19 自定义类型:面向对象编程的基础设施
你好,我是海纳。
在 Python 中,包括函数、方法、类型在内的一切皆是对象,我们前面已经很深刻地认识到了这一点。这些机制为面向对象编程提供了基础。上一节课,我们为虚拟机添加了类型系统。这节课,我们会在上节课的基础上,继续研究如何实现用户自定义类型。
自定义类的实现可能是 Python 3 相对于 Python 2 变化最大的一个特性了。它新增了很多机制,使类的功能变得更加强大、灵活了。但同时,这些新的特性也给开发者设置了不小的门槛,尤其是元类(metaclass),很多人即使可以合理地使用它来进行开发,但仍然很难说出它背后的原理。
这一节课,我们就一步步地来实现自定义类的这些功能。
支持用户自定义类型
Python 是一种支持对象的编程语言,而面向对象的编程语言中,最重要的一个特性就是自定义类。我们经过了长途跋涉,终于走到自定义类的门口了。和之前一样,我们先来研究测试用例以及它的字节码。
对应的字节码:
1 0 LOAD_BUILD_CLASS
2 LOAD_CONST 0 (<code object A>)
4 LOAD_CONST 1 ('A')
6 MAKE_FUNCTION 0
8 LOAD_CONST 1 ('A')
10 LOAD_NAME 0 (object)
12 CALL_FUNCTION 3
14 STORE_NAME 1 (A)
4 16 LOAD_NAME 1 (A)
18 CALL_FUNCTION 0
20 STORE_NAME 2 (a)
5 22 LOAD_NAME 3 (print)
24 LOAD_NAME 2 (a)
26 LOAD_ATTR 4 (value)
28 CALL_FUNCTION 1
30 POP_TOP
32 LOAD_CONST 2 (None)
34 RETURN_VALUE
这段字节码有点复杂,我来给你逐行讲解。第 1 条指令是 LOAD_BUILD_CLASS,这是一个 Python 3 版本新加的指令,用来向栈顶加载一个内建函数 __build_class__,这个内建函数非常复杂,我们使用 help 来查看这个函数的格式。
>>> help(__build_class__)
Help on built-in function __build_class__ in module builtins:
__build_class__(...)
__build_class__(func, name, *bases, [metaclass], **kwds) -> class
Internal helper function used by the class statement.
可以看到,这个函数的作用是创建一个类型对象,它接受的参数有 5 个。
- func 代表一个函数对象,这个对象用来构建类型。
- name,一个字符串,代表类型的名称。
- bases,一个列表,这是一个扩展位置参数,代表了类型的父类。
- metaclass,可选参数,翻译为元类。其实它的作用是类型的工厂,后面我们会专门讲解。
- kwds,一个字典,可以在创建类型的时候为类型添加额外的属性。
第二组指令包括第 2、3、4 三条,它们的作用是创建一个函数对象,这个函数对象就是用来构建类型的,也就是 __build_class__ 的第一个参数。第 2 条指令将定义 A 的 CodeObject 加载到栈顶,目前我们知道,函数、方法和lambda 表达式会被翻译成 CodeObject。这里类定义中的代码也会被翻译成一个 CodeObject。
第三组指令是第 5 条,它的作用是加载字符串 A 到栈顶。这个字符串正是类型的名称。
第四组指令是第 6 条,它把 object 类型加载到栈顶,代表了 A 类型的父类。如果A 类型还有更多的父类,这里就会有多条指令把父类的类型对象都加载到栈顶。然后通过扩展位置参数传递给 __build_class__。
最后一组就是第 7 条指令,CALL_FUNCTION 的作用是真正地执行 __build_class__ 来创建类型对象。类型对象在我们的虚拟机中,其实就是上节课所实现的 HiTypeObject。
接下来的字节码就比较简单了,我就不再解释了。注意到第 4 行的 MAKE_FUNCTION 的参数都是 0,这说明定义类的代码既没有默认值,也不接受任何参数。接下来,我们再研究一下第 2 行加载的那个 CodeObject 到底做了什么事情。
用于构建类型的CodeObject
在 show_file 的结果里,我们也可以找到用于创建类型 A 的 CodeObject 的字节码。
1 0 LOAD_NAME 0 (__name__)
2 STORE_NAME 1 (__module__)
4 LOAD_CONST 0 ('A')
6 STORE_NAME 2 (__qualname__)
2 8 LOAD_CONST 1 (1)
10 STORE_NAME 3 (value)
12 LOAD_CONST 2 (None)
14 RETURN_VALUE
第 1 行和第 2 行的指令是进行一次关于 module 的赋值操作。
module 是 Python 中的核心概念之一,通常一个 Python 文件就是一个 module。module 提供了一个命名空间,在某个 module 中定义的方法,类型不会和其他 module 里的名称冲突。关于 module 你暂时先了解这么多就可以了,后面我们还会深入地研究 module 的实现。
至于 __name__ 这个名称,它是 Python 虚拟机的一个规定,作为程序入口的那个模块,在当前阶段,就认为是被执行的那个 py 文件,它的局部变量表里会设置 __name__ 的值为 __main__。我们可以通过一个例子来验证一下。
为了满足这一项规定,我们只需要在第一个 FrameObject 的局部变量表里增加 __name__ 的初始化就可以了。
FrameObject::FrameObject(CodeObject* codes) {
...
