24 带你看一个完整的向量数据库Milvus
你好,我是彭旭。
前面几节课我们介绍了Faiss,学习了使用Faiss构建索引与向量化检索,也用Faiss来搭建了一个简单的人脸识别应用。
通过对Faiss的介绍,你应该知道,Faiss不像数据库一样持久化存储向量化数据,而是每次使用之前,都需要从硬盘等持久化设备读取数据,加载索引。并且Faiss也没有一个数据库所需要的数据管理功能。所以 DBRanking 对向量数据库的排名,并没有将Faiss包括在内。
那有没有一个具备完整的数据存储、管理功能的向量数据库产品呢?
有,就是我们这节课要介绍的Milvus。
Milvus是什么?
Milvus其实是基于Faiss、HNSW、DiskANN、SCANN(Scalable Approximate Nearest Neighbor)等这些向量检索库构建的,被设计用来做稠密向量的相似性检索。它可以支持十亿,甚至万亿以上向量化数据的存储检索。
Milvus支持数据分片、动态Schema、单向量检索、多向量检索、向量与标量混合检索以及许多其他高级功能。
与StarRocks类似,Milvus也支持存算分离。因为Milvus使用MinIO对象存储来存储日志文件的快照、索引文件、数据以及一些查询的中间结果,所以能够快速地部署在兼容MinIO协议的AWS S3和Asure Blob上。
最后,作为一个具备完整数据管理功能的向量数据库,GUI也是必不可少的一项,Milvus提供了一个attu的Web GUI工具,你可以在这里下载部署。
Milvus架构

从架构上来看,Milvus服务包括四层:访问层、协调服务层、工作节点和存储。这几个分层在弹性伸缩与故障恢复上可以相互独立。
访问层由一组无状态的代理服务组成,接收客户端的请求,有点类似StarRocks的FE,访问层使用负载均衡工具(比如Nginx、Kubernetes Ingress、NodePort等)来提供一个统一的服务地址。Milvus也采用了大规模并行处理(MPP)架构,请求被并发地发送到后端处理,然后在访问层做一个汇总,最终将结果返回给客户端。
协调服务层是Milvus的“大脑”,又可以分为三种类型的协调服务。
- Root coordinator:用来处理DDL和DCL请求,比如创建、删除Collection、Partition、Index等,在Milvus里面,Collection就相当于关系型数据库里面的表。
- Query coordinator:负责管理和协调查询操作,包括查询的拓扑结构管理、负载均衡、查询节点之间的通信和数据传输等。
- Data coordinator:负责管理和协调数据的存储和访问,包括数据的分片、索引构建、数据迁移等工作。 确保数据的高效存储和检索,是实现数据的快速查询的核心。
工作节点是Milvus的手脚,由于Milvus是存储与计算分离,所以工作节点是无状态的,会无脑执行从代理传来的数据操作语言(DML)命令。同样地,工作节点也可以分为三种类型。
- Query Node:主要负责接收用户的查询请求,并进行向量相似度搜索和数据分析等操作。查询节点负责对数据进行检索和计算,返回查询结果给用户。
- Data Node:Milvus数据的DML操作,同样会生成类似Redo Log的预写入日志,然后写入消息中间件,Data Node就从消息中间件订阅这些日志消息,处理变更请求,并将日志数据打包成日志快照,存储在对象存储中。
- Index Node:负责构建索引,管理索引。
存储层是Milvus的骨架,负责数据的持久化,存储层包含三种类型的数据存储。
- Meta Storage存储元数据的快照,比如数据库schema、日志消费checkpoint等,为了保障存储元数据需要极高的可用性、强一致性和事务支持,Milvus使用etcd存储元数据。
- Object Storage使用MinIO对象存储日志文件的快照、索引文件、数据以及一些查询的中间结果。
- Log Broker是Milvus的脊椎。它负责数据持久性和读写分离,系统数据的操作,都会以日志的形式写入Log Broker, 然后给到下游消费去更新本地数据。Milvus集群使用Pulsar作为Log Broker,单机版采用RocksDB作为Log Broker。
从架构上看,Milvus就是一个大数据时代常用的分布式架构模式,不过Milvus作为向量数据库,不支持SQL查询,反而提供了丰富了SDK,比如Python、Java、Go等。
接下来,我们就来看一下Milvus的逻辑模型,在这个过程中使用Python SDK来演示下与Milvus的交互过程。
Milvus的逻辑模型
Milvus的逻辑模型与关系型数据库类似。
首先,你可以创建database,然后给特定用户分配权限,来管理这个database。
from pymilvus import connections, db
conn = connections.connect(host="127.0.0.1", port=19530)
database = db.create_database("RAG")
与其他数据库直接授权给用户的方式不同,Milvus使用RBAC(Role-Based Access Control,基于角色的权限控制)来控制资源的访问,比如database、collection,甚至是partition。你可以新建一个角色,然后授予这个角色一些权限,最后将这个角色跟用户关联起来。
from pymilvus import MilvusClient
client = MilvusClient(
uri='http://127.0.0.1:19530',
token='root:Milvus' # username:password
)
client.create_role(
