09 为什么HBase能够实现海量数据的实时随机存取?
你好,我是彭旭。
上节课我们讲到HBase通过自动管理数据分区以及弹性伸缩应对数据的增长。这两个特性解决了我们云服务需求中的运维成本问题。
这节课我们从性能入手,看看HBase为什么能够在高并发场景下也做到秒到毫秒级的实时随机存取,替换掉MySQL。顺便看看HBase是如何实现高可用,解决的云服务高可用与故障恢复的问题。
先来看一下HBase在读写上是怎样优化性能的。
HBase写入性能优化
第2讲的时候我们介绍过LSM数据结构,HBase就是使用LSM的一个典型代表,LSM对写入的性能优化,这里我们直接复习一下。
总体来说,HBase数据写入的时候,无论是新增数据还是更新删除数据,都会先写入MemStore这个内存组件。
MemStore在内存中会使用一个有序的数据结构,比如NavigableSet,所以数据写入就已经排好序。当MemStore的大小达到配置的阈值或者经过一定时间后,MemStore就会将数据刷新输出到磁盘。这里会是一个磁盘的批量顺序写入,所以速度很快。又因为数据已经排好序,所以后续数据的读取也能够基于索引去做二分查找等快速读取。
在我们云服务中,其实大部分时候都是新增写入场景,或者修改了单条数据,比如修改联系人。新增的数据可以顺序写入磁盘。单条或者多条的联系人数据更新,原本需要的磁盘随机IO,也被转化成为了内存的读写与磁盘的顺序写入。而内存的写入基本上是纳秒到微秒级别,这样,数据的写入性能就有了一个巨大的提升。
HBase读取性能优化
读取响应最快的情况是能够命中缓存,HBase读取数据时,会将数据块缓存到内存,HBase使用多种缓存技术,如LRU BlockCache、BucketCache来提升缓存的性能。像BucketCache堆外缓存,就可以提供更大的缓存,并且绕过JVM垃圾回收器,减少GC的压力,同时提升缓存的性能。
数据在写入的时候,会先写入MemStore。MemStore数据是最新的数据,并且也可能是最热的数据,所以MemStore也是一个“最天然”的缓存。
缓存没有命中的情况下,HBase就需要通过HDFS去磁盘读取StoreFile文件来获取数据了。
HBase基于LSM的数据结构,数据写入的时候会将更新、删除的数据也先写入内存,然后再刷新输出到磁盘。这样会带来一个数据一致性的问题:同一行记录,可能存在多个存储文件中。
这样又会涉及一个数据的版本问题。HBase数据写入的时候都会带有一个时间戳版本,所以数据读取的时候会扫描MemStore、多个StoreFile文件,然后根据时间戳版本读取最新的数据版本。
