04 使用LLM提取和传递知识
你好,我是徐昊,今天我们来继续学习AI时代的软件工程。
通过前面的学习,我们逐步认识了知识工程的整体框架,并且尝试用知识工程的视角重新理解软件工程,那么软件工程效率提升的问题,自然就转化成为构造知识传递效率更高的知识过程。
那么大语言模型(Large Language Model,LLM)能否让知识过程更高效呢?这就是今天我们要讨论的问题,因为这是将大语言模型(Large Language Model,LLM)应用到知识过程的前提条件。
LLM是革命性的迁移学习平台
LLM是怎么帮助我们提取知识的呢?我们首先需要将LLM看作一种特殊的迁移学习(Transfer Learning)平台。
迁移学习(Transfer Learning)是机器学习领域的一个重要概念,意思是将从一个问题(源任务)中学到的知识应用到另一个相关的问题(目标任务)上。即使两个任务不完全相同,一个任务中学到的特征、模式和知识也可以在另一个任务中发挥作用,从而提高学习效率和性能。比如,一个可以识别猫狗的计算机视觉AI,可以通过迁移学习训练成用来识别汽车的AI。
迁移学习在实际应用中非常重要,特别是在数据稀缺的情况下。例如,在深度学习中,训练一个从头开始的模型通常需要大量的标记数据和计算资源。通过迁移学习,我们可以利用在大型数据集上预训练的模型,然后将这些模型调整(fine-tune)到特定的、数据较少的任务上。

LLM是一个非常特殊的模型,它的核心能力是阅读理解——结合预训练集中的语料,根据提示词中提供的上下文信息执行任务。从概念上说,当我们为LLM提供了上下文之后,实际已经把LLM迁移成为一个面向特定领域的模型了。
