09 函数对象 :函数是依赖什么成为第一类公民的?
你好,我是海纳。
上一节课我们介绍了函数的静态代码和动态记录之间的区别,以及通过递归函数的执行过程,深入介绍了栈帧的组织结构,这一节课我们就通过编写代码实现相应的功能。
在 Python 中,函数(function)和方法(method)的意义是不同的。类中定义的成员函数被称为方法,不在类中定义的函数才是我们平常所说的狭义的函数。方法是建立在类机制上的,所以函数比方法要简单一些,这节课我们就从函数开始实现。
实现函数功能
我们先从一个最简单的例子开始,定义一个函数,让它打印一个字符串。
将这段代码存为一个文件,名为 func.py,然后使用 python -m compileall func.py 命令,把这个文件编译成 func.pyc 文件。再使用 show_file.py 工具,查看 func.pyc 文件的构造。
1 0 LOAD_CONST 0 (<code object fo>)
2 LOAD_CONST 1 ('foo')
4 MAKE_FUNCTION 0
6 STORE_NAME 0 (foo)
4 8 LOAD_NAME 0 (foo)
10 CALL_FUNCTION 0
12 POP_TOP
14 LOAD_CONST 2 (None)
16 RETURN_VALUE
这里展示的是定义 foo 函数和调用 foo 函数的字节码。这一段里有两个字节码是我们之前没有实现的,就是 MAKE_FUNCTION 和 CALL_FUNCTION。前者用于定义函数,后者用于调用函数。这一节课的关键就是实现这两个字节码。
在第 4 节课使用 print 函数的时候,实际上我们就已经遇到过 CALL_FUNCTION 指令了,但是因为当时没有函数的功能,所以我们就使用了一些特殊的手段绕过去了,现在就应该正常地实现这条指令了。
除了上述两个字节码,你还要注意第一条指令和第二条指令,第一个是LOAD_CONST,从常量表里加载第一项,而这一项是一个 code object。在这里code object 的定义出现了嵌套,也就是说 foo 所对应的 code object 出现在了主模块的常量表里。
第二个 LOAD_CONST从常量表里加载了一个字符串,代表函数的名字。这是与Python 2.7有区别的地方。在Python 2中,MAKE_FUNCTION 指令并不需要函数名字。
接下来,我们重点查看主模块的 consts 表的内容。
consts
code
argcount 0
nlocals 0
stacksize 2
flags 0043
code 740064018301010064005300
2 0 LOAD_GLOBAL 0 (print)
2 LOAD_CONST 1 ('hello')
4 CALL_FUNCTION 1
6 POP_TOP
8 LOAD_CONST 0 (None)
10 RETURN_VALUE
consts
None
'hello'
names ('print',)
varnames ()
freevars ()
cellvars ()
filename 'test_func.py'
name 'foo'
firstlineno 1
lnotab 0001
'foo'
None
这就很清楚了,consts 表包含了三项。其中的第一项,就是一个 code object,它的 name 就是 foo。前边我们在讲解 code object 的结构的时候也提到过,code object 是可以嵌套定义的,在二进制文件中用字母 'c' 代表 code object。在实现 BinaryFileParser 的时候,我们已经提前支持了这一特性。这里就不用再修改了。
实现函数栈帧
上一节课我们讲过,每一次函数调用都会有一个活动记录与之对应。这个活动记录也被叫做栈帧(frame)。
在当前的虚拟机执行器里,还没有栈帧的概念,因此我们要实现一种数据结构,来记录函数的调用过程,这个数据结构就是 FrameObject。每一次调用一个函数,就有一个这次调用的活动记录,也就是说每次函数调用,都会创建一个 FrameObject。每次函数执行结束,相应的 FrameObject 也会被销毁。
在 Interpreter 里,有很多变量是为函数执行时的活动记录服务的。例如,pc 记录了程序当前执行到的位置;locals 表记录了变量的值等等。本质上这些变量是与函数的执行绑定的,所以它们应该被封装到 FrameObject 里,而不是 Interpreter 中。
所以,接下来我们就应该重构 Interpreter,把所有这些与执行状态相关的量移到 FrameObject 中。
首先,我们来定义 FrameObject。
class FrameObject {
public:
