24 构造基于语义的自动化脚本
你好,我是徐昊,今天我们来继续学习AI时代的软件工程。
上节课我们讲解了使用大语言模型(Large Language Model,LLM)辅助软件开发的两个核心知识过程,即技术方案的应用以及软件质量的保证,以及如何通过LLM消除团队中的认知分歧,从而提高团队的整体效率。
对比第16节课我们讲述的测试驱动AI开发,就会发现,测试驱动AI开发关注于个人与LLM交互,以及知识是如何从人传递到LLM的。而消除认知分歧,最需要关注这两个方面——知识如何在人与人之间传递,以及LLM是如何辅助这一过程的。
然而无论是辅助个人还是辅助团队,我们都需要用到基于语言的自动化脚本来加速工作。那么,这节课,我们来学习一些常用技巧,帮助我们更有效地构造自动化脚本。
补充上下文
正如我们最开始在开篇词里介绍的一样,想要获得更高质量的结果,关键在于补充上下文。我们在前面的课程里,已经介绍了很多提示词技巧可以有效补充上下文。让我们简单复习一下,比如,结构化自然语言。
看一个简单的例子,现在有一个雇员的数据表,有两种不同的雇员,全职或者兼职。雇员按照不同的类型,有不同的计算工资的办法。全职按工资(SALARY)计算,兼职按时薪(HOURLY_RATE)计算。结构如下:
CREATE TABLE EMPLOYEE (
ID BIGINT(19) NOT NULL PRIMARY KEY,
NAME VARCHAR(255),
TYPE VARCHAR(255),
SALARY INTEGER(10) NOT NULL,
HOURLY_RATE INTEGER(10) NOT NULL
);
因为上下文的缺失,我们直接询问ChatGPT可能得不到我们想要的结果。比如,我们想知道所有雇员的工资,ChatGPT并不能给出我们预期的答案:

而我们只需要稍微补充一下上下文,结果就会有很大的不同,比如:
CREATE TABLE EMPLOYEE (
ID BIGINT(19) NOT NULL PRIMARY KEY,
NAME VARCHAR(255),
TYPE VARCHAR(255), — 取值为P或F,P是兼职,F是全职
SALARY INTEGER(10) NOT NULL, — 全职工资以此为准
HOURLY_RATE INTEGER(10) NOT NULL — 兼职工资为时薪
);

