08 使用LLM辅助业务理解
你好,我是徐昊,今天我们来继续学习AI时代的软件工程。
在上一节课,我们介绍了如何使用业务模型通过模型展开的方式,帮助我们理解业务。我们也谈到了,在使用模型展开的时候,我们处在庞杂的认知模式下。因此,提效的关键在于构造思维链,让LLM帮助我们更好地应用不可言说知识。
那么今天,我们就围绕之前的例子,看看如何通过LLM辅助我们理解不同的业务场景。
通过半结构化自然语言表示模型
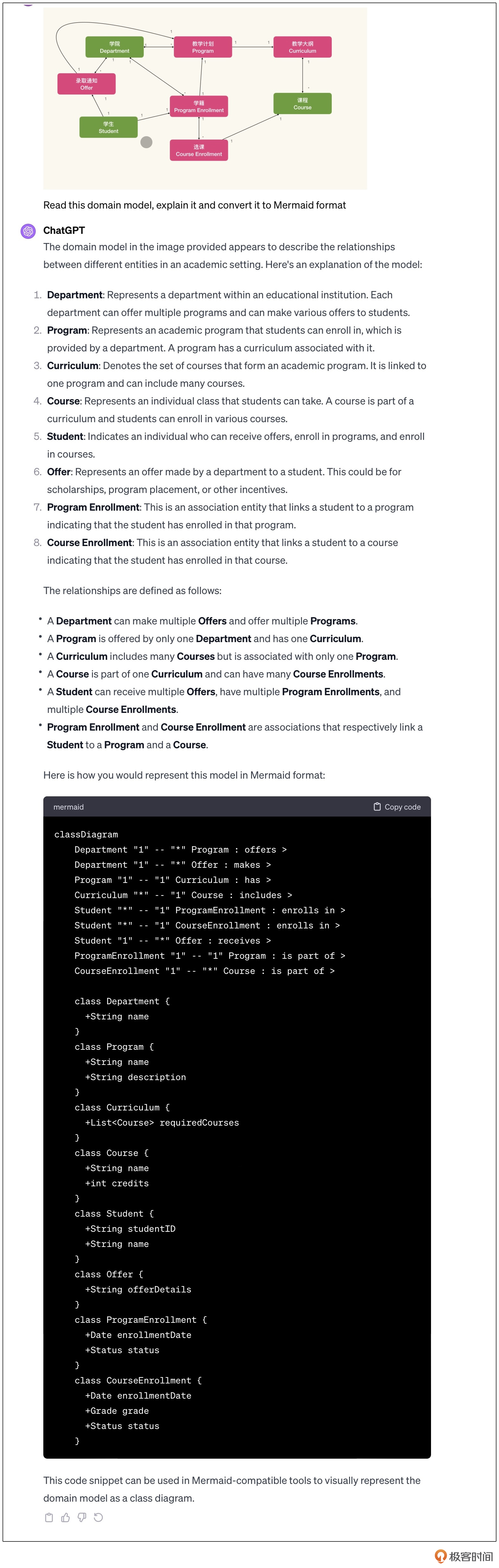
当我们想让大语言模型(Large Language Model,LLM)帮助我们通过模型解释业务知识时,首先就会碰到一个问题,如何将我们的模型表达为大语言模型能够理解的形式。
其实这比想象中要容易得多,因为LLM不仅仅懂得自然语言,它还懂得各种编程语言或结构化描述语言。我们可以使用 Mermaid 描述我们的领域模型:
classDiagram
Department "1" -- "*" Program
Department "1" -- "*" Offer
Offer "1" -- "1" Program
Program "1" -- "1" Curriculum
Curriculum "1" -- "*" Course
Student "1" -- "1" ProgramEnrollment
ProgramEnrollment "1" -- "*" CourseEnrollment
Student "1" -- "1" Offer
ProgramEnrollment "1" -- "1" Program
CourseEnrollment "1" -- "1" Course
class Department {
}
class Program {
}
class Curriculum {
}
class Course {
}
class Student {
}
class Offer {
}
class ProgramEnrollment {
}
class CourseEnrollment {
}
当我们把这段Mermaid录入LLM,它会为我们提供它的理解:

其中大部分的内容都是正确的,只是不够准确。比如领域概念的名字,在LLM中的解读部分就是错误的。再比如,关联所代表的含义,也不甚准确。图里Department、Program、Offer三个对象间的意思就不对。
这时候,我们可以使用一个我发明的技巧,叫半结构化自然语言。所谓半结构化自然语言,就是在结构化的描述中混入自然语言去补充对应的上下文。说人话就是写注释。
那为什么要叫半结构化自然语言呢?因为在LLM的视角来看,结构化的信息和非结构化的自然语言一样重要。半结构化自然语言既可以看作以自然语言给予结构化数据补充,也可以看作结构化数据赋予自然语言结构。而从赋予自然语言结构的角度,就能够解锁更多对于LLM应用的巧思。
首先我们来解决一下命名的问题。在Mermaid中增加注释,并给出解释和例子:
classDiagram
...
