10 不支持二级索引,如何自己实现一个?
你好,我是彭旭。
上节课我们讲了HBase实现高性能实时随机存取的过程,但是,还没有讲到索引。事实上,索引是保障数据读取性能的最基本手段。
我们知道,HBase的数据是按行键字典序排序的,所以行键就是HBase最天然、最有效的索引。通过行键的读取是最高效的。
但是,HBase除了行键这个索引之外,竟然不支持二级索引。
为什么单独提到二级索引这件事呢?
在我们的云服务场景中有一个联系人数据表,行键是“用户ID反转+时间戳”,当你需要用手机号或者联系人姓名查询时,就需要扫描全部联系人数据,然后再一条条地过滤、匹配手机号或者联系人。这样是不是性能可能又不好了?
所以,这节课,我们就看一下在HBase中,在需要支持多个条件筛选的场景下,如何自己实现一个二级索引来提升性能。在这个过程中,我还会引入一个叫做协处理器的组件。希望在学完这一讲以后,你也能掌握这个知识点。
如何用行键实现组合索引?
在我们的例子中,如果用户ID在每次查询时都是必填项,那么有一个稍简单一些的方法,就是我们简单改变一下行键的组成,利用行键来实现一个类似关系型数据库的多字段组合索引。
我们在设计HBase行键的时候,除了考虑怎样合适地划分分区外,还要把查询的条件字段尽可能地融入到行键里。如果例子中的所有场景都是基于用户ID加上手机号查询数据,那么行键设计可以是图片里的样子。
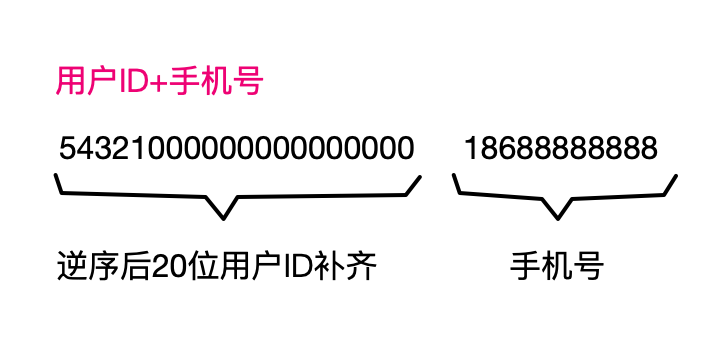
这样查询的时候,就可以根据用户ID和手机号精准地定位到某一条记录。
但是,跟关系型数据库索引前缀匹配的原则一样,如果查询条件字段中不包含HBase行键的前缀字段,那就没法命中行键索引,就可能需要全表或者区间扫描了。比如根据姓名查询联系人但是不知道用户ID,就得全表扫描了。
如果知道用户ID,那就满足前缀匹配,可以将全表扫描优化为区间扫描。也就是可以根据用户ID确定一个区间。下面这个图,描述了这样的一个区间。

你可以看到,区间的开始行键是用户ID逆序补齐后加上0,结束行键是用户ID逆序加上多个z,这也是因为字典序里面0最小,z最大。
这里再给你一个建议,就是行键保持定长,这样方便从行键中提取信息。
如果单纯依赖行键索引查询,满足不了需求。比如还是刚刚根据姓名查询联系人的需求,但是行键是用户ID加手机号。那该怎么办呢?接着往下看。
如何实现一个二级索引
回顾一下,MySQL的主键索引其实是一个基于B+树的聚簇索引,用叶子节点存储了数据。一个用户基本信息表的主键索引就像下面这张图。
