02 编程语言全景图(上):编译器是如何把源代码翻译成字节码的?
你好,我是海纳。
从上节课编程语言发展的基本历程中,我们可以了解到,编程语言的发展为虚拟机技术提供了源动力,而虚拟机技术的发展则为编程语言的发展提供了根本保障。虚拟机中的很多技术是为了支持对应的语言特性才被发明出来的,同样有很多好用的语言特性也是因为虚拟机技术的长足发展才得以实现。所以说,编程语言和虚拟机技术是相互依赖和对立统一的。
这节课我们将在上节课内容的基础上,使用一个最基本的表达式求值的例子,来说明一个编程语言的编译器是如何把源代码翻译成计算机可以理解的结构并最终执行的。
我们先创建一个文本文件,里面是一个只包含了数字和四则运算的表达式,编写一个程序来计算这个表达式。基本的过程包括词法分析、文法分析、生成抽象语法树、生成字节码、虚拟机执行五个步骤。这节课我们会实现前四个步骤,虚拟机执行是一个很大的话题,我们将会在第三讲深入介绍。
词法分析
第一个步骤就是要从文本文件中逐个字符地去读取内容,然后把字符识别成数字或者是运算符。这些数字和运算符是组成程序的基本元素,它有一个专用的名字,叫做token。把文本文件中的一串字符,识别成一串token,这就是我们要解决的第一个问题。
比如,我们创建一个文本文件,命名为 test_token.txt,其中只包含一行表达式。
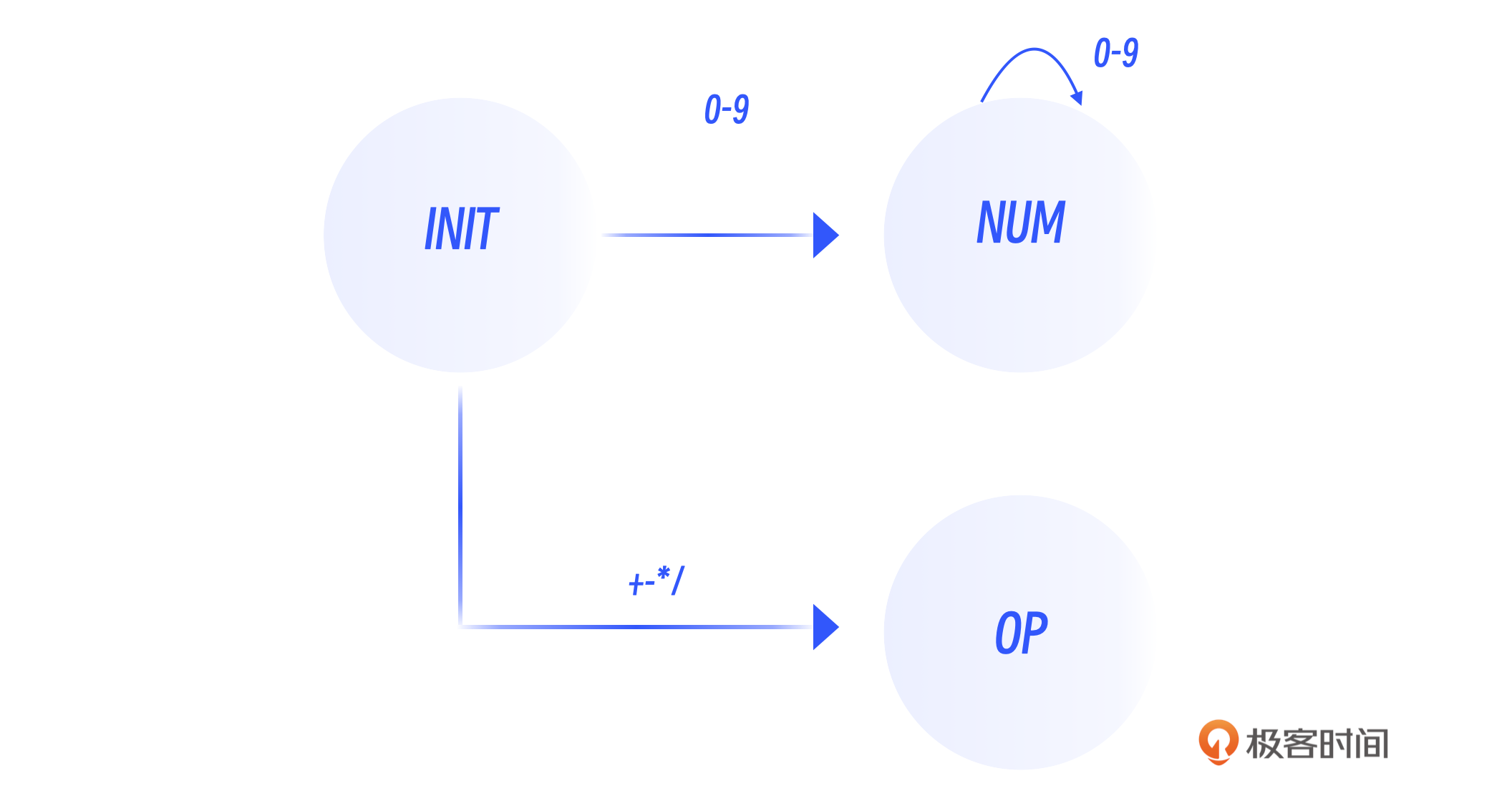
这个表达式其实是由5个token组成的,分别是数字12、乘号、数字48、加号和数字59。这些 token 可以分为两大类:数字和操作符。我们可以使用正则表达式来描述这两类 token。
其中,NUM 代表整数,它的定义是至少包含一个0到9之间的一个数字。OP 代表操作符,是加减乘除四个字符中的一个。在字符串中识别正则表达式,最常用的一个办法就是使用有限自动机。你可以看一下包含了这两条简单规则的自动机示意图。
注:这里我补充一个有限自动机的讲解视频,你可以了解它是如何定义以及如何转换成相应的代码。
将这个有限自动机转换成程序代码是一种固定化的模式。程序不断地读入字符,并把其中的token识别出来。你可以看一下相应的代码。
#include <stdio.h>
#define INIT 0
#define NUM 1
int main() {
FILE * fp = fopen("test_token.txt", "r");
char ch;
int state, num = 0;
while ((ch = getc(fp)) != EOF) {
if (ch == ' ' || ch == '\n') {
if (state == NUM) {
printf("token NUM : %d\n", num);
state = INIT;
num = 0;
}
}
else if (ch >= '0' && ch <= '9') {
state = NUM;
num = num * 10 + ch - '0';
}
else if (ch == '+' || ch == '-' || ch == '*' || ch == '/') {
if (state == NUM) {
printf("token NUM : %d\n", num);
state = INIT;
