04 字节码文件:编译器与虚拟机的标准合约
你好,我是海纳。
从上一节课的例子中可以看出,字节码文件在整个 Python 语言的实现中位于中枢地位,这一节课,我们就聚焦字节码文件的格式,目标是把 Python 3.8 的字节码成功地加载进内存。
CPython 虚拟机既可以执行 py 文件,也可以执行编译过的 pyc 文件,这是因为 CPython 里包含了一个可以编译 py 文件的编译器,在执行 py 文件时,第一步就是要把 py 文件先翻译成字节码文件。
接下来,我们将深入分析 pyc 文件结构,实现 pyc 文件的解析,将文件内容加载进内存,并且做好执行的准备。
字节码文件格式
我们先准备一个 pyc 文件。新建一个名为 hello.py 的文件,内容如下:
然后执行 python -m compileall hello.py 命令,就可以得到 hello.pyc 文件。还有一种办法,就是直接运行 python 命令,进入 CPython 的交互式界面,然后执行 import hello,也可以生成 hello.pyc 文件。
# python3
Python 3.10.13 (main, Feb 19 2024, 20:13:37) [GCC 9.4.0] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> import hello
255
对于 Python 3.x 版本,生成的二进制文件位于__pycache__下。
在 Windows 系统上,可以通过 Notepad++、UltraEdit 等 16 进制查看工具来打开 pyc 文件。在 Linux 系统上,则可以通过 xxd 命令来查看这个文件的内容。
# xxd hello.cpython-310.pyc
00000000: 6f0d 0d0a 0000 0000 1f47 d365 0b00 0000 o........G.e....
00000010: e300 0000 0000 0000 0000 0000 0000 0000 ................
00000020: 0002 0000 0040 0000 0073 0c00 0000 6500 .....@...s....e.
00000030: 6400 8301 0100 6401 5300 2902 e9ff 0000 d.....d.S.).....
00000040: 004e 2901 da05 7072 696e 74a9 0072 0300 .N)...print..r..
00000050: 0000 7203 0000 00fa 0868 656c 6c6f 2e70 ..r......hello.p
00000060: 79da 083c 6d6f 6475 6c65 3e01 0000 0073 y..<module>....s
00000070: 0200 0000 0c00 ......
视频讲解字节码:
接下来,我们一起研究 pyc 文件的各个组成部分。
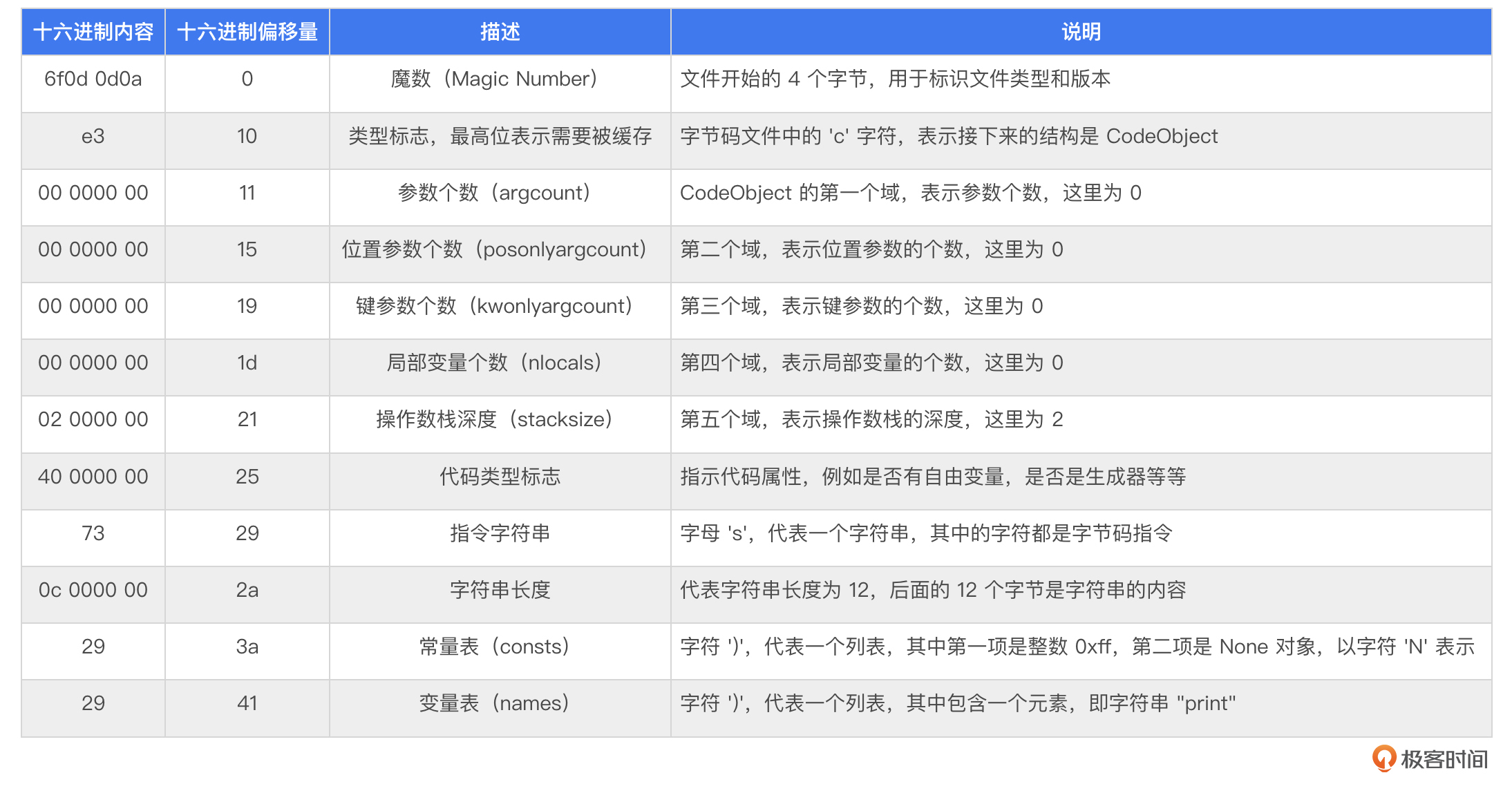
pyc 文件的头部包含四个部分。2.7 版本的字节码文件只有两个部分,分别是魔数和文件时间戳。3.8 版本则扩展为四个,这是由 PEP 552 规范 引入的,新引入的第二字段和第四字段对我们实现一个简单的虚拟机没有太大影响,所以这里就不再介绍了,如果你感兴趣的话可以阅读PEP文档了解一下。
文件开始的 4 个字节代表一个整数,被称为魔数(magic number),用于标识文件类型和版本。需要注意的是,文件中高字节存储在高位,低字节存储在低位。不同版本的字节码文件,魔数不相同。使用 Python 3.8 编译得到的 pyc 文件的魔数是 0xa0d0d55。
前面我们讲过,第二部分也是 4 个字节,这里不再重复了。
第三部分是字节码文件的创建时间,用 4 个字节记录了一个时间戳,只需要简单地将它读出来就可以了,目前对我们的意义也不大。如果你有兴趣,可以将它转换成具体的时间并打印出来,方便验证。
接下来一定会是一个字符 'c',在字节码文件中就是 16 进制的 0xe3。在老的版本文件里,这个字符是 0x63,正好是字符 'c' 的 ASCII 码,但是在 Python 3.x 版本里,标识字符的最高位被用于 REF 标志,起到优化文件结构的作用。
