13 客户数据平台(CDP)的存储与计算需求
你好,我是彭旭。
从这一讲开始,我们就进入StarRocks相关内容。在这个章节,我会从一个客户数据平台CDP的需求出发,和你一起看看在StarRocks中,如何选用合适的表类型来设计CDP的数据模型,如何更好地分区分桶,在海量数据中生成SQL标签?
先来看一下什么是CDP(Customer Data Platform)。
什么是CDP?
在存量时代,企业开始更专注于服务现有用户,而不仅仅是吸引新用户。数字化转型成为了一个热门的企业发展方向。
举个例子,地产行业以前只在购房的时候和用户联系,现在则是从物业、商业、写字楼等多个渠道与用户建立联系,从“一生一次的生意”变成“一生一世的生意”。
为了实现存量用户的精细化运营,企业就需要全面收集客户信息,构建客户的完整画像。
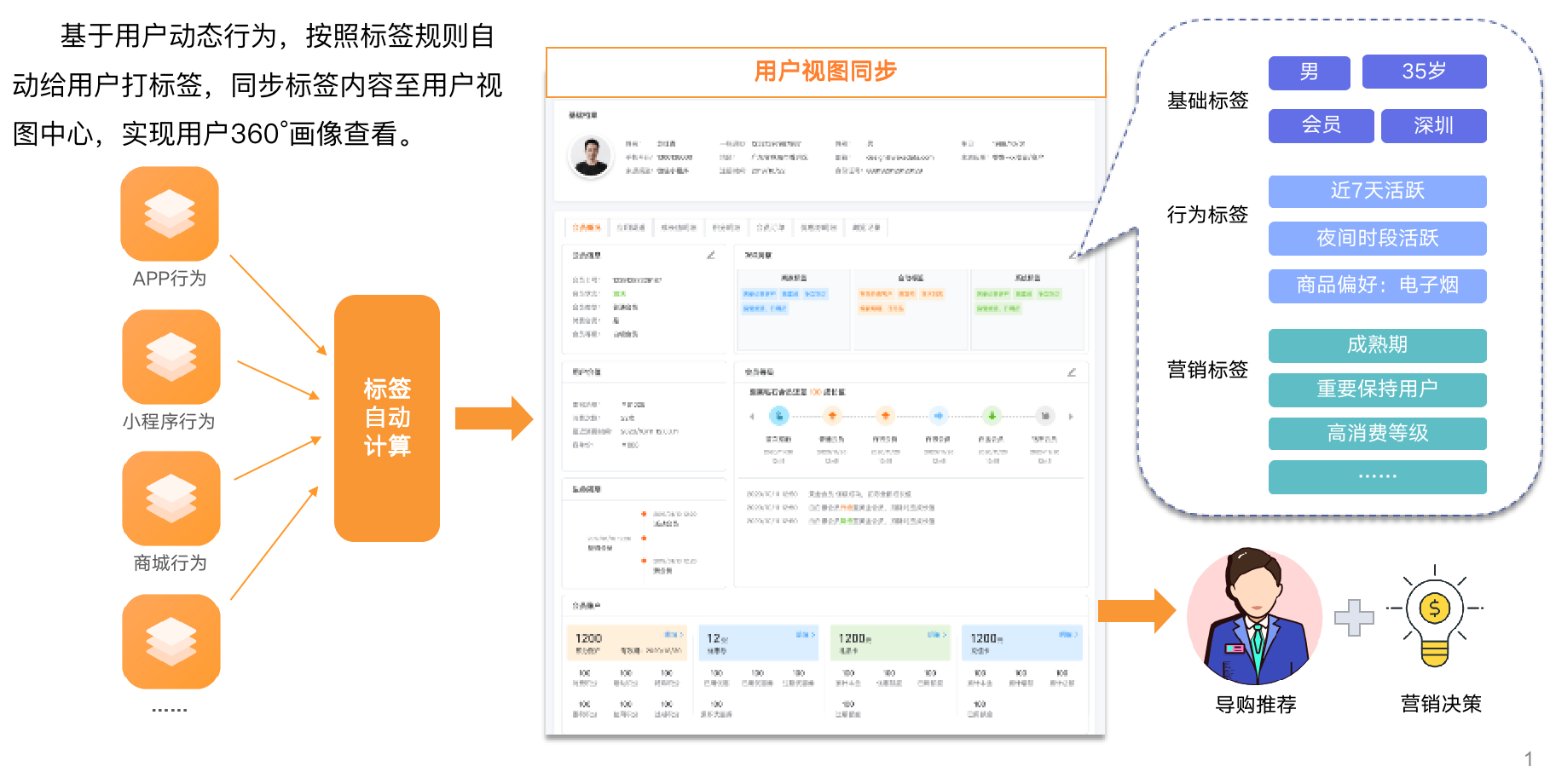
上面这个图描述了一个典型的CDP业务流程:企业收集用户的各种行为数据、业务数据,通过规则计算、机器算法、数据挖掘等方式处理数据,构建一个客户的360度标签、画像。
当然,标签、画像构建过程很复杂,比如需要构建用户全域的ONE-ID,也就是将各个渠道收集到的数据,再通过各个系统不同的关联键,比如手机号、微信unionId、设备ID、邮箱等,识别到这些数据是属于同一个人,通过一个ONE-ID把用户所有的标识符都统一起来。