%% 学院
class Department {
}
%% 教学计划
%% 比如,计算机科学与技术学士学位教学计划,或是计算机科学与技术硕士学位教学计划
class Program {
}
%% 教学大纲
class Curriculum {
}
%% 教学课程
class Course {
}
%% 学生
class Student {
}
%% 录取通知
%% 通知学生被那个教学计划录取,比如张三录取为学士学位学生
class Offer {
}
%% 学籍
%% 根据录取通知将学籍注册到指定的教学计划,比如,张三根据录取通知注册为2023年入学的计算机科学与技术学士学位教学计划学生
class ProgramEnrollment {
}
%% 选课
%% 在学籍有效期内,需要根据教学大纲选课
class CourseEnrollment {
}

这就是半结构化自然语言为什么会被称作半结构化自然语言。我们通过注释,实际上使用了少样本迁移学习(Few Shots Example),在一个小范围的上下文中,给LLM提供了更为具体的迁移指引。
接下来我们用同样的方法来处理关联关系。通过Mermaid的语法,标注关系之间方向和含义,并提供注释:
classDiagram
Department "1" *-- "*" Program: 提供不同学位的教学计划 >
Department "1" *-- "*" Offer: 为学生发出录取通知 >
Offer "1" --> "1" Program: 录取通知针对某个学位 >
Program "1" --> "1" Curriculum: 教学计划对应的教学大纲 >
Curriculum "1" *--> "*" Course: 组成教学大纲的课程 >
Student "1" --> "1" ProgramEnrollment: 学生登录的学籍 >
ProgramEnrollment "1" *-- "*" CourseEnrollment: 在学籍有效期内,需要根据教学大纲选课 >
Student "1" --> "1" Offer : 学生拿到的入学通知 >
ProgramEnrollment "1" --> "1" Program: 录取通知中指定的教学计划 >
CourseEnrollment "1" --> "1" Course: 选定的课程 >
%% ProgramEnrollment根据Offer生成,表示学生已经到校注册
...

