22 Faiss是一个向量数据库吗?
你好,我是彭旭。
在上一讲中,我们探讨了人工智能领域对于数据的向量化表达以及相应的存储和检索需求,这极大地促进了向量数据库技术的发展。
自从2017年FaceBook开源了Faiss后,从2019年到2020年,市场上诞生了许多优秀的向量数据库,据 DBRanking 对向量数据库的排名所示,最新流行的纯向量数据库排名靠前的包括如Pingcone、Chroma、Weaviate、Milvus等。
让人奇怪的是,这个榜单竟然没有把Faiss包含在内。在我看来,这是因为Faiss其实不能算是一个完整的数据库。
为什么呢?
我们先来看一下Faiss提供了什么能力。
Faiss是什么?
官方对Faiss的介绍是“Faiss是一个用于高效相似性搜索和密集向量聚类的库”。注意,这里说Faiss是一个库,而没有说是一个数据库。
事实上,Faiss是用C++编写的,并提供了一个Python的封装,而Faiss对外提供的服务就是一个Python的依赖库,所以它并不具备一个完整的数据库的功能,甚至不具备数据的持久化能力、数据的管理能力。
比如说Faiss每次在程序中访问之前,都需要重新加载数据,然后基于这些数据在内存中构建索引。但是程序一旦结束,这些数据就在内存中消亡了,并不会被持久化存储。除非手动调用Faiss的API将构建好的索引数据,以文件的形式存储到磁盘。但是,就算存储下来,也没有一个管理工具可以查看这些数据,只能在Faiss重新启动后,再去加载这个文件。
看到这里,你也会觉得Faiss并不是一个完整的数据库了吧。
Faiss号称能够处理百万千万级数据量,但是刚刚又说数据全部是加载到内存构建索引,那么我们需要多大的内存来支持这么大体量的数据呢?
其实,Faiss通常使用32 bit的浮点数来代表向量,向量的维度通常从几十到几百,这里我们假设向量维度为128,这样我们可以简单地用下面的公式来计算向量占用内存的大小。
公式中向量数就是我们需要存储的数据量大小,向量维度= 128,一个32 bit的向量字节大小为4 byte,所以最终一百万向量占用内存的大小如下:
当然,实际上需要存储到内存的数据并不仅仅是向量本身,还可能需要包括向量编号、原始的数据等等,某些索引也需要额外的内存。但是即使这样,一台16 G以上的服务器,也基本都能承载百万级向量数据的索引与检索。
Faiss的安装使用也很简单,接下来我用一个简单的例子带你体验一下Faiss的向量化检索。
简单使用Faiss
前面提到Faiss就是一个Python的库,最新版本推荐使 用 conda 来安装,在服务器上安装好conda之后,只需执行一条命令即可安装Faiss库。
# CPU-only version
$ conda install -c pytorch faiss-cpu=1.8.0
# GPU(+CPU) version
$ conda install -c pytorch -c nvidia faiss-gpu=1.8.0
# GPU(+CPU) version with NVIDIA RAFT
$ conda install -c pytorch -c nvidia -c rapidsai -c conda-forge faiss-gpu-raft=1.8.0
这里提一下现在Faiss的CPU版本支持Mac、Linux、Window操作系统,但是GPU版本只能在Linux上运行。
接下来我们就来看一下如何使用Faiss来添加数据构建索引,然后进行向量检索。
import pandas as pd
data = pd.read_csv("/Users/xupeng/Downloads/sentence.csv", sep='\\t')
data.head()
sentences = data['sentence'].tolist()
print("sentences length: {}".format(len(sentences)))
from sentence_transformers import SentenceTransformer
# 初始化文本向量化模型
model = SentenceTransformer('bert-base-nli-mean-tokens')