回想一下我们在开篇词中提过的例子:
目前我们在编写一个产品目录服务,通过API提供所有可售商品的详细信息;
此API包含列出所有商品,按SKU查看某个商品,按照分类列出商品以及按关键词搜索的功能;
API返回的结果是json格式;
当查找的SKU不存在时,返回404;
按关键搜索功能使用POST而不是GET;
使用Java编写;
为所有功能提供功能测试,包括异常情况。
请编写功能和测试代码。
这其中包含了上下文描述和问题/任务两个部分:
目前我们在编写一个产品目录服务,通过API提供所有可售商品的详细信息;(业务上下文)
此API包含列出所有商品,按SKU查看某个商品,按照分类列出商品以及按关键词搜索的功能;(业务功能描述)
API返回的结果是json格式;(技术规范描述)
当查找的SKU不存在时,返回404;(技术规范描述)
按关键搜索功能使用POST而不是GET;(最佳实践)
使用Java编写;(技术栈)
为所有功能提供功能测试,包括异常情况;(代码范围)
请编写功能和测试代码。(问题/任务)
在概念上,如果将提示词中的上下文与问题当作截然不同的两个部分,那么实际上我们可以将结合了上下文的LLM看作一个经过迁移学习后的模型:

之所以可以这样看待大模型,是因为LLM在大规模数据集上进行预训练,能够学习到语言的深层结构和模式,因此具备了很强的泛化能力。
这意味着LLM可以很容易地适应新的任务和领域,即使这些任务和领域在预训练时没有明确地被考虑进去。伴随着泛化能力,目前很多LLM支持零样本(zero-shot)或少样本(few-shot)学习。这意味着即使没有数据训练,或者只有很少的数据的情况下,LLM也可以执行特定任务。