类型标志的最高位如果置为 1,就代表这个值应该被缓存起来,如果下一次遇到字符 'r' 时,就直接从缓存表里根据下标找到这个缓存值。所以这段字节串将会被缓存,并且其序号为 0。
直接将 0xe3 与 0x7f 进行与运算,可以将高位清零,从而得到字符 'c'。
这个字符的意义是告诉我们接下来是一个CodeObject结构。这个是虚拟机中的核心结构,下面我来详细解释这个结构。
CodeObject结构
CodeObject 的第一个域是一个整数,代表参数个数,我们记为 argcount。可以看到,在 hello.pyc 这个例子中,argcount 的值为 0。第二个域也是一个整数,代表位置参数的个数,记为posonlyargcount。在当前的例子里,它的值为 0。
第三个域是一个整数,代表键参数的个数,记为kwonlyargcount。在当前例子中,它的值为 0。位置参数和键参数是 Python 在调用函数时两种特殊的传递参数的方式,在实现函数机制的时候,我们会详细地介绍。
第四个域是一个整数,代表局部变量的个数,记为 nlocals,在当前的例子中也是 0。第五个域是一个整数,代表执行这段 code 所使用的操作数栈的深度的最大值,记为 stacksize,在现在的例子中,值是 2。第六个域是一个整数,代表 code 的属性值,记为 flags,值为 0x40。介绍函数时,我们会详细讲到,这里先略过。
再接下来就是我们这节课要介绍的重点了——字节码。它以一个字符 's' 开头,接下来是一个整数,代表了这段 code 的字节码长度。在 xxd 结果的第二行,我们可以看到在字符 's' 后面紧跟着一个整数 0xc,这就代表了这段字节码的长度是12。接下来的 12 个字节,就是字节码了。
在字节码之后,是常量表,记为 consts,里面存着程序所使用的所有常量。它是一个元组,在现阶段,我们可以把它理解成一个列表,或者是数组。这个元组以字符 ')' 作为开头,紧接着的是一个整数,代表了元组中的元素个数,可以看到,常量表的元素个数为 2。接着就是常量表中的 2 个元素。
第一个元素的类型由字符 'i' 表示,这里它的十六进制数是 0xe9,去掉最高位以后就是0x69,也就是字符 'i',同时,它也应该被缓存,缓存序号为 1,这表示第一个元素是一个整数,它的值是接下来的四个字节,也就是 0xff,这正是源码中整数 255 的十六进制表示。
再往后就是一个字符 'N',代表了 Python 中的 None,这里我们先不关心这个 None 是什么,在后面实现对象系统的时候,你自然就会知道这个 None 是怎么来的。常量表到这里就结束了。
接下来是变量表,记为 names。在一个 ')' 字符之后,紧跟一个整数 1,代表变量表只有一个元素。这个元素的类型是 'Z'(第6行的0xda,去掉最高位以后就是0x5a,是 'Z' 的ASCII码值),代表这是一个字符串,同时这个字符串应该被缓存,序号为 2。字符串的长度为 5,其值为 print,这正是源代码中使用的函数名字。
字节码文件中代表字符串类型的字符有 6 种,分别是:
- 字符
's',虚拟机内部表示为 TYPE_STRING,普通的字符串、字节码是这种类型的。 - 字符
't',内部表示为 TYPE_INTERNED,也是字符串,但是这个字符串应该被缓存到缓冲区里,下一次使用时,可以直接使用序号进行引用,不需要将相同的字符串再编码一次。 - 字符
'a',内部表示为 TYPE_ASCII,代表字符串中的每个字符都是不超过 255 的一个字符。 - 字符
'A',内部表示为 TYPE_ASCII_INTERNED,代表字符串的字符都是不超过 255 的一个字符,而且这个字符应该被缓存。 - 字符
'z',内部表示为 TYPE_SHORT_ASCII,代表字符串中的每个字符都是不超过 128 的字符,大多数键盘可以输入的字符。 - 字符
'Z',内部表示为 TYPE_SHORT_ASCII_INTERNED,代表字符串中的每个字符都是不超过 128 的字符,而且字符串应该被缓存。
变量表之后则是参数列表。这一项只在函数和方法里有用,代表了函数的输入参数。这里可以先略过。这个空的参数列表的类型标志是 ')',字节码文件中的值是 0xa9,所以它的最高位是 1,代表它也应该被缓存,序号是 3。