# 将文本向量化
sentence_embeddings = model.encode(sentences)
# 获取向量化后向量的维度
d = sentence_embeddings.shape[1]
import faiss
# 创建faiss索引
index = faiss.IndexFlatL2(d)
# flat索引无需训练,所以这里输出为true
print("is_trained: {}".format(index.is_trained))
# 将数据添加到faiss索引
index.add(sentence_embeddings)
k = 5
xq = model.encode(["Someone sprints with a football"])
import time
start_time = time.time()
# 搜索TOP 5最相似向量
D, I = index.search(xq, k) # search
end_time = time.time()
execution_time = (end_time - start_time)*1000
print(f"执行时间: {execution_time} 毫秒")
print(I)
# 根据搜索结果位置找出原数据
print(data['sentence'].iloc[I.flatten().tolist()])
上面的代码是从csv文件中读取了一个sentence列表,将sentence向量化后,通过Faiss建立索引,最后用一个句子转化为向量来检索。
你可以从这里下载这个csv文件。
注意,第10行我们初始化了一个文本向量化模型,这是一个提供用于自然语言处理(NLP)任务的 BERT 类型模型。
因为其实大部分向量数据库都不提供向量化模型,基本都依赖外部的向量化模型来将文本、图片向量化。当然其中也有一些特例,比如Weaviate就提供了各种内置的模型,包括text2vec-transformers、multi2vec-bind等,也支持与各种外部模型集成。