至此,我们可以看到LLM已经可以理解我们包含在模型中的业务知识了。
围绕业务上下文进行模型的展开
让我们再看一下上节课中模型展开之后的结果:
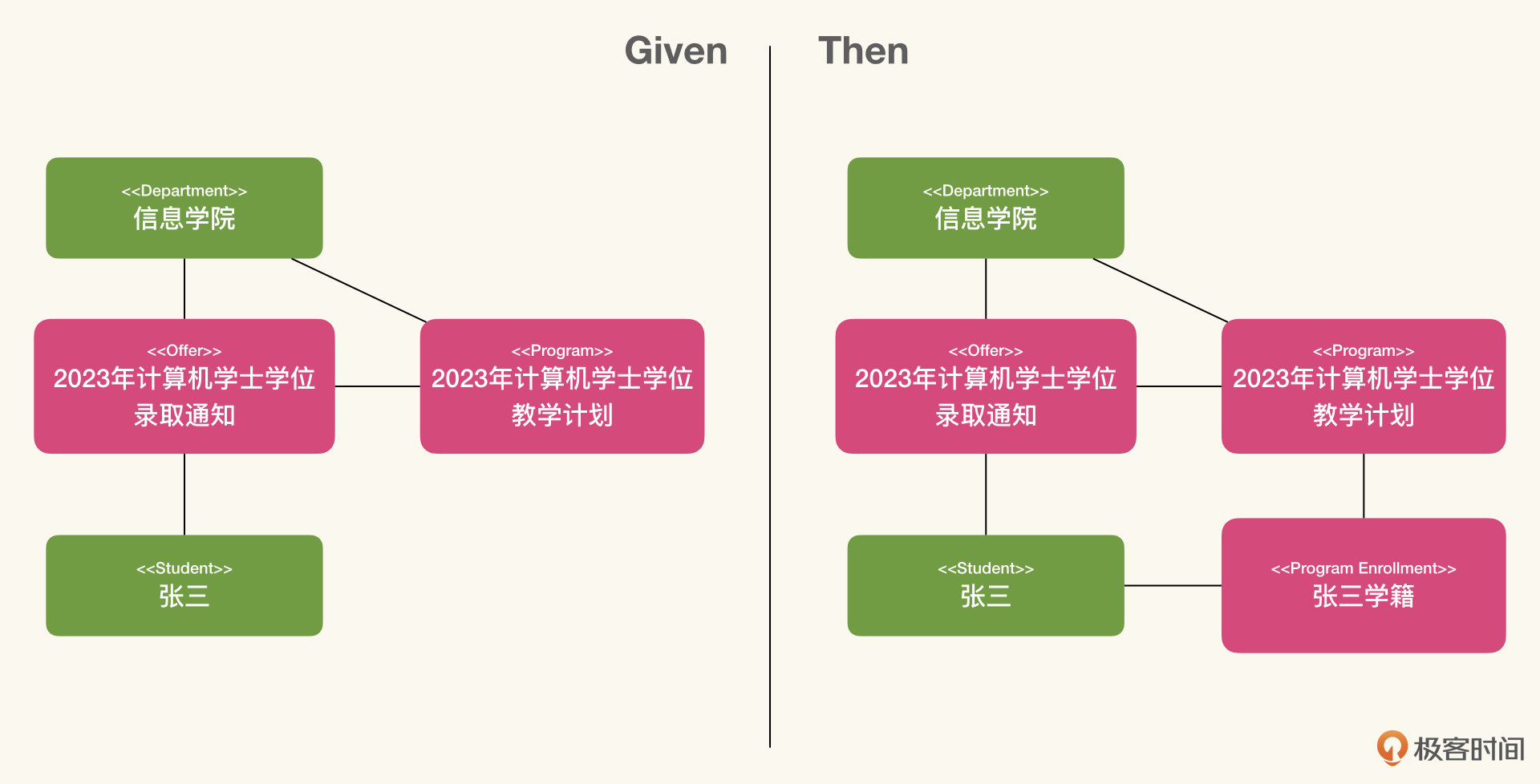
可以明显看到,我们的模型展开了两次。第一次是根据Given描述的场景,寻找样例数据,然后再用模型实例化解释这个数据。第二次是根据When的描述,引入了数据改变,然后再用模型实例化解释这个数据。
这是一个典型的知识生成(Generated Knowledge)场景。下面我来展示一下这个知识提取的过程。让我们先做一个提示词模板,然后先给出第一个任务,让LLM根据验收条件生成样例数据。
领域模型
======
```mermaid
{model}
```
用户故事
======
{user_story}
验收场景
======
{ac}
任务
===
数据都以yaml格式给出。
首先,请根据领域模型理解用户故事中的场景,并针对验收场景中Given的部分,给出样例数据。
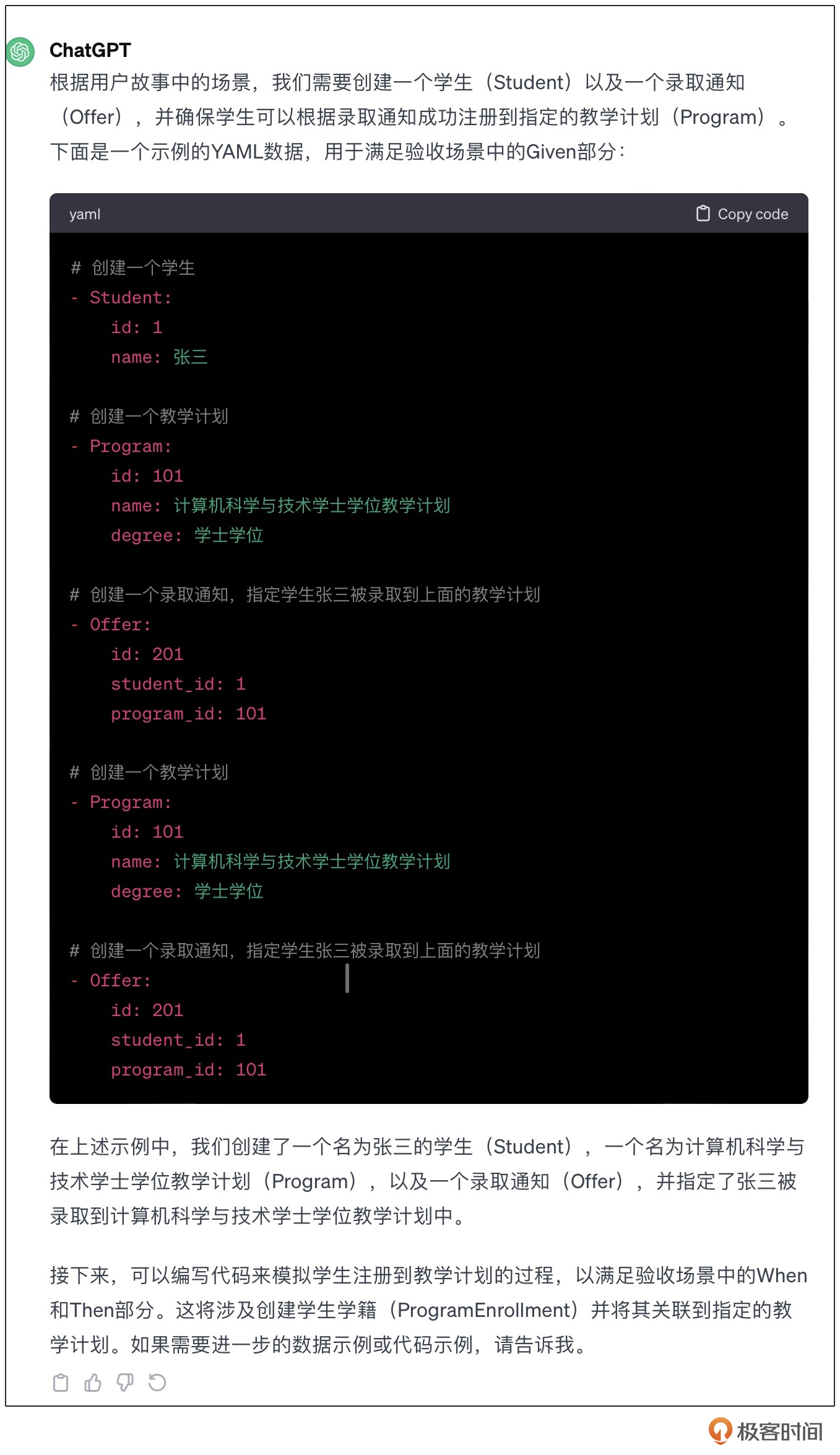