FrameObject(CodeObject* codes);
~FrameObject();
ArrayList<HiObject*>* _stack;
ArrayList<Block*>* _loop_stack;
ArrayList<HiObject*>* _consts;
ArrayList<HiObject*>* _names;
Map<HiObject*, HiObject*>* _locals;
CodeObject* _codes;
int _pc;
public:
void set_pc(int x) { _pc = x; }
int get_pc() { return _pc; }
ArrayList<HiObject*>* stack() { return _stack; }
ArrayList<Block*>* loop_stack() { return _loop_stack; }
ArrayList<HiObject*>* consts() { return _consts; }
ArrayList<HiObject*>* names() { return _names; }
Map<HiObject*, HiObject*>* locals() { return _locals; }
bool has_more_codes();
unsigned char get_op_code();
int get_op_arg();
};
上述代码已经把 Interpreter 中的相关变量都转移到 FrameObject 中了。注意第 3 行的构造方法,以前虚拟机要执行一段字节码的时候,是通过直接调用 Interpreter 的 run 方法来实现的,其中 CodeObject 是 run 方法的参数。现在则要先创建一个 FrameObject,代码执行时,就只会影响 FrameObject 中的 pc、locals 等变量。
这段代码的逻辑很简单,FrameObject 只是对一些状态变量的封装,包括代码第 27 至 29 行所声明的三个方法,也不过是对一些简单逻辑的封装。具体内容你可以看我给出的代码。
// this constructor is used for module only.
FrameObject::FrameObject(CodeObject* codes) {
_consts = codes->_consts;
_names = codes->_names;
_locals = new Map<HiObject*, HiObject*>();
_stack = new ArrayList<HiObject*>();
_loop_stack = new ArrayList<Block*>();
_codes = codes;
_pc = 0;
}
int FrameObject::get_op_arg() {
int byte1 = _codes->_bytecodes->value()[_pc++] & 0xff;
int byte2 = _codes->_bytecodes->value()[_pc++] & 0xff;
return byte2 << 8 | byte1;
}
unsigned char FrameObject::get_op_code() {
return _codes->_bytecodes->value()[_pc++];
}
bool FrameObject::has_more_codes() {
return _pc < _codes->_bytecodes->length();
}
和它相应的,Interpreter的run方法也发生了很多变化。
// [runtime/interpreter.cpp]
// stack has been moved into FrameObject.
#define PUSH(x) _frame->stack()->add((x))
#define POP() _frame->stack()->pop()
#define STACK_LEVEL() _frame->stack()->size()
...
void Interpreter::run(CodeObject* codes) {
_frame = new FrameObject(codes);
while (_frame->has_more_codes()) {
unsigned char op_code = _frame->get_op_code();
bool has_argument = (op_code & 0xFF) >= ByteCode::HAVE_ARGUMENT;
int op_arg = -1;
if (has_argument) {
op_arg = _frame->get_op_arg();
}
...