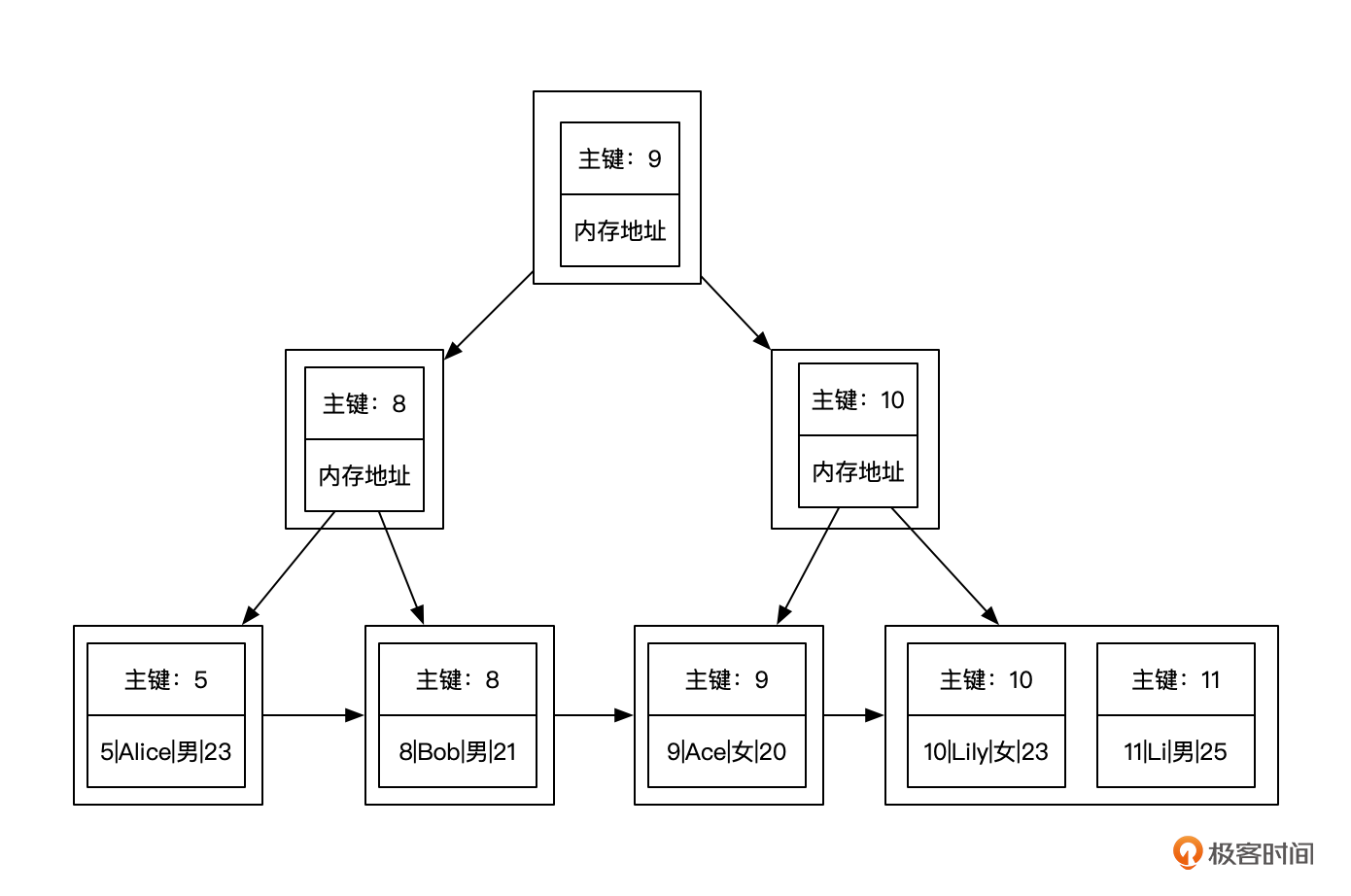
如果我要创建一个基于用户姓名的索引,MySQL会为我们构建一棵通过姓名找到主键的B+树。像下面这个图一样。
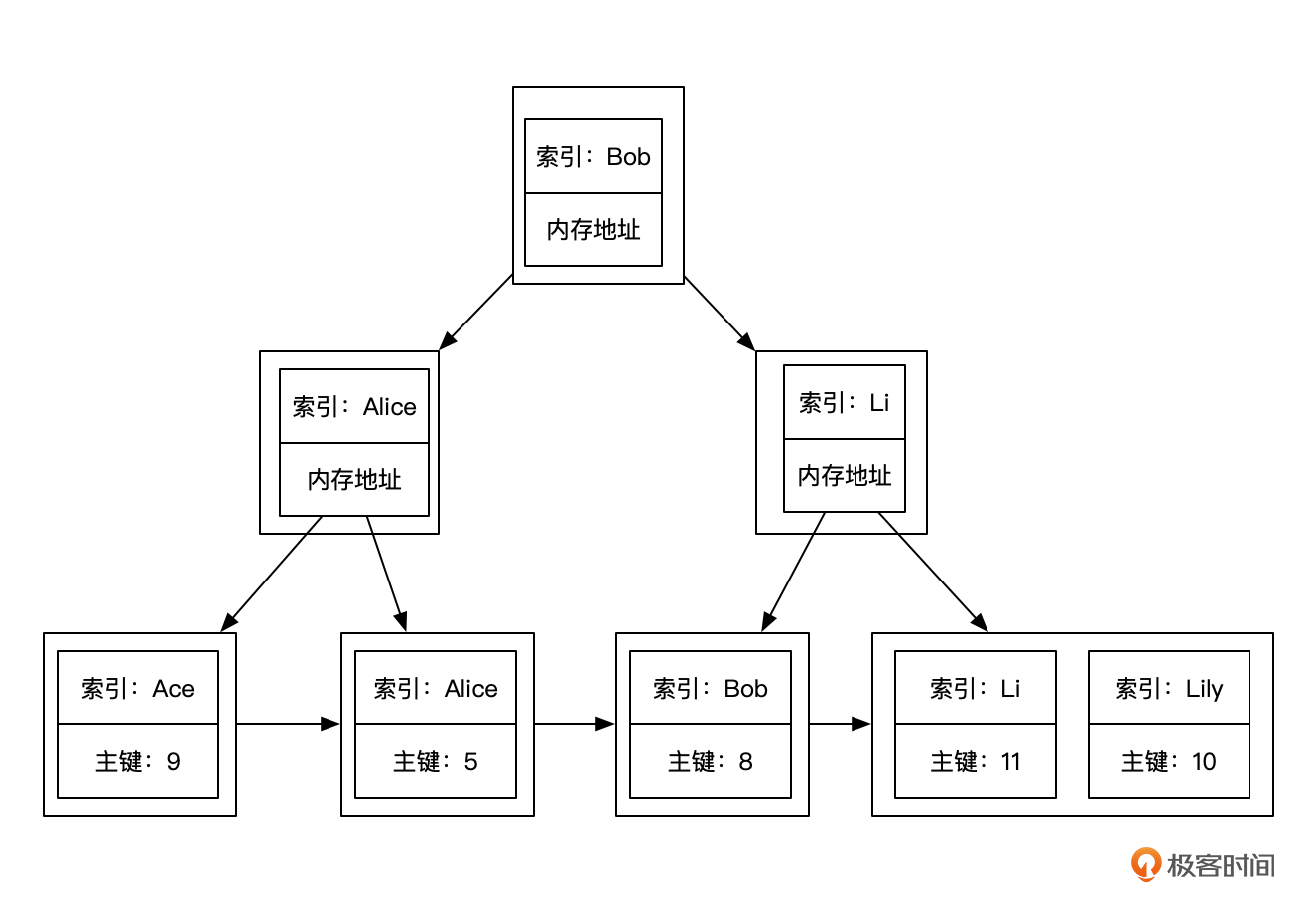
这样根据姓名查询的时候,就可以根据这个索引找到对应的数据行主键,再找到实际的数据。
类似的,我们也可以通过这种形式来实现一个HBase的二级索引。
在前面的例子中,我们可以构建一个从姓名到用户联系人表行键的映射关系。这样就可以先通过姓名找到行键,再通过行键直接读取联系人数据。
像下面这张图一样。
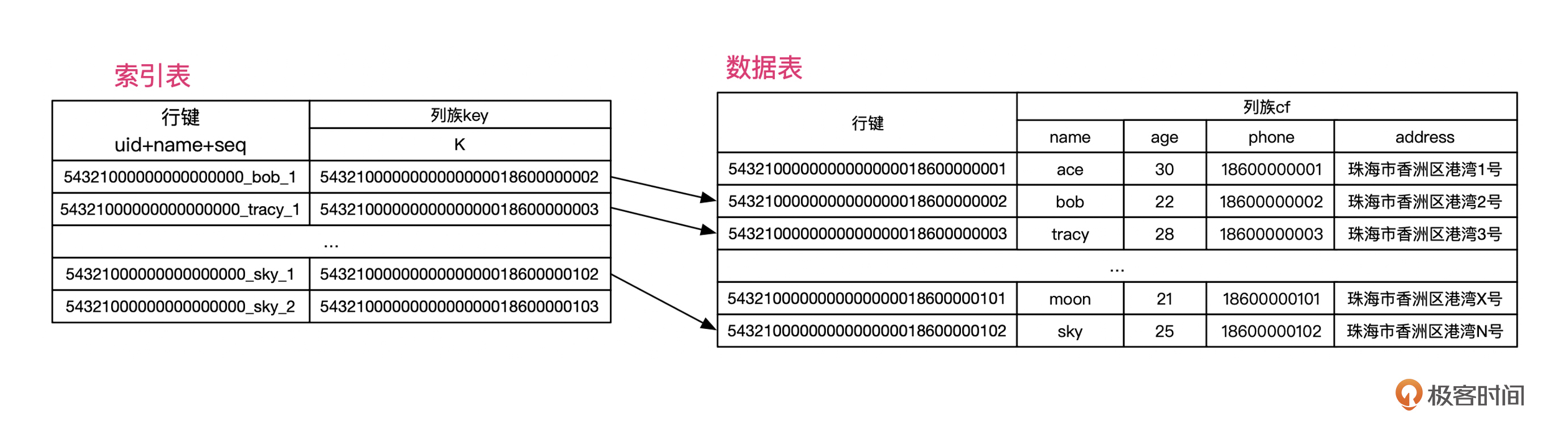
注意看,索引表的行键,我们组合了用户ID、姓名、序列号,这样一来,就做到行键的全局唯一性,避免与其他记录重复。
看起来是不是很简单?但是难点就在于什么时候写入索引表,如何保证索引表的数据与数据表一致。Phoenix就使用了HBase协处理器来解决这个问题。
什么是协处理器?
HBase有两类协处理器。
第1类叫做观察者类型协处理器,即Observer。观察者类型协处理器提供了各种回调函数,在一些方法执行前后触发,类似于Spring里面的AOP切面或者数据库的触发器。比如,针对Master的MasterObserver,会在建表、删除表、表压缩、表拆分的时候触发执行。而针对分区的RegionObserver,会在分区flush、数据Put等操作的情况下触发执行。
第2类叫做端点类型协处理器,类似存储过程。可以用来统计分析。它会在服务端完成统计分析之后,将结果传输到客户端。
今天我们要用到的就是观察者类型的协处理器,Phoenix也是通过Observer实现的在HBase上构建表的二级索引。
基于协处理器的自定义索引
好了,回到我们的例子中。我们需要在用户联系人表(假设为s_contact)写入数据时,同时写入一个索引表(假设为i_contact_name)。
注意,有个叫做RegionObserver的Observer类型协处理器,可以用来监听Region的一些Flush、Put等操作。这里我们就借用prePut方法,在s_contact表数据写入前构建我们的索引表数据。
实现逻辑很简单,我这里准备了一段示例代码,你也可以在这里找到。
package com.mt.hbase.chpt08.coprocessor;
import java.io.IOException;
import java.util.List;