经过各种各样的操作,最终把用户对应的数据关联起来。这里提一下,构建ONE-ID的过程一般都会用到图数据库。
而且过程中还需要涉及数据清洗、离线计算、实时计算等复杂逻辑。
这些构建好的标签、画像就可以用在自动化推荐、人群分析、精准营销等场景,全面提升用户体验和转化率。
CDP用在什么场景
实际上,CDP的应用已经渗透到我们的日常生活中。
第一个典型场景就是个性化推荐,用淘宝的个性化推荐举个例子,你在淘宝上搜索了“智能手机”这四个字,并在搜索结果里面浏览了几个手机品牌。这时候其实你已经产生了一些行为数据,包括搜索行为数据、浏览行为数据等。接下来实时标签引擎就开始生效,可以开始为你构建一些临时或者长久的标签,并且这些标签也需要能够实时生效。比如你再次打开淘宝,就发现首页可能就推荐了一些同等配置、价位的手机了。
其实,这种标签的实时生效有时候非常重要,因为你可能搜索完手机,很快就购买了,如果等你已经购买完成了,还一直在推手机,其实没有意义了,你想一下,这时如果能够推手机配件是不是更好?
相比个性化推荐这种被动触发的,现在企业也更加注重主动的精细化营销。
所以,CDP第二个典型场景就是结合企业的自动化营销系统,主动做精细化推送,比如圈选附近5公里的白领,发送一个商场的优惠券,为商场引流等。