num = 0;
}
printf("token operator : %c\n", ch);
state = INIT;
}
}
fclose(fp);
return 0;
}
当程序遇到加减乘除操作符的时候,就可以直接打印出这是一个操作符。需要注意的是当遇到数字的时候要进行转换,将字符变成数字(20至23行)。在数字字符结束的时候要将数字的值打印出来(第13至17行,第26至30行)。
程序使用state变量来标识数字字符是否结束。当state的值为NUM时,就表示程序正在接收一个数字。
编译并执行的结果如下:
可见,这个程序正确地将表达式中的各个 token 分析出来了。
文法分析
从文本文件中分析出程序的基本元素——token以后,编译器就要尝试着去理解这些 token 之间的关系了。
token 之间是有其内在的逻辑关系的,比如,加法符号的前后都必须是一个可以执行加法操作的目标,它可以是一个数字,也可以是一个变量,但加号后面却一定不能紧跟一个乘号,否则就是一个不合法的表达式。
编译器要分析这些 token 组成的序列是否有意义,这个工作就是由文法分析完成的。
文法分析主要有两大类算法,一种是自顶向下的分析方法,一种是自底向上的分析方法。其中,自顶向下的分析方法算法简单直接,易于理解和编写。而 yacc 等文法分析工具则以自底向上的算法为主,它的特点是性能好,表达能力强,但是难以调试。所以这里我们就以自顶向下的分析方法为主,来介绍文法分析器是如何工作的。
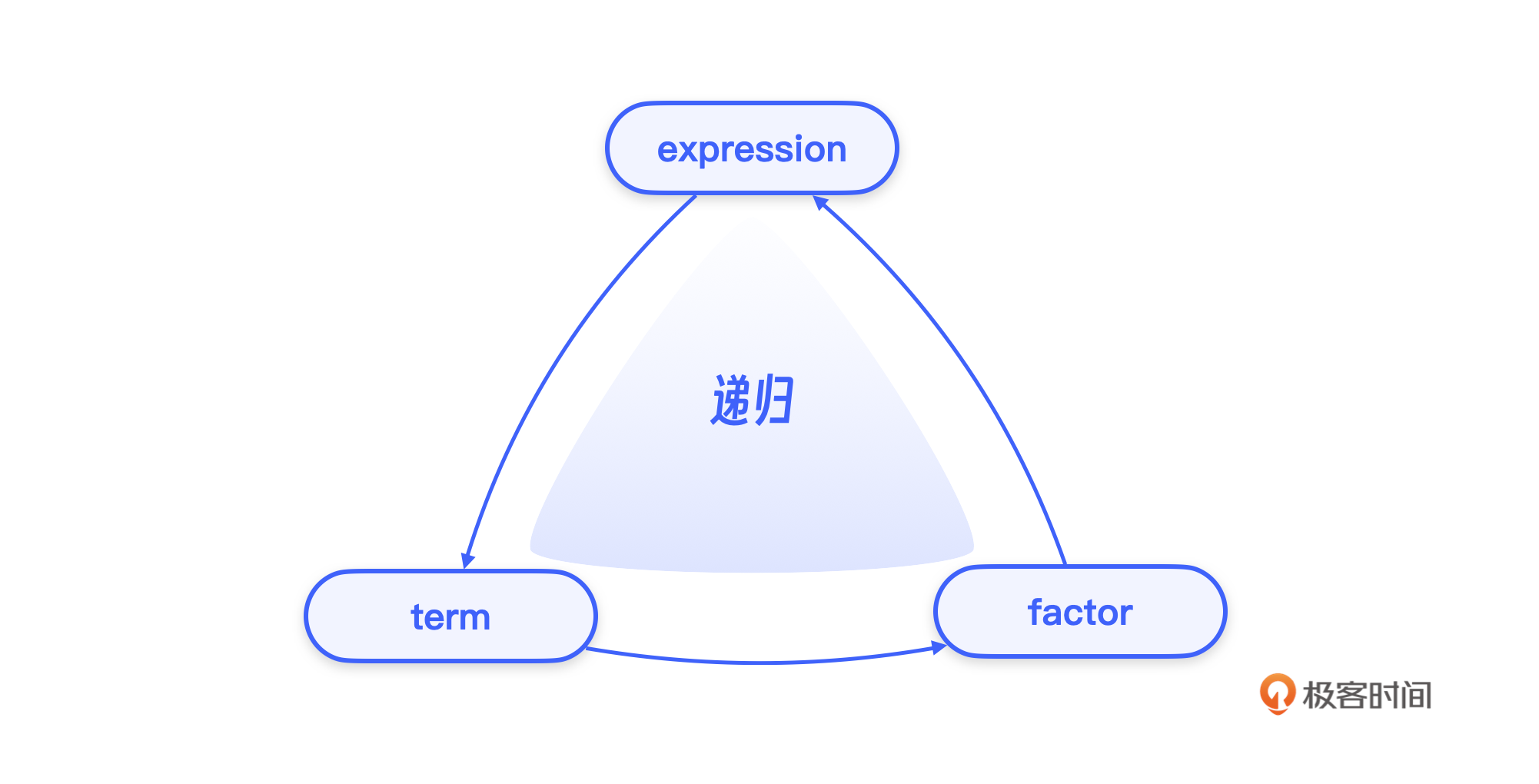
自顶向下的分析方法也被称为递归下降的分析方法。
所谓软件设计,不过是把一个大的问题化解为一个个小的问题。比如说,我们设计一个网站服务器,也是把它分成不同的模块,然后每个模块下面再设计各个不同的组件,组件下面再进行更细粒度的划分。这就是一种从上到下的任务分解。在文法分析中,本质上也采用了同样的分析思路。
以表达式求值为例,最顶部的任务,计算一个表达式(expression)的值。一个表达式,也就是多项式,它是由每个项求和(差与和的原理一样,这里为了描述方便只说和的情况)得到的。所以,一个expression就可以定义为:
等式右边的 term 是一个求和式中的各个加数。例如,对于多项式 2 + 3 * 4 + 5,我们可以把这个式子看成 2 与 3 * 4 与 5 的求和。其中,2 是一个term,3 * 4 也是一个term,5 也是一个 term。
同样的方法也可以用来拆分 term。term 可以看成是多个因子的积。所以term 就可以定义为:
左边的 term 是一个规模比较大的积,而右边的一个 factor 则代表了一个因子。这样,我们就把 term 这个结构拆成了规模更小的因子了。接下来,我们继续定义 factor。
等式右边的中间竖线表示“或”的关系,也就是说,一个 factor 可以是一个整数(NUMBER),也可以是一个包在一对括号里的表达式。反过来说,当遇到一个整数,就可以认为它是一个 factor。或者用括号括起来的表达式,也是一个 factor。
这里需要注意的是,表达式的文法需要先使用 term 去解构 expression,再使用 factor 去解构 term,最后 factor 还要 expression 去解构,绕了一圈又回来了。这种用自己的定义来定义自己的情况就是递归。