零样本或少样本学习是一种革命性的迁移学习机制。比起传统迁移学习,训练数据从几千几万条降低到零或几条。训练时间从几天、几周甚至几个月缩短到几秒钟或者几分钟。
我们在提示词中对于上下文的描述,实际上是在使用零样本学习对LLM进行迁移学习训练。将LLM看作一种特殊的迁移学习(Transfer Learning)平台是通过LLM提取知识的关键,提醒我们需要将用以迁移的上下文和具体的任务分开来看待。
聚焦于知识而非任务
请你回想一下我们在开篇词中提到的例子,它最开始的版本是这样的:
在这个提示词中,主要描述的是任务本身,也就是我们希望LLM帮助我们做什么,对于上下文和知识的描述是非常粗略的。此刻我们的关注点聚焦在LLM能做什么,寄希望于大模型的预训练恰好能够帮助我们补足上下文。
这其实是过往时代和经验带来的局限,我们习惯性地认为,将某个工作实际做出来是非常花费时间的,那么越早开始越好。但是在LLM时代,做出来的成本是非常低的,做对的成本是非常高的。因而,用好LLM的第一步,就是聚焦于知识的提取与组织。
我们可以把要做的事情放在一边,将目光更多的集中在如何迁移训练LLM,也就是如何提取上下文、如何提取知识上。那么我们可以构造这样的一个提示词:
我建议所有人在使用提示词的时候,都将知识的部分(背景)与任务的部分分开。这样能有一个明确的关注点。在这个改版的提示词中,我们暂时放弃了最终目标,而首先检查我们的知识提取是否足够清楚。ChatGPT给我的答案是:
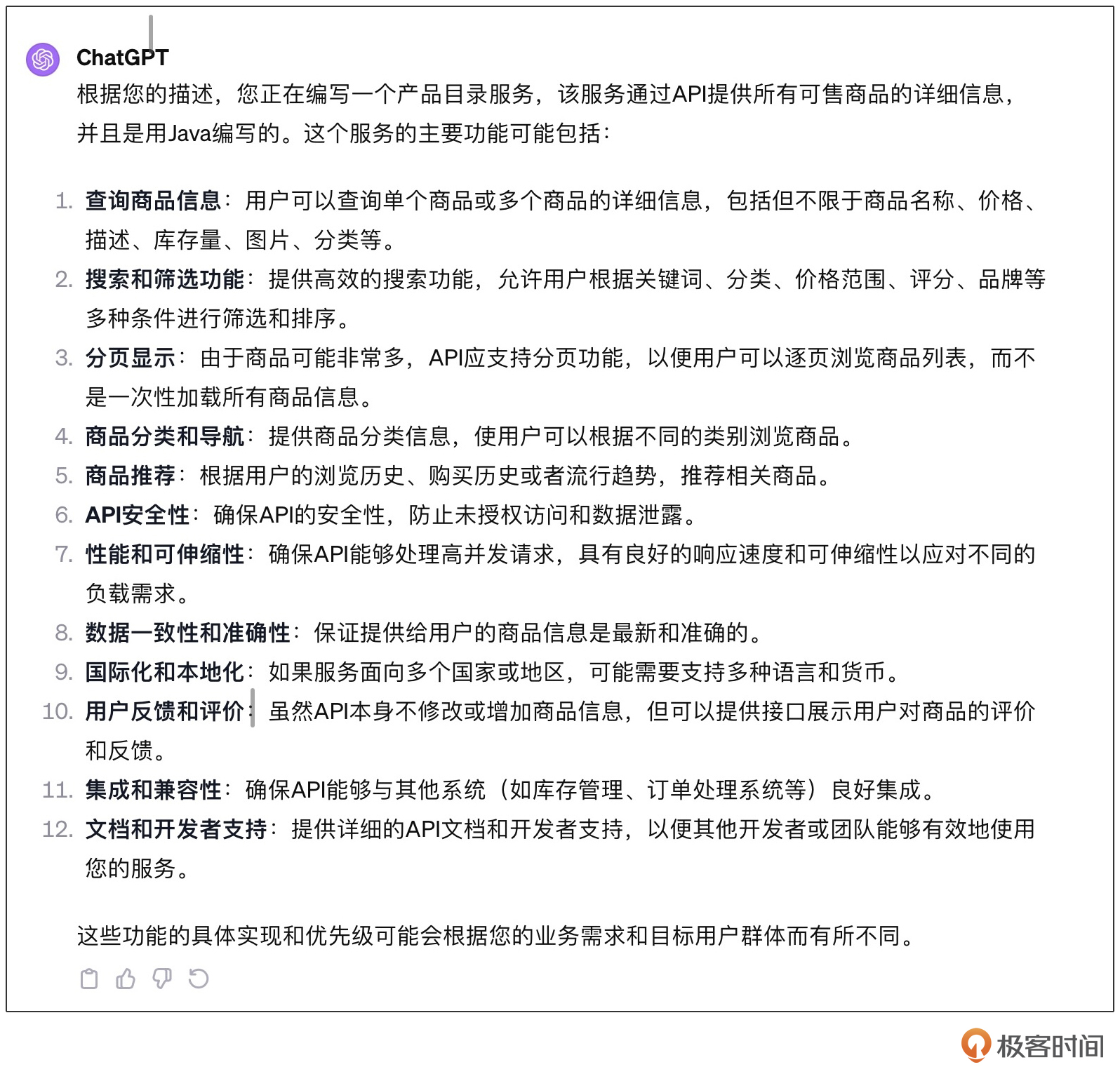
显然,这个答案与我预期的结果是不同的,我们预期中这个API只有列出所有商品、按SKU查看某个商品、按照分类列出商品以及按关键词搜索的功能。ChatGPT列出了非常多的额外功能。如果在这个基础上去生产代码,就会有很多无用的功能。
那这说明什么呢?说明迁移学习的效果并不好,LLM仍然受基础模型的影响,并没有完全迁移到我们现在要处理的领域。我们需要补充额外的信息,让LLM更接近我们要处理的领域。
我们可以补充这部分信息,然后使用同样的问题,再次询问LLM:
背景
===
目前我们在编写一个产品目录服务,通过API提供所有可售商品的详细信息。
此API包含列出所有商品,按SKU查看某个商品,按照分类列出商品以及按关键词搜索的功能;
使用Java编写。
任务
===
请问这个产品目录服务主要有什么功能?
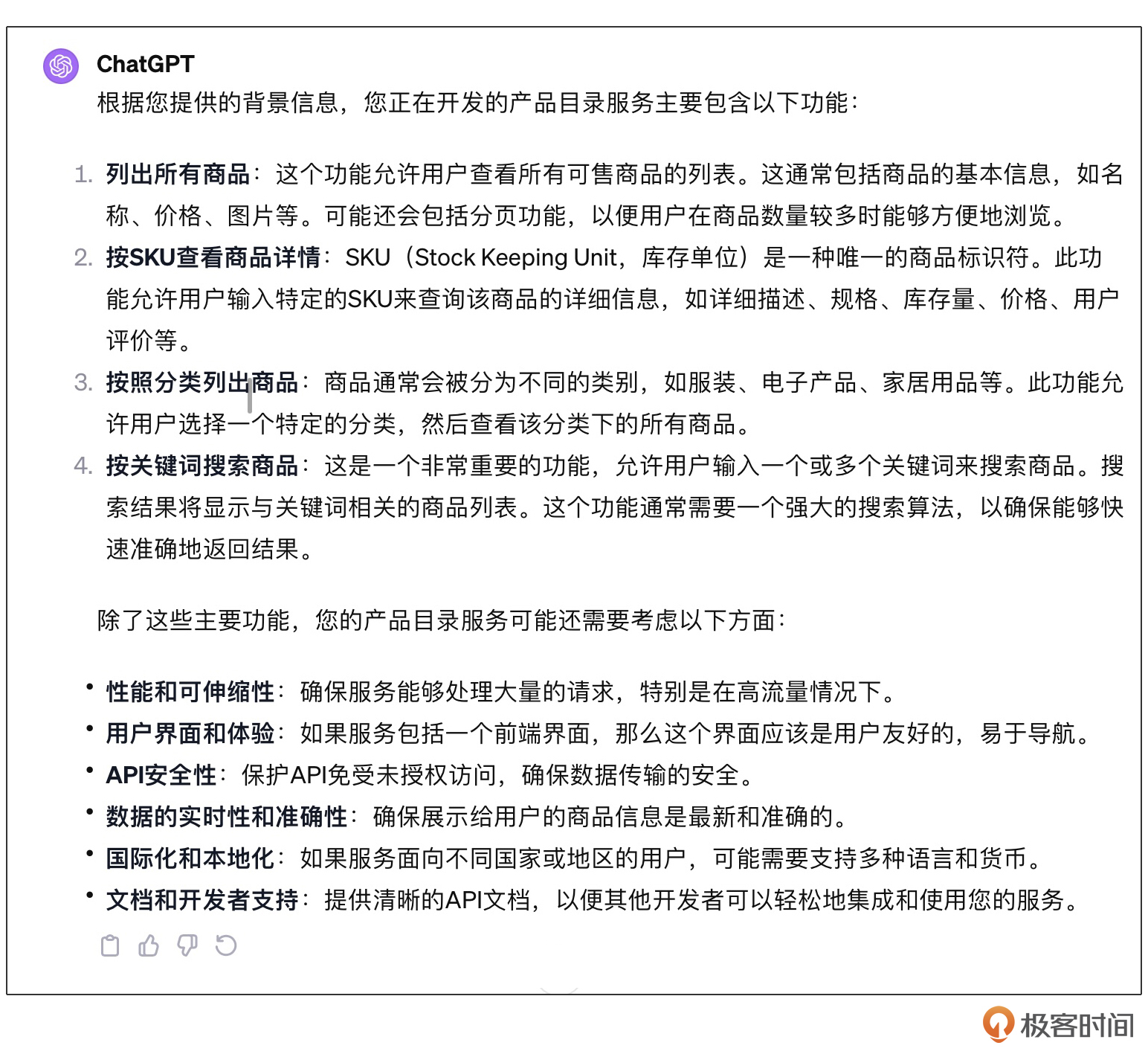
这一次因为我们明确了功能的范围,ChatGPT给出的答案就完全符合我们的要求了。同样,我们还可以继续验证当前的业务知识是否是足够的,比如:
背景
===
目前我们在编写一个产品目录服务,通过API提供所有可售商品的详细信息。
此API包含列出所有商品,按SKU查看某个商品,按照分类列出商品以及按关键词搜索的功能;
使用Java编写。
任务
===
请问通过API提供的产品信息都包含哪些内容?

同样ChatGPT提供了非常多的额外信息。如果在这个基础上去生产代码,还是会有很多无用的功能。因为我们这里是个例子,并没有细扣其中的具体实现细节,但是在实际工作中,我们可能会根据实际的情况,补充更完备的信息,比如:
背景
===
目前我们在编写一个产品目录服务,通过API提供所有可售商品的详细信息。
商品详细信息包括:SKU,商品名字,不同的产品选项,以Markdown形式保存的商品详情;
此API包含列出所有商品,按SKU查看某个商品,按照分类列出商品以及按关键词搜索的功能;
使用Java编写。
任务
===
请问通过API提供的产品信息都包含哪些内容?
当我们把目标聚焦于知识时,我们所关注的就不再仅仅是通过LLM帮助完成某些功能,而是如何使用LLM高质量地完成某些功能。
通过LLM提取与传递知识
这种通过LLM的反馈反思并修改知识描述的方式,就是知识工程中的知识提取流程,你可以结合下图来理解。
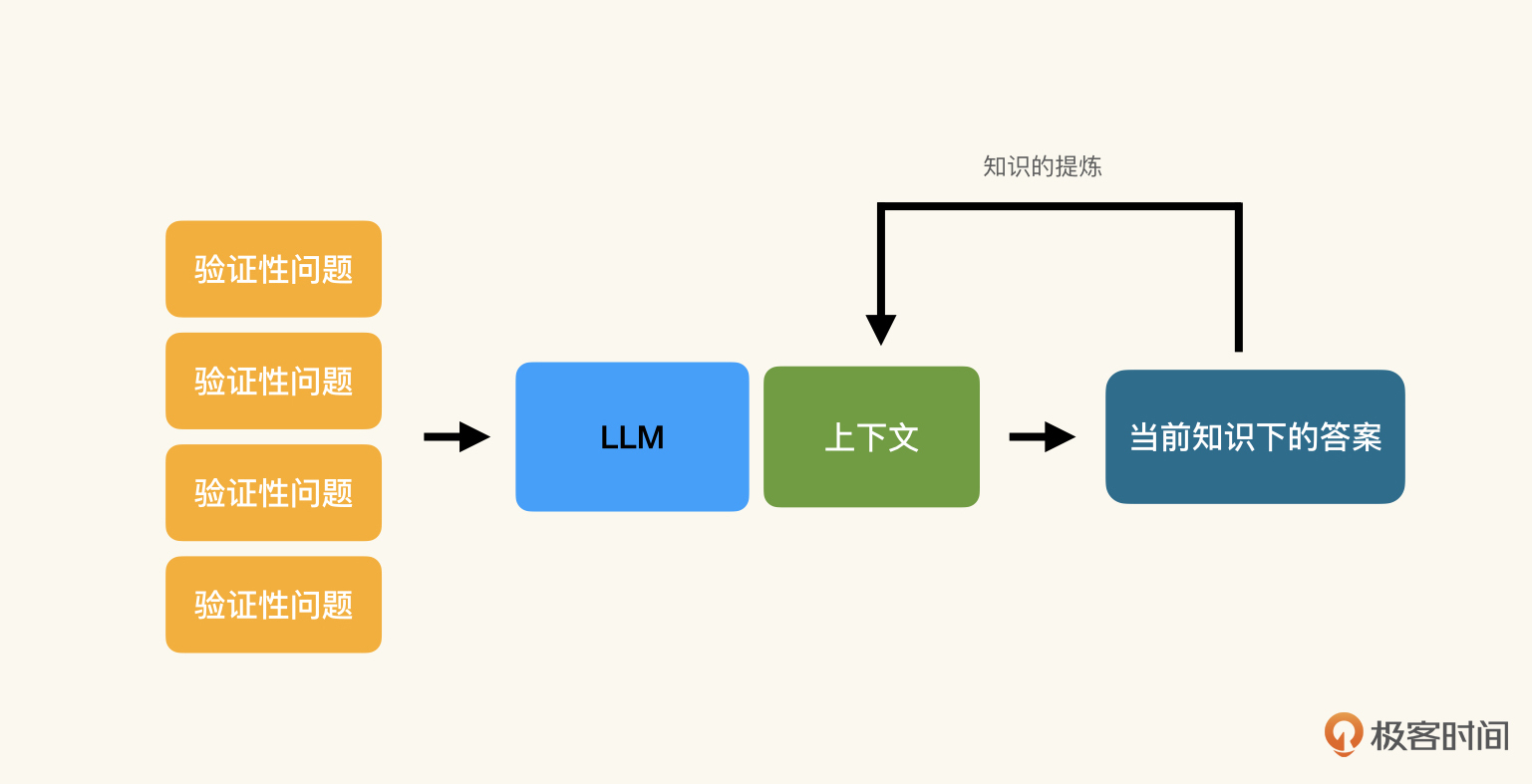
回想一下刚刚的例子,我们提取的是什么知识呢?我们提取的是隐式知识(Implicit Knowledge)。因为对于业务的上下文我们已经有了构想和要求,只不过没有变成文字形式而已。
在提取了隐式知识之后,我们就可以在提取的知识之上,完成不同的任务了。这时候我们的关注点又从知识重新回到了任务。但此时我们会发现,提取出的知识并不仅仅能服务于某一项任务。在上面的例子里,虽然我们是为了编写代码而做的知识提取,但是产生的结果可以服务于其他任务。比如,为API编写文档:
背景
===
目前我们在编写一个产品目录服务,通过API提供所有可售商品的详细信息。
商品详细信息包括:SKU,商品名字,不同的产品选项,以Markdown形式保存的商品详情;