}
}
除了上述代码所展示的修改以外,run 方法里还有很多处修改,这里我就不一一列出了,你可以通过工程提交记录自己比较代码还有哪些变化。
有了 FrameObject 这个基础结构以后,我们终于可以把注意力转向 MAKE_FUNCTION 和 CALL_FUNCTION 这两个字节码了。
创建 FunctionObject
有了代表栈帧的 FrameObject 和代表代码的 CodeObject,分别用于描述动态的活动记录和静态的代码信息,对于普通的编程语言就已经够了。但是在 Python 中,函数是第一类公民,所以虚拟机中还需要一个表示函数的对象。我们先来看一个例子。
def make_func(a):
def add(b):
return a + b
return add
add3 = make_func(3)
add5 = make_func(5)
print(add3(2))
print(add5(2))
在这个例子里,add 函数所对应的代码只有一份,也就是说,虚拟机在执行的过程中只需要一个 CodeObject 就可以了。但是,add3 和 add5 这两个函数却明显不相同,虽然它们的代码是相同的,但是因为绑定的参数不同,所以就成为了两个不同的函数。
从这个例子中,我们可以看出,CodeObject 所代表的静态代码和 FunctionObject 所代表的运行时构建出来的函数是有区别的。当我们把一个函数像变量一样用于函数返回值、参数等场景中,实际上使用的是 FunctionObject,而不是 CodeObject。
不同于 C 语言中的函数定义,FunctionObject 是一个真正的虚拟机对象。它可以被变量引用,也可以被添加到列表中。总之,所有可以对普通对象进行的操作,都可以施加到 FunctionObject 上。一个 CodeObject 可以对应多个 FunctionObject。
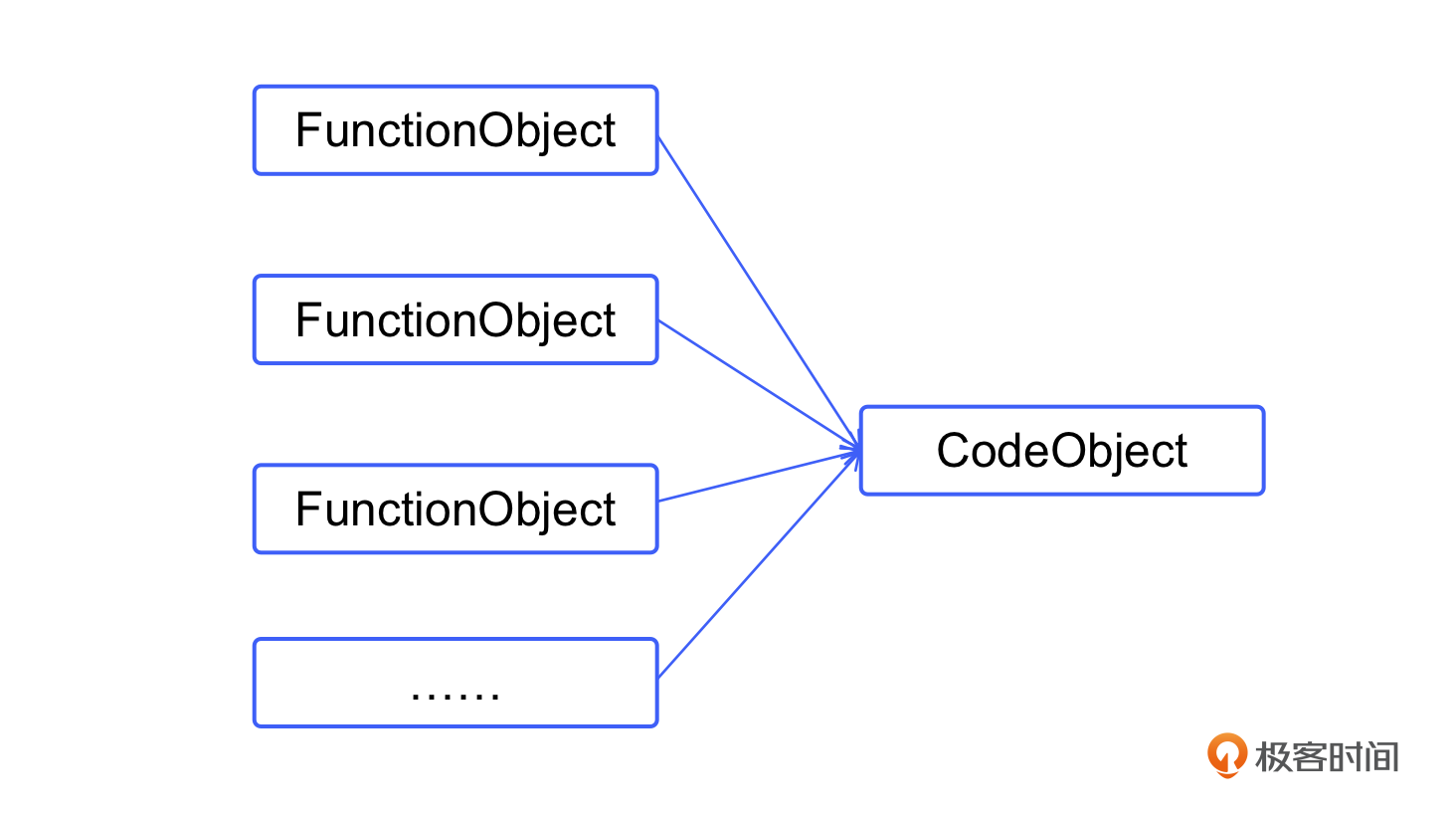
如上图所示,经过这些分析,我们可以这样定义 FunctionObject:
class FunctionKlass : public Klass {
private:
FunctionKlass();
static FunctionKlass* instance;
public:
static FunctionKlass* get_instance();
virtual void print(HiObject* obj);
};
class FunctionObject : public HiObject {
friend class FunctionKlass;
friend class FrameObject;
private:
CodeObject* _func_code;
HiString* _func_name;
unsigned int _flags;
public:
FunctionObject(HiObject* code_object);
FunctionObject(Klass* klass) {
_func_code = NULL;
_func_name = NULL;
_flags = 0;
set_klass(klass);
}
HiString* func_name() { return _func_name; }
int flags() { return _flags; }