但是递归不能没有终点,要使递归的定义变得完整,就必须满足两个条件。
- 子问题必须和原始问题是同样性质的,而且规模要更小、更简单。
- 不能无限制地调用本身,必须有个出口,化简为非递归状况处理。
在上述例子中,子问题的规模是不断缩小的,这一点没有问题。第2点,必须有个出口,这个出口是什么呢?其实就是factor的定义,当问题拆到只有一个整数的时候,递归就会终止,也就是条件2中所说的出口。
这几条规则一起组成了表达式求值的文法,接下来,我们就把这个文法转换成程序(节选自parser.cpp)。
// 这里只要对照 expression 的定义实现就可以了
// expression := term (+|- term)*
int Parser::expression() {
// 对应第一个 term
int a = term();
Token* op = get_token();
// 多个 term 可以对应 while 语句
while (op != NULL &&
(op->_tt == T_PLUS || op->_tt == T_MINUS)) {
consume();
int b = term();
if (op->_tt == T_PLUS) {
a = a + b;
} else {
a = a - b;
}
op = get_token();
}
return a;
}
// term := factor ((*|/) factor) *
int Parser::term() {
int a = factor();
Token* op = get_token();
while (op != NULL &&
(op->_tt == T_MULT || op->_tt == T_DIV)) {
consume();
int b = factor();
if (op->_tt == T_MULT) {
a = a * b;
} else {
a = a / b;
}
op = get_token();
}
return a;
}
// factor := INT | (expression)
int Parser::factor() {
Token* data = get_token();
if (data->_tt == T_INT) {
consume();
return stoi(data);
}
else if (data->_tt == T_LEFT_PAR) {
match(T_LEFT_PAR);
int a = expression();
match(T_RIGHT_PAR);
return a;
}
return -1;
}
// 将字符串转换成数字
int Parser::stoi(Token* data) {
int value = 0;
for (int i = 0; i < data->_length; i++) {
value = value * 10 + data->_value[i] - '0';
}
return value;
}
int Parser::eval() {
printf("%d\n", expression());
