06 循环语句:控制流让虚拟机执行复杂的运算
你好,我是海纳。
上一节课我们介绍了控制流中的第一种基本结构——分支语句。这一节课我们会介绍第二种基本结构——循环语句。
Python 中有两种循环结构,分别是 while 语句和 for 语句。Python 中的 while 语句和其他语言中的 while 语句差不多,但是 for 语句却和 C、C++、Java 等常见语言有很大的区别,Python 中的 for 语句本质上是一个迭代器。我们要等到实现了类机制以后,才能实现迭代器,所以这节课我们的重点是实现 while 循环。
实现变量
要实现循环结构,首先就要实现变量。在每次循环中,变量都应该有所变化,这样才能在若干次循环以后,破坏循环继续的条件,从而跳出这个循环。接下来我们就实现这个变量机制。我们还是从一个最简单的例子开始。
我们按照以前的方法把它编译成 pyc 文件,然后通过 show_file 工具查看它的字节码。
1 0 LOAD_CONST 0 (1)
2 STORE_NAME 0 (a)
2 4 LOAD_NAME 0 (a)
6 LOAD_CONST 0 (1)
8 BINARY_ADD
10 STORE_NAME 1 (b)
3 12 LOAD_NAME 2 (print)
14 LOAD_NAME 0 (a)
16 CALL_FUNCTION 1
18 POP_TOP
4 20 LOAD_NAME 2 (print)
22 LOAD_NAME 1 (b)
24 CALL_FUNCTION 1
26 POP_TOP
28 LOAD_CONST 1 (None)
30 RETURN_VALUE
consts
1
None
names ('a', 'b', 'print')
varnames ()
freevars ()
cellvars ()
在这个反编译的结果中出现了一个新的字节码:STORE_NAME(第2行)。同时,我们注意到,names 表里除了 print 之外又出现了两个字符串,它们正好就是测试代码里使用的那两个变量:a 和 b。
在介绍 pyc 文件结构的时候,我们已经说过了,names 表里放的是 CodeObject 所使用的变量的名字,这里正好通过实例验证了这一说法。
就像名字里暗示的那样,STORE_NAME 和 LOAD_NAME 跟 names 表有关系。在第一节课的图里,除了操作数栈之外,还有一个变量表。变量表的作用是记录在程序执行过程中,变量的实际值是多少。
要实现这两个字节码,我们就必须要先实现变量表。
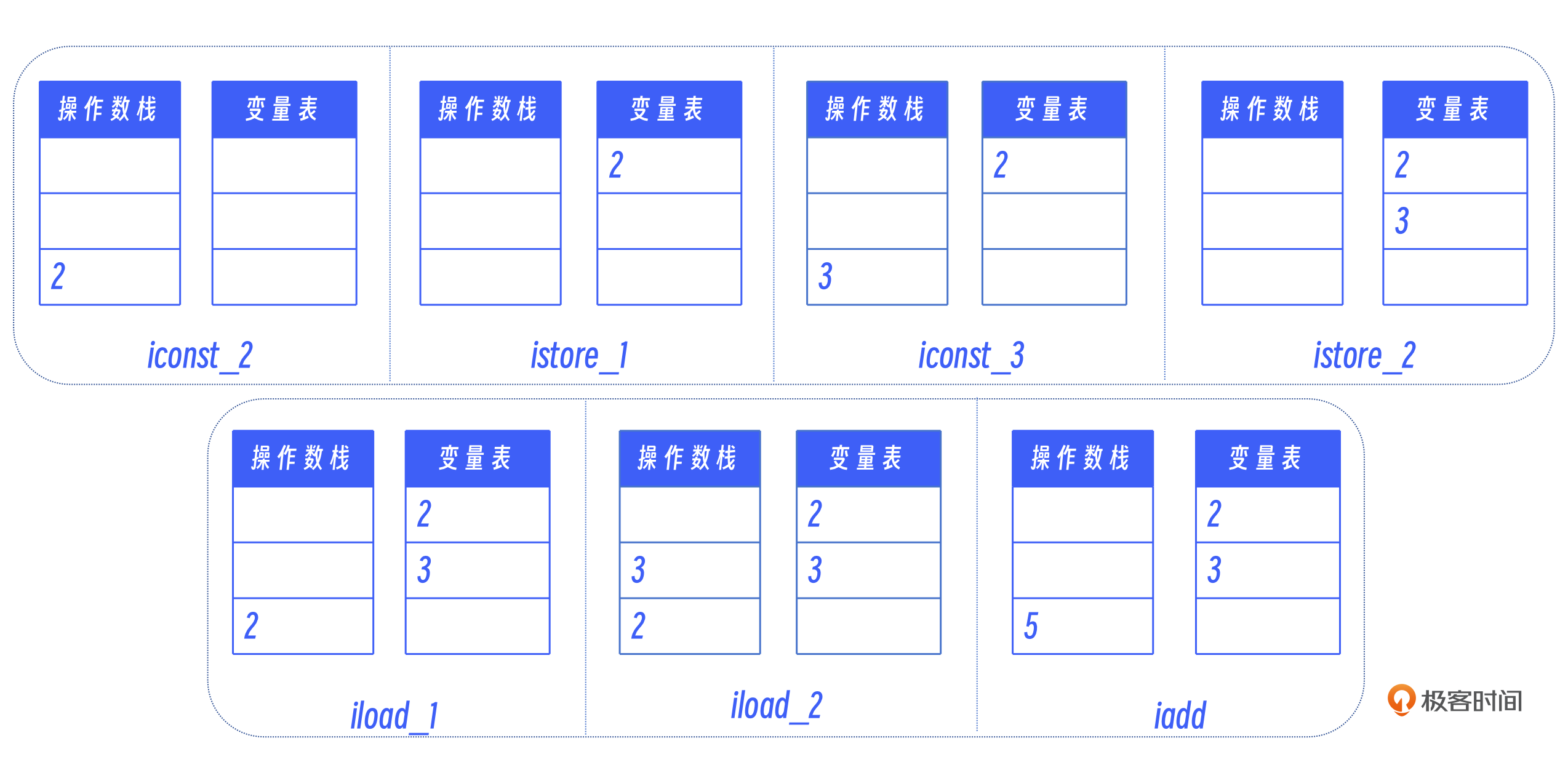
变量表是一个典型的键值(key-value)二元结构,它是一张表,每个键(key)都对应着一个值(value),键在这张表里是唯一的,不能重复。
这种结构,我们通常称之为 map。map 的实现有很多种,最常见的有基于哈希表的 HashMap,还有基于二叉排序树的 BinaryMap 等。由于 HashMap 要定义键的哈希函数,而有序的 map 又需要键之间的偏序关系,所以我们暂时都先不采用。
这里我们使用一种最简单的方式:直接使用数组实现。当插入一个键值对的时候,如果 map 里不包含 key,就直接插入。如果已经包含了 key,就把它原来的值更新成新的值。查询的时候,也是遍历整个数组,找到与查询的键相等的那个键,返回对应的值。
这里我给出一个简单的实现。
template <typename K, typename V>
class MapEntry {
public:
K _k;