此API包含列出所有商品,按SKU查看某个商品,按照分类列出商品以及按关键词搜索的功能;
使用Java编写。
要求
===
所有API文档需要以RAML形式编写;
如存在异常分支,给出示例;
任务
===
根据背景中描述的业务,按要求编写文档
当我们完成了知识提取,再将知识应用到具体的任务时,就是知识的传递和应用的过程。在知识工程中,知识的提取与传递流程如下图所示:
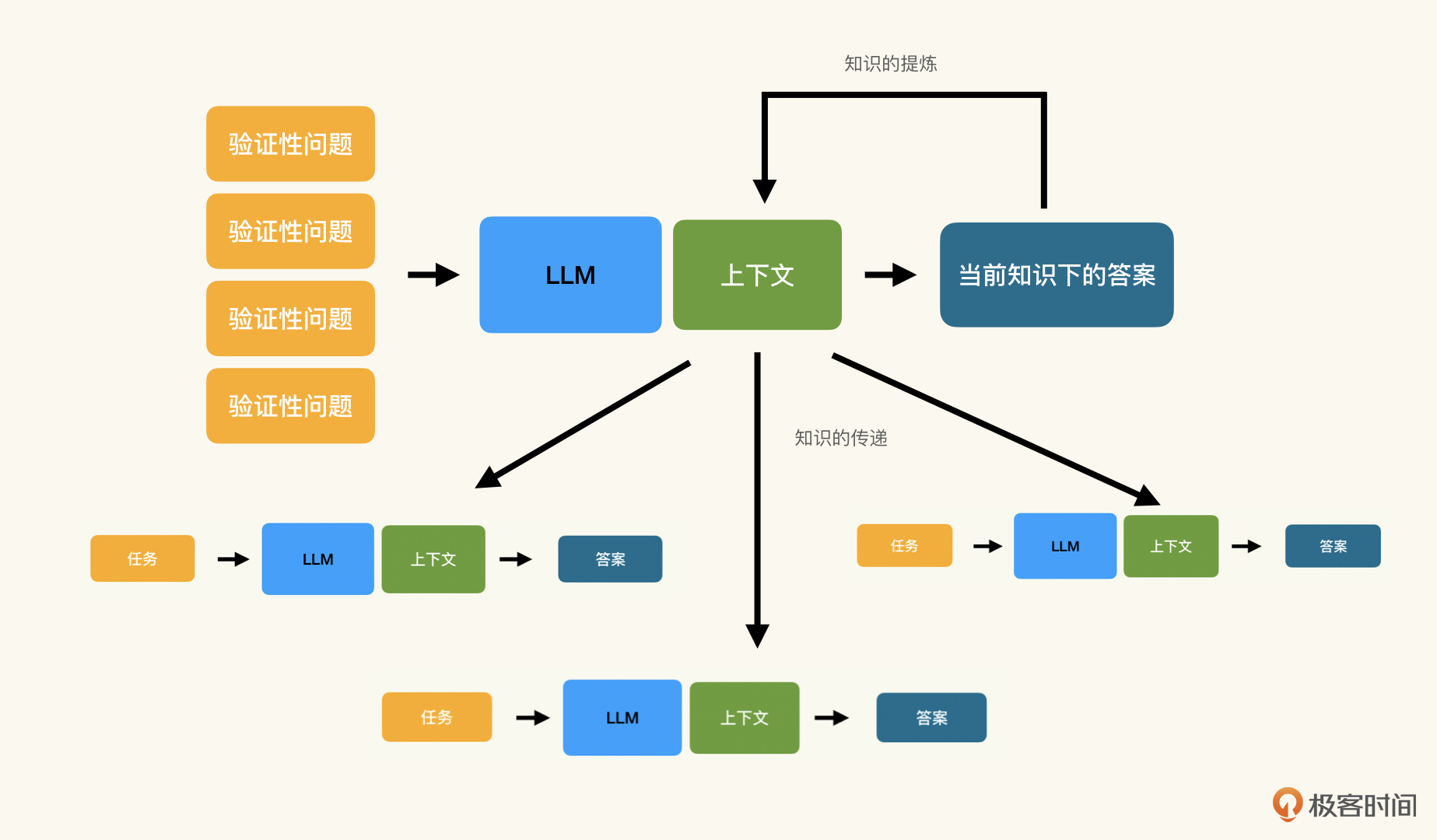
小结
今天我们介绍了为什么要将LLM看作一个迁移学习平台,这样我们就可以将提示词中的上下文和任务赋予不同的意义。上下文负责迁移学习,而任务是要进行的操作。
然后我们沿用了开篇词里产品目录服务的例子,演示了如何提取上下文、如何提取知识。这里的重点是我们要聚焦在知识而非任务上,通过LLM来检验知识的收集与提炼是否充分。再把提取的知识与任务结合,完成知识的传递与应用。
通过LLM的辅助,利用知识与任务的分离,我们有效地收集和传递了显式化的隐式知识。但是对于知识过程中的核心——不可言说知识要怎么处理呢?我们下节课再继续讨论。
思考题
这节课例子演示了如何利用LLM提取隐式知识,那么对于不可言说知识,我们要怎么提炼和应用呢?
欢迎在留言区分享你的想法,我会让编辑置顶一些优质回答供大家学习讨论。
- 杨松 👍(3) 💬(4)
老师,就是不知道如何去描述这个上下文,这方面是由于对所要解决的问题(任务)其中设计到的隐性知识不理解,导致无法准确描述的吧,解决的办法就是多次提出验证性的问题吗?