_locals = new HiDict();
_globals = _locals;
_locals->put(new HiString("__name__"), new HiString("__main__"));
...
}
注意,我们只在程序开始的时候,也就是创建第一个虚拟栈帧的时候才加入这个初始化动作。添加了这一行代码以后,上面那个小的测试用例就可以正确执行了。
再回到 code A 的字节码,接下来的两个功能比较简单,定义了类型的全限定名(__qualname__)为字符串 A(第3、4行),还定义了一个名为 value 的局部变量(第 5、6行)。
接下来就结束了。如果你对 Python 2.7 有一些了解的话,就会发现这里少了一条非常关键的字节码:LOAD_LOCALS,它会把 A CodeObject 执行过程中的局部变量表拉出来,作为参数发送给类型 A 所对应的 HiTypeObject。
在 Python 3 里,并没有任何 return 语句可以把这个 CodeObject 的局部变量传递出来。
实际上,__build_class__ 函数是通过 exec 函数来完成这个功能的。也就是说,__build_class__ 的第一个参数 func,它所对应的 CodeObject 就是类型 A 的 CodeObject。在 __build_class__ 内部,又会进一步调用 exec 来执行这个 func 对象,exec 会把 func 对象执行过程中产生的局部变量表取出来。
exec 函数也可以在 Python 中直接使用,你可以看一下它的定义。
>>> help(exec)
exec(source, globals=None, locals=None, /)
Execute the given source in the context of globals and locals.
The source may be a string representing one or more Python statements
or a code object as returned by compile().
The globals must be a dictionary and locals can be any mapping,
defaulting to the current globals and locals.
If only globals is given, locals defaults to it.
也就是说,exec 除了可以接受可执行对象以外,还额外接受两个参数:globals 和 locals,这两个参数都是字典类型,分别代表了全局变量表和局部变量表。下面我用两个例子来说明变量表的作用。
>>> locals = {"a" : 1, "b" : 2}
>>> exec("print(a + b)", globals, locals)
3
>>> locals = {}
>>> exec("a = 3\nb = 4", globals, locals)
>>> locals
{'a': 3, 'b': 4}
第一个例子说明在执行语句的时候,exec 会从 locals 所指向的字典里查找变量。第二个例子说明exec 在更新局部变量表的时候,会把值写入 locals 所指向的字典。
