21 向量数据库:图片、音频、文本等非结构化数据的搜索需求是怎么实现的?
你好,我是彭旭。
前两天看到一张漫画,一个大人工智能机器人带着小人工智能机器人在博物馆里指着一个人类的大脑标本说:“瞧,这就是第一代的处理器”。 这个图表达的是人工智能在无监管的发展下可能会给人类带来灾难的后果,但是解读成“人脑是第一代处理器”的比喻,似乎也是有迹可循的。

2022年12月OpenAI推出了一发布即爆火的基于GPT-3.5模型的ChatGPT,开启了人工智能的“iPhone时刻”。其中的GPT模型就是起源于模拟人脑的深度神经网络。
我们将感知到的信息如图片、声音、文字等通过神经元与突触的相互连接并传递信号,最终在脑海里形成一个抽象,也就是信息的处理结果,比如将看到白羽毛、长颈、黄色的喙、在水中游的这些特征在一层层的识别叠加后,就会得出这是一个天鹅的结果。
深度神经网络模仿人脑的结构与信息处理方式,通过多层的“人工神经元”对数据进行加工和抽象。比如深度神经网络识别一个动物,第一层可能识别羽毛,第二层可能识别形状,层层叠加,直到最高层能够根据识别特征做出决策。
人类神经元中传递的信息主要是以电信号和化学信号,而在深度神经网络中,传输的信息就是向量。不管初始数据是图片、音视频、文本还是其他,在深度神经网络中,都被抽象为向量,万物皆可向量化。
为了存储这些向量数据、提供快速的向量检索能力,向量数据库应运而生。关于“向量数据库”这个概念,我们先从从什么是向量开始说起。
向量是什么?
我们知道在数学和物理学中,一个向量通常定义为具有大小(magnitude)和方向(direction)的量。而在机器学习中,向量可以类比为一个多维空间中的点,数据转化为向量后,会在这个多维空间中映射到一个坐标点,具备越多相同特征的数据映射到的坐标点之间的距离就越小,靠得越近。
以一个用来描述名词关联度的简化版二维空间为例。“猩猩”“猴子”这两个词转化为向量后,在这个二维空间内距离较近,同样,“西瓜”跟“哈密瓜”距离较近。反过来“猩猩”跟“哈密瓜”就可能相距相对远一些。
多维空间就像一个大型的呈列货架,向量就是指定货物在这个柜子的摆放位置处于哪一层哪一列等等,具备类似特征的数据就会靠近摆放。
数据的向量化(Embedding)通常指的是将数据转换为一个数值型的数组,比如浮点型数组。
这里我使用OpenAI的text-embedding-ada-002向量化模型将一段产品介绍转化成的一个向量。
如下所示,表现形式为一个长度为1536浮点数的数组,代表着1536个维度。
[-0.009154034778475761,-0.024624012410640717,
.....中间省略.....,
-0.015027590095996857,0.017436904832720757,-0.022609444335103035,
0.008555108681321144]
注意,不管数据量的大小,比如一段文本,不管文本的长度是否一样,最终通过向量模型在相同特征维度下把数据向量化后生成的向量长度都是固定的。
当然,不同的向量化模型对输入的文本长度会有不同的限制。比如OpenAI的向量化模型text-embedding-3-small就限制输入为8191个token。在生成向量的过程中,模型会聚焦文本中的重要片段,在向量表示中给这部分更高的权重,最终影响到数据映射到的高维空间位置。
比如一段主要描述电池技术的文本,顺便提到了在特斯拉的应用。那么这段文本向量化后,在向量的多维空间坐标中,与“电池”向量的距离就会比和“特斯拉”向量的距离会更近。
向量的存储、检索需求
刚才我们说“万物皆可向量”,在人工智能领域,就是把文本、图片、音频、视频等全部作为向量来处理、分类、识别。
这些向量必然就需要一个引擎来存储,并且支持某种数据转化为向量后的对比查询。