};
FunctionObject 与普通的 Object 相比,并没有什么特别之处,所以它也要遵守 Klass-Oop 的二元结构。上述程序开始的地方定义的 FunctionKlass 用来指示对象的类型。
接下来定义的 FunctionObject 的属性也很简单,一个是指向自己所对应的 CodeObject 指针,还有一个代表了方法名称的字符串,最后一个属性 _flags,用于指示函数的类型,我们现在先不用,留到以后扩展。你可以看一下FunctionKlass 和 FunctionObject 中定义的方法实现。
FunctionKlass* FunctionKlass::instance = NULL;
FunctionKlass* FunctionKlass::get_instance() {
if (instance == NULL)
instance = new FunctionKlass();
return instance;
}
FunctionKlass::FunctionKlass() {
}
void FunctionKlass::print(HiObject* obj) {
printf("<function : ");
FunctionObject* fo = static_cast<FunctionObject*>(obj);
assert(fo && fo->klass() == (Klass*) this);
fo->func_name()->print();
printf(">");
}
FunctionObject::FunctionObject(HiObject* code_object) {
CodeObject* co = (CodeObject*) code_object;
_func_code = co;
_func_name = co->_co_name;
_flags = co->_flag;
set_klass(FunctionKlass::get_instance());
}
FunctionKlass 和其他的 Klass 一样,也采用了单例的实现方式。FunctionObject 的 print 方法,主要用于打印方法名。在 FrameObject 的构造函数里,把该对象的 klass 设置为 FunctionKlass。这就是上述代码的全部逻辑。
有了 FunctionObject,我们再来看 MAKE_FUNCTION 的具体实现,这个字节码的任务是通过 CodeObject,创建一个 FunctionObject。与这个功能相关的类和构造函数都已经实现好了,所以 MAKE_FUNCTION 的实现就很简单了。
void Interpreter::run(CodeObject* codes) {
_frame = new FrameObject(codes);
while (_frame->has_more_codes()) {
unsigned char op_code = _frame->get_op_code();
//...
FunctionObject* fo;
//...
switch (op_code) {
//...
case ByteCode::MAKE_FUNCTION:
v = POP();
fo = new FunctionObject(v);
PUSH(fo);
break;
//...
