11 实现:基于HBase的手机云服务数据存储设计
你好,我是彭旭。
前面几节课,我们探讨了HBase实现分区弹性伸缩,优化实时随机存取性能,以及实现高可用的方法。HBase的这些特性解决了手机云服务系统的运维需求、成本需求和高性能需求。为云服务采用HBase作为新的存储方案提供了理论上的支撑。
这节课我们再来看看,如果采用HBase作为新的存储引擎,系统架构设计是怎样的,过程中又可能遇到什么问题。
这节课会复习到前面讲解过的如何基于业务场景设计HBase行键,如何优化列限定符来减少存储空间。同时,我也会讲一个新的知识点,HBase如何实现跨集群数据的实时复制,完成单元化、集群数据汇总分析。
单元化与数据备份
你应该还记得我们讲云服务需求的时候有提到,多机房的目标本来是单元化,也就是每个机房能够独立提供服务,具备数据的完整性。但是因为MySQL使用SSD存储,导致了巨大的成本压力,最后每个机房只存储了一部分的数据,所有机房加起来才是一份完整的数据。这样其实没有做到真正的单元化,而且数据也没有多机房的容灾。
其实使用HBase作为新的存储引擎后,这几个问题很容易就解决了。
首先,HBase可以使用机械硬盘存储,使用编码与压缩,也能较大地压缩数据存储空间。这样整体的存储硬件成本至少能够减少50%。
其次,HBase提供了多种数据备份容灾的方式。比如使用replication可以在集群之间实时复制数据,可以使用快照、导入导出对集群数据做定期冷备容灾等。这样就实现了多机房多副本数据备份与容灾。
所以我们在每个机房都搭建了一个HBase集群,然后使用replication来在这些集群之间实时复制数据。这样每个机房都有一份完整的数据,真正做到了单元化。
换了存储引擎后,系统架构就像下面这张图 一样了。
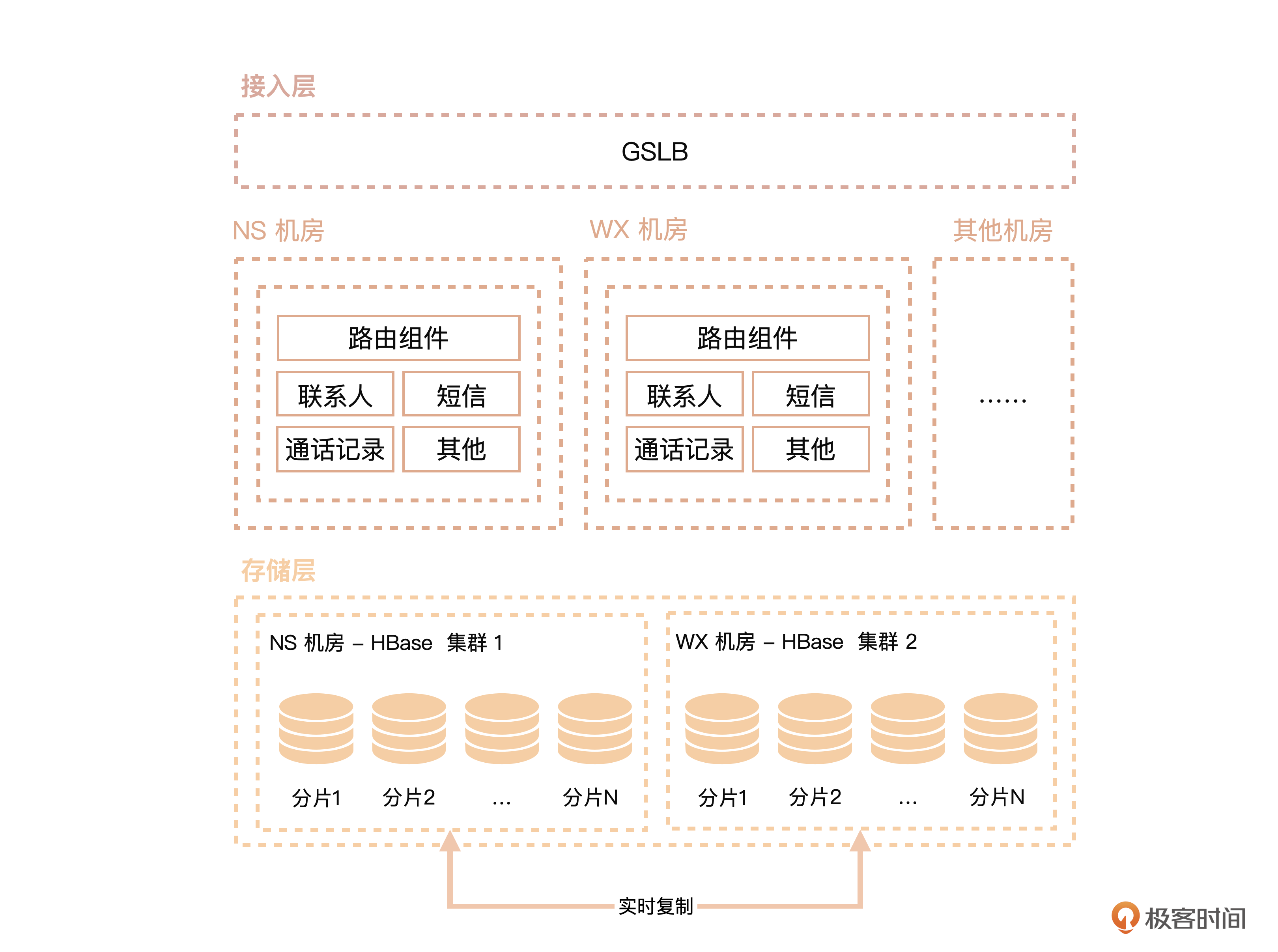
你可以看到整个系统的业务逻辑层基本没有变化,只是换了一个存储层。然后在存储层的不同机房集群之间配置了实时复制。注意,配置复制的时候,并不需要整个集群一起复制,你可以灵活地配置到表的列族级别复制。
数据是否会循环复制?