我们看到此处的模型展开与图中得到的结果是一样的,并且LLM按照模型的指引,在当前的上下文中给出了为什么如此展开的解释。最后LLM按照要求以YAML的格式给出数据,便于我们进行数据处理与准备。我们可以改进任务,让LLM帮助我们生成后续的结果。
任务
===
数据都以yaml格式给出。
首先,请根据领域模型理解用户故事中的场景,并针对验收场景中Given的部分,给出样例数据。
然后,参看验收场景中When的部分,给出样例数据会产生怎样的改变。
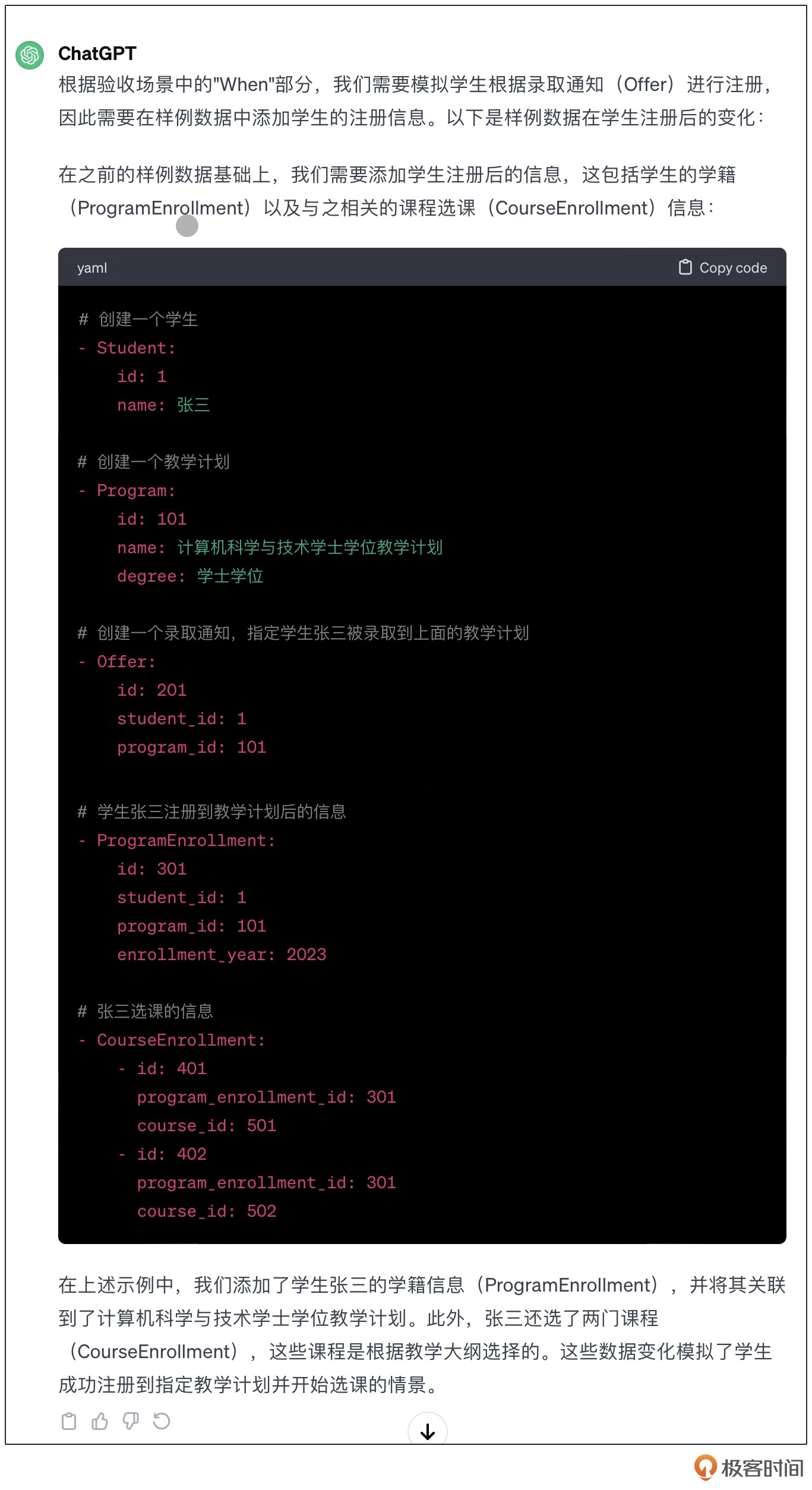
这个结果基本是正确的,但是在注册的时候,LLM认为应该连同课程一起注册了。这并不是我们希望的结果。
那么我们可以继续在半结构化自然语言中,包含一部分思维链的内容(Chain of Thought,CoT),也就是解释一下为什么注册和选课应该是分开的环节,并不应该合并。
classDiagram
Department "1" *-- "*" Program: 提供不同学位的教学计划 >
Department "1" *-- "*" Offer: 为学生发出录取通知 >
Offer "1" --> "1" Program: 录取通知针对某个学位 >