最后,我们把完整的创建类型的过程串起来。
- 加载
__build_class__函数。这个函数的主要作用是创建类型对象,也就是一个 HiTypeObject,其中包含了类的各种属性。 - 类的属性由第一个参数 func 来构造,func 所对应的 CodeObject 正是类型 A 的 CodeObject,在这段代码里,初始化了全量名、模块名、所有的方法和类属性。
- 调用
__build_class__来创建类型对象,这个过程中会使用 exec 方法把 func 的局部变量取出来,用于构建类型对象。
到这里,我们就把创建 A 的类型对象的过程梳理完了。可见,创建类型对象的核心逻辑位于 __build_class__ 和 exec 两个函数中。接下来,我们就来实现它们。
创建类型对象
我们采用自顶向下的思路来分析问题,有利于使问题逐渐细化。但实现功能的时候,就需要采用自底向上逐步添加的办法。所以这里我们先来实现 exec 方法。
HiObject* internal_exec(FunctionObject* callable, HiDict* globals, HiDict* locals) {
if (globals) {
callable->set_globals(globals);
}
if (locals) {
callable->set_locals(locals);
}
return Interpreter::get_instance()->call_virtual(callable, nullptr);
}
这段代码的逻辑比较简单,就是使用参数 globals 代替函数对象的全局变量表,使用 locals 代表局部变量表,然后再执行函数对象。
在实现 List 遍历功能的时候,虚拟机中就已经引入了 call_virtual 方法。当时只是用它来调用虚拟机内建函数 next,所以并没有深入解释这个方法的意义。
实际上,call_virtual 的意义在于,从虚拟机内部开始调用执行一段 Python 字节码。虚拟机是由 C++ 实现的,而目标代码是由 Python 实现的,所以这是一种跨语言的调用。
在 Java 虚拟机 hotspot 中,虚拟机调用 Java 代码进行跨语言调用的时候,使用的方法的名字就是 call_virtual。所以我们也在自己的虚拟机里增加一个同名的函数用于跨语言调用。你可以看一下它的代码。
HiObject* Interpreter::call_virtual(HiObject* func, HiList* args) {
if (func->klass() == NativeFunctionKlass::get_instance()) {
// ...
}
else if (MethodObject::is_method(func)) {
// return value is ignored here, because they are handled
// by other pathes.
if (!args) {
args = new HiList();
}
args->insert(0, method->owner());