V _v;
MapEntry(const MapEntry<K, V>& entry);
MapEntry(K k, V v) : _k(k), _v(v) {}
MapEntry() : _k(0), _v(0) {}
};
template <typename K, typename V>
class Map {
private:
MapEntry<K, V>* _entries;
int _size;
int _length;
void expand();
public:
Map();
int size() { return _size; }
void put(K k, V v);
V get(K k);
K get_key(int index);
bool has_key(K k);
V remove(K k);
int index(K k);
MapEntry<K, V>* entries() { return _entries; }
};
Map 的定义与 ArrayList 十分相似,内存都是可以按需增长的。其中,put 方法可以把键值对存入 Map 结构中。index 方法可以返回参数 k 在 _entries 数组中的序号。其他的方法,比如get、remove,都和它们名字所指示的意义一样,用于获取值和删除键值对。
接下来就可以实现 Map 里定义的所有函数了。我建议你不要照着课程中的代码抄,最好是自己实现一遍 Map 这种结构。这是一个很好的练手机会。为了提高编程水平,不断地练习是必不可少的。
template <typename K, typename V>
Map<K, V>::Map() {
_entries = new MapEntry<K, V>[8];
_length = 8;
_size = 0;
}
template <typename K, typename V>
MapEntry<K, V>::MapEntry(const MapEntry<K, V>& entry) {
_k = entry._k;
_v = entry._v;
}
template <typename K, typename V>
void Map<K, V>::put(K k, V v) {
for (int i = 0; i < _size; i++) {
if (_entries[i]._k->equal(k) == Universe::HiTrue) {
_entries[i]._v = v;
return;
}
}
expand();
_entries[_size++] = MapEntry<K, V>(k, v);
}
template <typename K, typename V>
bool Map<K, V>::has_key(K k) {
int i = index(k);
return i >= 0;
}
template <typename K, typename V>
V Map<K, V>::get(K k) {
int i = index(k);
if (i < 0)
return Universe::HiNone;
else
return _entries[i]._v;
}
template <typename K, typename V>
int Map<K, V>::index(K k) {
for (int i = 0; i < _size; i++) {
if (_entries[i]._k->equal(k) == Universe::HiTrue) {