Program "1" --> "1" Curriculum: 教学计划对应的教学大纲 >
Curriculum "1" --> "*" Course: 组成教学大纲的课程 >
Student "1" --> "1" ProgramEnrollment: 学生登录的学籍 >
ProgramEnrollment "1" --> "*" CourseEnrollment: 在学籍有效期内,需要根据教学大纲选课 >
Student "1" --> "1" Offer : 学生拿到的入学通知 >
ProgramEnrollment "1" --> "1" Program: 录取通知中指定的教学计划 >
CourseEnrollment "1" --> "1" Course: 选定的课程 >
%% ProgramEnrollment根据Offer生成,表示学生已经到校注册
%% 向ProgramEnrollment中添加CourseEnrollment,表示学生选课。选课与注册是不同的流程。
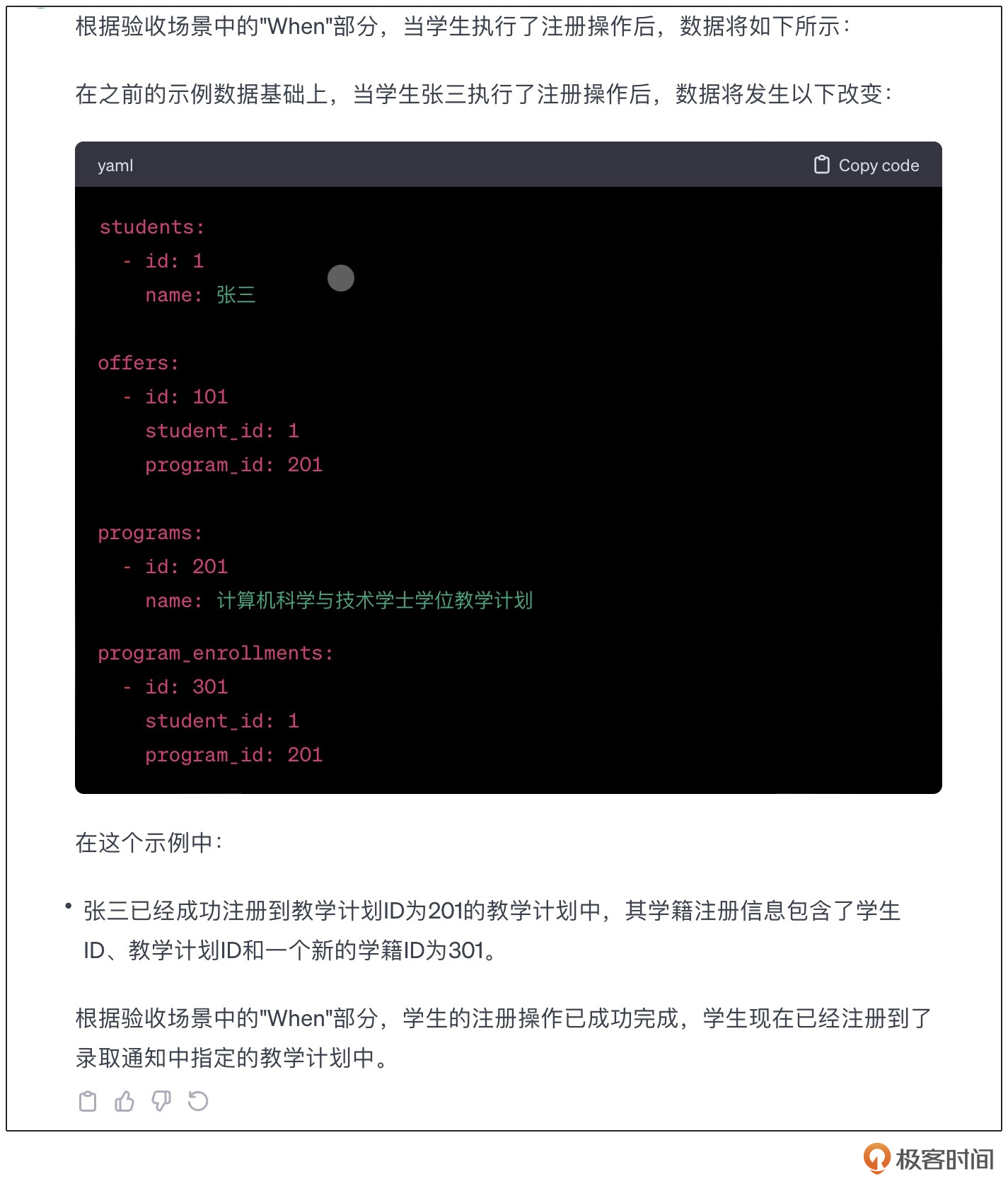
通过在模型描述的注释中,引入部分思维链的内容,我们成功地指导了LLM按照模型与我们的期待,完成了模型展开的部分。