import java.util.Optional;
import org.apache.hadoop.hbase.Cell;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.client.Table;
import org.apache.hadoop.hbase.coprocessor.ObserverContext;
import org.apache.hadoop.hbase.coprocessor.RegionCoprocessor;
import org.apache.hadoop.hbase.coprocessor.RegionCoprocessorEnvironment;
import org.apache.hadoop.hbase.coprocessor.RegionObserver;
import org.apache.hadoop.hbase.util.Bytes;
import org.apache.hadoop.hbase.wal.WALEdit;
/**
* 该Observer的作用是在s_contact表写入的时候, 抽取name、行键写入i_contact_name表建立二级索引
*/
public class IndexRegionObserver implements RegionCoprocessor, RegionObserver {
private static final String NAME = "name";
private static final String INDEX_TABLE_NAME = "i_contact_name";
private static final String CF = "cf";
private static final String COLUMN_K = "k";
@Override
public Optional<RegionObserver> getRegionObserver() {
return Optional.of(this);
}
@Override
public void prePut(ObserverContext<RegionCoprocessorEnvironment> c, Put put, WALEdit edit)
throws IOException {
RegionObserver.super.prePut(c, put, edit);
// 当一行数据中带有name才写索引
List<Cell> putNameCells = put.get(Bytes.toBytes(CF), Bytes.toBytes(NAME));
if(putNameCells==null || putNameCells.size()==0){
return;
}
// 获取name和行键
byte[] name = putNameCells.get(0).getValueArray();
byte[] rowKey = put.getRow();
RegionCoprocessorEnvironment env = c.getEnvironment();
Put indexPut = new Put(Bytes.toBytes(Bytes.toString(name)));
indexPut.addColumn(Bytes.toBytes(CF), Bytes.toBytes(COLUMN_K), rowKey);
Table indexTable = env.getConnection().getTable(TableName.valueOf(INDEX_TABLE_NAME));
indexTable.put(indexPut);
indexTable.close();
}
}
我来简单解释下这段代码,它的逻辑是在s_contact表数据写入之前,从写入的字段里面抽取出联系人姓名和行键,然后插入到索引表i_contact_name里。我这里简化了一下,直接以联系人姓名作为行键,原s_contact表行键做为值,建立一个映射。
当然,实际的实现方式要更为复杂,是先写索引还是先写数据?比如数据与索引的一致性如何保障?出现异常了如何处理?如何重建索引等。
我先说说先写索引还是数据这个问题。剩下的你可以自己展开。
话说回来,如果先写索引,再写数据,写数据即使失败了,那么在查询的时候,先查询到索引,再去找数据,这时候数据不存在,其实索引也相当于无效。
但是如果先写数据,后写索引,如果索引写入失败,查询的时候,查询索引发现不存在,这时候一般也不会进一步再去查找数据了,可能就会出现数据明明存在,但是查询不到的问题了。
一个完整的实现,肯定是需要保障索引与数据的一致,比如如果索引或者数据写失败了,可以重试几次或者抛出异常。也可以用定时任务,来扫描索引,重建索引,维护索引与数据的一致。
现在,代码实现了,如何加载生效呢?
协处理器如何装载?
我们可以通过两种方式加载HBase的协处理器。