return i;
}
}
return -1;
}
template <typename K, typename V>
void Map<K, V>::expand() {
if (_size >= _length) {
MapEntry<K, V>* new_entries = new MapEntry<K, V>[_length << 1];
for (int i = 0; i < _size; i++) {
new_entries[i] = _entries[i];
}
_length <<= 1;
delete[] _entries;
_entries = new_entries;
}
}
template <typename K, typename V>
V Map<K, V>::remove(K k) {
int i = index(k);
if (i < 0)
return 0;
V v = _entries[i]._v;
_entries[i] = _entries[--_size];
return v;
}
template <typename K, typename V>
K Map<K, V>::get_key(int index) {
return _entries[index]._k;
}
template class Map<HiObject*, HiObject*>;
这段代码虽然行数很多,但是逻辑都很简单。有两个地方是你需要注意的。第一处是 put 方法的实现(第15行)。由于 Map 中的 key 是唯一的,不会重复,所以在往 Map 插入键值对的时候,需要先检查 Map 中是否已经存在相同的 key 了。如果存在,就直接更新它的值,如果不存在,再插入键值对。
第二处要注意的是 remove 方法的实现。由于 Map 中的元素没有先后顺序的要求,所以我们可以将键值对任意排列。当要删除容器中的某一个元素的时候,我们只需要将最后一个元素与待删除元素交换位置,这样待删除元素就出现在最后一位了。这个时候只需要把最后一个元素删除就可以了。而我们知道,删除最后一个元素是非常高效的,把 size 变量减 1 就可以实现了。
有了 map 结构,我们就可以进一步实现变量表了。解释器中的变量表是一个以字符串为键的 map 结构,变量名存储在 CodeObject 的 names 列表中。所以,我们就可以这样实现变量表:
void Interpreter::run(CodeObject* codes) {
// ...
HiList* names = codes->_names;
Map<HiObject*, HiObject*>* locals = new Map<HiObject*, HiObject*>();
while (pc < code_length) {
unsigned char op_code = codes->_bytecodes->value()[pc++];
short op_arg = (codes->_bytecodes->value()[pc++] & 0xFF);
// ....
switch (op_code) {
case ByteCode::LOAD_NAME:
v = names->get(op_arg);
w = locals->get(v);
PUSH(w);
break;
case ByteCode::STORE_NAME:
v = names->get(op_arg);
locals->put(v, POP());
break;
//....