最后,CDP数据也可以用来做一些客群的画像分析。通过这些画像分析可以更好地了解客户的爱好与需求,帮助企业更好地把握客户需求,做出产品方向决策或者制定不同的营销策略。
好,到这里你应该已经对CDP有一个大概的了解了。因为专栏主要聚焦在数据库存储层,所以主要还是来看如何用StarRocks来满足CDP的数据表存储需求。我们要研究的问题是,在CDP的使用的典型场景中,又是海量数据的情况下,性能能否得到保障?比如找出最近7天搜索了手机但是没有购买手机的用户,发一个手机优惠券。
先来看一下CDP的主要数据模型。
CDP数据模型
CDP号称全域的用户数据平台,首先第一个基础表就是用户属性表cdp_user,包括用户的基本资料,用户的一些属性指标等,像下面这个表。
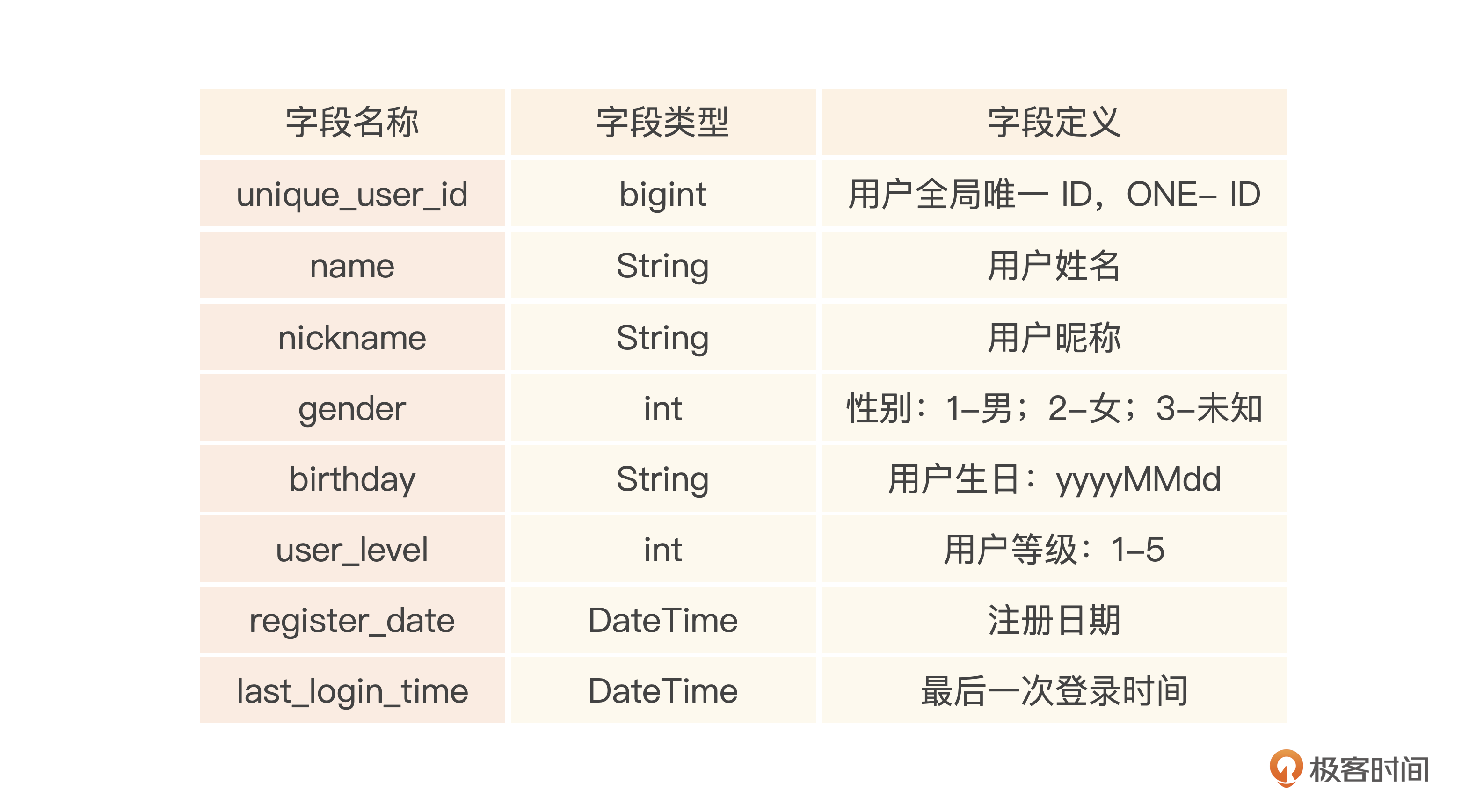
你可以认为这个表是经过了数据清洗后汇总的一个用户表。一般来说,这个汇总表的一条记录,还会对应到另外一个渠道表的来自多个系统的多条用户记录信息。这里我们暂不考虑。
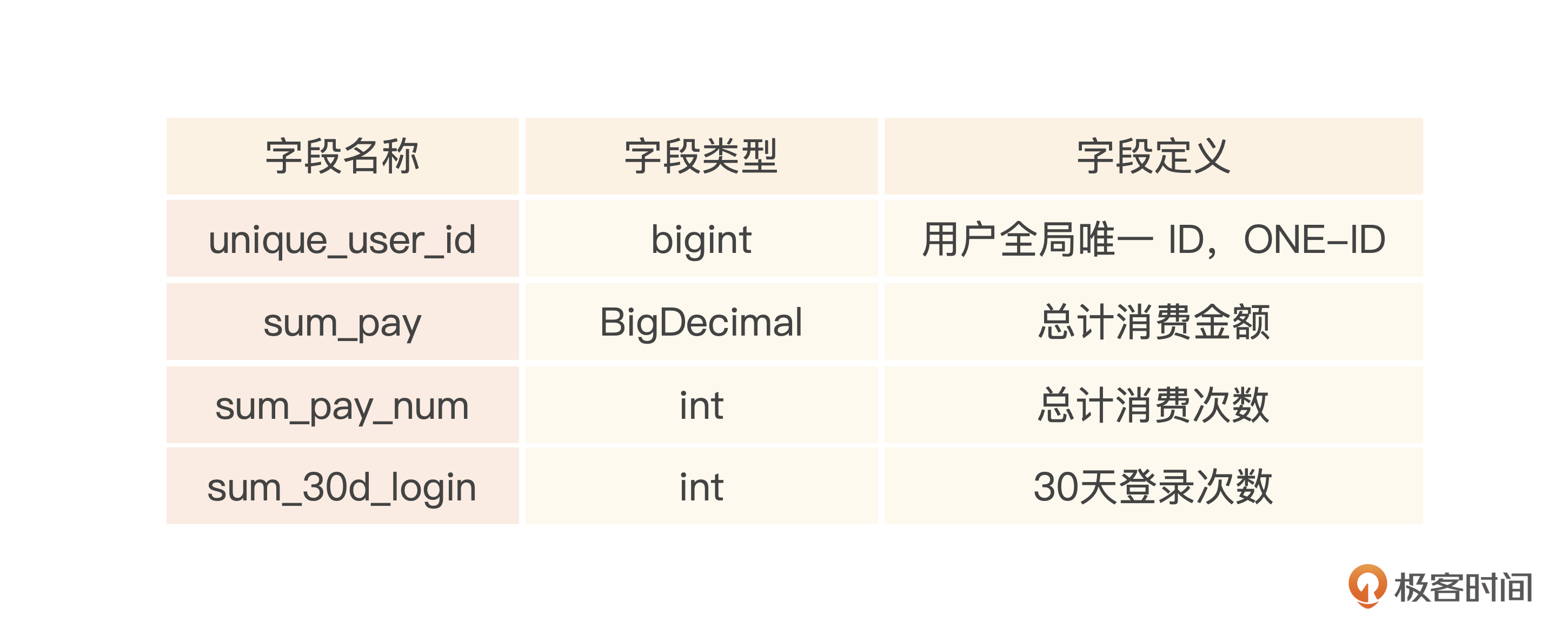
为了方便统计计算,同时也试试StarRocks在星型模型下的多表Join表现,我们额外创建一个用户的指标属性表cdp_user_metrics,简单定义字段如下。