}
}
}
这里需要注意的是,MAKE_FUNCTION 指令本身是带有参数的,它是一个整数,代表了这个函数有多少个默认参数。我们现在还没有关心函数调用传参的问题,所以就先把 MAKE_FUNCTION 的参数忽略掉。
执行函数
有了函数对象,接下来我们就可以研究函数是如何被执行的了。
当函数被调用时,最关键的是正确地维护与这个函数相对应的 FrameObject。这节课开头我们已经介绍了,FrameObject 中存储了程序运行时所需要的所有信息,例如程序计数器、局部变量表等等。
当虚拟机执行一个函数的时候,需要为这个函数创建对应的 FrameObject;当一个函数的执行结束,也就是执行到 return 指令时,虚拟机就应该销毁对应的 FrameObject,然后回到调用者的栈帧中去。
为了维护这种函数调用时的栈帧切换,我们可以在 FrameObject 里增加一个链表项,将所有的 FrameObject 串起来,每次新增的 FrameObject 只能增加到链表的头部。同理,销毁时也只能从链表的头部进行删除。这样的话,FrameObject 的实现必须有所调整。
// runtime/frameObject.hpp
class FrameObject {
public:
FrameObject(CodeObject* codes);
FrameObject(FunctionObject* func);
...
FrameObject* _sender;
...
void set_sender(FrameObject* x) { _sender = x; }
FrameObject* sender() { return _sender;}
...
};
// runtime/frameObject.cpp
FrameObject::FrameObject (FunctionObject* func) {
_codes = func->_func_code;
_consts = _codes->_consts;
_names = _codes->_names;
_locals = new Map<HiObject*, HiObject*>();
_stack = new ArrayList<HiObject*>();
_loop_stack = new ArrayList<Block*>();
_pc = 0;
_sender = NULL;
}
FrameObject 中的构造函数发生了变化,新的实现中,它的参数变成了 FunctionObject。目前看来,这个构造函数与第一个版本,即以CodeObject为参数的那个构造函数,并没有太大的差别,但当后面我们的函数中有参数和返回值的时候,这两个构造函数就会产生差异了。
FrameObject 里还新增了 sender 这个域,这个域里会记录调用者的栈帧,当函数执行结束的时候,就会通过这个域返回到调用者的栈帧里。
前面我们介绍过,帧是用链表串起来的,创建的时候挂到链表头上,销毁的时候从链表头上的第一帧开始销毁。满足后进先出的特性,所以这是一个典型的栈结构,这再次表明了函数调用的活动记录被叫做栈帧的原因。