2024-03-15 - 范飞扬 👍(2) 💬(2)
不知道如何去描述上下文怎么办? 老师说:多次提出验证性的问题、刻意练习。 我觉得老师的回答不够好。 我从文中总结出的方法是:“分而治之”和“筛选”循环。 比如,拿文中的例子来看看这两步是怎么发挥作用的,数字体现了上下文的演进: 上下文1.0:产品目录服务。 1、问 LLM 这个服务有什么功能。(分而治之) (LLM回复了一大串功能。。。) 2、筛选一下功能,丢到下一个上下文,成为上下文2.0。(筛选) 上下文2.0:产品目录服务,API包含 x,y,z功能。 接下来就是重复 1 和 2 就行了。比如,继续问产品有什么信息(分而治之)。
2024-03-25 - 术子米德 👍(0) 💬(2)
🤔☕️🤔☕️🤔 【R】from知识工程,at软件工程: 🔼 软件工程效率 = 构造知识传递过程 🔼 迁移学习(Transfer Learning)-> LLM with ctxInfo in prompt -> new domain specific LLM. 【.I.】LLM里的参数,来自人类的所有知识;跟LLM聊天的过程,就是在把这些参数,还原为相应知识的过程,或者用这些参数,组合出新知识的过程。 聊法,就是让凝结为参数的知识,再次释放出知识的方法,高级点就叫做迁移学习,土法叫做会聊天。 【R】atLLM时代:做出来🔽,做正确🔼。 【Q】知识的提取与组织,跟知识的创造之间的关系是什么?提取,是否意味着知识已经存在,只是没有显式表达出来,而创造,是否意味着知识要实践过程新创造出来,才有所谓的提取知识可言? — by 术子米德@2024年3月17日
2024-03-17 - Geek1591 👍(0) 💬(1)
老师多更新一些啊,意犹未尽
2024-03-15 - 需要练习的码农 👍(0) 💬(1)
课后题答案没思路,感觉还是和识别隐性知识一样的方式,不断prompt。背景、要求、任务中描述的更加具体。
2024-03-15 - 临风 👍(5) 💬(0)
看到老师对留言的回复,强调了第一章内容的重要性,我又返回去看了第一节内容。答案就在题面上,“围绕不可言说知识构造知识过程”,LLM(大语言模型)就是AI时代的利器,那我们要怎么去构造知识过程呢?从第一节的内容可以知道,我们必须要通过社会化的活动,不断的训练、反思,刻意练习才能掌握。 突然想到一个例子,不知道大家玩不玩王者荣耀,我偶尔也会玩,里面有一个绝悟AI的训练场。它可以帮助你去练习各个英雄的连招,就比如露娜的月下无限连,如果是一两年前,你想学会这个连招,你只能去看视频教程,然后自己去摆放木偶进行练习。按的快了以后,你也不知道按对了没有,因为你缺乏反馈或者反馈过慢,除了少数特别热爱或者天赋极高的人,大多数人是无法学会这个连招的。但现在,界面会提示你当下需要的操作,你每进行一次操作,界面就会给你反馈,判断你当前是否操作正确。所以有了这个训练场,对于一个资质平平的普通人,可能要过去要花几十个小时才能学会,现在花几个小时就能学会了。不可言说的游戏连招操作,在这里传递效率就提升了10多倍。 同理,软件工程是否也是一样呢?我觉得答案也是肯定的,我们同样可以通过LLM制造一个“训练场”。比如团队中想要统一代码风格,它的好处就是能降低认知负载,每个人读自己的代码都是相对简单的,但代码风格这种东西是没办法说清楚的,但你一看到一段代码,你就能够看出来和谁的比较像,那么我给LLM喂上大量相同风格的代码,之后我再给LLM一段代码,它就能自动转换为我希望的风格,新的同事就能快速掌握团队的代码风格。
2024-03-15 - aoe 👍(3) 💬(0)
在提问的时候使用敬语,和 AI 做朋友,以后就有一个强大的朋友 分离关注点,有助于学习老师提问的技能
2024-03-15 - 一只豆 👍(2) 💬(0)