接下来还有两个空的元组,分别是 cell_var 和 free_var。它们在字节码文件中不是使用 ')' 来标志的,而是使用 'r',并且序号是 3,也就是说这两个值需要在缓存列表中查找,而缓存列表中序号为 3 的值正是前面说的参数列表。
cell_var 和 free_var 用于构建闭包(Clousre),闭包是 Python 函数中的核心机制之一,在讲解函数的时候,我们会重点介绍它,这里先略过。
再接下来则是一个字符 'z',我们前面介绍过,这代表一个字符串,接下来是一个整数,代表了字符串的长度,可以看到这个字符串长度为 8,其值为 "hello.py",代表了源文件的名字。
再接下来是一个字符 'Z',它也是一个字符串,格式与 's' 是完全相同的。代表了当前code所属模块。
最后一项也是一个字符串,以字符 's' 标志。它是一个名为 line number table 的结构,在实现 Traceback 时,我们要打印详细的调用栈,会使用这个数据结构。这里就先略过。
加载CodeObject
经过上面的分析,我们大概了解了一个 .pyc 文件的结构,接下来就可以写一个 .pyc 文件的分析程序,在内存中重建 CodeObject,然后尝试着去执行它。
我们要做的第一件事就是写程序打开 .pyc 文件,并将其内容按结构读入。上一节课我们已经实现了打开文件和读取数据的功能,这里继续实现相关的结构。第一个要实现的结构就是列表。
实现列表
为了节约地使用内存,我们希望这个列表是可以动态扩展的。这样的话,可以在一开始让列表的容量小一些,当元素越来越多的时候,再重新分配内存。另外,列表作为一个容器,我们希望它能容纳各种类型的元素,所以这里我们使用模板来实现列表。
#ifndef ARRAY_LIST_HPP
#define ARRAY_LIST_HPP
#include <stdio.h>
template <typename T>
class ArrayList {
private:
int _length;
T* _array;
int _size;
void expand();
public:
ArrayList(int n = 8);
void add(T t);
void insert(int index, T t);
T get(int index);
void set(int index, T t);
int size();
int length();
T pop();
};
#endif
ArrayList 类里定义了元素数组的大小 _capacity,指向元素数组的指针 _array,并且使用 _length 来指示当前列表里有多少个有效元素。然后又定义了 add 方法,用来向列表的末尾插入元素,insert 方法向指定的位置插入元素,get 方法用来获取指定位置的元素,set 方法用来设置指定位置的元素。
私有方法 expand 的作用是当有效元素数量超过元素数组容量的时候,可以扩展元素数组。你可以看一下它的具体实现。
#include "arrayList.hpp"
#include <stdio.h>
template <typename T>
ArrayList<T>::ArrayList(int n) {
_length = n;
_size = 0;
_array = new T[n];
}
template <typename T>
void ArrayList<T>::add(T t) {
if (_size >= _length)
expand();
_array[_size++] = t;
}
template <typename T>
void ArrayList<T>::insert(int index, T t) {
add(NULL);
for (int i = _size; i > index; i--) {
_array[i] = _array[i - 1];
}
_array[index] = t;
}
template <typename T>
void ArrayList<T>::expand() {
T* new_array = new T[_length << 1];
for (int i = 0; i < _length; i++) {
new_array[i] = _array[i];
}
_array = new_array;
delete[] _array;
_length <<= 1;