这里我们同样可以使用pip命令来安装这个模型,不过这个模型需要科学上网。为了防止你无法访问这个模型,我也准备了一个用Python Numpy来生成一些随机向量测试的代码,你可以在这里找到这个测试代码。
代码上面我都添加了注释,容易理解,这里我就不展开说明,代码运行结果如下图所示:
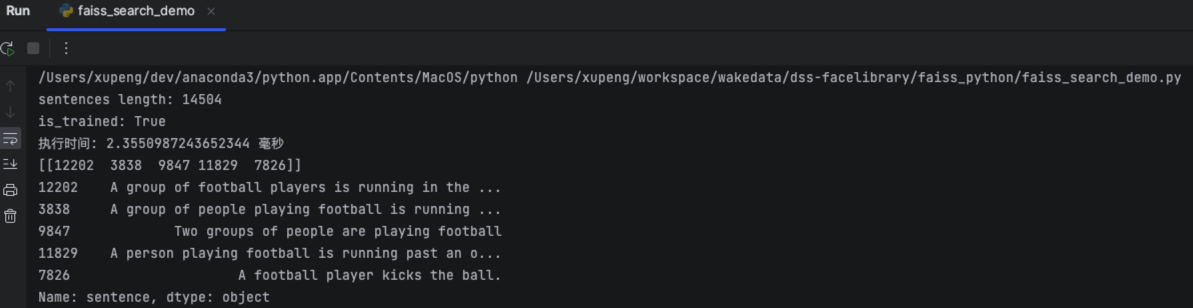
从运行结果中可以看到,搜索结果匹配的Top5基本上都是跟football相关的句子。
好了,到这里你基本了解了Faiss是什么,如何使用Faiss,但是Faiss的功能远不止这么强大。
Faiss提供了非常丰富的索引和相似度度量方法。上一讲我们讲到了FLAT类型的向量索引,其实采用的是暴力的搜索方式,所以可能存在性能问题,只在小数据集的场景下适用。
比如我们的demo中,在14504个向量中搜索最匹配的5个,在我的Apple M2 Max+32G的Mac上面耗时稳定在2.4毫秒左右。
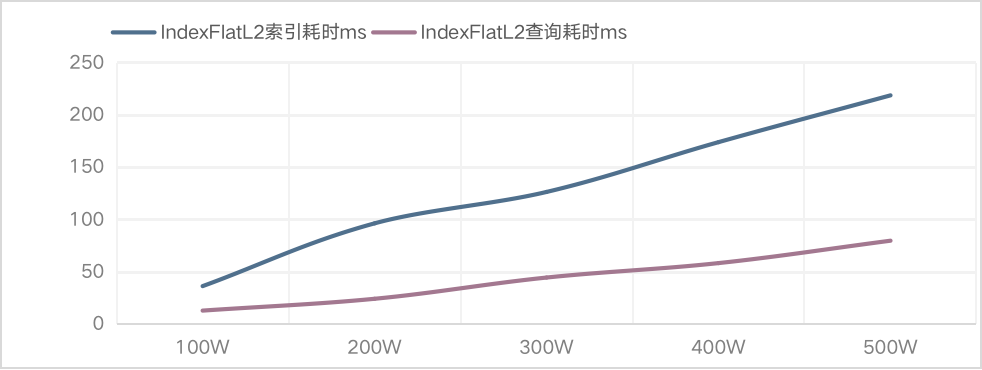
在这个数据体量下,即使我们使用FLAT类型索引,Faiss的性能还是很好的,但是可能随着数据量的增加,FLAT索引的响应时间基本上就是一个线性增长了。
下面这个图就是我在使用IndexFlatL2在100万-500万数据量的情况下统计的耗时。可以看到,结果跟预期一样,索引时间跟搜索时间基本都是一个线性增长。
当然,Faiss也提供了性能高的索引方式,毕竟Faiss强大之处就是提供了各种类型的索引方式以及相似度的度量方法。
比如,如果需要使用我们前面提到的HNSW方式来构建与检索,只需要修改构建索引的一行代码。
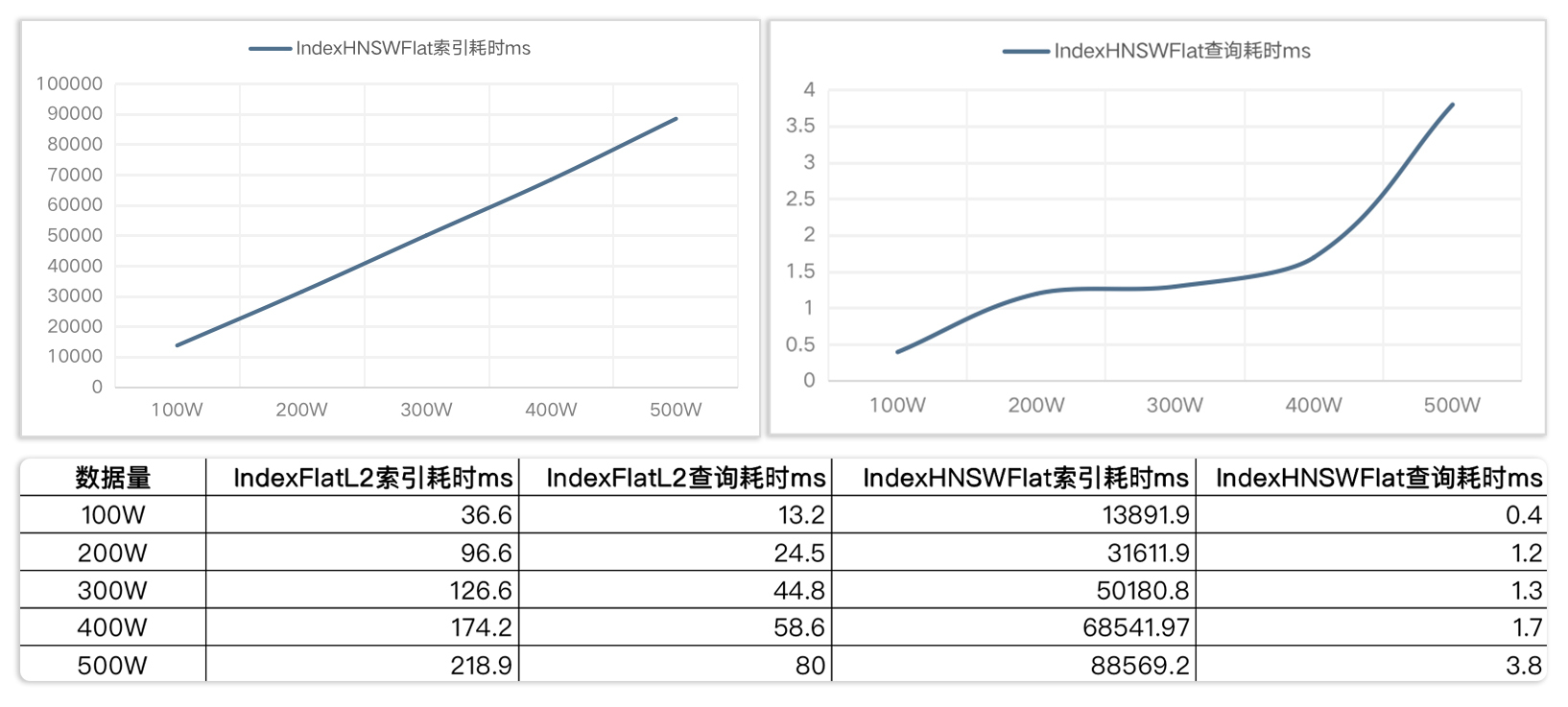
注意,这里多了一个M参数。M控制了HNSW图中各个层级中每个节点可以保持的最大邻居数。M值越大,索引构建时间与检索时间越长,但是结果越精确。反过来,M值越小则索引构建时间与检索时间越短,但是结果越模糊。
在实际测试过程中,比如M从16调整到32,构建索引时间可能翻3倍以上。当然这个跟代码运行的机器配置也是相关的。
同样我也基于这段测试代码,验证了一下HNSW的性能,你可以参考下面的图表来做个对比。