在传统的关系型数据库和搜索引擎中,如果我们要搜索一个关键字,关系型数据库会支持直接关键字内容对列值的匹配。搜索引擎通常会先把被搜索的文本数据分词倒排,然后同样匹配关键字后返回匹配的内容。
前面提到,具备相同特征的数据转化为向量后在多维空间中映射的点靠的就越近,也就是具备相同特征或者类似的数据在多维空间聚集在一起。所以,在向量的搜索查询中,一般是将数据向量化后,找到这个向量在多维空间的映射里面,相邻的或者距离较近的点。
假设在传统搜索引擎中被搜索文本是“故宫坐落在北京,是历代皇帝的住所”。如果搜索关键字是“北京旅游景点”,那么这段被搜索的文本数据就可能无法被搜索到。
但是在向量表示中,故宫会有一部分旅游景点的特征,所以这段文字转化成的向量就有可能与“北京旅游景点”这个搜索关键字转换成的向量在高维空间距离较近。这样,这段文本就有可能能够被搜索出来并返回。
总结一下,向量数据库的出现就是为了解决向量数据的存储、相邻向量的搜索问题。向量数据库一般会将数据与向量一起存储,同时支持基于数据字段的标量过滤查询,也支持基于向量字段的近似相邻查询。向量数据库提供的向量检索的能力,解决了传统关系型数据库只能进行文本关键字检索的问题,让关联文本之间检索、相似图片之间检索等非结构化数据也能够实现存储与快速检索,让机器学习和人工智能能够更快更准确地找到我们需要的东西。
举个例子,假定有个向量数据库存储了所有的新闻,数据集大致包含下面这些字段。
当然,实际存储中,一般会对新闻内容做切分分段存储。如果需要查询7天内关于比特币的新闻,向量数据库可以使用publish_dt标量先做精准过滤,然后再使用vector做相似性查询。下面使用Milvus向量数据库的python SDK实现了一个标量与向量的混合查询,简化的代码片段如下所示。
embeddings = OpenAIEmbeddings(
openai_api_key="xxx",
)
vector_db = Milvus(
embeddings,
collection_name,
connection_args={"host": "172.31.13.171", "port": "31115"}
)
query = "比特币新闻"
docs = vector_db.similarity_search(query, expr=' publish_dt > "2024-03-03" ')
输出结果类似下图,可以看到输出结果里面包含了2个Document对象,可以类比为关系型数据库的2行结果。

向量数据库的索引
不过,检索、输出只是基本要求,我们肯定还希望速度越快越好。我们知道,索引能够大大提升数据的检索效率。为了提高向量的检索速度,向量数据库同样提供了许多类型的向量索引方式。
接下来,我们就一起来看一下向量数据库的索引。
关系型数据库常用B+树作为索引数据结构,核心逻辑就是根据索引字段按文本的顺序或者大小构建一棵多路平衡查找树。每次查询就是比较查询文本或者数值跟树的节点大小,然后可以得出需要查询的数据是在对比节点的哪个子节点,树的高度就是每次查询需要对比的次数。
文本、数值等可以比较大小,而向量一般关注其长度或者向量之间的角度。所以在比较向量时,通常会使用向量之间的距离或相似度度量(如欧氏距离、余弦相似度)来比较它们的“接近程度”而不是大小,也就是多维向量在多维空间坐标的映射中越靠近,向量就越相似。
所以向量数据库一般用ANN(Approximate Nearest Neighbor,近似最近邻)类算法来在多维空间中快速寻找与给定点最近的点。ANN类算法的关键思想是接受一定程度的不精确性以换取速度。不过,很多向量数据库都会提供一定的配置参数让我们可以动的调整这个配置参数来平衡返回数据的准确性与速度。
这个地址列出了多种ANN算法的beachmarks对比,你可以参考一下各种算法实现的性能与支持的并发度等。