接下来就是用来存储,从各个渠道收集用户行为数据的用户行为表cdp_user_event。这里我们将事件的一些参数打平,构建一个宽表。
看下简化版本的行为表。
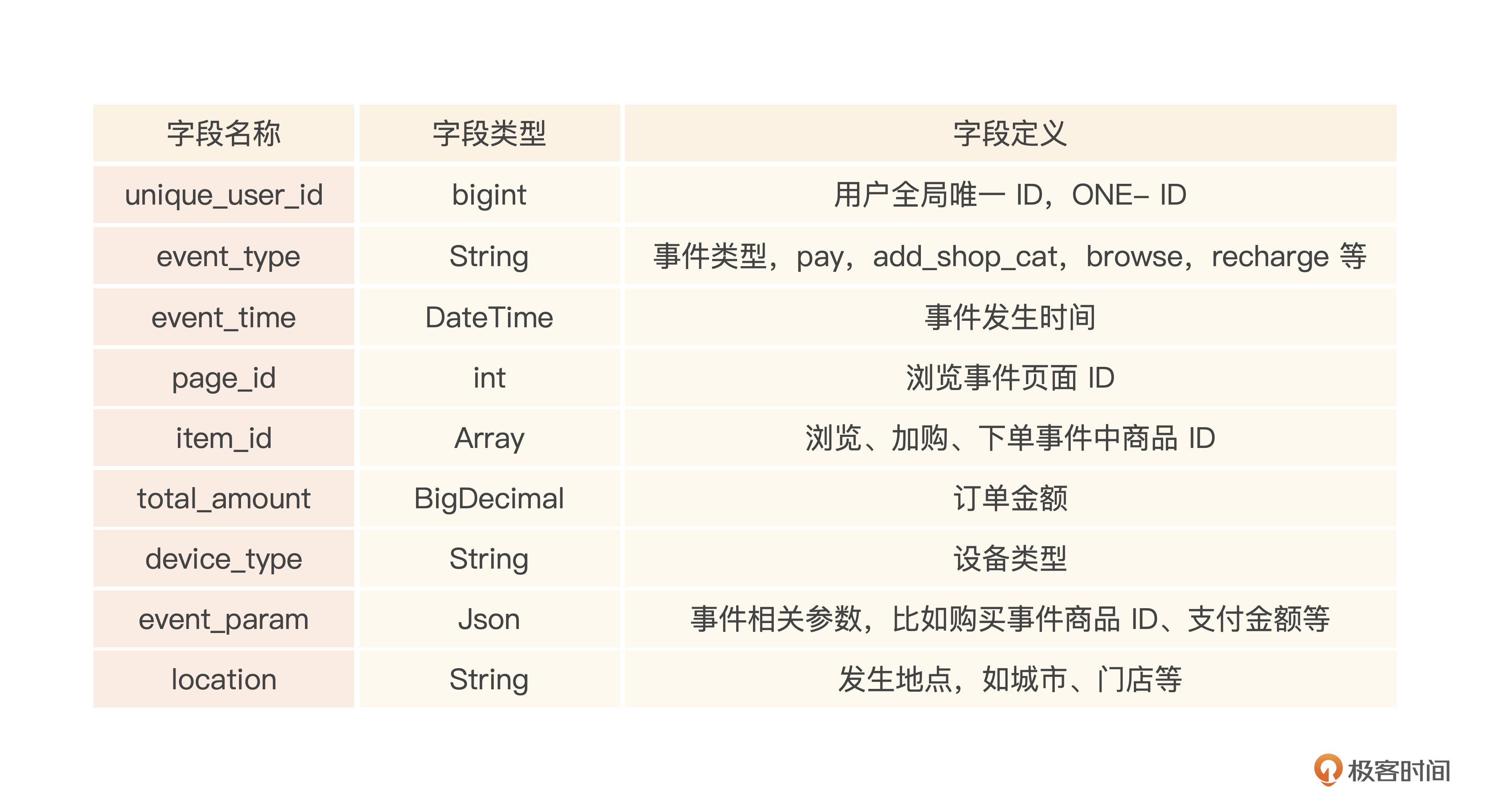
用户属性表与行为表其实是标签画像的数据来源,基于这些数据,我们可以根据规则,生成很多用户的标签,标签其实也可以使用多个层级、分类来管理。
比如第一层,可以分为用户基础属性标签、行为标签、内容标签等。
第二层,比如内容标签又可以分为兴趣标签、品牌标签等。
标签表有宽表、高表存储模式,也可以组合不同的数据结构用来存储,比如bitmap,这里我们先用高表的模式来定义一个标签表cdp_tag。
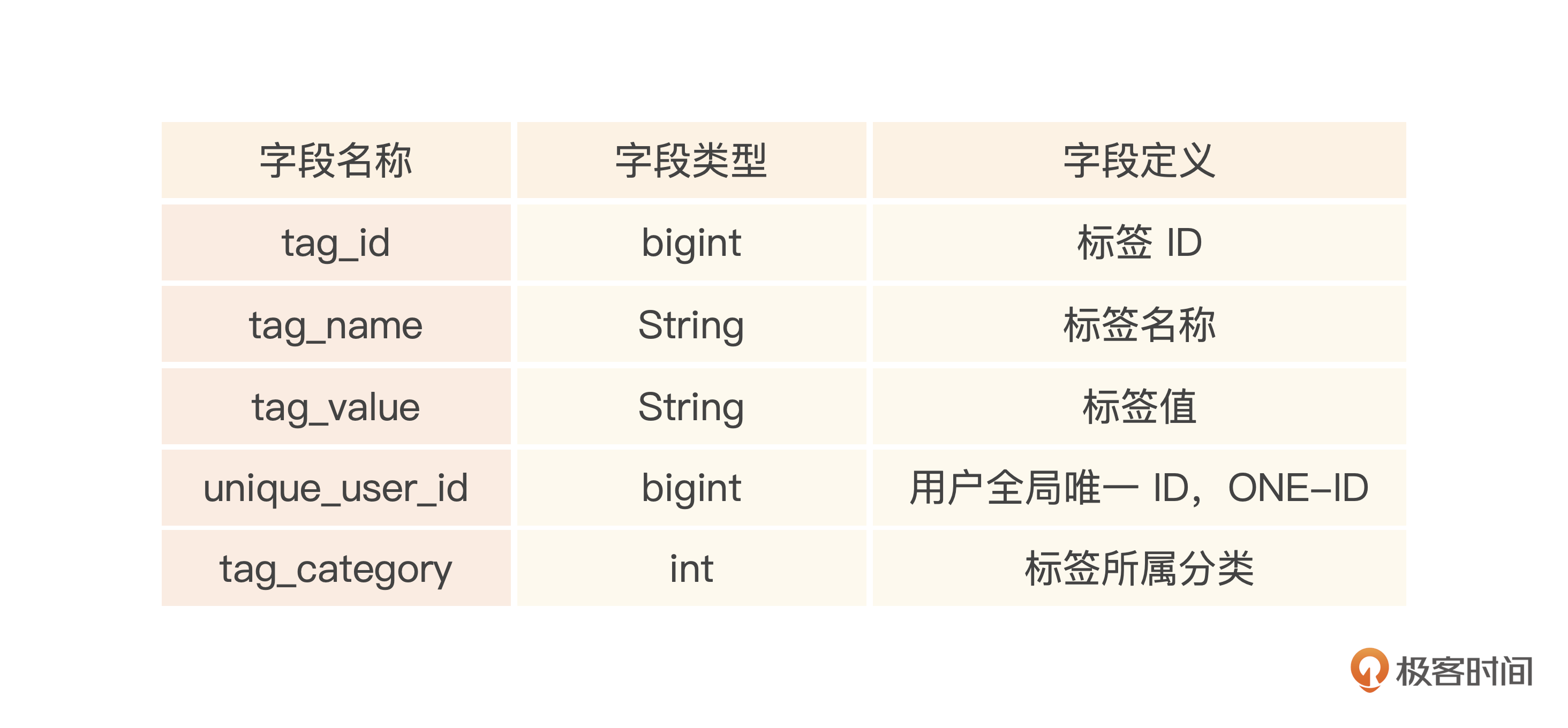
注意,同一个tag_id,可以有多个值,有可能这些值是互斥的,也就是一个用户只能有一个值,比如性别,只能选男、女或者未知。但是有些另外的标签,比如阅读偏好,一个用户就可能有多个值了,比如喜欢体育、小说等,所以这时候同一个tag_id、同一个unique_user_id可能在标签表存在多行记录。
这个章节,我们会以这3个基础表来做示例,看一下如何通过StarRocks的存储,来满足我们下面一些业务场景。
我们需要考虑的业务场景