显然,这个时候减少需要读取的StoreFile文件数量就是优化的重点了。
这里HBase有两种优化方式。
- 第一个是定期清理,通过Major/Minor Compact来合并同一个分区下的StoreFile文件,同时清理过期与删除的数据,减少需要扫描的文件与数据,也就是我们前面讲的LSM做的事情。
- 第二个是读取数据时,使用布隆过滤器来过滤掉部分StoreFile文件。
最后,到达需要读取的StoreFile文件。StoreFile又被划分为很多“数据块”,每个块都有一个对应的索引条目,使用索引就能通过数据行键定位到数据块。由于数据是按行键字典序排序的,所以在数据块内部,也可以使用二分查找等算法,快速查找到具体的行键数据。
总结一下,HBase数据写入的时候,通过将磁盘的随机写,转化为内存的随机写和磁盘的顺序写入。在使用机械磁盘的场景下,这个操作对写入性能的提升是成百上千倍的。HBase数据读取的时候,通过缓存、StoreFile的合并、布隆过滤器、索引等机制提升读取性能,最终保障HBase的单一请求读写性能能够达到毫秒级。
高并发
好,再说高并发。注意,高性能并不一定代表着能够支持高并发。当然,如果没有高性能,那大概率也不能支持高并发。
在互联网、金融交易、电信等领域面向C端的系统经常需要处理大量的用户请求,这些系统在高并发环境下,需要能够支持大量的用户同时访问或修改数据,而不会造成性能下降或系统崩溃。
水平扩展弹性伸缩,就是高并发系统必备的保障。
作为一个分布式数据库,HBase天然支持水平扩展,HBase负责给客户端提供读写请求服务的RegionServer可以动态扩容,实时加入HBase集群并开始提供服务。
HBase最小的负载均衡单元就是Region分区。一个HBase的表可以按行键范围拆分成多个分区,也只支持这种基于范围的分区,每个RegionServer负责服务多个Region的读写请求。这样,随着RegionServer的增多,能够支撑的并发也扩大。
实际上,高性能与高并发相辅相成,高性能作为高并发的支撑,每台RegionServer响应越快,每秒能够支持的请求量就越大,相应地集群的并发能力也越高。
有了高性能与高并发保障,最后再来看一下HBase的高可用与故障恢复如何保障。
高可用性和故障恢复
高可用需要一系列的设计与配置来保障,这里我们来看一下核心的数据高可用、服务高可用在HBase中是怎样实现的。
HBase的数据存储在HDFS上,HDFS本身提供了数据多副本、服务多节点的能力。