这里我主要介绍一下ANN算法在向量数据库中的一个常用实现,HNSW(Hierarchical Navigable Small World,分层导航小世界图)。常用的向量数据库Weaviate、Milvus都以这个算法作为默认的或者主要的向量索引实现。
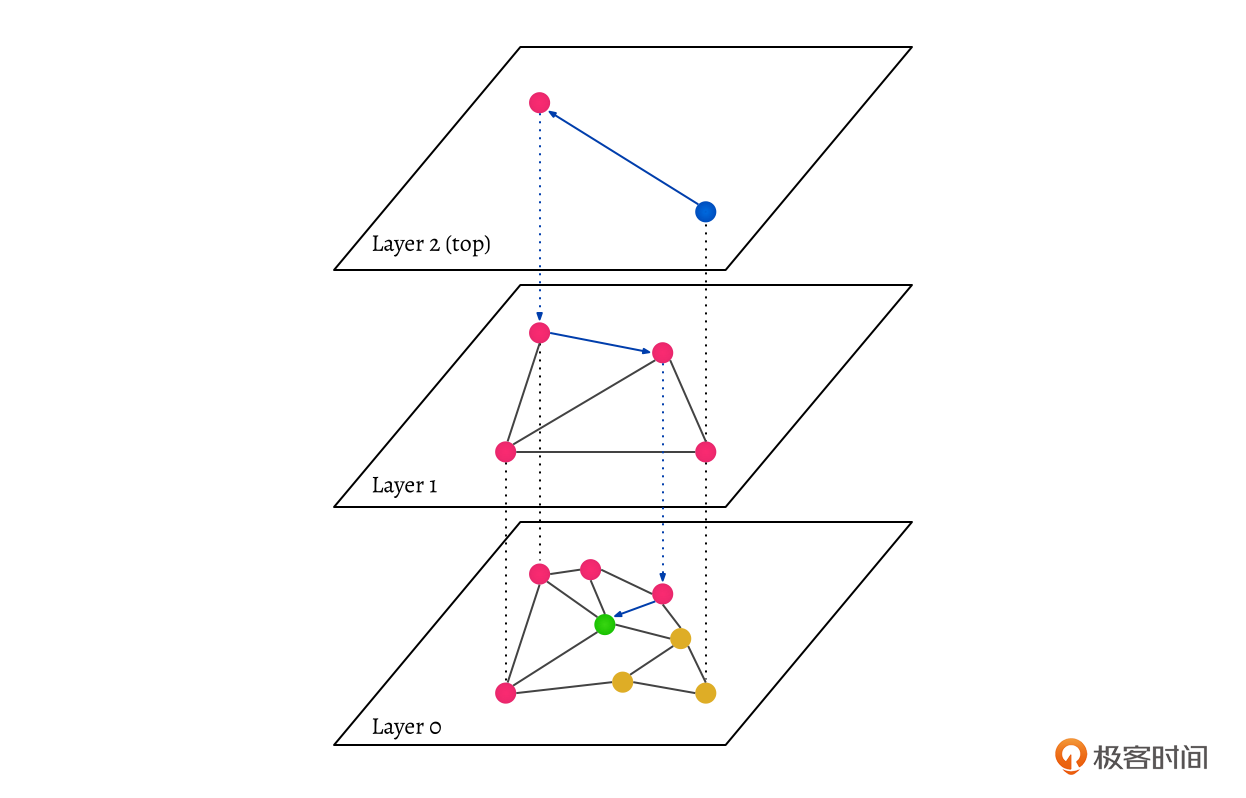
你可以通过上面的图片来理解。你看,HNSW是一种图数据结构,这个图有很多层,顶层的节点比较少,节点间距离也比较大。随着层级下降,节点数量会越来越多,但节点之间的距离会变小,最底层包含了所有数据映射的点,每层数据都会和其他数据有一个连接,并且连接能够算出点之间的距离。
搜索的时候会从顶层开始,在每层里,算法会选择与当前点最近的节点,然后移动到这个节点。当无法进一步接近时,搜索就下降一层,直到达到最底层。图中搜索蓝色节点数据的搜索路径就如蓝色的虚线所示,最终在Layer0层找到了蓝色节点在Layer0层的近似最近邻,也就是绿色的节点。
说到这里不知道你有没有发现,其实HNSW跟跳表、B+树很像。
比如Layer0以上的分层,是不是类似跳表的“高速公路”指针或者B+树的非叶子节点层?所以,其实HNSW的性能也能达到跟B+树类似的量级。
我们知道,在关系型数据库中,B+树在千万级数据量下能够实现毫秒的响应,同样,HNSW在百万级数据量下也能够实现毫秒级的响应。它的性能、健壮性、平衡性让它成为了在推荐系统、图像检索和机器学习中首选的近似最近邻搜索解决方案之一。
但还有一个问题,就是使用HNSW有可能导致搜索结果不是最精确的,因为它跳过了一部分数据的搜索。比如图中橘色的点距离搜索的蓝色点更近,右下角那个橘色点其实就是蓝色点本身的在Layer0层的呈现。按理来说,右下角的橘色点是最精确的结果,但是搜索结果却可能不包含在内。
如果需要完全精确搜索该怎么办呢?这个时候就需要FLAT(Full Linear Scan,全量遍历)来为查询向量对比数据集中的每个向量,但是这种方法非常低效,适应于小数据集的场景。
向量数据库将向量索引后,提供快速的近似搜索能力,被广泛的应用于人工智能等场景。比如人脸识别技术,将人脸照片向量化后存储,然后提供相似照片检索匹配的能力;比如抖音的视频推荐,就是将视频特征向量化存储,然后将用户的喜好特征向量化后作为查询向量,用来实现千人千面的智能推荐等。
小结
这节课,我们从深度神经网络模拟人脑的方式出发,引出了“向量数据库”的概念。
其中,向量作为在深度神经网络中数据的表现形式,代表了数据在深度神经网络多维空间坐标中一个映射的位置点。多维空间的每一个维度通常代表着数据的一个特征,比如地域、颜色、形状等,所以,具备相同特征的数据在多维空间坐标中距离就越近。
向量化就是把数据转化为一个多维向量的过程。当然,这个过程会比较复杂,有很多机器学习模型和算法可以对数据进行向量化转化,比如词袋模型、BERT Embeddings等。万物皆可向量化。当然,不同类型的数据如文本、图片、视频等向量化的模型算法都不尽相同,而且向量化出来的结果也不能直接用来做对比。
向量数据库就是为了存储、索引、搜索向量而生。向量数据库通过ANN近似最近邻算法,为向量搜索提供了快速的检索能力。常用的ANN算法HNSW通过构建一个类似跳表的分层检索模型,快速地跳跃到搜索空间的不同区域。随着层级的降低,每个层级包含的节点数量增加,连接范围变得更局部。HNSW使得在高层可以实现快速导航,而在低层则可以进行精细的局部搜索,当然这也会带来结果没那么精准的影响。
如果需要搜索结果绝对精确,则可以使用FLAT向量索引,来全量遍历数据集,但是只适应于小数据集场景。
思考题
向量数据库由于OpenAI的大火而爆发,你们公司有使用过向量数据库吗?你是如何选择合适的向量数据库产品的?
欢迎你在留言区和我交流。如果觉得有所收获,也可以把课程分享给更多的朋友一起学习。欢迎你加入我们的读者交流群,我们下节课见!
- Geek_b0e84e 👍(0) 💬(0)
qdrant😭
2024-10-02