return call_virtual(method->func(), args);
}
else if (MethodObject::is_function(func)) {
FrameObject* frame = new FrameObject((FunctionObject*) func, args, nullptr);
enter_frame(frame);
_frame->set_entry_frame(true);
eval_frame();
destroy_frame();
return _ret_value;
}
return Universe::HiNone;
}
这段代码会先判断可执行对象的类型。如果可执行对象是内建函数(第 2 至 4 行),或者是与具体对象绑定的方法(第 5 至 13 行),处理方式与 build_frame 一样。
如果可执行对象是 FunctionObject(第 14 至 23 行),就要创建一个新的虚拟机栈帧 FrameObject,并在这个栈帧里进行运算(第 15 行)。
其中,enter_frame 负责切换解释器的 _frame 变量,使其指向新创建的帧。然后调用 eval_frame 进入解释器执行 Python 代码。从虚拟栈帧返回以后,就调用 destroy_frame 销毁新创建的栈帧,并把 _ret_value 作为返回值返回给调用者。
经过这种重构,Interpreter 的逻辑变得更加清晰易读。这些修改涉及到的代码量并不大,这里我就不再列出所有函数的代码了,你可以通过代码仓自己查看。
以前,在执行 RETURN_VALUE 的时候,虚拟机并不会立即从 eval_frame 中返回,而是回到上一个虚拟栈帧,也就是调用者的 FrameObject 继续执行。现在虚拟机调用 Python 代码的时候却希望 RETURN_VALUE 可以直接结束 eval_frame 方法的执行,回到虚拟机的 C++ 代码中来。
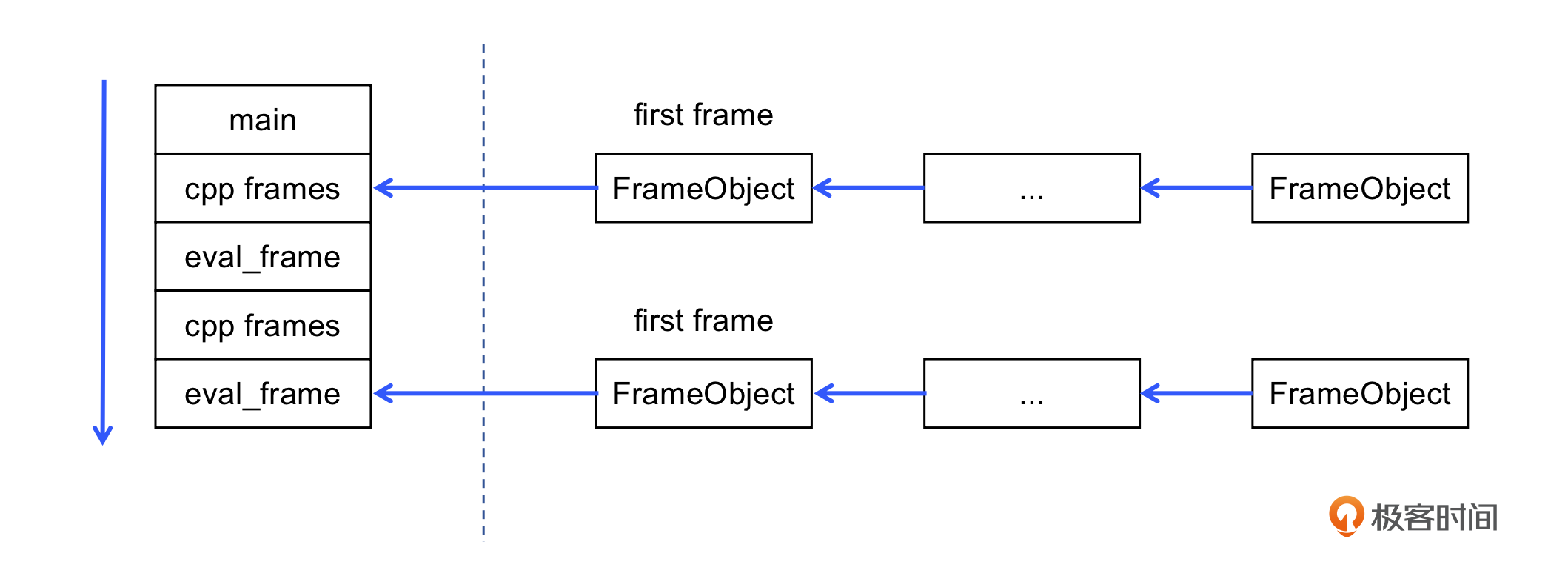
如图所示,我们希望 RETURN_VALUE 能正确地区分是否需要结束 eval_frame,所以就引入了 _entry_frame 这个变量来作为标记。所有 C++ 代码调用 Python 代码产生的第一个 frame,我们叫做 entry frame。set_entry_frame 方法就是为了设置这个标志位(第 18 行)。
相应的,RETURN_VALUE 的实现也会发生变化,你可以看一下变化后的代码。
// [runtime/interpreter.cpp]
void Interpreter::eval_frame() {
while (_frame->has_more_codes()) {
unsigned char op_code = _frame->get_op_code();
...
switch (op_code) {
...
case ByteCode::RETURN_VALUE:
_ret_value = POP();
if (_frame->is_first_frame() ||
_frame->is_entry_frame())
return;
leave_frame();
break;
...
