37 RESTful Web Services(1):明确架构愿景与架构组件间的交互
你好,我是徐昊。从今天开始,我们就来使用TDD的方式实现RESTful Web Services。
在上节课,我们展示了需要完成的几大功能块。我们很容易可以发现,RESTful Web Services需要多模块协同完成。而不是像DI Container那样,可以从单一模块入手,在完成几个功能之后再进行重构。
那么我们可以先简单地规划一下架构愿景(Architecture Vision),以简化后续的工作。
规划架构愿景
首先,我们需要明确的是,我们将以Servlet的方式来实现RESTful Web Services框架。也就是说,我们将提供一个Servlet作为主入口,在其中完成对资源对象(Resources)的派分,并根据不同的超媒体选择对应的reader和writer进行输入输出处理。大致结构如下图所示:
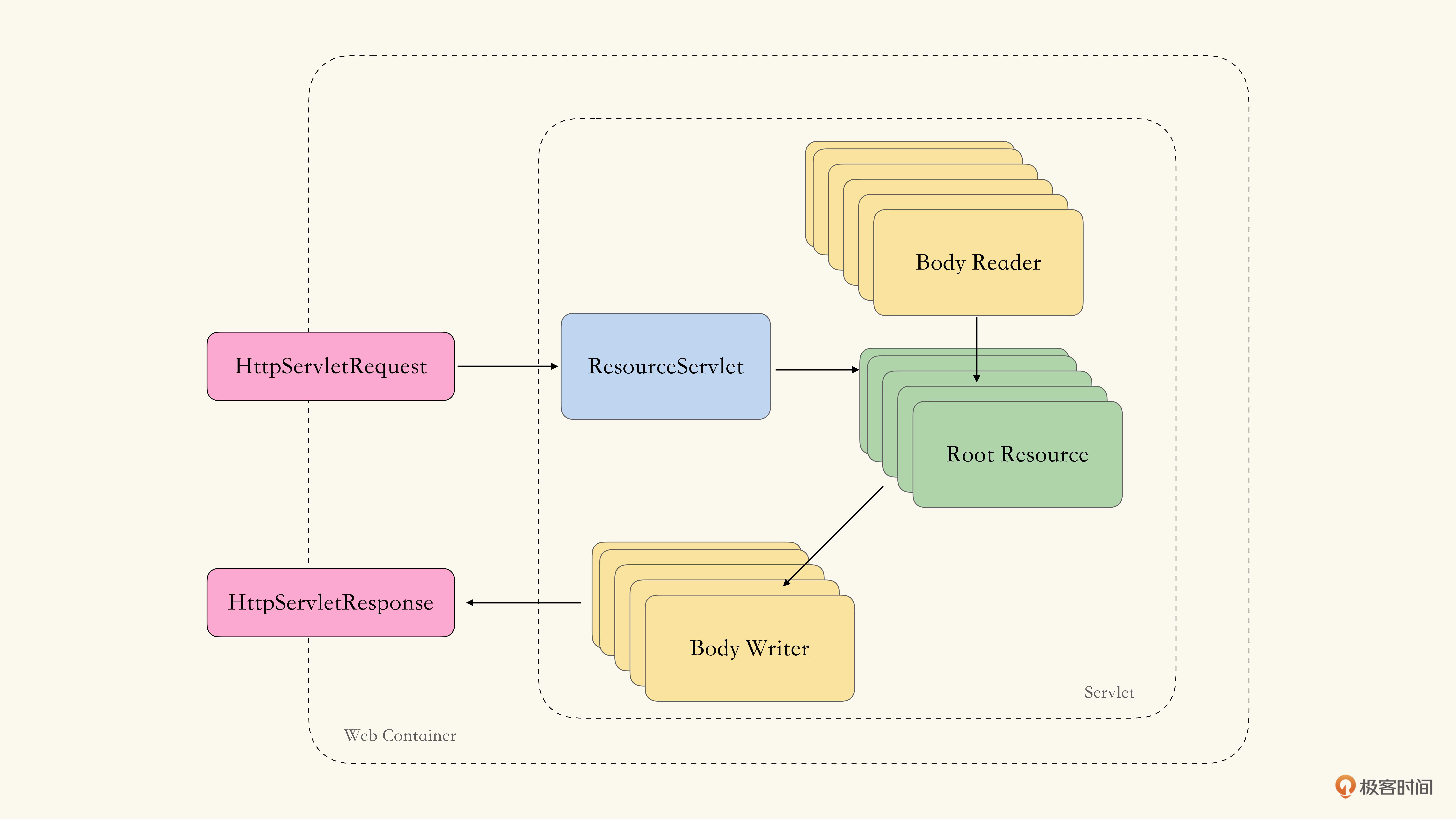
然而仅仅如此,还不足以让我们顺滑地进入伦敦学派的流程(如果你足够自信,已经可以开始经典学派TDD了),我们需要进一步细化ResourceServlet中的组件与交互:
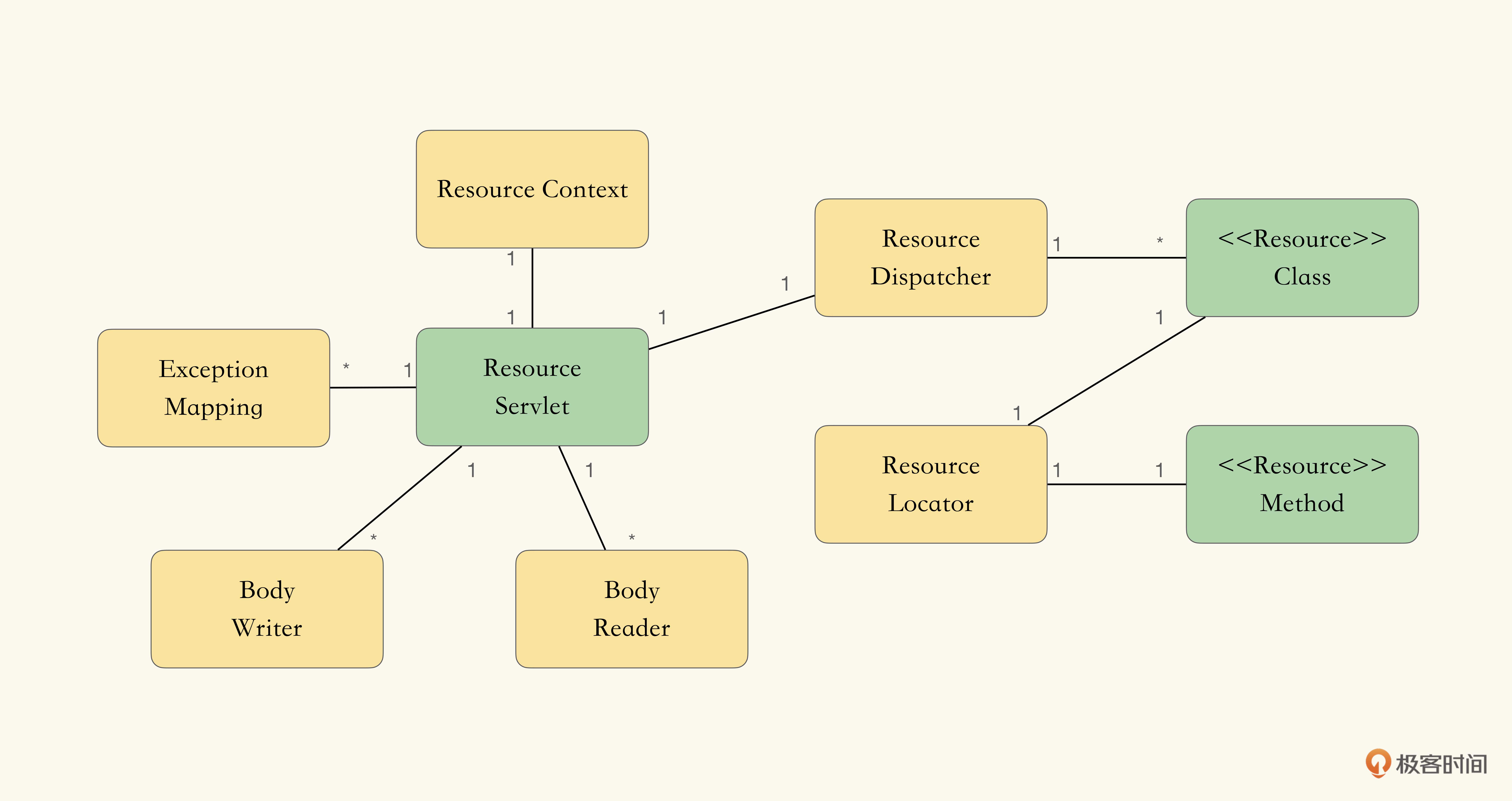
如上图所示,为大致的组件划分:
- ResourceDispatcher管理所有的Root Resource,并根据Root Resource的标注形成路由表。它可以根据路由表,生产对应的ResourceLocator。
- ResourceLocator表示与URI中某一段相匹配的资源方法(Resource Method),并负责调用它。
- ResourceContext表示Resource上下文,包含所有可注入的组件(通过@Context标注)。