小结
到此为止,我们通过将模型转化为Mermaid格式,并将其转化为半结构化自然语言,指导LLM帮助我们完成了模型展开。这里有几个问题需要注意。
第一,通过Mermaid描述的类图,极大地简化了我们构造CoT的难度。这是因为Mermaid描述的类图,本身就是对于抽象概念的表述。而LLM可以理解Mermaid中的内容,这样LLM会自然而然地使用Mermaid中的概念,做下一步分解映射的指引。这也是目前为止(2023年12月),我们构造思维链最简单的方法。
第二,在LLM通过Mermaid构造的原始思维链中,LLM会更多地将它映射到方案域。所以需要我们通过半结构化自然语言的方式,以问题域的角度,对思维链进行标注。也就是,通过注释给予更多的上下文信息,并且在Mermaid允许提供额外信息的地方,提供自然语言的说明。
第三,由于我们使用的是类图,一些隐含的关系需要通过额外的方式补充。当然,如果我们愿意,还可以逐步引入关键逻辑的时序图,进一步帮助LLM理解业务上下文。但是,以我的经验,大部分时候,一些简单的补充就已经足够了。
最后,如果你不会写Mermaid或是别的结果描述,可以使用ChatGPT-4的识图功能,让它生成最初始的版本,再在其上修改。
思考题
请使用这节课介绍的技术,在其他场景中展开模型。
欢迎你在留言区分享自己的思考或疑惑,我们会把精彩内容置顶供大家学习讨论。
- 李威 👍(2) 💬(1)
请教老师:对于一个复杂的软件系统有大量的领域模型,所有的领域模型及其他们之间的关系我都用mermaid格式编写好,并添加相应的注释,但是最终生成的文本超过了LLM可接受最大字数限制,我譔怎么办呢? 当然我可以根据限界上下文或者功能模块将领域模型进行拆分,每次只为LLM提供部分领域模型的半结构化自然语言描述文本,这样可以让LLM针对部分业务需求为我提供相关的辅助。 还有一种办法是每次为LLM提供部分领域模型的半结构化自然语言描述文本,然后让其先总结一把,之后再输入另一部分的领域模型,继续让其总结以压缩文本内容。但是我试了一下发现,针对这种领域模型的半结构化自然语言的描述文本,LLM一总结就把重要的领域概念直接给总结没了,下次直接使用LLM总结后的文本重新发起一轮新的聊天对话,他就完全不知道自己在说什么了。 所以,请教老师,如何突破LLM对字数的限制,将大量的领域知识一把喂给LLM?