role_name="roleA",
)
client.grant_privilege(
role_name='roleA',
object_type='User',
object_name='SelectUser',
privilege='SelectUser'
)
client.create_user(
user_name='rag_user',
password='P@ssw0rd'
)
client.grant_role(
user_name='rag_user',
role_name='roleA'
)
其次,database里面可以有多个collection。Collcection就类似关系型数据库的表。Milvus创建collection的时候,需要指定字段field。它也同时支持动态字段,插入时,新增的动态字段会以Key-Value的形式存储在一个叫做$meta的特殊字段当中。
from pymilvus import MilvusClient, DataType
# 2. Create schema
schema = MilvusClient.create_schema(
auto_id=False,
enable_dynamic_field=True,
)
schema.add_field(field_name="pk", datatype=DataType.INT64, is_primary=True, auto_id=True)
schema.add_field(field_name="user_id", datatype=DataType.INT64, description='user unique id')
schema.add_field(field_name="file_sha1", datatype=DataType.VARCHAR, description='file sha1', max_length=128)
schema.add_field(field_name="file_size", datatype=DataType.INT64, description='file size')
schema.add_field(field_name="file_name", datatype=DataType.VARCHAR, description='file name', max_length=512)
schema.add_field(field_name="text", datatype=DataType.VARCHAR, description='the original content', max_length=65535)
schema.add_field(field_name="vector", datatype=DataType.FLOAT_VECTOR, description='Embedding vectors', dim=1536)
# 3、创建index
index_params = client.prepare_index_params()
index_params.add_index(
field_name="vector",
index_type="IVF_FLAT",
metric_type="IP",
params={"nlist": 128}
)
# 4、创建collection,同时加载index
client.create_collection(
collection_name="RAG_COLLECTION",
schema=schema,
index_params=index_params
)
注意,创建collection的时候,一般需要同时创建好索引。像关系型数据库一样,创建一个表的时候,就需要考虑怎么样去访问这个表,根据使用场景设计好索引。当然,你也可以先创建collection,然后再添加一个索引。collection在开始写入数据与查询之前,需要先load,load的过程就会将索引加载到内存。
# 5. Load the collection
client.load_collection(
collection_name="RAG_COLLECTION",
replica_number=1
)
在load collection的时候,可以设置一个collection数据需要加载的副本数replica_number,在单机版本下,这个副本数最大值是1,在集群模式下,最大值则是queryNode.replicas这个配置的值。
在集群模式下启用多副本,Milvus会将同一个数据片段分布到多个queryNode,这样可以用来容灾与提升查询性能。
然后,当你创建一个collection时,Milvus会为这个collection默认创建一个叫做 _default的分区 partitions。在一个collection下,最多可以创建4096个分区。
Milvus有两种创建partition的方式。
第一种是在创建完collection后,手动再创建分区。
# 4、创建分区
client.create_partition(
collection_name="RAG_COLLECTION",
partition_name="partition_technology"
)
第二种是在创建collection的时候,使用一个字段,作为分区键来分区。
schema = MilvusClient.create_schema(
auto_id=False,
enable_dynamic_field=True,
partition_key_field="user_id",
num_partitions=16 # Number of partitions. Defaults to 16.