printf("expand an array to %d, size is %d\n", _length, _size);
}
template <typename T>
int ArrayList<T>::size() {
return _size;
}
template <typename T>
int ArrayList<T>::length() {
return _length;
}
template <typename T>
T ArrayList<T>::get(int index) {
return _array[index];
}
template <typename T>
void ArrayList<T>::set(int index, T t) {
if (_size <= index)
_size = index + 1;
while (_size > _length)
expand();
_array[index] = t;
}
template <typename T>
T ArrayList<T>::pop() {
return _array[--_size];
}
代码的逻辑比较简单,就不再过多解释了。
这节课的例子中还包括了字符串和整数,所以要解析这个字节码文件,还要进一步支持字符串和整数。第二节课我们已经实现了字符串的基本功能,接下来要将它统一到 Python 的对象体系中。
重构字符串
在 Python 中,所有的数据都是对象,字符串、整数、浮点数是对象,甚至类定义、模块、函数也是对象。它们都有共同的基类 object。这里我们也引入了一个超类,定义为 HiObject。它就是 Python 语言中的超基类 object。
虚拟机中处理的所有数据都将会是一个 HiObject 的实例。整数、字符串也同样会是它的子类。你可以看一下HiObject 的定义。
// object/hiObject.hpp
#ifndef _HI_OBJECT_HPP
#define _HI_OBJECT_HPP
class HiObject {
public:
virtual void print() {
printf("This is an object.\n");
}
};
#endif
然后重构上一节课所实现的字符串类,使它继承自 HiObject。
HiString 类的实现没有任何改动,我们只是修改了它的类继承结构,通过这种方式就可以实现语言的泛型能力。
实现整数
在 Python 中,整数也是对象。因此,我们也选择实现整数类,继承自 HiObject,其定义如下:
#ifndef _HI_INTEGER_HPP
#define _HI_INTEGER_HPP
#include "hiObject.hpp"
class HiInteger : public HiObject {
private:
int _value;
public:
HiInteger(int x);
int value() { return _value; }
};
#endif
整数类的定义非常简单,我就不再讲解了。
到这里,我们已经把解析 pyc 所需要的工具类全部准备好了。接下来,就是要使用这些工具去完成这节课的最终目标,从文件中读入字节流,并在内存中建立 CodeObject。
创建 CodeObject
开头我们分析过 pyc 文件的结构,我们讲到 CodeObject 里,包含了常量表、变量表、参数列表、字节码、行号表等等。根据这些属性,我们来定义 CodeObject。
class CodeObject : public HiObject {
public:
int _argcount;
int _posonlyargcount;
int _kwonlyargcount;
int _nlocals;
int _stack_size;
int _flag;
HiString* _bytecodes;
HiList* _names;
HiList* _consts;
HiList* _var_names;
HiList* _free_vars;
HiList* _cell_vars;
HiString* _co_name;
HiString* _file_name;
int _lineno;
HiString* _notable;
CodeObject(int argcount, int posonlyargcount, int kwonlyargcount, int nlocals, int stacksize,