对于绝大多数场景,只要补充足够的上下文,都能得到更好的结果,而且LLM的表现也会更加稳定。如果对于表结构的标注不够,也可以增加业务的场景和应用的背景说明。类似的场景,还有Text2API,你可以课后自行验证。
除此之外,另一个让LLM结果更加稳定的办法是零样本(zero shots example)或少样本学习(few shots example),这个也是我们之前学习过的技法。
比如,上面的例子中,通过TYPE字段区分,在同一个表中存在一族对象的信息,这是一个常用的模式,叫做单表继承映射(Single Table Inheritance)。单表继承映射是处理对象继承结构持久化时常用的模式。对于单表映射的SQL查询,实现方法有很多,除了使用case表达式外,我们还可以使用union all,甚至其他的更复杂的方式来完成。
通常我们会倾向于使用某一种固定的方式,但是LLM并不一定会在每一个场景下,都返回我们期待的模式。这时候,我们就需要使用少样本学习,将LLM的返回结果,固定在我们期望的模式中。
SCHEMA
=======
CREATE TABLE EMPLOYEE (
ID BIGINT(19) NOT NULL PRIMARY KEY,
NAME VARCHAR(255),
TYPE VARCHAR(255), — 取值为P或F,P是全职,F是兼职
SALARY INTEGER(10) NOT NULL, — 全职工资以此为准
HOURLY_RATE INTEGER(10) NOT NULL — 兼职工资为时薪
);
如果使用single table inheritance,我们会在该表的SCHEMA中,使用TYPE作为子类型的区分标志。遇到single table inheritance时,我们要使用CASE语句,完成对于类型的筛选。
比如,当SCHEMA为:
CREATE TABLE WHOLE_OBJECT_TREE(
ID BIGINT(19) NOT NULL PRIMARY KEY,
TYPE VARCHAR(255) — 取值为A或B
)
查询的SQL为:
SELECT …
CASE
WHEN TYPE=’A' THEN …
WHEN TYPE=‘B’ THEN …
END …
…
任务
====
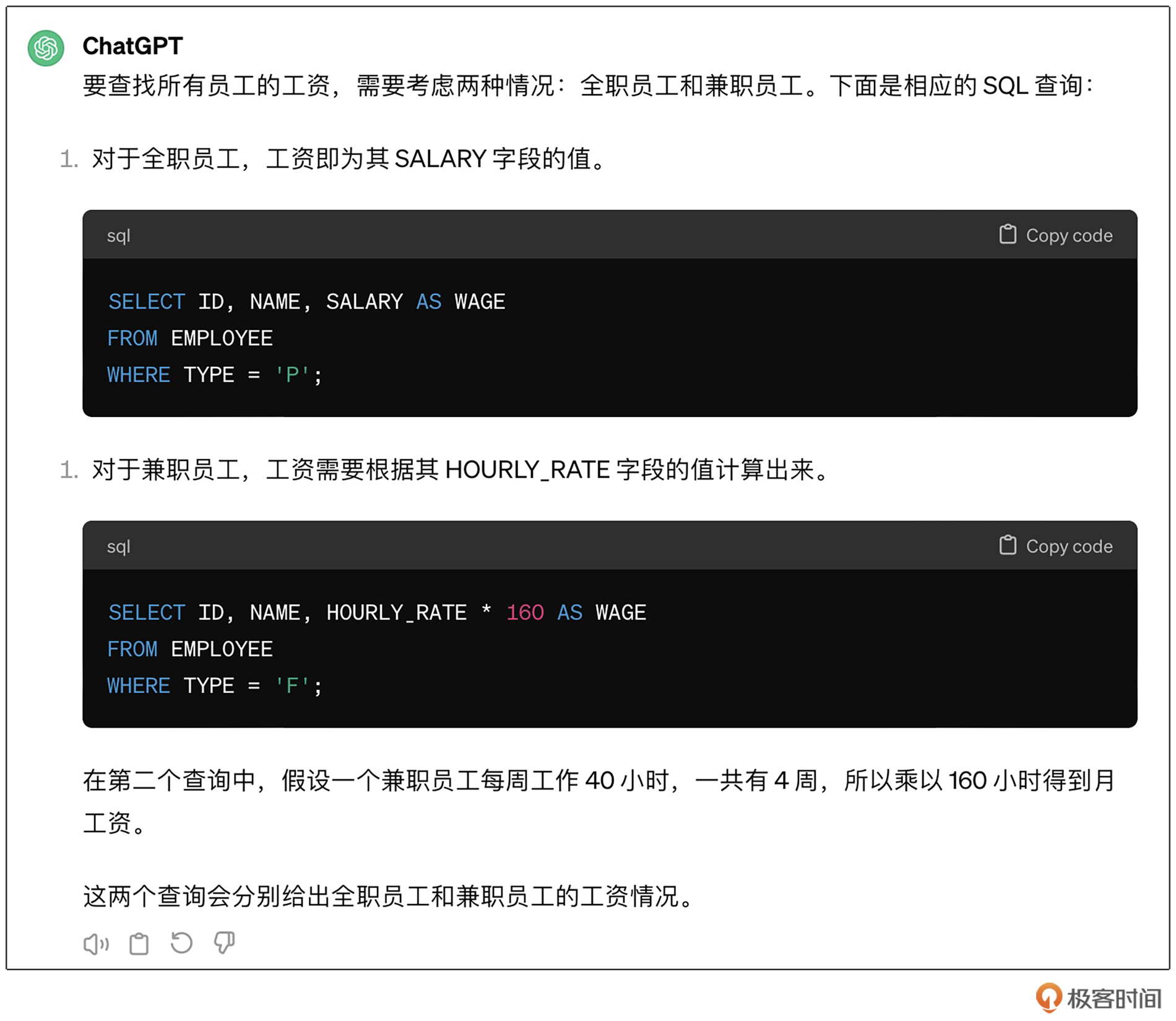
查找所有员工工资的SQL是什么?