关于如何利用 LLM 提炼和应用“不可言说知识”,也许谜底就在谜面上。 翻阅一下“不可言说知识”在课程中提到的蛛丝马迹:1 特定场景下的 know-how 2 从应用题场景里提取隐含的数学关系,然后选择正确的公式或算法求解 3 《庄子》中轮扁询问学徒任务场景下(拿到材料和制式)的制作思路,并根据师傅的经验提供反馈 4 架构设计的不可言说知识在于 如何应对变化。 这些蛛丝马迹共同指向两个关键点: 强场景相关 ,场景解读和对策的映射具象化了不可言说知识。所以,也许“不可言说知识”的验证性问题就是:让 LLM 自编自演+内心独白。 自编自演是描述场景和解决思路;内心独白 是外化场景和解决思路之间的映射关系。 徐昊老师啊,打字打出这两段话真是费了老鼻子劲儿了~ 您课程太通透了,我无以为报,只好豁出去参与一下的啦
2024-03-15 - keep_curiosity 👍(1) 💬(0)
既然要让llm提取不可言说的知识,那就需要让它可以练习。那我们就要扮演老师傅,给出具体场景,让它尝试给出思路,并且告诉它有疑问可以提问,然后我们给出反馈。然后重复不同的场景,直到验证性问题的回答符合我们的预期效果。
2024-03-16 - Sophia-百鑫 👍(0) 💬(0)
提炼不可言说知识的 主要途径 还是要询问 对方的思维过程和对上下文背景的侧重点把握,为啥这么决定。 通过不断的提问验证提问验证,就会挖掘出不可言说的知识 ,不可言说知识通常背后有个强大的方法论支持,基石。
2024-07-31 - 术子米德 👍(0) 💬(0)
🤔☕️🤔☕️🤔 【R】把目标聚焦于知识,通过LLM帮助完成某些任务、实现某些功能,结果视角必然关注此,如何使用LLM更高质量完成任务和实现功能,在过程视角下更值得关注。 【.I.】原来我实现个函数,要再写这个函数的测试,难呐。如今,有LLM来结对,想必能帮我写测试吧。结果,非得我把用例的注释,写到自己都觉得完美感十足时,LLM才能帮我生成用例代码。否则,LLM顶多就是在码间随机作祟的搭子而已。 实际,原来花多少时间,现在还是花多少时间,甚至因沉浸其中,还在完美感驱动下,忘记又多花不少时间。 不过,以前,只有份函数的代码,现在,注释里写得清清楚楚,测试用例是啥、为何要这样写用例、如何实现这个用例,甚至,删除用例代码,LLM还会不厌其烦再生成一份可用的代码,还有,持续改进注释,删除代码后会生成符合新注释的测试代码。 在结果视角,没有什么变化,如果眼里只有函数代码本身的话。 在过程视角,开发要回答,如何验证才达到可交付的要求,开发能想清说清为何这么验证,在What/How/Why方面,同时达到真正符合交付要求。在没有代码之前,就把这些用注释表达出来,这样的过程需要开发的基本功扎实,同时,这样的过程也有助于开发训练自己的扎实基本功。 — by 术子米德@2024年5月29日
2024-05-29 - Jaising 👍(0) 💬(0)
不能提炼出上下文就不断给答案,让 LLM 帮助我们从答案中建立知识模型,并在灌输一定上下文后让 LLM 提问我们来解答
2024-03-25 - 范飞扬 👍(0) 💬(0)
上一讲说:“所谓知识过程,就是从知识管理的角度理解我们的工作,将我们的工作看作产生、传递、应用、消费知识的过程。” 可以得出知识工程的四个关键:产生、传递、应用、消费。 那么这一讲的“知识的提取与组织” 是不是对应与“产生”呢?
2024-03-24 - 范飞扬 👍(0) 💬(0)
知识提取流程:通过 LLM 的反馈反思并修改知识描述的方式。比如,ChatGPT 提供的信息过多(反馈),我多加点信息让 LLM 的反馈更精确。 知识传递过程:把提取出的上下文(原来是隐式知识),复制粘贴到下次与LLM的交互。比如,复制粘贴需求背景。 知识应用过程:让 LLM 做任务。比如,写 API 文档。 (最后有个问题:老师的措辞用了流程和过程这两个词,这是为啥呢?我没想出区分的理由)
2024-03-24 - 奇小易 👍(0) 💬(0)
对于不可言说的知识,猜测是跟隐式知识提取过程类似,把自己对某个问题的解决方案来作为上下文信息给到 LLM 使其完成迁移学习,从而跟它开始结对解决问题。
2024-03-21