但是集群之间数据实时复制,又会遇到一些新的问题。
比如数据A写入NS集群后,发现有一个到WX集群的复制链接,那么A就会被复制到WX集群。当A写入到WX集群后,发现WX集群又有一个到NS集群的复制链接,结果A又被复制到了NS集群。
那么HBase如何解决这种循环复制的问题呢?
其实,集群间replication是采用数据源推的方式,如果某个表的列族配置了复制,当这个列族下分区的WAL(Write-Ahead-Log)有更新时,RegionServer会将这个WAL推送到配置了复制链接的目标集群。是不是跟关系型数据库的binlog同步很像?
当数据从源集群复制到目标集群的时候,WAL里面的数据会记录下源集群的唯一标识符clusterID,HBase会将所有已经消费过数据的集群clusterID记录下来,防止数据的循环复制(如A→B→C→A)。
这里提一下,数据复制的单元是WALEntry,由WALEdit和WALKey组成,WALEdit是变更的数据,WALKey用来记录已经复制过的集群标识符。
数据顺序能否保证?
跟消息中间件消息投递的可靠性保障一样,HBase为复制提供了至少投递一次的语义。这样可以保证所有的目标集群都能收到需要复制的数据。
这样又带来了一个新的问题,数据的有序性就可能无法保证了。
比如分区X原来由RegionServer A负责,在RegionServer A异常下线之后,分区X转移到RegionServer B,如果RegionServer A上数据M未复制完成,保存在一个数据队列,这个数据队列,也正好转移到RegionServer B负责复制。那这个时候,分区X上新增的数据N可能已经通过RegionServer B复制完成,但是比N更旧的数据M还没复制好。
也就是说,当目标集群的某个RegionServer异常后,因为复制过程是异步的,新复制的数据可能会与尚未复制的数据发生顺序上的交错,导致数据更新的顺序无法保证,因此复制的时候无法保证数据更新的顺序不变。
所以,某些非幂等(f(x) = x)的操作(如Increments)复制到从集群后,目标集群数据可能与源集群不一致,设计应用程序的时候需要特别注意这个特性。
不过HBase2.1以后,HBase提供了一个串行化复制的能力,串行化复制能够将日志按照到达源集群的顺序推送到目标集群,从而保障数据的有序性。
好,单元化部署、高可用与数据的备份问题解决了,对存储层来说,剩下的就是数据模型怎么设计的问题了。
表与行键的设计
其实云服务涉及的一些业务,像通话记录、联系人、短信等业务上不会相互关联,数据模型扁平化,所以基本都可以用一张宽表存储。实际上在MySQL中就是这样,到了HBase中,有什么变化呢?
表字段与存储优化
首先,HBase是动态schema,表的字段可以根据行的需求动态添加,所以建表时只需要声明表名字,以及配置一些优化表存储的属性,如使用压缩、预先分区等。像下面这个联系人表s_contact,启用了布隆过滤器,使用Snappy压缩,开启复制,又将表分成了10个分区。
create 's_contact', {NAME=>'cf',BLOOMFILTER=>'ROW',
REPLICATION_SCOPE=>'1',COMPRESSION=>'SNAPPY'},
{SPLITS=>['1','2','3','4','5','6','7','8','9']}
不过最终实际线上环境中,表的分区远远不止10个,在一个几十个节点的集群中,最终像短信、
通话记录这些表,分区数都在一百以上。而且在系统运行过程中,我们一直在根据分区的数据量大小进行手动拆表。
其次,由于每行数据的列都可以不同,而HBase又使用了一个KeyValue的键值对存储列与值,所以,每行数据都会把列限定符(也就是列名)存储一次。如果列限定符较长,占用空间就大。因此,我们也做了一个列限定符的精简映射。比如通话记录表,将电话号码、通话时长等字段,全部用最少得字符来表示。这样就可以尽可能的节省存储空间。
public class CallD {
private long u; //userId
private String p = ""; //电话号码 number
private long d; //日期 date
private int a; //通话时长 duration
private int t; //通话类型(来电:1;去电:2;Missed:3;voiceMail:4;录音:5;录音失败:6) type
....