int flag, HiString* bytecodes, HiList* consts,
HiList* names, HiList* varnames, HiList* freevars, HiList* cellvars,
HiString* file_name, HiString* co_name, int lineno, HiString* notable);
};
在定义了 CodeObject 之后,终于可以开始解析的工作了。接下来我们就继续完善 BinaryFileParser 类来完成这个工作。
我们先重构它的 parse 方法。
CodeObject* BinaryFileParser::parse() {
int magic_number = file_stream->read_int();
printf("magic number is 0x%x\n", magic_number);
int file_flag = file_stream->read_int();
// 打印时间戳
char buffer[80];
time_t moddate = (time_t)file_stream->read_int();
struct tm * timeinfo = localtime(&moddate);
strftime(buffer, 80, "%Y-%m-%d %H:%M:%S", timeinfo);
printf("%s\n", buffer);
int file_size = file_stream->read_int();
printf("size of source file is %d\n", file_size);
char object_type = file_stream->read();
bool ref_flag = (object_type & 0x80) != 0;
object_type &= 0x7f;
if (object_type == 'c') {
// 这里需要先占位
int index = 0;
if (ref_flag) {
index = _cache.size();
_cache.add(NULL);
}
CodeObject* result = get_code_object();
if (ref_flag) {
_cache.set(index, result);
}
printf("parse OK!\n");
return result;
}
return NULL;
}
BinaryFileParser 类中还定义了很多用于解析各种数据结构的函数,它们的逻辑相对简单而且有一些重复的代码,所以这里我就不详细列出了,你可以通过代码仓库自行查看。
执行 parse 函数,虚拟机就从字节码文件中成功加载了 CodeObject。接下来,我们实现一个简单的解释器来执行字节码,进一步验证 CodeObject 是正确的。
执行字节码
就像我们前面分析的,字节码是一个字符串,位于 CodeObject 的 _code 属性里,所以解释器也要做相应的修改。你可以看一下它的代码。
void Interpreter::run(CodeObject* codes) {
int pc = 0;
int code_length = codes->_bytecodes->length();
_stack = new ArrayList<HiObject*>(codes->_stack_size);
_consts = codes->_consts;
while (pc < code_length) {
unsigned char op_code = codes->_bytecodes->value()[pc++];
short op_arg = (codes->_bytecodes->value()[pc++] & 0xFF);
HiInteger* lhs, * rhs;
HiObject* v, * w, * u, * attr;
switch (op_code) {
case ByteCode::LOAD_CONST:
_stack->add(_consts->get(op_arg));
break;
case ByteCode::LOAD_NAME:
// "print", do nothig.