第一种是静态加载。静态加载需要在配置文件hbase-site.xml中指定需要加载的类,并将包含类的jar包放在集群每个节点的hbase/lib目录下。静态加载的协处理器类会被加载到HBase服务的内存当中,在生命周期里一直存在。但是,静态加载需要重启HBase服务才能生效。所以静态加载适用于稳定的业务逻辑。
第二种是动态加载,通过HBase Shell或者Java API来动态手动加载,动态加载可以根据实时需求随时调整协处理器,可以灵活地添加、更新和删除协处理器类。
这里我们以动态加载为例,来看看如何将这个二级索引应用到表s_contact。
第一步,首先需要将代码打包,你可以从代码仓库下载代码后,使用maven命令"mvn package -DskipTests"打包,假设打包后jar包名字为 referencebook-1.0.jar。
第二步,因为在生产环境中一般都是集群部署模式,为了让集群的每个节点都能够访问这个jar包,加载协处理器类,所以需要把这个类上传到HDFS中,方便全局访问。
比如下面的命令就将jar包上传到了HDFS的/hadoop目录。
/home/hadoop/hadoop-2.10.1/bin/hdfs dfs -mkdir /hadoop
/home/hadoop/hadoop-2.10.1/bin/hdfs dfs -put referencebook-1.0.jar hdfs://master1:9000/hadoop/referencebook-1.0.jar
最后一步就是在s_contact表上启用这个协处理器,你可以参考下面的命令。
#创建索引表
create 'i_contact_name', {NAME => 'cf'}
#创建数据表
create 's_contact', {NAME => 'cf'}
disable 's_contact'
#为数据表动态加载协处理器
alter 's_contact', METHOD => 'table_att', 'Coprocessor'=>'/Users/xupeng/Downloads/referencebook-1.0.jar | com.mt.hbase.chpt08.coprocessor.IndexRegionObserver| 12345| arg1=1,arg2=2'
enable 's_contact'
#插入数据
put 's_contact', '5432100000000000000018600000002', 'cf:name', 'bob'