你会发现这个提示词得到的结果非常稳定,而去掉少样本学习的部分,在多次执行时,它的结果就会有很大差别,比如下面是我得到的另一种结果:
转换生成内容
除了提供足够的上下文和零样本/少样本学习外,指定LLM生成一种更为稳定的输出,也可以让最终的结果更为可控。一个常见的例子是单元测试的数据准备。比如,我们使用上面例子中的schema生成测试数据。一个直接的做法是让LLM直接生成灌注测试数据的代码。
SCHEMA
======
CREATE TABLE EMPLOYEE (
ID BIGINT(19) NOT NULL PRIMARY KEY,
NAME VARCHAR(255),
TYPE VARCHAR(255), — 取值为P或F,P是兼职,F是全职
SALARY INTEGER(10) NOT NULL, — 全职工资以此为准
HOURLY_RATE INTEGER(10) NOT NULL — 兼职工资为时薪
);
任务
====
请按照上述schema,生成测试数据,要求生成5个全职和5个兼职员工。
全职员工薪水从8000-12000不等,兼职时薪不低于50,不高于150.
使用JUnit和JDBC作为技术栈

import org.junit.jupiter.api.Test;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
import java.sql.SQLException;
import java.util.Random;
public class TestDataGenerator {
// JDBC连接信息,请根据你的实际数据库配置修改
private static final String URL = "jdbc:mysql://localhost:3306/database_name";
private static final String USERNAME = "your_username";
private static final String PASSWORD = "your_password";
@Test
public void generateTestData() {
try (Connection connection = DriverManager.getConnection(URL, USERNAME, PASSWORD)) {
// 生成5个全职员工
for (int i = 1; i <= 5; i++) {
String name = "FullTimeEmployee_" + i;
int salary = getRandomNumberInRange(8000, 12000);
insertEmployee(connection, name, "F", salary, 0);
}
// 生成5个兼职员工
for (int i = 1; i <= 5; i++) {
String name = "PartTimeEmployee_" + i;
int hourlyRate = getRandomNumberInRange(50, 150);
insertEmployee(connection, name, "P", 0, hourlyRate);
}
} catch (SQLException e) {
e.printStackTrace();
}
}
private void insertEmployee(Connection connection, String name, String type, int salary, int hourlyRate) throws SQLException {
String sql = "INSERT INTO EMPLOYEE (NAME, TYPE, SALARY, HOURLY_RATE) VALUES (?, ?, ?, ?)";
try (PreparedStatement statement = connection.prepareStatement(sql)) {
statement.setString(1, name);
statement.setString(2, type);
statement.setInt(3, salary);
statement.setInt(4, hourlyRate);
statement.executeUpdate();
}
}
private int getRandomNumberInRange(int min, int max) {
Random r = new Random();