第一个场景,也是最基础的场景,我们需要考虑标签如何生成,其实从对用户打标签的方式上来看,标签有多个类型。
比如统计类标签。这是最基础的标签类型、比如对某个用户来说,他的性别、年龄等基础信息、总计登录次数、总计消费金额等,都是基于用户的行为数据统计出来的。
还有规则类标签。比如需要定义一个用户消费层级标签,包括高消费、中消费、低消费等,这些标签会基于业务人员给出的一个规则来定义。举个例子,消费大于1万属于高消费、5000到1万属于中消费,低于5000属于低消费。这类标签通常也是通过用户的行为数据,基于给出的规则计算出来的,与统计类标签的区别是规则可以变化,标签也需要相应变化。
最后是挖掘类标签。它是基于机器学习、数据挖掘产生的,能够根据用户的数据或者行为进行预测,比如根据用户的购买历史和行为数据,挖掘客户的购买偏好,如偏好的产品类别、品牌、价格范围等。
我们这里就聚焦在用SQL来生成,统计类和规则类标签。
第二个场景,有了标签之后,标签如何使用,比如基于用户属性、标签、行为等,构建一个人群,再给这个人群推送一个优惠券,比如给浏览过高端手机、女性、中消费、高活跃的用户群体推送一个100元手机抵扣券。
当然还有很多其他场景,比如人群分析,基于圈定的人群,洞察这些人群的显著特征等。我们这里暂不考虑,聚焦在能够通过数据库层,使用SQL实现的场景。
小结