最后,我们可以实现 CALL_FUNCTION 这个字节码了。我们在 Interpreter 里增加一个 build_frame 方法,这个方法用于创建新的 FrameObject,被调用的方法的内部状态全部由新的 FrameObject 维护。这些内部状态包括程序计数器 pc、局部变量表 locals 等。
void Interpreter::run(CodeObject* codes) {
_frame = new FrameObject(codes);
while (_frame->has_more_codes()) {
unsigned char op_code = _frame->get_op_code();
...
FunctionObject* fo;
...
switch (op_code) {
...
case ByteCode::CALL_FUNCTION:
build_frame(POP());
break;
...
}
}
}
void Interpreter::build_frame(HiObject* callable) {
FrameObject* frame = new FrameObject((FunctionObject*) callable);
frame->set_sender(_frame);
_frame = frame;
}
这段代码里定义的 build_frame,将 FrameObject 切换到新函数后就立即退出,返回到 run 方法里继续执行。与调用 build_frame 方法之前不同的是,_frame 变量已经发生了变化。_frame里的程序计数器已经指向要调用的目标方法里了。
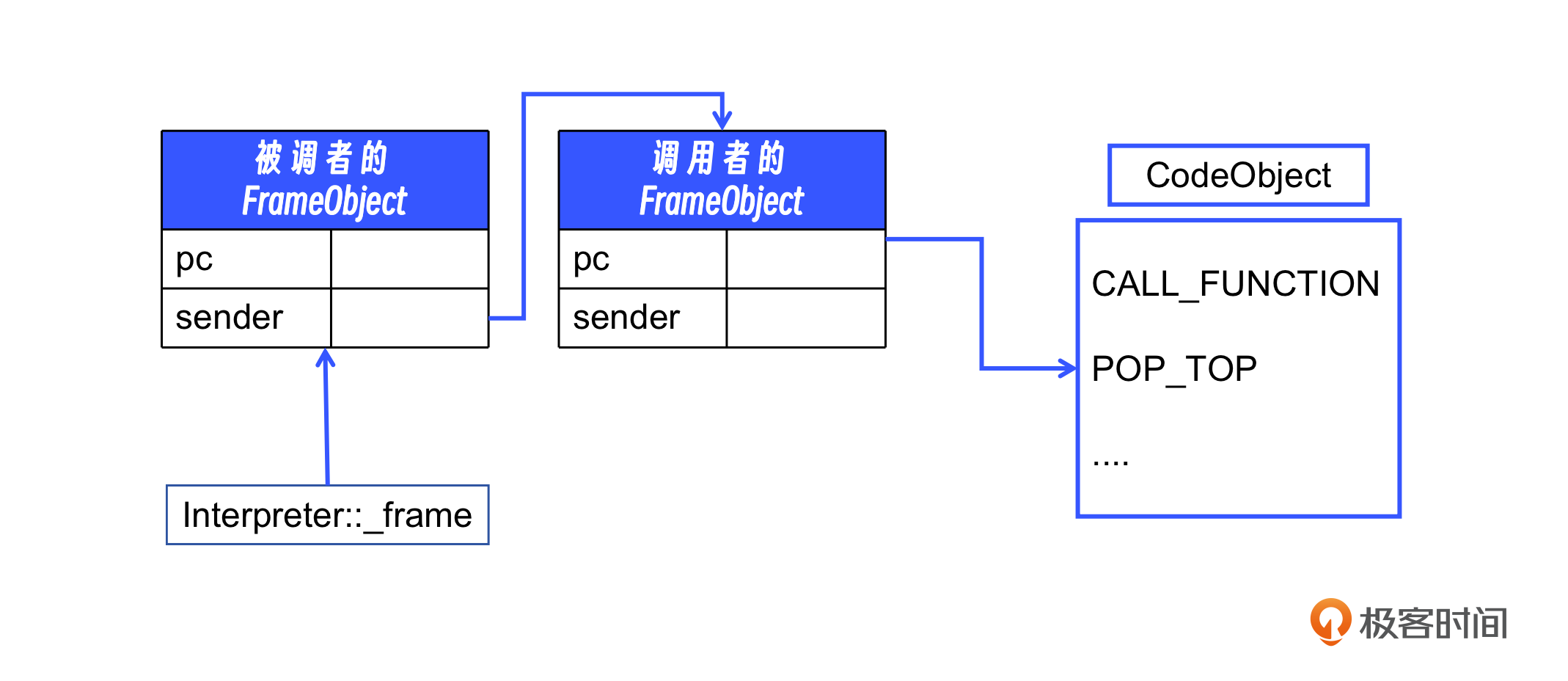
如上图所示,作为调用者,老的程序计数器还在它所对应的 FrameObject 里保存着,并且指向了CALL_FUNCTION 的下一条指令。而 _frame 变量现在指向了 foo 所对应的栈帧,当被调用的函数结束时,虚拟机就会把 _frame 变量重新指回调用者的 FrameObject,从而回到调用者的栈帧里继续执行。
所以,我们可以这样实现 RETURN_VALUE 字节码。
void Interpreter::run(CodeObject* codes) {
_frame = new FrameObject(codes);
eval_frame();
destroy_frame();
}
void Interpreter::eval_frame() {
...
while (_frame->has_more_codes()) {
unsigned char op_code = _frame->get_op_code();
...
FunctionObject* fo;
...
switch (op_code) {
...
case ByteCode::RETURN_VALUE:
_ret_value = POP();
if (_frame->is_first_frame())
return;
leave_frame();
break;
...