return 0;
}
代码里定义这样三个函数:expression、term、factor。expression表示对表达式求值,term表示对表达式中的某一项求值,factor表示对某一个因子求值。
expression 函数里的主要结构就是 while 循环,用于处理多个加号和减号的情况。遇到一个加号以后,就会调用 term 函数去处理多项式中的某一项。term 函数的结构与 expression 函数的结构是相同的。factor 函数则使用了分支结构来区分数字(第48行)和小括号(第52行)两种情况。
在这个过程中,从 expression 下降到 term,再下降到 factor,有明显的自上而下的解析过程。所以这种方式就被称为自上而下的递归下降式文法分析。
上述代码与三条文法规则的对应关系十分明显,所以这里我就不再过多地分析代码的实现了。这段代码在执行的时候就直接把表达式的值求出来,并且打印在屏幕上了。一个真实的编译器在工作的时候是不会执行源代码的,它只负责将源代码转换成抽象语法树(Abstract Syntax Tree,AST)。下面我们就来介绍一下抽象语法树的结构和工作原理。
抽象语法树
抽象语法树对编译器有非同寻常的意义,大多数编译器都会实现抽象语法树这个数据结构。这是因为语法树在表达程序结构方面有非常直观的形式。例如,12 * 48 + 59 的抽象语法树如下图所示。
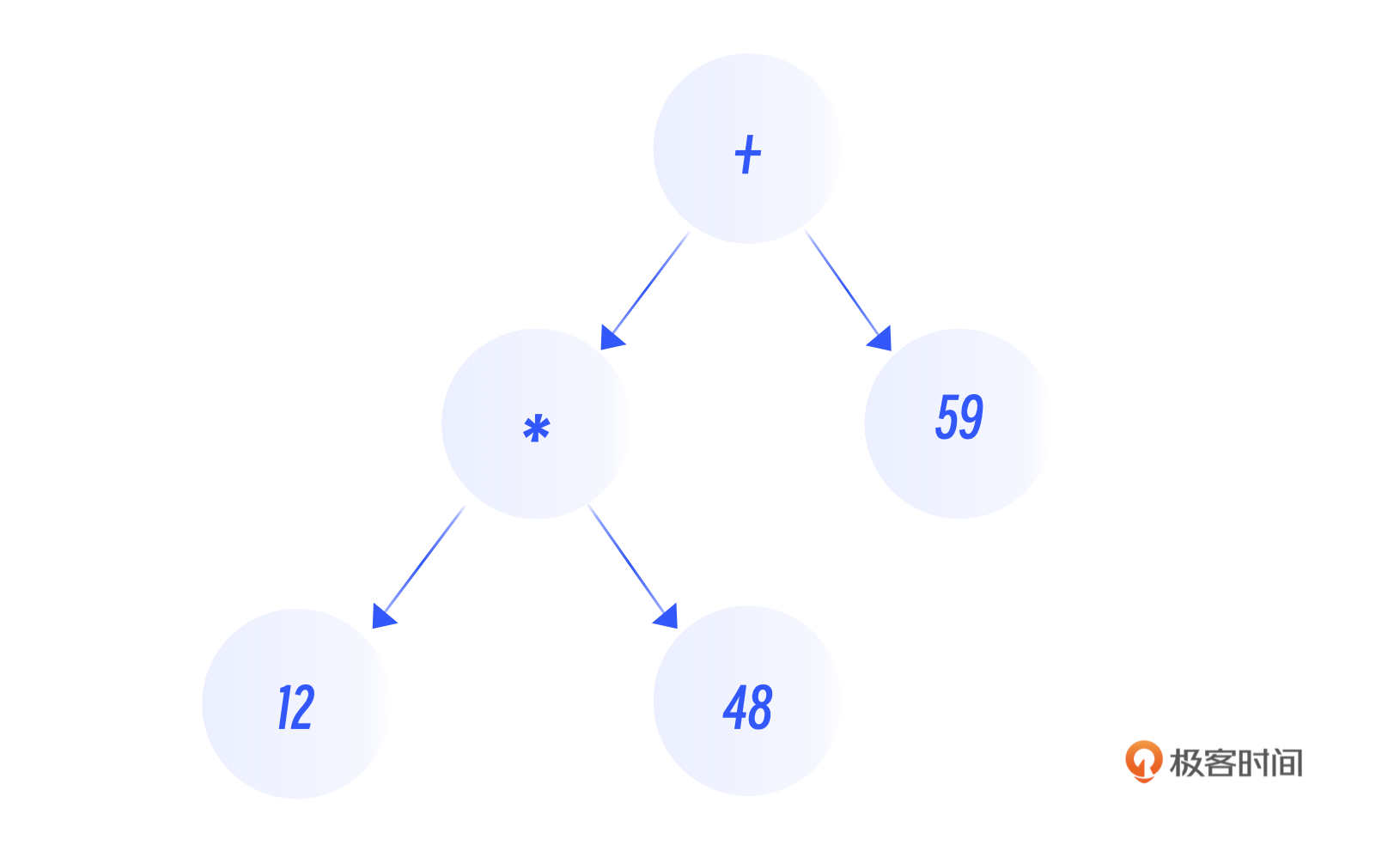
抽象语法树有很多作用,我们可以直接后序遍历语法树来对表达式进行求值,也可以在语法树上做很多性能优化的工作,还可以通过抽象语法树来生成字节码。接下来的例子将会展示如何通过语法树产生字节码。
在文法分析的过程中,如果不直接计算表达式的值,而是将每一个分析结果转化成一个语法树内部节点,就可以在文法分析过程中构建语法树了。
首先,定义好抽象语法树的各个结点的结构。
class Node {
public:
virtual void accept(Visitor* v) = 0;
};
enum OpType {
AST_OP_ADD,
AST_OP_SUB,
AST_OP_MUL,
AST_OP_DIV,
AST_OP_MOD,
};
class BinaryOp : public Node {
protected:
OpType _op_type;
Node* _left;
Node* _right;
public:
BinaryOp(OpType op_type, Node* left, Node* right) :
_op_type(op_type), _left(left), _right(right) {
}
virtual void accept(Visitor* v);
void set_left(Node* left);
void set_right(Node* right);
OpType op_type() { return _op_type; }
Node* left() { return _left; }
Node* right() { return _right; }
};
class ConstInt : public Node {
public:
int _value;