}
}
}
在变量表的基础上,我们进一步支持了 LOAD_NAME 和 STORE_NAME 两个字节码。
STORE_NAME 的作用是在局部变量表 locals 写入变量的值。变量的名称是一个字符串,存储在 names 中,所以要先从 names 中取出变量名(第 20 行),然后以变量名为键,将值写入变量表(第21行)。
LOAD_NAME 的过程与 STORE_NAME 相反,它负责从变量表里取出值。
由于循环结构的实现依赖于循环变量的迭代修改,所以在实现了变量的功能以后,我们才可以进一步支持循环结构。下面我们就开始实现循环结构。
循环内的跳转
在循环内有三种跳转,第一种是循环体正常执行,正常结束;第二种是使用 continue 语句,跳转回循环头部再进行条件判断;第三种是使用 break 语句,跳转到循环结束处。每一次循环体执行结束以后,都要跳到循环开始的地方再进行条件判断,来决定是否进入下一次循环。举一个最简单的例子,为了方便研究,我们把源代码和字节码混合在一起打印。
i = 0
1 0 LOAD_CONST 0 (0)
2 STORE_NAME 0 (i)
while i < 2:
2 4 LOAD_NAME 0 (i)
6 LOAD_CONST 1 (2)
8 COMPARE_OP 0 (<)
10 POP_JUMP_IF_FALSE 20 (to 40)
print(i)
3 >> 12 LOAD_NAME 1 (print)
14 LOAD_NAME 0 (i)
16 CALL_FUNCTION 1
18 POP_TOP
i = i + 1
4 20 LOAD_NAME 0 (i)
22 LOAD_CONST 2 (1)
24 BINARY_ADD
26 STORE_NAME 0 (i)
2 28 LOAD_NAME 0 (i)
30 LOAD_CONST 1 (2)
32 COMPARE_OP 0 (<)
34 POP_JUMP_IF_TRUE 6 (to 12)
36 LOAD_CONST 3 (None)
38 RETURN_VALUE
>> 40 LOAD_CONST 3 (None)
42 RETURN_VALUE
从这个反编译结果中,我们可以看到,这里面只有一个新增的字节码,那就是 POP_JUMP_IF_TRUE。除了它之外,其他的字节码我们都已经很熟悉了。
注:不同版本的编译器得到的字节码可能会有很大的不同,例如Python 2.7会使用JUMP_ABSOLUTE来实现绝对跳转。
如果循环判断不成功,就使用 POP_JUMP_IF_FALSE,跳过整个循环体。这个机制与 if 语句完全相同,这里不再赘述。
好了,到此为止,我们就把 while 循环所需要的字节码全部实现了。你可以编译运行一下,上面举的例子虽然简单,但都是可以运行的。比如下面的代码作用是打印 Fibonacci 数列的前10项,编译之后,在我们的虚拟机上就可以正确地打印出结果。
实现continue语句
影响 while 控制流的两个重要的关键字,分别是 continue 和 break。continue 的作用是直接跳到循环开始的地方进行条件判断,来决定是否要执行下一次循环。这种跳转将 continue 后面的循环体部分直接跳过了。
在查看 continue 的具体实现之前,我们可以猜想一下,这种跳转并不需要额外的数据结构,那是不是只要一个绝对跳转语句就可以实现呢?我们写一个例子验证一下。
i = 0
while i < 10:
3 >> 4 LOAD_NAME 0 (i)
6 LOAD_CONST 1 (10)
8 COMPARE_OP 0 (<)
10 POP_JUMP_IF_FALSE 25 (to 50)
if i < 2:
4 >> 12 LOAD_NAME 0 (i)
14 LOAD_CONST 2 (2)
16 COMPARE_OP 0 (<)
18 POP_JUMP_IF_FALSE 11 (to 22)
continue
5 20 JUMP_ABSOLUTE 2 (to 4)
print(i)
7 >> 22 LOAD_NAME 1 (print)
24 LOAD_NAME 0 (i)
26 CALL_FUNCTION 1
28 POP_TOP
i = i + 1
我们只展示了最关键的部分。注意位置为 20 的那条 JUMP_ABSOLUTE 指令(第 18 行),它就是continue 语句翻译出来的结果。Python 通过绝对跳转来实现 continue 语义。
JUMP_ABSOLUTE 这个字节码的作用是当循环体执行结束以后,跳到循环开始的位置,进行条件判断来决定是否进入下一次循环。它的参数是一个绝对地址,例如在刚刚那个例子里,参数是 9,就代表下一个要执行的字节码位置是9。我们看一下位置为 9 的那条字节码,恰好就是 i < 2 这个比较开始的地方。所以这条字节码的实现如下:
// code/bytecode.hpp
class ByteCode {
......
static const unsigned char JUMP_ABSOLUTE = 113;
......
};
// runtime/interpreter.cpp
void Interpreter::run(CodeObject* codes) {
....
while (pc < code_length) {
switch (op_code) {
case ByteCode::JUMP_ABSOLUTE:
pc = op_arg;
break;
....