默认情况下,HDFS会为存储在上面的文件保存3个副本,而且3个副本会分配到不同的数据节点。所以,即使某些数据节点故障,另外的数据节点仍然可以提供服务保障数据可用。在开启了机柜感知的情况下,数据副本也能至少跨越两个机架。
这里简单解释一下机柜感知。其实就是通过配置,让HDFS知道集群中的数据节点在物理机柜上是怎么分布的,哪几个数据节点机器是部署在同一个机柜、同一个网关的。
所以,HDFS从数据、网络、文件的访问上,都为HBase提供了高可用以及容灾能力。
再来看一下服务层面的高可用是如何实现的。
前面也提到RegionServer作为提供读写服务的角色,其实是一个无状态的服务。一般一个RegionServer可以负责成百上千个分区Region的读写请求。一个分区同一时刻,只会由一个RegionServer来负责对外提供服务。
如果为某个分区提供读写服务的RegionServer出现了故障,HBase Master会监到RegionServer的状态,然后将其负责的分区转移到其他活跃的RegionServer。这样就可以保证数据的高可用与服务的持续性,当然这个过程可能会有秒到分钟级别的分区迁移耗时。
最后,我们从一个HBase客户端发起请求,到服务端响应的流程再来看一下,整个在线服务过程中,哪里可能还存在单点问题。
HBase数据读写流程如下图所示。
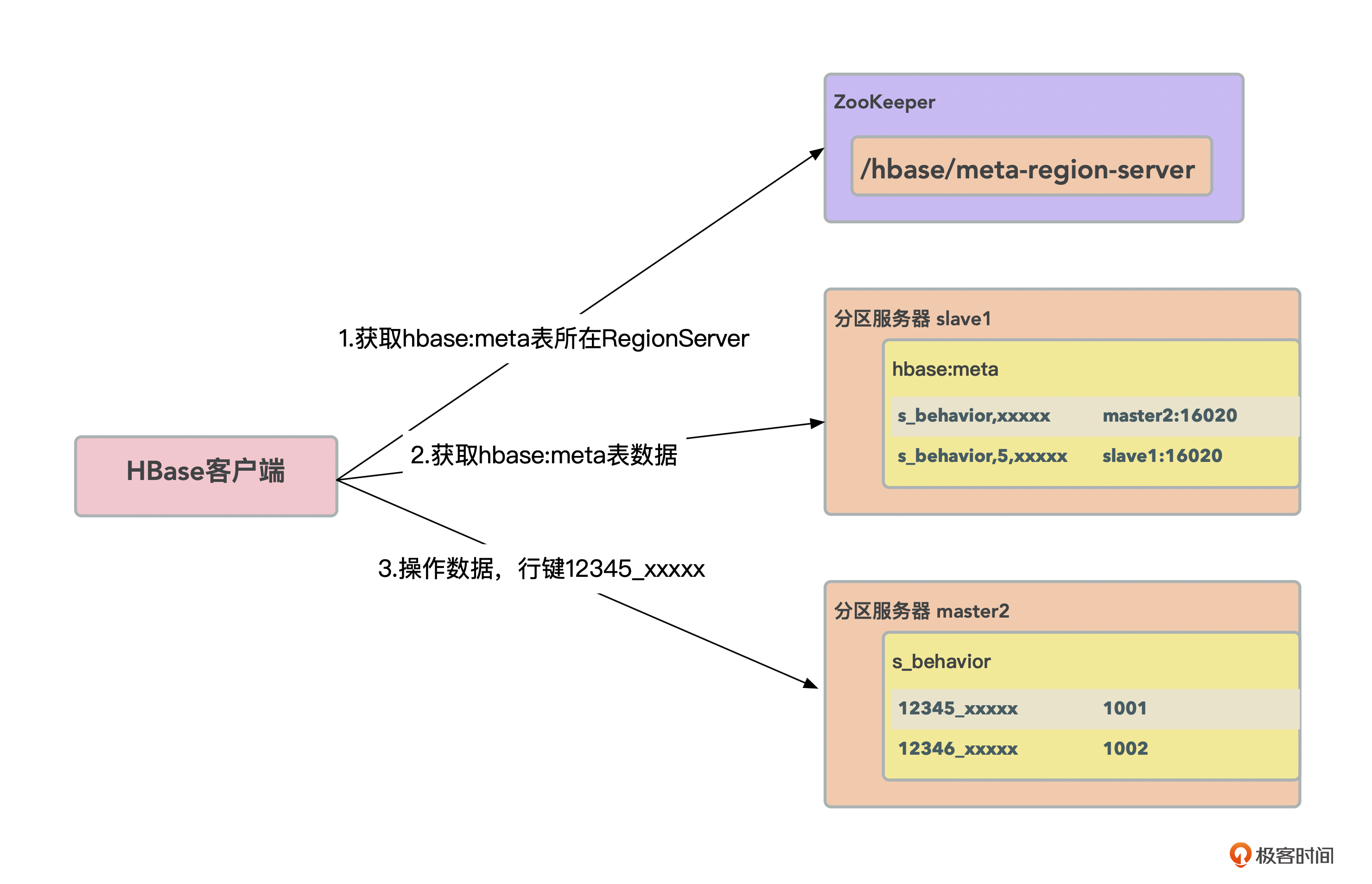
- HBase客户端从ZK上面获取到hbase:meta表即元数据表所在的RegionServer是哪一台。
- HBase客户端从负责元数据表的RegionServer上,获取到全部元数据表的数据,元数据表记录了数据表有多少个分区、每个分区又由哪个RegionServer提供服务,注意这里HBase客户端会缓存所有元数据表数据。
- 接下来HBase客户端就直接将需要读写的数据行键与元数据表做个匹配,直接与负责该数据的RegionServer发起读写请求。
这个过程中涉及的ZK是高可用集群,没有单点问题,hbase:meta元数据表被当成一个只有一个分区的表,只需一个RegionServer负责提供读写服务。同样如果负责元数据表的RegionServer故障,也会将元数据表转移到其他RegionServer提供服务。
注意,数据读写流程的第二步,客户端会缓存元数据表。那如果有些分区转移或者拆分后,元数据表数据更新了,客户端缓存的元数据也就过期了,这又该怎么处理呢?
比如表A分区1原本由RegionServer slave1负责提供服务,但是通过负载均衡后,表A分区1转移到了slave2提供服务。此时客户端仍然向slave1发起读写请求会发生什么呢?