到这里你应该已经了解Faiss如何使用不同的索引,其实向量的索引可以由索引的方式与相似度度量的方式组合来决定。
为了方便你理解Faiss支持的各种索引方式,我整理了一下Faiss支持的索引与其适用场景,你可以参考下面这个表。
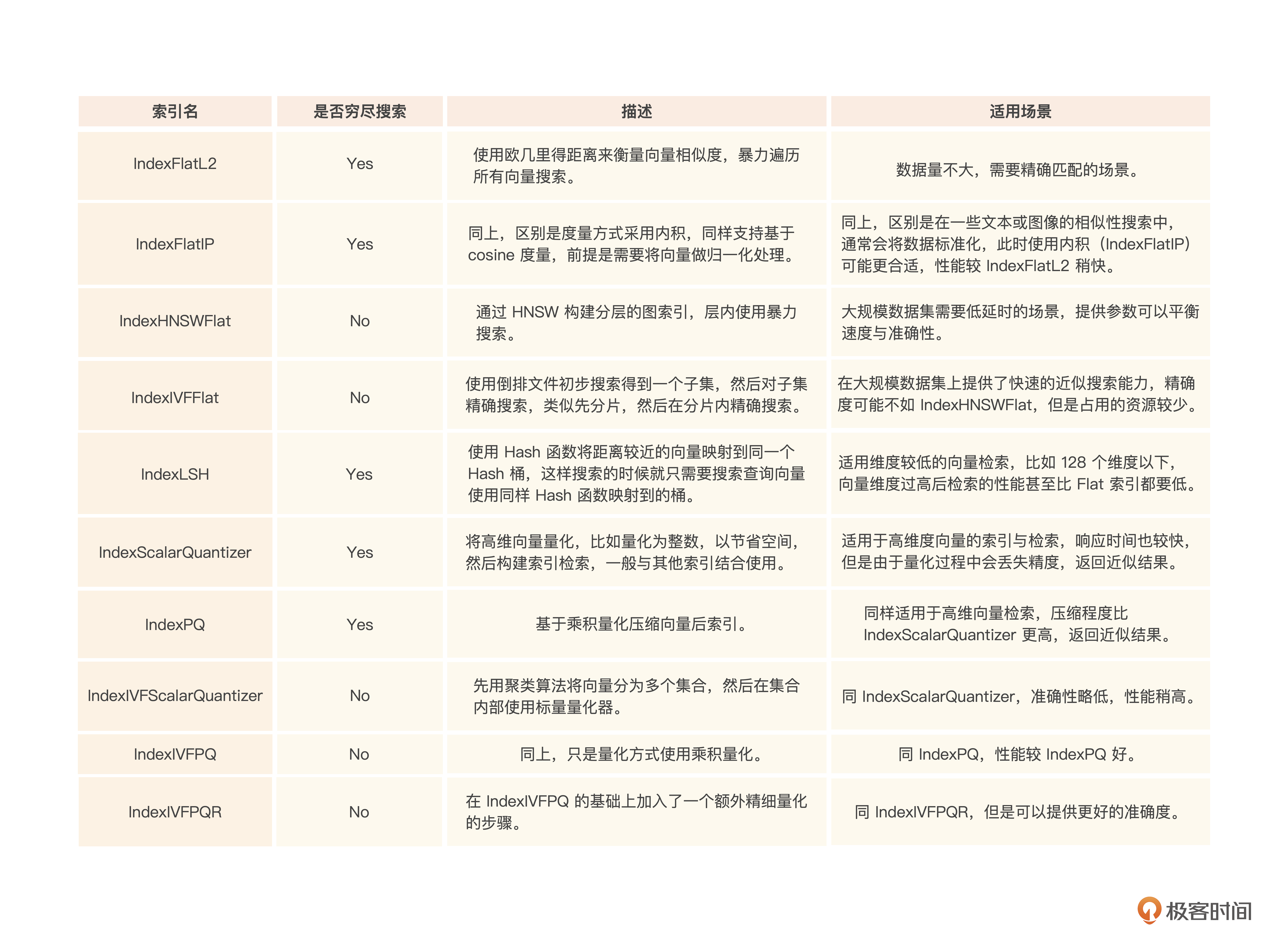
看完后,你应该可以根据业务的准确度要求、性能要求、资源占用情况来选择合适的索引。
小结
Faiss虽然不能被称之为一个向量数据库,但是它还是提供了完整的向量索引与检索能力,只是需要在检索之前,将数据集添加到索引。
Faiss索引默认基于内存存储,但是也可以调用接口将内存中建好的索引保存到磁盘,以便下次服务启动的时候重新加载,以节省初始化时间。
向量引擎或者向量数据库通常不直接提供向量化的能力,所以我们通常需要找一个向量化模型来先将数据向量化。
在Faiss中,最常用的索引方式其实还是Flat类型的索引,因为基于内存构建的索引,我们通常也不会加入超过百万的数据。如果数据过多,其实也可以将数据分片,然后不同分片由不同的Faiss进程服务来提供。
通过组合不同的索引方式与相似度度量方式,Faiss提供了很多种索引的支持,我们可以根据不同的业务场景来选择不同的索引。比如在人脸识别场景,准确度要求高,那么Flat类型就比较适用。比如视频搜索场景,性能要求较高,就可以采用HNSW类型索引。甚至可以组合不同的索引方式。
好了,到这里相信你已经对Faiss有了一定的了解,包括如何使用Faiss,什么场景下用什么样的索引与度量方式来平衡性能与搜索结果的准确性。下一讲,我们就进入Faiss的一个实战,用Faiss构建一个人脸识别应用。
思考题
当Faiss需要索引的数据过多时,需要考虑数据分片,在门店客流人脸识别场景下,你觉得应该如何做数据分片?
欢迎你在留言区和我交流。如果觉得有所收获,也可以把课程分享给更多的朋友一起学习。欢迎你加入我们的读者交流群,我们下节课见!
- eriklee 👍(0) 💬(1)
请问老师,faiss与其他向量数据库检索相比有什么优势呢?是检索速度更快,还是有其他优点呢?
2024-08-11