)
Milvus使用分区键来创建分区的方式跟其他分布式数据库一样。使用分区键查询的时候,同样可以用分区键来“裁剪”查询时需要扫描的数据量。
数据写入与读取
一个collection里面一般会定义多个标量字段,以及至少1个向量字段。创建好collection并load后,就可以开始向collection写入与读取这些标量与向量数据了。
import random
from pymilvus import MilvusClient
# 2. Insert randomly generated vectors
data = []
for i in range(1000):
user_id = i % 2 + 1
file_sha1 = ''.join(random.choices('abcdef0123456789', k=128))
file_size = random.randint(1, 10000)
file_name = ''.join(random.choices('abcdefghijklmnopqrstuvwxyz', k=20))
text = ''.join(random.choices('abcdefghijklmnopqrstuvwxyz', k=100))
vector = [random.random() for _ in range(1536)]
data.append({
"user_id": user_id,
"file_sha1": file_sha1,
"file_size": file_size,
"file_name": file_name,
"text": text,
"vector": vector
})
res = client.insert(
collection_name="RAG_COLLECTION_P",
data=data
)
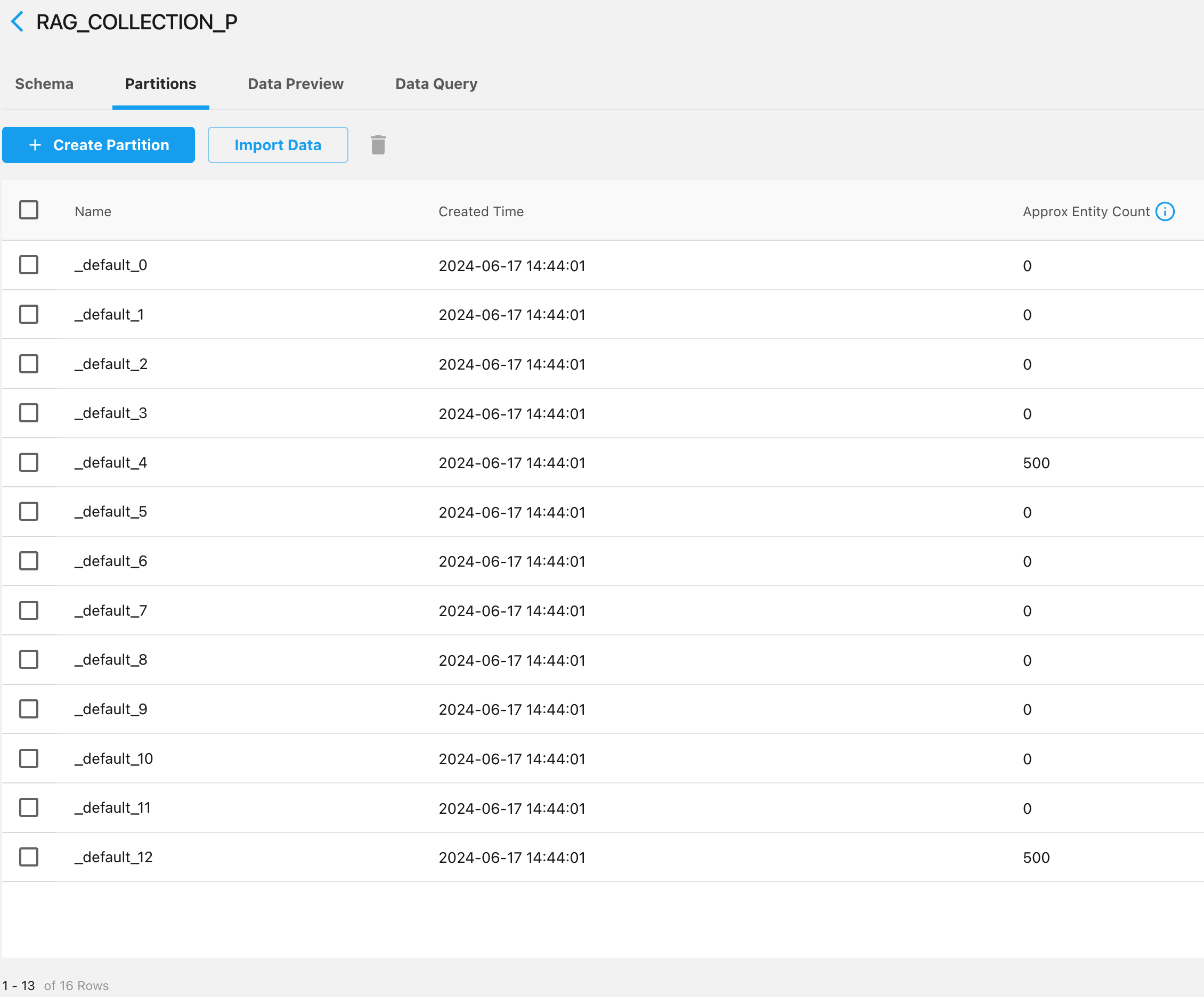