}
}
}
如果解释器判断当前栈帧是 first frame,或者是 entry frame,就直接结束 eval_frame 的执行。否则就只是从当前的虚拟栈帧退回到上一个虚拟栈帧。
这样,exec 方法就完成了,接下来我们实现最重要的创建类型对象的方法,你可以看一下实现代码。
HiObject* build_type_object(HiList* args) {
int length = args->length();
assert(length >= 2);
FunctionObject* cls_def = args->get(0)->as<FunctionObject>();
HiString* name = args->get(1)->as<HiString>();
HiList* super_list = new HiList();
for (int i = 2; i < length; i++) {
super_list->append(args->get(i));
}
HiDict* locals = new HiDict();
internal_exec(cls_def, nullptr, locals);
return Klass::create_klass(locals, super_list, name);
}
cls_def 就是上一部分例子里 MAKE_FUNCTION 所得到的函数对象,虚拟机正是通过执行这一段函数得到了创建对象类型所需要的字典。name 是类型名字,super_list 是父类列表,如果参数的数量大于 2,就代表这个类有父类。在这节课的实际例子里,父类只有 object 一个,所以在创建 A 类型对象的时候,这里的参数只包含了 object 类的 TypeObject。
最后,通过调用 internal_exec,虚拟机就得到了创建 A 的类型对象所需要的字典了。当执行完以后,locals 字典里会包含类的全量名称、类属性 value 等。在调试的时候,你可以在这里增加一个打印函数,把 locals 的值打印出来,来观察执行结果是否符合预期。
最后一个步骤是实现 Klass 里的静态方法,create_klass。这个方法接受三个参数,然后创建一个新的 Klass,以及和它绑定的 TypeObject。
HiObject* Klass::create_klass(HiDict* klass_dict, HiList* supers_list, HiString* name) {
Klass* new_klass = new Klass();
new_klass->set_klass_dict(klass_dict);
new_klass->set_name(name);
if (supers_list->length() > 0) {
HiTypeObject* super = supers_list->get(0)->as<HiTypeObject>();
new_klass->set_super(super->own_klass());
}
HiTypeObject* type_obj = new HiTypeObject();
type_obj->set_own_klass(new_klass);
return type_obj;
}
create_klass 方法会先创建一个空的 Klass 对象(第 2 行)。这个对象不同于以往的 ListKlass、DictKlass 等,它在创建的时候并不知道自己的类名。
接下来,第一个参数传进来的字典被设置成了这个新建的 klass 对象的 klass_dict(第 4 行)。并且,它的名字设成了第三个参数传入的字符串(第 5 行)。然后设置 klass 对象的父类。由于我们现在只支持单继承,所以就只取父类列表的第一个元素,将新建 klass 的父类设成父类列表的第一个元素(第 7 至 10 行)。
最后,创建与这个 klass 相对应的 TypeObject。请注意,create_klass 方法最后返回的是 TypeObject,而不是 Klass。当程序上下文要求出现的是一个对象的时候,就必须使用 TypeObject 代替 Klass。
build_type_object 方法被执行完以后,它的返回值就是新建类型的 TypeObject。接下来的指令是执行 STORE_NAME,把变量 A 和新创建的这个类型对象绑定在一起。最终变量 A 所代表的就是一个类对象。也就是说,Python 的 class 语句的作用是产生一个类对象,并与类名变量绑定。
执行 build_type_object 创建类型对象的时候,Python 源码中 class 定义里的那些代码都会被执行。TypeObject 的 Klass 是 TypeKlass,而 TypeKlass 里已经定义了 print 方法。所以我们可以通过调用 print 语句,来打印这个类型对象。
执行上面这段代码,就会打印这个类的名字。这时候的运行结果与标准 Python 3 虚拟机有一点差异,这里没有打印模块名字,这是因为我们当前阶段还没有支持模块功能。
总结
这节课我们主要实现了创建自定义类型的功能。在 Python 中,开发者使用 class 关键字可以自行定义类型。上一节课我们使用了 TypeObject 和与它绑定的 Klass 对象来代表一个类型。所以,这节课的主要目标就是创建自定义类型的 TypeObject 对象。
我们这节课只新增了一条新的字节码 LOAD_BUILD_CLASS,用来把内建函数 __build_class__ 加载到栈顶。所以在字节码层面并没有引入特别多的机制(这和 Python 2.7 非常不同),主要的功能都封闭在 __build_class__ 函数里了。
__build_class__ 通过使用 exec 调用类定义的 CodeObject 取出相关的属性字典,再用这个字典去构建一个新的 Klass,并把这个 Klass 的 TypeObject 作为返回值传递出来。
通过这种方式,我们就创建了一个自定义类型的类型对象,也就是它的对应的 TypeObject。下节课,我们就可以使用这个类型对象创建实例了。
思考题
对于以下代码:
我们要怎么修改才能正确运行?或者说,对于类型对象的 LOAD_ATTR 指令,应该如何实现呢?欢迎你把你的答案分享到评论区,也欢迎你把这节课的内容分享给需要的朋友,我们下节课再见!
- 冯某 👍(0) 💬(0)
记录一下
2024-12-08 - ifelse 👍(0) 💬(0)
学习打卡
2024-11-03