put 's_contact', '5432100000000000000018600000002', 'cf:age', '22'
scan 's_contact'
scan 'i_contact_name'
注意,动态加载协处理器的时候,我使用了jar包的一个本地路径,并指定了需要加载的协处理器的类全路径。加载的命令最后也带了两个参数,一个是协处理器的优先级,另外一个是用来传给协处理器程序的参数。
输出结果如下所示:
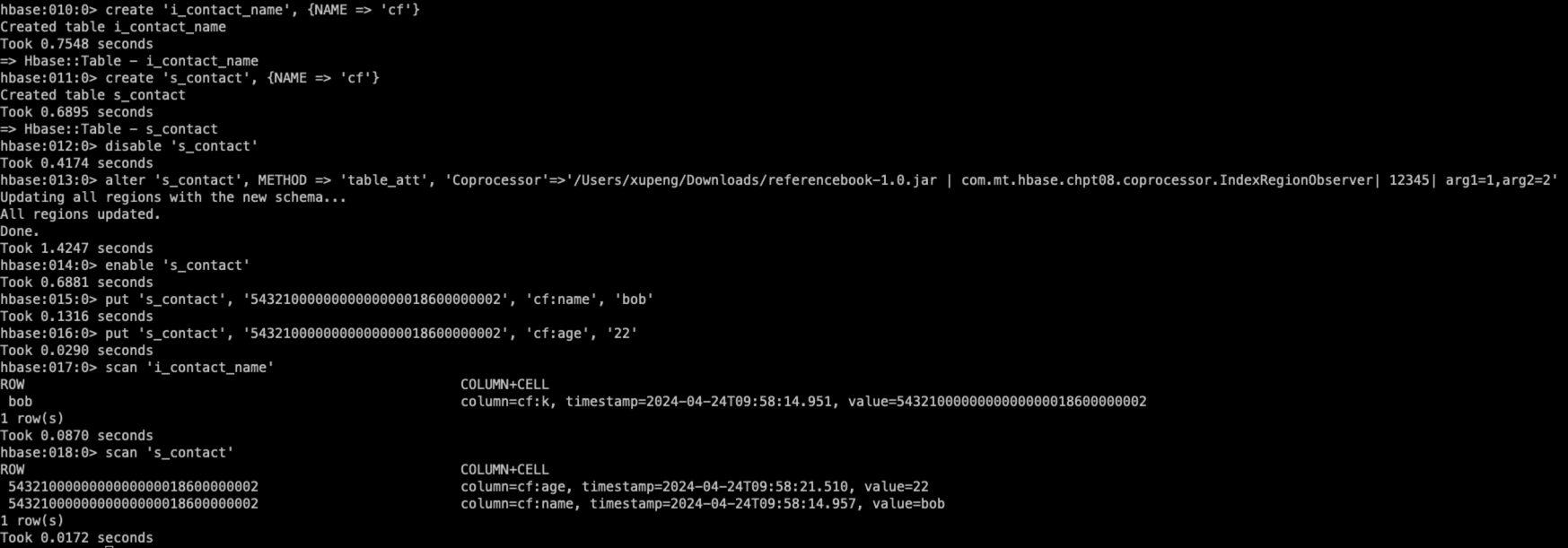
从输出结果可以看到,在向s_contact表写入数据的同时,也向索引表i_contact_name写入了一行索引记录。行键为用户名,而s_contact表的行键作为列值。
小结
设计行键的时候不单单要考虑如何更好地分区,同时也要考虑表数据的使用场景,将查询时用到的条件字段,尽可能多地融到行键里面,这样才能在查询时尽可能精准的定位到数据行。基于行键的单行读取最为高效,其次是基于一个小区间的扫描。
索引是数据库性能的基础保障,虽然HBase只支持行键的索引,但是我们还是有很多方法来解决需要涉及二级索引的需求。
HBase二级索引的方案有很多,比如基于ES+HBase的组合,我们的例子中,姓名到s_contact表行键的映射,可以在ES中构建,而表数据仍然存储在HBase中。这样,查询的时候就会先通过姓名从ES中快速搜索到行键,再通过行键去HBase表中读取数据。当然,这种方式同样需要一个工具,将这个映射关系的数据写入ES,会带来一定的复杂性,不过反过来说,也能实现一些更加复杂的查询场景。
HBase协处理器为我们提供了一个在服务端能力扩展的接口,比如实现一个二级索引、数据校验与验证、数据的安全性管理等。也可以通过协处理器在服务端对数据进行处理,减少在网络上传输的数据。
思考题
在示例程序中,我们并未考虑数据的分区,即使数据表与索引表采用同样的分区策略,一行数据与其索引也分属不同表的不同分区,由不同的RegionServer提供服务。这样对查询性能可能又是一个负面的影响,有什么优化方案吗?
欢迎你在留言区和我交流。如果觉得有所收获,也可以把课程分享给更多的朋友一起学习。欢迎你加入我们的读者交流群,我们下节课见!
- 淡漠落寞 👍(0) 💬(0)
是不是可以异步地把数据表里的内容写到索引表里去,这样获取下次用户来查询的时候通过索引表就可以查到数据了,以减少回表?写到索引表里的数据可以基于对于数据的访问热度来挑选,过久的不热的数据也可以将其在索引表里的内容删掉。防止最终所有数据都写了2份。
2024-10-20