越来越多的企业选择搭建自有的CDP用来构建客户的完整画像,实现个性化推荐、精细化营销等业务场景。
过往的CDP数据的清洗、处理、存储等,都依赖Hadoop体系。比如基于HBase、Hive存储用户行为数据,通过ETL、Flink生产标签等。但是Hadoop集群相对中小企业来说成本有点高,一个小的集群使用云服务的话,通常每年的硬件成本会在10万以上,所以这些中小企业也在寻找一个更敏捷轻量的数仓方案。
在StarRocks、ClickHouse流行后,越来越多的企业已经在使用它们构建自己的数仓,作为CDP的数据存储方案。
这节课我们提出了CDP存储层两个主要的需求。
- 在海量行为数据下,能够基于运营规则,输出SQL,然后用SQL为客户生成标签画像。
- 在生成的海量标签下,通过营销诉求圈人,比如圈出高端手机、女性、中消费、高活跃的用户群体。
接下来的几节课,我们就来看一下StarRocks作为数仓,有什么优势,数据模型上又如何支持我们提到的几个表,以及是否能够支持上亿级行为数据的SQL标签生产。
思考题
我们这里事件表只考虑了用户的单一事件,如果需要考虑一些组合事件,比如用户7天内连续签到了,送一个优惠券,这个该如何处理?
欢迎你在留言区和我交流。如果觉得有所收获,也可以把课程分享给更多的朋友一起学习。欢迎你加入我们的读者交流群,我们下节课见!