return r.nextInt((max - min) + 1) + min;
}
}

我们可以看到,LLM以代码的形式,生成了测试数据准备的代码。而如果我们希望为不同场景再次生成数据准备测试代码时,很难保证LLM会生成一样的代码。那我们也就很难保证,它生成结果的一致性。
但是如果我们只让LLM生成数据,那么它的稳定性就会得到很大提高。比如:
SCHEMA
======
CREATE TABLE EMPLOYEE (
ID BIGINT(19) NOT NULL PRIMARY KEY,
NAME VARCHAR(255),
TYPE VARCHAR(255), — 取值为P或F,P是兼职,F是全职
SALARY INTEGER(10) NOT NULL, — 全职工资以此为准
HOURLY_RATE INTEGER(10) NOT NULL — 兼职工资为时薪
);
任务
====
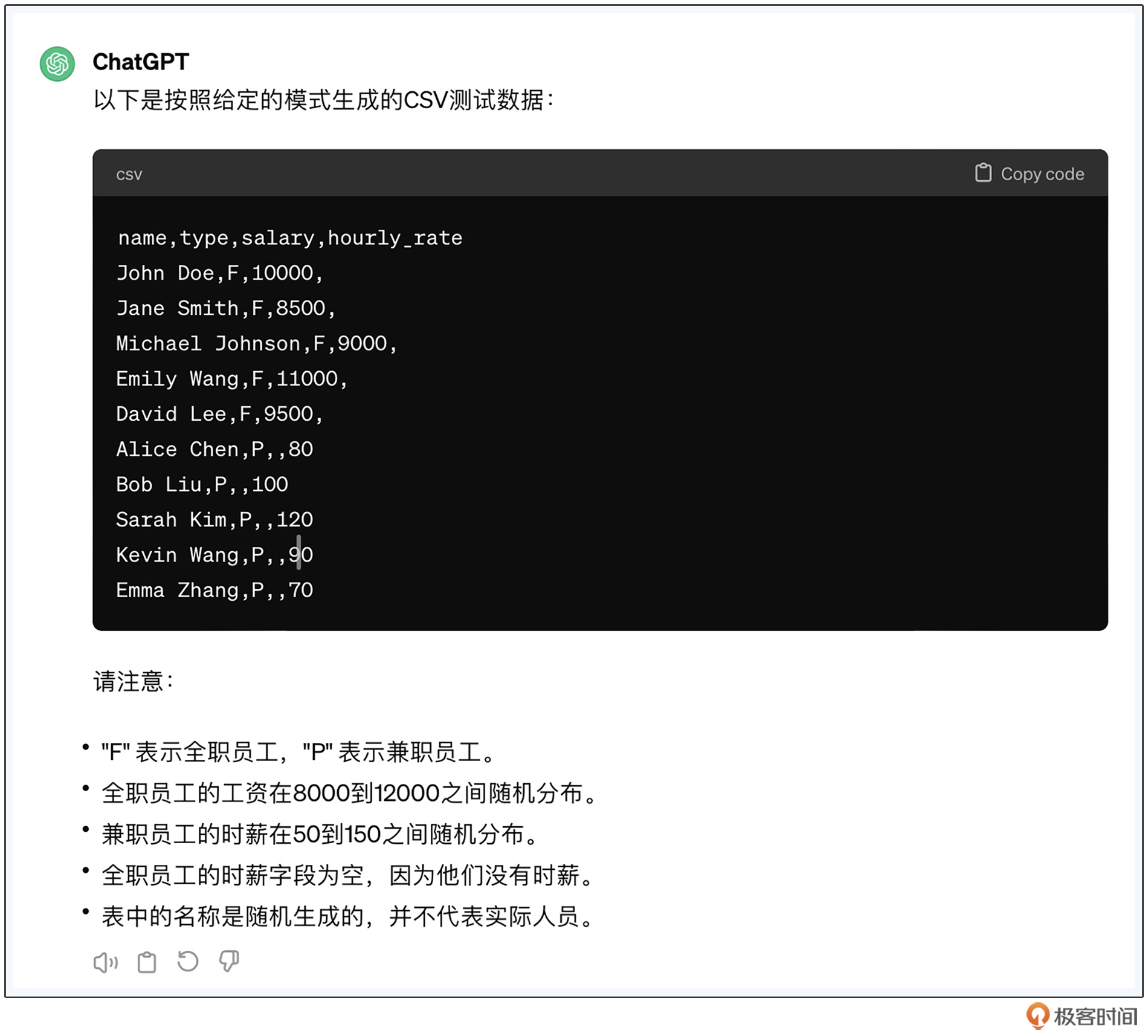
请按照上述schema,生成csv格式的测试数据,要求生成5个全职和5个兼职员工。
全职员工薪水从8000-12000不等,兼职时薪不低于50,不高于150.
csv的格式如下
name,type,salary,hourly_rate
然后我们可以使用数据驱动的测试风格,将这些数据灌入我们要的测试中。
SCHEMA
======
CREATE TABLE EMPLOYEE (
ID BIGINT(19) NOT NULL PRIMARY KEY,
NAME VARCHAR(255),
TYPE VARCHAR(255), — 取值为P或F,P是兼职,F是全职
SALARY INTEGER(10) NOT NULL, — 全职工资以此为准
HOURLY_RATE INTEGER(10) NOT NULL — 兼职工资为时薪
);
任务
====
编写一个JUnit准备测试数据的方法,按照如下csv的格式,将数据插入上述schema。
name,type,salary,hourly_rate
csv文件由指定路径读入。

import org.junit.Before;
import org.junit.Test;
import java.io.BufferedReader;
import java.io.FileReader;
import java.io.IOException;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
import java.sql.SQLException;
public class TestDataPreparationTest {
private static final String JDBC_URL = "jdbc:mysql://localhost:3306/your_database_name";
private static final String USERNAME = "your_username";
private static final String PASSWORD = "your_password";
@Before
public void setUp() {
// Your setup code, e.g., initializing database connection
}
@Test
public void testDataInsertion() {
String csvFilePath = "path/to/your/csv/file.csv";
try (Connection connection = DriverManager.getConnection(JDBC_URL, USERNAME, PASSWORD);
BufferedReader reader = new BufferedReader(new FileReader(csvFilePath))) {
String line;
while ((line = reader.readLine()) != null) {
String[] data = line.split(",");
String name = data[0].trim();
String type = data[1].trim();
int salary = Integer.parseInt(data[2].trim());
int hourlyRate = Integer.parseInt(data[3].trim());