这时,slave1会向客户端返回一个RegionMovedException,并且异常信息里面包含了负责该分区的新的RegionServer slave2的地址信息。然后客户端就会直接跟slave2进行通信,同时更新本地缓存,最后再刷新一遍元数据表。
到第三步,HBase客户端获取到元数据表信息以后,所有的读写操作就只跟数据所在的RegionServer通信了。而RegionServer具备高可用弹性伸缩,所以在整个数据读写流程中就不存在一个组件是瓶颈或者单点了。
总结一下,数据上HBase依靠HDFS提供高可用,而服务上HBase的组件都支持集群模式,能够支持快速故障转移,提供服务上的高可用。
小结
作为一个需要支持海量数据实时随机存取的数据库,设计上至少需要考虑这么几个关键点。
- 高性能:实时随机存取就表示能够在OLTP系统中使用,所以读写性能都需要在毫秒级别以内。
- 高并发:互联网应用动则每秒成千上万个并发,并且经常有类似秒杀的活动,会人为地创造一些请求高峰,所以并发设计上需要能够实现水平弹性伸缩、负载均衡等。
- 高可用性和故障恢复:无论是在OLTP系统还是其他系统,都不能因为数据问题导致系统不可用,也就是设计中不能存在单点问题,像MySQL可以实现主备容灾等。
当然,设计一个优秀的数据库或者存储引擎还需要考虑很多因素,比如数据的一致性保障、监控与调优如何实现、数据如何访问、数据安全如何保障等。
在高性能保障上,HBase通过使用LSM,通过将磁盘的随机写转化为内存的随机写,加磁盘的顺序写入,大大提升了写入性能。同时通过合并、布隆过滤器、缓存等手段减少读取数据需要扫描的文件数量,提升缓存命中率,将读写响应都控制在毫秒级。
在高并发上,HBase能够实现RegionServer的在线弹性伸缩。将分区Region作为负载均衡的最小单元在集群中自动均衡迁移。随着RegionServer的增加,能够支撑的并发也能够相应增加。当然这也建立在分区设计合理,能够均衡分布的基础上。
在高可用与故障恢复上,HBase Master、RegionServer都采用的是集群模式,可以实现秒级故障转移,系统也不存在单点的问题。
通过这些设计与优化,HBase在单行、多行数据上的实时随机存取性能能够到达毫秒级,这样才能真正在一个OLTP系统中使用。
思考题
理论上来说RegionServer能够无限弹性伸缩,但是实际上会有什么限制吗?
欢迎你在留言区和我交流。如果觉得有所收获,也可以把课程分享给更多的朋友一起学习。欢迎你加入我们的读者交流群,我们下节课见!
- lufofire 👍(1) 💬(2)
思考题: 1. 读写性能影响:一个client请求,如果查询找到真正负责读取RegionServer,本身就是代理转发过程,有一定网络延迟。 2. 增加master和ZK管理压力:RegionServer状态监控,元数据管理,更多RegionServer意味着更多的元数据读写。 另外一个关于HBase的高并发, 文章简单说了扩缩容, 没有详细说明在扩容后,HBase如何做了哪些事情来保证高可用,比如服务发现和节点故障后如何处理。另外,只是通过依赖CK来着保活和元数据管理, 本身是不够的,毕竟从ZK组件也有缺陷,比如ZooKeeper 集群的性能受到其最慢节点的影响,在大规模的读写操作下,性能可能会成为瓶颈。再比如相比etcd, zk本身没有很好的watcher机制,如何进行服务状态监控呢?
2024-06-28 - 密码123456 👍(0) 💬(1)
受到的限制应该就是带宽了。文件写入hdfs,本身也是一个服务,不会像硬盘那么快。从hdfs读取也是,也会占用一定的资源。 有个问题,正常服务都是预写日志,memstore,没有提交。预写的日志,没有上传到hdfs,服务故障了,其他服务接替这个分区后,数据是不是就丢失了?
2024-06-28