上面的代码片段,为两个用户随机准备了1000条记录,然后插入了我们之前创建的以user_id作为partition key的collection。从下面的图可以看到,这两个用户的数据,就是分布到了两个partition。
接下来就可以开始检索数据了,在Milvus中,基于标量字段的查询被称为Query,基于向量字段的查询被称为Search。
在2.3.x版本中,同时基于标量字段与向量字段的查询被叫做Hybrid Search。
query_vectors = [[random.random() for _ in range(1536)]]
result = client.search(
collection_name="RAG_COLLECTION_P",
data=query_vectors,
filter="user_id == 1 && file_name like 'pmp%'",
search_params={"metric_type": "IP", "params": {"nprobe": 10}},
output_fields=["user_id", "file_name", "text"],
limit=3
)
比如上面的代码片段,通过标量字段过滤了user_id=1 , 文件名以pmp开头的数据,然后再进行向量化检索,找到与向量query_vectors近似的数据行,就是一种Hybrid Search。
注意,向量化检索时,度量方式metric_type的取值必须与创建索引时指定的值一样,这里使用IP(Inner Product,内积)的度量方式。
但是在2.4.x版本里,“Hybrid Search”被用在一个collection中存在多个向量字段,并且多个向量字段被同时检索的场景。
多个向量字段同时检索时,需要选择一个Ranking的策略,用来决定结果的排序,比如WeightedRanker策略,会为每个向量字段分配一个权重,结果就基于这个权重来排序。
2.4.x版本,还增加了一个基于主键列,作为id Get数据行的方法。