}
}
}
如果循环判断不成功,就使用 POP_JUMP_IF_FALSE 跳过整个循环体,这个机制与 if 语句完全相同,这里不再赘述。
到此为止,这节课的 continue 的例子就可以正常执行了。接下来我们实现第三种跳转——break语句。
我们先用一个简单的例子来测试一下。
得到的字节码如下所示:
1 0 LOAD_CONST 0 (0)
2 STORE_NAME 0 (i)
3 4 LOAD_NAME 0 (i)
6 LOAD_CONST 1 (5)
8 COMPARE_OP 0 (<)
10 POP_JUMP_IF_FALSE 23 (to 46)
4 >> 12 LOAD_NAME 1 (print)
14 LOAD_NAME 0 (i)
16 CALL_FUNCTION 1
18 POP_TOP
5 20 LOAD_NAME 0 (i)
22 LOAD_CONST 2 (3)
24 COMPARE_OP 2 (==)
26 POP_JUMP_IF_FALSE 15 (to 30)
6 28 JUMP_FORWARD 8 (to 46)
7 >> 30 LOAD_NAME 0 (i)
32 LOAD_CONST 3 (1)
34 BINARY_ADD
36 STORE_NAME 0 (i)
3 38 LOAD_NAME 0 (i)
40 LOAD_CONST 1 (5)
42 COMPARE_OP 0 (<)
44 POP_JUMP_IF_TRUE 6 (to 12)
9 >> 46 LOAD_NAME 1 (print)
48 LOAD_NAME 0 (i)
50 CALL_FUNCTION 1
52 POP_TOP
54 LOAD_CONST 4 (None)
56 RETURN_VALUE
第 17 行的 POP_JUMP_IF_FALSE 代表了 (i==3) 这个条件不满足的时候,应该继续执行循环体。第 19 行的 JUMP_FORWARD 则代表 (i == 3) 条件满足时,应该直接跳到循环体结尾处。
到这里,分支语句和循环语句就全部实现完了。你可以在自己的虚拟机上实验下面这个循环嵌套代码,看看是否能正确执行。
总结
这节课我们实现了循环语句。变量的读写操作和跳转指令支撑了循环语句的实现。
第一部分我们实现了变量的读写操作。在解释器里,除了操作数栈之外,最重要的数据结构就是变量表了。变量表采用关联数据结构,也就是 Map 来实现。LOAD 和 STORE 操作就是针对变量表的读写。
第二部分我们重点实现了 POP_JUMP_IF_TRUE 指令。它的实现是比较简单的,这里需要你重点理解 while 语句是如何对应到这条跳转指令的。
第三部分我们分析了 continue 语句和 break 语句,并重点实现了 JUMP_ABSOLUTE 指令。这是一条绝对跳转指令。通过以上几种跳转指令,循环语句就全部能运行了,包括比较复杂的嵌套循环语句也能正常执行。
相比于2.7版本的字节码,3.8版本的循环语句极大地简化了。如果你有余力的话,也可以研究一下Python 2.7的字节码是如何实现的。
到此为止,虚拟机已经具备了一定的计算能力。在过去的两节课中,我们遇到过很多次需要处理对象的情况。当时我们都是通过一些手段把问题回避过去了,那么下节课我们就应该把对象体系重新梳理一下,让它能够支持整数、浮点数、字符串等更多的基本数据类型。
思考题
老版本的Python字节码中,有一个BREAK_LOOP指令,你可以研究一下这条指令,然后思考为什么新版本的虚拟机中不需要这条指令了。期待你把你的答案分享到评论区,如果你觉得这节课的内容对你有帮助的话,也欢迎你分享给其他朋友。我们下节课再见!
- Se7en 👍(3) 💬(2)
有人看到这里吗
2024-05-17 - Se7en 👍(0) 💬(0)
关于思考题,我节选了一下python3.8文档的内容 POP_FINALLY(preserve_tos) Cleans up the value stack and the block stack. If preserve_tos is not 0 TOS first is popped from the stack and pushed on the stack after performing other stack operations: If TOS is NULL or an integer (pushed by BEGIN_FINALLY or CALL_FINALLY) it is popped from the stack. If TOS is an exception type (pushed when an exception has been raised) 6 values are popped from the stack, the last three popped values are used to restore the exception state. An exception handler block is removed from the block stack. It is similar to END_FINALLY, but doesn’t change the bytecode counter nor raise an exception. Used for implementing break, continue and return in the finally block. New in version 3.8.
2024-12-06 - Se7en 👍(0) 💬(0)
关于思考题,我节选了一下文档的内容 It is similar to END_FINALLY, but doesn’t change the bytecode counter nor raise an exception. Used for implementing break, continue and return in the finally block.
2024-12-06 - ifelse 👍(0) 💬(0)
学习打卡
2024-10-21