作呢?欢迎你把你思考后的结果分享到评论区,也欢迎你把这节课的内容分享给其他朋友,我们下节课再见!
- 冯某 👍(0) 💬(0)
记录一下
2024-12-09 - ifelse 👍(0) 💬(0)
学习打卡
2024-11-05