好了,到这里你已经对Milvus的逻辑模型有一定了解,能够使用Milvus去存储数据、查询数据了,你还可以使用各种索引来调优数据的读取性能。
Milvus的索引
Milvus支持给向量字段、标量字段创建索引。具体怎么索引呢?
首先,collection的数据由多个不可变的数据片段组成,这些数据片段被称为segment。
当给标量字段创建索引后,向量化检索的时候如果带上这个索引字段作为过滤条件,Milvus会检查每个segment是否包含查询的数据,然后构建一个segment是否存在数据的bitset。向量检索的时候,会把这个bitset作为查询参数传递,用来“裁剪”需要检索的segment。看到这里,是不是又想起了布隆过滤器?
好,再说向量字段的索引。Milvus支持几种模式:In-Memory Index、On-Disk Index、GPU Index。分别适用不同的场景。
比如我们的人脸识别场景,正常情况下使用In-Memory Index,查询的响应时间能够控制在几十到几百毫秒。
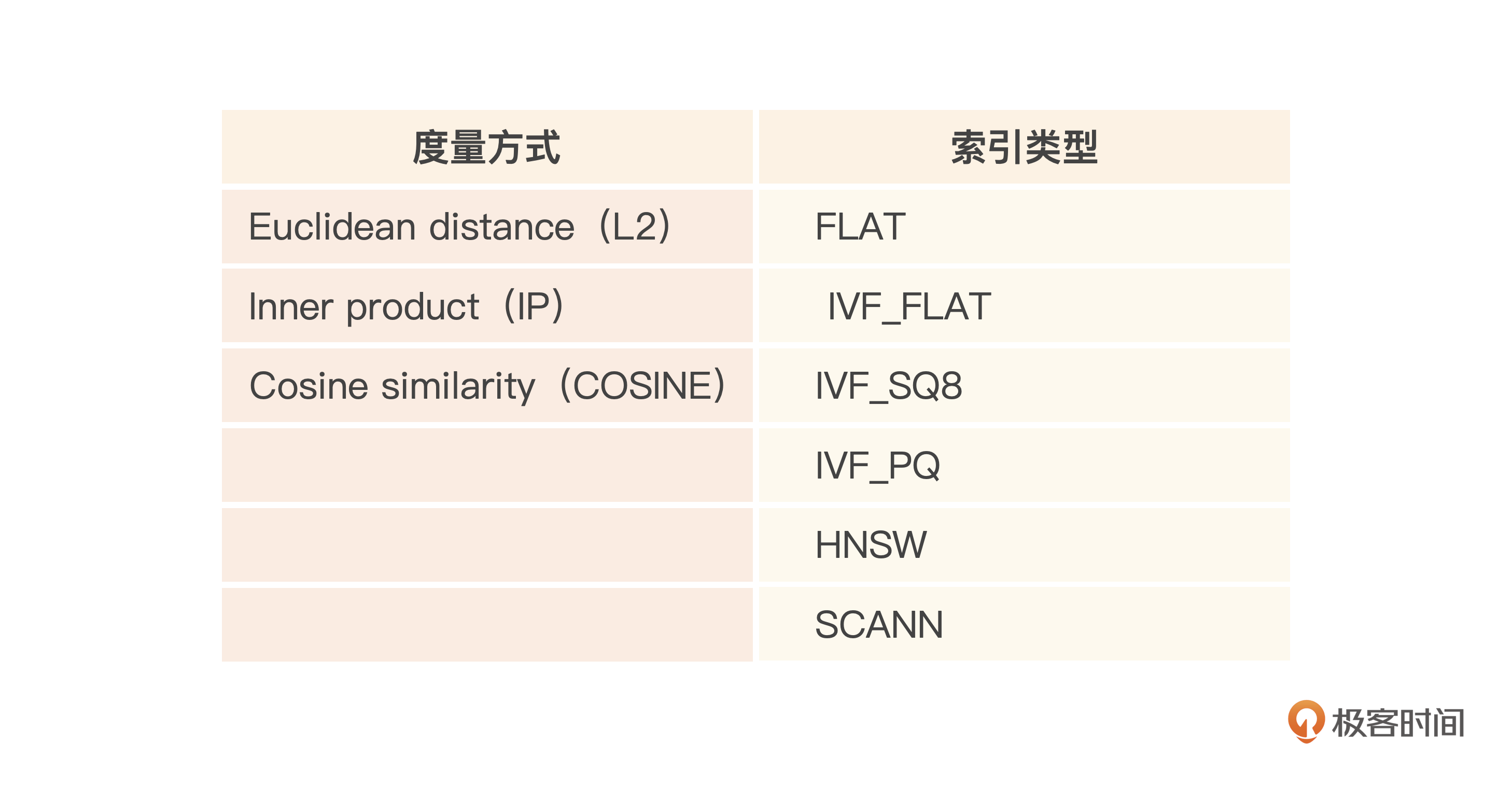
In-Memory Index是最常用的向量索引方式,向量索引基于内存存储。其实跟Faiss类似,支持多种ANNS算法索引与度量方式,两者组合就形成了一个索引类型。以浮点数向量索引为列,你可以参考下表:
index_params.add_index(
field_name="vector",
index_type="IVF_FLAT",
metric_type="IP",
params={"nlist": 128}
)
当人脸图片数量增加到一定程度,它向量化后的数据,在内存中已经放不下了,这时候就可以考虑使用On-Disk Index,但是相应地也会带来性能的下降。
创建On-Disk Index的时候,只需要指定index_type为DISKANN。
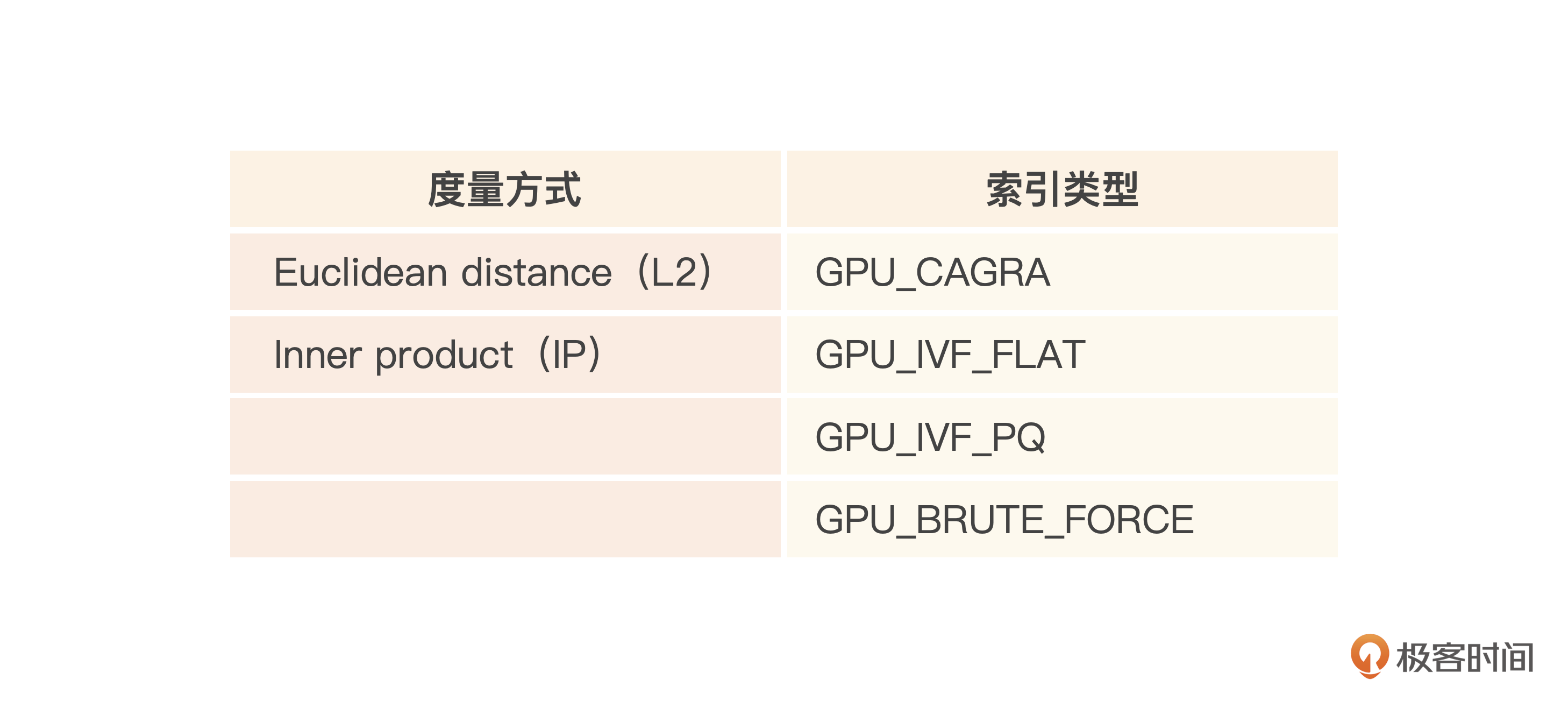