insertEmployee(connection, name, type, salary, hourlyRate);
}
} catch (IOException | SQLException e) {
e.printStackTrace();
}
}
private void insertEmployee(Connection connection, String name, String type, int salary, int hourlyRate) throws SQLException {
String sql = "INSERT INTO EMPLOYEE (NAME, TYPE, SALARY, HOURLY_RATE) VALUES (?, ?, ?, ?)";
try (PreparedStatement preparedStatement = connection.prepareStatement(sql)) {
preparedStatement.setString(1, name);
preparedStatement.setString(2, type);
preparedStatement.setInt(3, salary);
preparedStatement.setInt(4, hourlyRate);
preparedStatement.executeUpdate();
}
}
}

在后续的测试生成中,我们可以通过少样本学习,让LLM继续使用insertEmployee完成数据的准备。这时LLM只需要专注于生成csv格式的数据即可。比起代码,生成csv具有更高的稳定性和一致性。数据驱动风格的代码也更适合由LLM辅助开发。
小结
当我们与LLM交互时,有一个奇妙的心理预期,当我们处于复杂的认知模式时(Complex),我们对于LLM返回的结果是最满意的。因为我们对于要解决的问题十分懵懂,LLM返回的结果只要对我们稍有启迪,我们就会非常满意。
比如,对于一个完全不了解的技术栈,哪怕是非常简单的功能,当LLM返回的代码可以达成一定功能时,我们就会惊讶于LLM的能力。其实这倒不是LLM有多么厉害,而是我们自己太菜了而已。我们菜到甚至无法正确判断LLM产生结果的质量。
而当我们处在清晰认知模式(Clear)时,我们又对LLM产生的结果异常地苛刻。因为此时我们对于要解决的问题,以及问题的解决方案有准确的认知,我们不光知道要解决的问题是什么,而且对于如何解决也有明确的期待。此时,我们就可以一眼看出LLM生成结果的成色。那么自然,对于LLM的结果也就没有那么满意了。
所以我们可以听到很多关于LLM截然相反的讨论,有人因为它给予我们启迪和思考,给予高度的赞扬,也有尝试将LLM用于实际工作屡屡碰壁,最后决定这东西没有什么太大用途。当然,我们现在知道,这是因为不同的认知行为模式造成的,在不同的认知行为模式下,LLM能够发挥的作用也不尽相同。
所以当我们尝试通过大语言模型构造自动化脚本时,一方面我们不希望LLM像传统脚本一样,只能处理有限的情况。另一方面,我们又希望它能在更多的场景下,给出符合我们预期的答案,这就是使用LLM构造自动化脚本的核心难点。
而截止到现在(2024年4月),解决LLM自动化脚本问题时,比较常用的技巧无非是:
- 补充上下文让LLM更好地理解问题域;
- 零样本/少样本学习以固定LLM的生成习惯;
- 由数据驱动简化LLM生成目标。
思考题
试想一个可以通过数据驱动简化LLM生成的例子。
欢迎在留言区分享你的想法,我会让编辑置顶一些优质回答供大家学习讨论。
- 6点无痛早起学习的和尚 👍(0) 💬(1)
这里有一个问题,比如要写一个测试代码,投喂给 LLM 的测试策略(stub、mock等等),这些是不是都可以归为零样本/少样本?
2024-05-05 - 术子米德 👍(0) 💬(0)
🤔☕️🤔☕️🤔 【R】自动化脚本:一方面突破传统脚本、怎么写就那么点效果,另一方面放到更多场景、给出预期答案。 技巧:补充上下文、零样本/少样本学习、数据驱动。 【.I.】问题在我面前,我懵懂Complex状态,一股脑儿扔给大模型,生成的内容中,只要对我有启发,我就很开心。任务列表在我面前,我清晰Clear状态,就是自己懒得动手干,稍作整理扔给大模型,生成的内容中,哪怕一点点偏差,我心里就会泛嘀咕,这么笨。 【Q】系统里的某个模块(如:类似MQ的消息通讯模块),它以C/C++的API接口供其它模块调用,跟CRUD类的测试是否有不同的关注点,提示词技巧是否有差别? 这样的模块的单元测试,若想LLM协助设计,哪些方面有别于CRUD类的测试? — by 术子米德@2024年5月1日
2024-05-01