- BodyReader聚合了所有的MessageBodyReader,可以根据所需的类型,从HttpServletRequest中读取对象。
- BodyWriter聚合了所有的MessageBodyWriter,可根据提供的类型,将信息写回到HttpServletResponse中。
- ExceptionMapping聚合了所有的ExceptionMapper,可根据提供的异常,将信息写回到HttpServletResponse中。
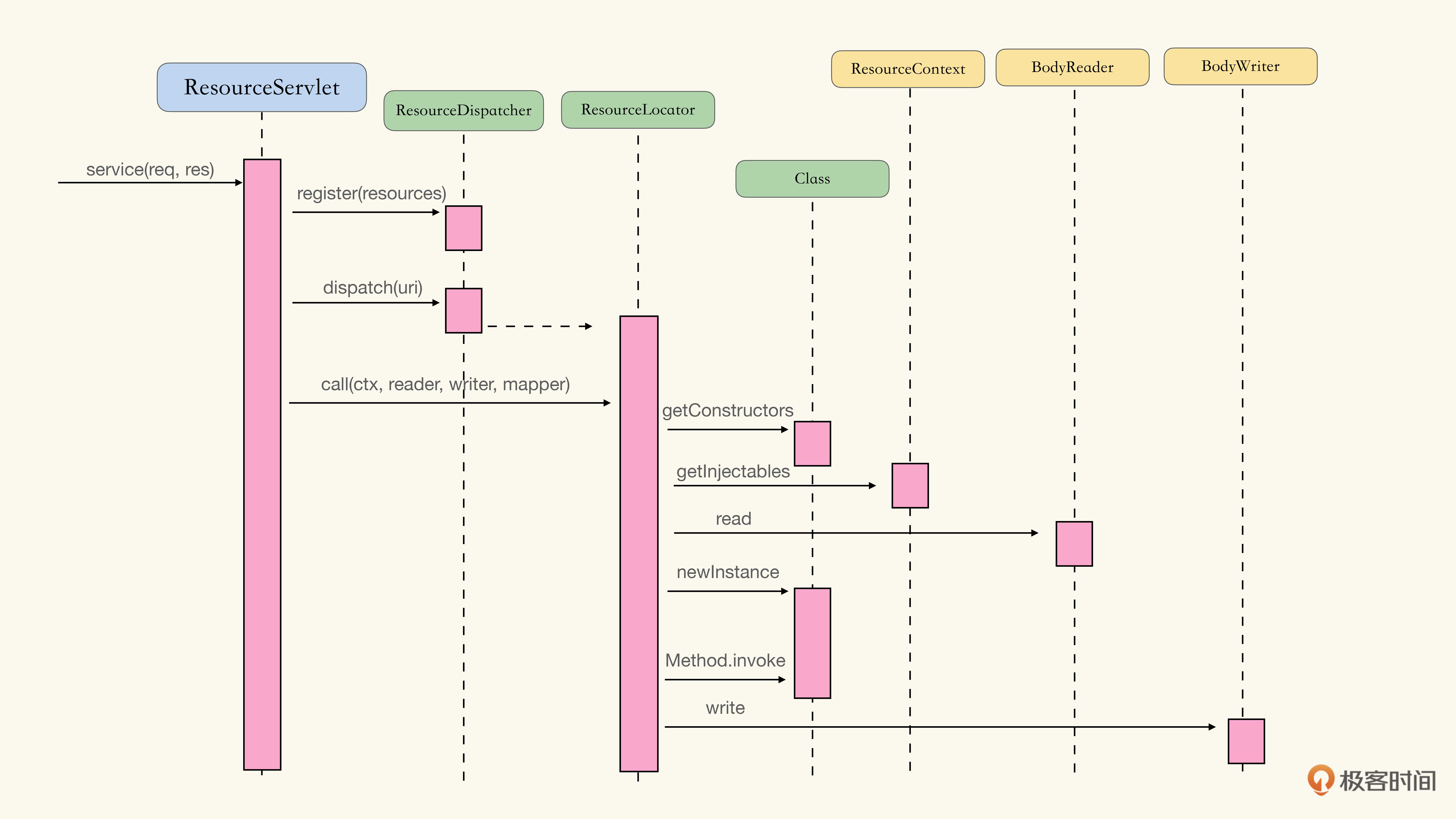
在构想中,这些组件所对应的交互可能是这样的:
- Serlvet容器调用ResourceServlet的service方法,并提供HttpServletRequest和HttpServletResponse。
- ResourceServlet调用ResourceDispatcher,将所有的Root Resource注册到ResourceDispatcher上。
- ResourceServlet调用ResourceDispatcher的方法,根据URI查找路由表,生成对应的ReosurceLocator方法。
- ResourceServlet调用ResourceLocator,并提供ResourceContext、BodyReader、BodyWriter和ExceptionMapping。
- ResourceLocator根据Resource Class的需要,从ResourceContext中寻找可注入的组件。初始化Resource对象,并完成注入。
- ResourceLocator根据Resource Method的需要,使用BodyReader从HttpServletRequest中读取信息。