2024-03-26 - 一只豆 👍(1) 💬(2)
有个很模糊的直觉性感触:这两讲中的业务模型好像是比较 E-R 样子的,好像偏重于显性知识的核心脉络全写出来。看了编辑推荐的 《创造知识的企业》后,特别是SECI 模型,我在想 未来的模型是不是 不一定停留在显性知识范畴,而是从人类直接提取不可言说知识后形成的模型。所以我的问题是:我的推论是否合理?哪里偏差了?如果存在这种新模型,LLM 如何辅助我们展开,并增强业务理解?
2024-03-25 - 术子米德 👍(0) 💬(4)
08 | 使用LLM辅助业务理解 🤔☕️🤔☕️🤔 【R】Mermaid(🧜🏻♀️),用它来描述业务模型,能绘制成示意图,人瞄一眼就懂,LLM也能读懂,这样就双赢。 半结构化自然语言(即:写注释),一方面,作为自然语言的结构化补充,另一方面,作为结构化语言的自然补充,这样就双边补充、双边互通。 【.I.】之前,我敲代码,敲的时候,我Clear,跑一下发现不对,那就转到调试,调的时候,我到处打断点,待程序跑到那里,我停下来看看,我大概率是Complex、小概率是Chaotic。无论怎样,我总能一点点来,喝点水、走走路、熬个夜、睡一觉、问一问,总能搞定。 【Q】如今,自然语言的描述、加上半结构化的注释、再加上增强半结构化的Mermaid,输出的内容有个三长两短,除了一遍又一遍尝试,我咋个“逐行调试”法? — by 术子米德@2024年3月25日
2024-03-26 - 范飞扬 👍(0) 💬(4)
神操作! 问个细微的问题,请教一下老师和各位同学的经验: 对于比较庞大的领域模型,画图的方式和顺序有什么经验嘛?比如,应该采用以下哪种方式呢? 1、先用draw.io等类似工具画图,再让gpt生成 mermaid. (可能gpt看不懂?) 2、一开始就用mermaid来画图(可能有些没法用mermaid表达?或者不太灵活?) 3、迭代交织使用1和2。 4、还有更好的方式?
2024-03-25 - aoe 👍(2) 💬(0)
第二次学习,把示例中变量 {user_story}、{ac} 从 07 课中补充完整后询问 AI 获得了正常的答案 第一次学习时,直接粘贴了模板,AI 和我都懵了
2024-03-30 - 范飞扬 👍(1) 💬(0)
趁还没讲到测试驱动AI开发,我盲猜一下:生成 yaml 数据后,就可以用于编写 TDD的测试了,有了测试,“功能良好”的软件 就不是啥问题了。不过仅靠这些yaml,应该还没法保证“架构良好”?架构良好得靠CoT? 那CoT从哪来呢?直接复制粘贴架构的描述?(比如六边形架构的描述?)
2024-04-01 - 赫伯伯 👍(0) 💬(5)
所以,模型展开的用途是什么???
2024-04-10 - 范飞扬 👍(0) 💬(0)
和 chatGPT 的聊天:https://chat.openai.com/share/587f2e0f-53be-4fa0-8458-7f5658b30714
2024-04-04