ConstInt(int v) : _value(v) {}
virtual void accept(Visitor* v);
};
抽象语法树结点类中的 accept 方法是为了实现访问者模式而定义的。同时,修改文法分析的实现,让文法分析的结果返回语法树结点。
Node* Parser::expression() {
Node* a = term();
Token* op = get_token();
while (op != NULL &&
(op->_tt == T_PLUS || op->_tt == T_MINUS)) {
consume();
Node* b = term();
if (op->_tt == T_PLUS) {
a = new BinaryOp(AST_OP_ADD, a, b);
} else {
a = new BinaryOp(AST_OP_SUB, a, b);
}
op = get_token();
}
return a;
}
Node* Parser::term() {
Node* a = factor();
Token* op = get_token();
while (op != NULL &&
(op->_tt == T_MULT || op->_tt == T_DIV)) {
consume();
Node* b = factor();
if (op->_tt == T_MULT) {
a = new BinaryOp(AST_OP_MUL, a, b);
} else {
a = new BinaryOp(AST_OP_DIV, a, b);
}
op = get_token();
}
return a;
}
Node* Parser::factor() {
Token* data = get_token();
if (data->_tt == T_INT) {
consume();
return new ConstInt(stoi(data));
}
else if (data->_tt == T_LEFT_PAR) {
match(T_LEFT_PAR);
Node* a = expression();
match(T_RIGHT_PAR);
return a;
}
return NULL;
}
到此为止,重新编译运行整个项目,就可以正确地得到抽象语法树了。我们课程所附带的代码仓里提供了一个使用访问者模式实现的Dumper工具,可以使用树形结构打印一个表达式的抽象语法树,你可以自己看一看。
生成字节码
对抽象语法树进行一次后序遍历就可以生成基于栈的字节码。如果你对二叉树的遍历比较了解的话,这个过程就是显而易见的。
第一节课我们已经介绍过了,字节码的本质是一个虚拟指令集,它里面的每条指令代表一种操作。一般来说,虚拟机的虚拟指令集包含的指令数不会超过 256,一个字节就足够编码全部的指令了,所以人们把这种虚拟指令集叫做字节码。
作为示例,虚拟指令的编码可以任意定义,例如:
#define BINARY_MUL 20
#define BINARY_DIV 21
#define BINARY_ADD 23
#define BINARY_SUB 24
#define LOAD_CONST 100