- ResourceLocator调用Resource Method,并通过BodyWriter将结果写回HttpServletResponse中。
- 如果有异常,则使用ExceptionMapping将结果写回HttpServletResponse中。
如下图所示:
那么至此我们是否可以开始任务分解了呢?还不行。请回想一下伦敦学派的流程:
- 按照功能需求与架构愿景划分对象的角色和职责;
- 根据角色与职责,明确对象之间的交互;
- 按照调用栈(Call Stack)的顺序,自外向内依次实现不同的对象;
- 在实现的过程中,依照交互关系,使用测试替身替换所有与被实现对象直接关联的对象;
- 直到所有对象全部实现完成。
所以我们还需要明确对象(架构组件)之间的交互,明确到有清晰的调用栈顺序,足以支撑我们使用测试替身构造测试。
明确架构组件间的交互
明确架构组件间的交互有三种方法:根据经验设计,通过经典模式进行定向重构,以及Spike。
根据经验设计永远是一种可能的选项,不过我总觉得这是更难的一种方法(也更为不靠谱)。通过经典模式进行定向重构有个额外的好处,它可以看作是对于架构愿景的验证:通过一组典型场景测试,验证架构的可行性;然后在重构过程中,根据愿景提炼组件间的交互。具体过程和前一个项目差不多,这里可留给你们自己练习。
Spike是另一种常用的方法,特别是对遗存代码或需求上下文不够熟悉,不能直接进入经典模式的情况下,经常采用的模式:
Spike可以看作不严格的经典模式,通常只有非常简单的测试,并不限制一定要用重构,重写也可以。那么以最快的方式理解需求上下文,获得架构愿景就可以了。
思考题
在进入下节课之前,希望你能认真思考如下两个问题。
- 根据Spike的结果,我们要如何调整架构愿景?
- 学完这节课后,你最大的收获是什么?有没有让你特别惊喜的操作?