}
最后再来看看表的行键如何设计。
行键设计
你应该已经知道了,从技术上讲,表分区与行键的设计需要做到让数据均衡分布,同时将查询条件尽可能融到行键里面,提升数据读取效率。而从业务场景上,需要支持云服务数据的全量同步与增量同步。
我们云服务的数据都是用户隔离的,每个用户肯定只能看到自己的数据。所以,为了避免信息泄露或者越权访问,甚至连客户端也做了用户数据的对比。假设同步请求访问到了不该访问的数据,最终也会被客户端过滤掉。当然这个只是最后一层安全保障,实际上并不会发生。
具体来说,业务上每个同步请求,用户ID都是一个必填项,所以行键开头就使用用户ID。同时,为了避免热点区间,还要对用户ID做反转补齐。
行键的第二个组成部分有两个选项,第一个是选用数据的更新时间,第二个是选用数据的唯一标识UUID。
到底如何组合呢?从业务场景出发来分析一下。
全量同步的时候,需要拉取用户所有的数据,这里会以用户ID作为前缀,区间扫描,所以使用两个方案都没影响。
至于增量同步,需要从两个维度来看。
- 从服务端拉取某个时间点后更新的数据到客户端。
这时候,如果行键是用户ID+数据更新时间,就可以更进一步缩小需要扫描数据的范围。如果行键是用户ID+UUID,则需要扫描用户所有数据,然后在Scan中增加时间作为过滤条件。
- 从客户端更新一行或者多行数据到服务端。
这个时候就需要根据更新数据的UUID,从服务端找到对应的数据进行更新。
这种情况如果行键是用户ID+UUID,那是不是直接做一个数据写入就行了?也不需要去查询数据是否存在。如果行键是用户ID+数据更新时间,那么就需要从用户所有数据中,找到更新的这条记录,然后用找到记录的行键删除旧数据,再构造新行键写入新数据。
最后综合来看,行键选用用户ID+UUID读写成本会更低,而且排查问题的时候,更容易找到数据。所以我们最后选择了用户ID+数据UUID作为行键的方案。
确定了系统架构、表设计与行键设计,就可以开始数据迁移了。
迁移保障
虽然有一些数据迁移工具,如Sqoop,可以将MySQL数据迁移到HBase,但是为了能够实时保证数据的一致,同时也方便两边数据的实时对比,所以最后我们还是自己写了程序来做数据的迁移。同时也通过程序对比两边的数据数量与抽样校验。
业务请求上我们也是按业务类型(比如通话记录与联系人)、按流量比例分批迁移。通过制定一系列的迁移策略,以配置开关来实时调整,切换哪个业务、多少百分比用户流量到HBase集群读写。这样来最终保障系统的稳定。
在读写策略上,整个迁移过程分为了3个阶段,保证出问题了能够随时回滚。
第1阶段:双写MySQL与HBase,读MySQL。
第2阶段:双写MySQL与HBase,读HBase。
第3阶段:等到验证服务与数据都没问题后,改成单读写HBase。
通过将数据、流量分批逐步迁移到HBase,这个过程也是对HBase一个调优与压力测试的过程。最终准确地评估出HBase集群的节点与存储规模。
小结
好了,我们总结一下。HBase的复制能力真正实现了多机房的单元化,而且每个机房都存储了一份完整的数据,可以用来做灾备。当然MySQL也可以做跨机房的主主复制,但是成本上相对更高。
由于HBase不支持Join,所以对于需要星型或者雪花型数据模型架构的场景支持不好,建议就是一个业务场景能用一张或者少数张的表搞定。
基于HBase存储的模型设计主要是在表如何分区、行键如何设计上。在避免热点区间的同时,将查询条件尽可能的融到行键上。
你应该还记得前面提到HBase只支持单行事务,所以从MySQL迁移到HBase的时候,也要注意到程序中用到的事务。要么将关联数据一行写入,要么用程序来实现最终一致性的保障。
虽然一切看起来都设计妥当了,逻辑也比较简单。但是实际上迁移过程中还是出现了很多问题。
比如HBase集群的自动Split与Compact导致系统响应慢。比如因为数据写多读少,磁盘出现瓶颈,磁盘IO使用率过高等。
下一节课,我们就来看看如何针对这些问题进行调优。
思考题
行键设计的时候最终选用了用户ID+UUID的方案,你觉得能否使用三个字段组合的方式?或者你还有没有其他优化的方案?
欢迎你在留言区和我交流。如果觉得有所收获,也可以把课程分享给更多的朋友一起学习。欢迎你加入我们的读者交流群,我们下节课见!
- 柯察金 👍(0) 💬(0)
选择行键的时候没有懂,为啥用 uuid 的时候直接插入就可以,而用时间的要先删除后插入?
2024-12-25