如果需要进一步提升性能与吞吐量,就可以考虑GPU Index,使用GPU Index的吞吐量可以是In-Memory Index的几倍,性能上通常也能够得到提升,不过GPU机器一般比较贵,所以会带来成本的上升。
同样你可以参考下表GPU索引支持的索引类型与度量方式。
你可以在这里找到完整的代码清单,帮你理解、测试Milvus。
小结
在DBRanking对纯向量数据库的排名中,Milvus排名第2,仅次于Pinecone。这里我认为有很多方面的考量,比如Milvus的性能突出、分布式集群架构,能够支撑的数据体量巨大、简单易用、支持多语言SDK访问、同时支持私有化与SaaS、支持GPU索引等。所以Milvus号称全球用得最广的向量数据库,被超过5000家企业使用。
此外,Milvus有多种多租户支持的方式,比如基于database隔离、基于collection隔离、基于partition隔离、基于字段隔离。如果你需要构建一个在线的SaaS系统,Milvus也为多租户、多用户的数据隔离,提供了非常灵活的支持。
同时,Milvus架构也吸取了分布式关系型数据库的优点,比如支持数据分片、多副本等等。Milvus的数据片段写入后不可变,但也支持upsert来更新数据。它也和LSM类似,也会有后台compact任务来合并segment,同时清理删除的数据。
Milvus支持内存索引、磁盘索引、GPU索引。如果使用内存索引,索引节点会在collection加载的时候,把索引数据写入内存。
说了这么多优点,再说说我的感受。上节课我用Faiss构建了人脸识别系统,对比用Milvus构建个人知识库的时候,会感觉到Milvus在响应上更快。而且SDK的支持种类比较多,API设计简单,用起来确实便捷。下节课,我们就一起上手体验Milvus。
思考题
Milvus的标量索引,其实是以搜索引擎的逻辑来构建的,你知道它用的是什么数据结构吗?
欢迎你在留言区和我交流。如果觉得有所收获,也可以把课程分享给更多的朋友一起学习。欢迎你加入我们的读者交流群,我们下节课见!