欢迎把你的想法分享在留言区,也欢迎把你的项目代码的链接分享出来。相信经过你的思考与实操,学习效果会更好!
- 张铁林 👍(0) 💬(1)
https://github.com/vfbiby/tdd-restful 开始提交作业,这次把中间记的操作步骤一起放在项目doc下,还有小步提交,尽量,把每一个改变都提交上来,然后,每一章完成时,再做一个大提交。可以check到小提交处来练习。
2022-06-17 - 人间四月天 👍(5) 💬(0)
非常喜欢这个spike方法,在产品需求领域,叫做mvp最小可行产品,这个应该叫做最小可行设计,对于复杂需求,需求不清晰,或者复杂设计,通过这个方法验证架构愿景的可行性非常好,也能增强前期架构规划的信心。
2022-06-02 - Geek_dcb102 👍(1) 💬(0)
spike的过程: 1. spike过程 需要能够快速反馈结果 所以建议从一个开始可运行的小型框架 逐步替换成自己的代码 2. spike中 是需要自己认为的组件 尤其是大的组件 都全员参与的 确定组件之间的关系是否合理 3. spike中 需要参考现成的规约api 让组件更内聚合理 保证后续的复杂升级的可能性 也可以更好的观察组件的理解和划分是否合理.防止因为一开始的用例简单 造成很多组件相互耦合 职责不清 没有复杂升级的方向 进而没有达到spike应有的效果
2023-01-02 - Jason 👍(1) 💬(0)
第一次直观的感受spike方法
2022-06-28 - 枫中的刀剑 👍(1) 💬(0)
最大收获是Spike的方式也可以采取类似TDD的方式,甚至对于暂不关心的细节部分可以使用stub。
2022-06-13 - 大碗 👍(0) 💬(0)
通过实现“现有的接口”去了解组件交互的细节
2022-09-05