就像第一节课展示的基于栈的虚拟机的计算过程,BINARY_ADD这四个二元操作符的操作数都在栈上。执行BINARY_ADD时,虚拟机会从操作数栈顶上取两个数字,求和,然后将和再送入栈顶。而LOAD_CONST的作用则是将数字加载到栈顶。
接下来,再引入一个新的访问者PrintVisitor,用于打印字节码助记符。这里使用字符串将字节码的助记符打印出来,并不是直接将虚拟机可以执行的虚拟指令打印出来。我们可以这样定义:
// visitor.hpp
class PrintVisitor : public Visitor {
public:
PrintVisitor() {}
void visit(Node* n);
virtual void visit(BinaryOp* n);
virtual void visit(ConstInt* n);
};
// visitor.cpp
void PrintVisitor::visit(Node* n) {
n->accept(this);
}
void PrintVisitor::visit(BinaryOp* op) {
visit(op->left());
visit(op->right());
switch(op->op_type()) {
case AST_OP_ADD:
printf("BINARY_ADD\n");
break;
case AST_OP_SUB:
printf("BINARY_SUB\n");
break;
case AST_OP_MUL:
printf("BINARY_MUL\n");
break;
case AST_OP_DIV:
printf("BINARY_DIV\n");
break;
default:
printf("Unknown binary op %d\n", op->op_type());
return;
}
}
void PrintVisitor::visit(ConstInt* n) {
printf("LOAD_CONST\t%d\n", n->_value);
}
使用 PrintVisitor 来访问抽象语法树时,就可以使用字符串的方式将字节码展示出来。编译运行的结果如下所示:
如果想真正地生成字节码,就把字符串的方式改成字节码的方式即可。这里引入一个新的访问者 CodeGen,用于在内存中生成一段真正的可供虚拟机执行的虚拟指令串,也就是字节码。你可以看一下它的核心代码。
void CodeGen::add_op(unsigned char op_code, unsigned char param) {
_insts.push_back(op_code);
if (op_code > HAVE_ARGUMENT) {
_insts.push_back(param);
}
}
void CodeGen::visit(BinaryOp* op) {
visit(op->left());
visit(op->right());
switch(op->op_type()) {
case AST_OP_ADD:
add_op(BINARY_ADD);
break;
case AST_OP_SUB:
add_op(BINARY_SUB);
break;
case AST_OP_MUL:
add_op(BINARY_MUL);