}
}
}
void Interpreter::leave_frame() {
destroy_frame();
PUSH(_ret_value);
}
void Interpreter::destroy_frame() {
FrameObject* temp = _frame;
_frame = _frame->sender();
delete temp;
}
class FrameObject {
...
bool is_first_frame() { return _sender == NULL; }
};
我们来分析一下RETURN_VALUE 字节码的具体实现,首先它将被调用函数的返回值赋给了 ret_value 变量(第 17 行),然后调用 leave_frame 方法离开当前函数栈帧。
leave_frame 方法做了三件事情。
- 使用 destroy_frame 方法将被调用者的 FrameObject 销毁(第36行)。
- 将 _frame 变量切换为自己的调用者的栈帧(第34行)。
- 将返回值 push 到调用者的栈帧中去(第29行)。
注意,这是我们的项目中第一次使用 delete 来销毁和释放一个对象,其他对象都没有通过这种方法释放。这是因为后面虚拟机的内部对象都会使用垃圾回收器进行自动管理,但是我们并不打算将 FrameObject 也纳入自动内存管理中。FrameObject 的生命周期是确定的,所以虚拟机就在能够释放的时候尽早释放,这样做对自动内存管理的性能是有好处的。
自动内存管理的相关知识,我们会在后面的章节中继续介绍。
如果某个 FrameObject 的 sender 为 NULL,就代表它是第一个栈帧,是程序开始的地方,或者说是“主程序”,因为它没有调用者。这种情况下,只需要直接结束 run 的逻辑即可,也就是直接通过 return 结束(第 19 行)。
同时,我们做一点代码的重构,将 run 方法的逻辑改得更清晰一点。就是把原来在 run 方法中的那些解释执行的逻辑搬到 eval_frame 方法中。而 run 方法则简化为创建 frame,对 frame 进行解释执行以及销毁 frame 三个步骤。这样可以使代码的可读性更高一些。
我们执行以下测试用例就会发现,函数的返回值机制已经完美地实现了。
增加了函数以后,变量的定义和作用域受到了很大的影响。下一节课,我们就将重新审视变量的实现方式。
总结
上一节课介绍了函数的静态信息和动态信息之后,我们这一节课就实现了相关的功能。这涉及到了2个关键的结构,CodeObject和FrameObject。其中,CodeObject 用于描述静态信息,FrameObject 用于描述动态信息。
由于 Python 语言中函数是第一类公民,这就意味着函数可以像变量一样作为返回值和参数进行传递,所以即使是同一份代码,也可以创建出多个不同的函数对象。这就要求虚拟机中要提供可以描述函数的对象,也就是 FunctionObject。
在实现了上述三个关键的数据结构以后,就可以实现 MAKE_FUNCTION 和 CALL_FUNCTION 两条字节码了。MAKE_FUNCTION 的作用是使用 CodeObject 创建 FunctionObject,CALL_FUNCTION 则是创建新的函数栈帧,并转入新的帧里执行。
当函数执行结束以后,遇到 RETURN_VALUE 指令。这个时候,虚拟机就退出当前栈帧,返回到调用者的栈帧中,并且把返回值带回到调用者栈帧中,这样就完成了一次函数调用。
定义函数会创建不同的变量的作用域,这对变量的使用产生了比较大的影响,所以下节课我们就将重新梳理和实现变量的相关功能。
思考题
请你多设计几个测试用例,验证把函数作为变量进行赋值是否可以正确执行。欢迎你把你验证后的结果分享到评论区,也欢迎你把这节课的内容分享给其他朋友,我们下节课再见!
- 骨汤鸡蛋面 👍(1) 💬(1)
续一个上次的评论,尝试总结下:字节码可以视为一个dsl文件,然后用c++写了一个程序/引擎去执行这个文件 ==> 这个c++程序有一些基本设计 Klass-Oop(包括内建class 与自定义class)来支持一个基本流程Interpreter.run,每一个字节码都对应一段代码的执行,也就是涉及的内建class与自定义class 新增、删除、方法的调用。
2024-05-26 - qinsi 👍(0) 💬(1)
示例代码似乎混进了旧版虚拟机的代码...根据代码库里的代码才跑起来. 测试程序生成的字节码里似乎有后面才会讲到的内容, 可能需要先囤几节课再一起看
2024-05-26 - ifelse 👍(0) 💬(0)
学习打卡
2024-10-24