_stack->add(nullptr);
break;
case ByteCode::CALL_FUNCTION:
v = _stack->pop();
v->print();
printf("\n");
break;
case ByteCode::POP_TOP:
_stack->pop();
break;
case ByteCode::RETURN_VALUE:
_stack->pop();
break;
default:
printf("Error: Unrecognized byte code %d\n", op_code);
}
}
}
这段代码有几个点需要关注。
- run 方法的参数是 CodeObject,而不是之前的 HiString,指令都是从 _code 属性中获取的(第 9 行)。
- 不管是带操作数的字节码,例如 LOAD_CONST,还是不带操作数的字节码,例如 POP_TOP,它们的指令长度都是 2,只不过不带指令的字节码第二个字节不起作用(第 10 行)。
- print 在 Python 3 中是一个函数,而不是关键字,这一点和 Python 2 有很大的不同。但我们现在没有实现 LOAD_NAME 和 CALL_FUNCTION 指令,因为它们分别需要变量机制和函数机制,所以现在只能将它绕过去。在 CALL_FUNCTION 指令里,直接调用 print 方法(第 25 至 29 行),这是因为现阶段,除了 print 之外,我们不可能再使用其他的函数了,所以这也不会带来什么大的问题。
编译并执行开头的那个 hello.pyc,就能看到以下结果:
前边 5 行是各种打印信息,最后一行是字节码的执行结果。可以看到,正确地打印了数字 255,这说明我们的虚拟机是正确的,已经将字节码加载进来并且执行了。
总结
这节课我们讲解了字节码文件的格式,它是一个结构化的二进制文件,虚拟机通过二进制读写接口将文件加载进来,然后进行解析。字节码文件中最主要的结构就是 CodeObject,它包含了很多重要的属性。其中,字节码指令是最核心的部分,常量表、变量表等结构我们后面会一一介绍。
虚拟机也实现了 parse 方法来解析 CodeObject,将代码对象在内存中重建出来。最后,Interpreter 的 run 方法中实现了最简单的几条虚拟机指令,从而实现了打印数字的功能。实际上,到现在为止,虚拟机也可以打印字符串,你可以自己试验一下。
接下来,我们就将从最简单的程序结构开始实现虚拟机的更多功能,下一节课我们会介绍条件分支语句。
注:点击链接查看课程代码地址
思考题
请你使用 Python 2.7 和 Python 3.8 分别编译这节课开头的文件,体会一下 print 作为关键字和作为函数名有什么不同。欢迎你把你编译后的结果分享到评论区,也欢迎你把这节课的内容分享给其他朋友,我们下节课再见!
- 骨汤鸡蛋面 👍(3) 💬(1)
字节码是不是可以视为一个dsl文件,然后用c++ 写了一个程序/引擎去执行这个文件。
2024-05-22 - 细雨平湖 👍(2) 💬(1)
老师,能不能按照行号,一行一行讲解“hello.pyc”字节码文件?现在这个讲法,完全看不懂啊。
2024-05-13 - ifelse 👍(0) 💬(0)
学习打卡
2024-10-19