break;
case AST_OP_DIV:
add_op(BINARY_DIV);
break;
default:
printf("Unknown binary op %d\n", op->op_type());
return;
}
}
void CodeGen::visit(ConstInt* n) {
add_op(LOAD_CONST, n->_value);
}
CodeGen类的作用是记录字节码,_inst是一个 char 类型的 vector。add_op 方法是将一个指令添加到字节码向量里。
HAVE_ARGUMENT 是一个预定义的宏(第3行),它的值是 90,如果指令编号小于 90,就代表这个指令没有参数,否则这个指令就带有参数。
两个核心的 visit 方法(第 8 行和第 31 行),基本逻辑和 PrintVisitor 相同,都是对语法树进行后序遍历。
到此为止,我们就使用 C++ 语言成功实现了一个简单的表达式的编译器,包含了词法分析、文法分析、字节码生成等步骤,麻雀虽小,五脏俱全。后面不断地新增各种语法特性,实际上也不过是在这个大框架上添砖加瓦。理解了这个过程,就掌握了编译器的基本工作原理。
总结
源代码是由人编写,供人阅读和维护的,计算机并不认识它。计算机能理解的是机器指令,把源代码翻译成机器指令就是编译器的核心功能。一个由语言虚拟机支持的动态语言的编译器,其主要的工作流程包含了词法分析、文法分析、生成抽象语法树、生成字节码以及执行字节码等过程。
词法分析的主要作用是将字符划分成一个个有意义的单词,这些单词统称为 token,词法分析经常使用有限自动机作为主要的实现手段。文法分析的作用是分析 token 之间的有机联系,进而识别出抽象语法树结构。它有两大类重要的分析手段,分别是自顶向下的递归下降分析法和自底向上的分析法。自顶向下的分析法简单直观,所以是我们这节课重点介绍的内容。
使用访问者模式操作抽象语法树是一种常用的手段,对抽象语法树的后序遍历可以产生字节码,在生成字节码以后,虚拟机就可以执行这些字节码了。下一节课我们就会通过实现一个简单的虚拟机来说明字节码是如何被执行的。
注:点击链接查看课程代码地址
思考题
如果为这节课的文法引入变量的话,应该怎么做呢?只需要考虑变量出现在表达式即可,不用考虑变量是如何定义和赋初值的。欢迎你把你的答案分享到评论区,也欢迎你把这节课的内容分享给需要的朋友,我们下节课再见!
- 高并发 👍(4) 💬(1)
我觉得pratt算法是parse二元表达式最好的算法,特别好用😄
2024-05-10 - 果粒橙 👍(1) 💬(1)
gitee里面怎么找每一课对应的代码,最好能按照课时分类。
2024-05-13 - Triple tree 👍(0) 💬(2)
词法分析parser.cpp代码中,如果文件中末尾以数字结束并且没有空格或换行符,最后一个数字无法打印,在fclose前需要判断一下state是否为NUM,是的话打印num
2024-05-12 - lunar 👍(0) 💬(1)
antlr 还没研究完 又来看这个了,我还真是冲动
2024-05-11 - 浩仔是程序员 👍(0) 💬(1)
首发!!有交流群吗?
2024-05-08 - ifelse 👍(0) 💬(0)
学习打卡
2024-10-17