06 数据分区后,如何应对Join?
你好,我是彭旭。
上一讲,我们介绍了在分布式数据库中合理地分库分表或者分区的方法,还讲了如何裁剪查询时需要扫描的数据,优化查询性能。
但是,分区也会带来一个新的问题。数据表之间通常存在关联关系,一个完整的业务通常需要关联多个表,才能得到最终需要的业务数据。
这节课,我们就来看看数据分区后,分布式数据库是如何处理这种数据关联场景的。
相信这节课,你一定能了解分布式数据库连接的几种方式,以及它们各自的性能表现和适用场景。
分布式数据库的几种Join方式
为了更好地理解Join的各种方式,我给你准备了一个例子。
这是一个基于分布式数据库存储的用户行为管理系统。假设系统包含如下两个表,都以分区/分片形式存储。
用户表:以user_id分区。
CREATE TABLE t_user
(
`app_id` UInt32 COMMENT '应用id',
`user_id` UInt32 COMMENT '用户ID',
`name` String COMMENT '姓名',
`email` String COMMENT '邮箱',
`avatar` String COMMENT '头像url',
`phone` String COMMENT '手机号',
`address` String COMMENT '地址',
`create_date` DateTime COMMENT '创建时间'
)
用户行为表:以user_id分区。
CREATE TABLE t_user_event
(
`app_id` UInt32 COMMENT '应用id',
`device_id` String COMMENT '设备ID',
`event_time` DateTime COMMENT '事件时间',
`event` String COMMENT '事件名称',
`event_json` String COMMENT '事件详情',
`user_id` UInt32 COMMENT '用户ID',
`create_date` DateTime COMMENT '创建时间'
)
现在有个营销需求,我们需要查询出2024年1月1日登录过的用户清单,然后向其发送一个优惠邮件。一个简单的Join SQL就可以查询出来我们需要的数据。
SELECT
u.app_id,
u.user_id,
u.email
FROM t_user u , t_user_event as ue
where u.user_id = ue.user_id
and ue.event = 'login'
and DATE(ue.event_time) = '2024-01-01';
然后,基于表的统计信息,数据库的CBO会选择一个合适的执行计划,也就是cost最小的Join方式来查询数据。
以StarRocks为例,在两个表数据量相差较大的情况下,比如t_user表数据量在几万行级别,t_user_event表数据量在百万到千万以上,那么这个SQL的执行计划有一个片段就是这样的:
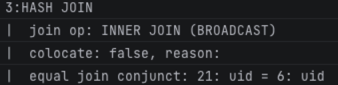
可以看到,这里采用了一种叫做Broadcast Join的方式。
当两个表的数据量相当时,这个SQL的执行计划又变成了下面这张图。此时StarRocks采用了另外一种叫做Bucket Shuffle Join的方式。
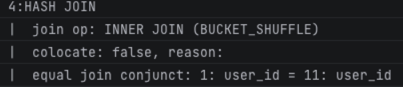
总结一下,这里涉及到了Hash Join、Broadcast Join、Bucket Shuffle Join这几个概念。而实际上 “Bucket Shuffle Join” 又是 “Shuffle Join” 的一种特殊形式。好了,下面我们就一个个说说这些Join。
Hash Join
事实上,Hash Join是传统关系型数据库中一种高效的Join方式。它会对一张表的Join列进行哈希处理,将具有相同哈希值的数据行放入同一个桶中,然后将另一张Join表的Join列同样Hash后再进行匹配,最终实现数据连接。
你可以看下这张图,辅助理解。
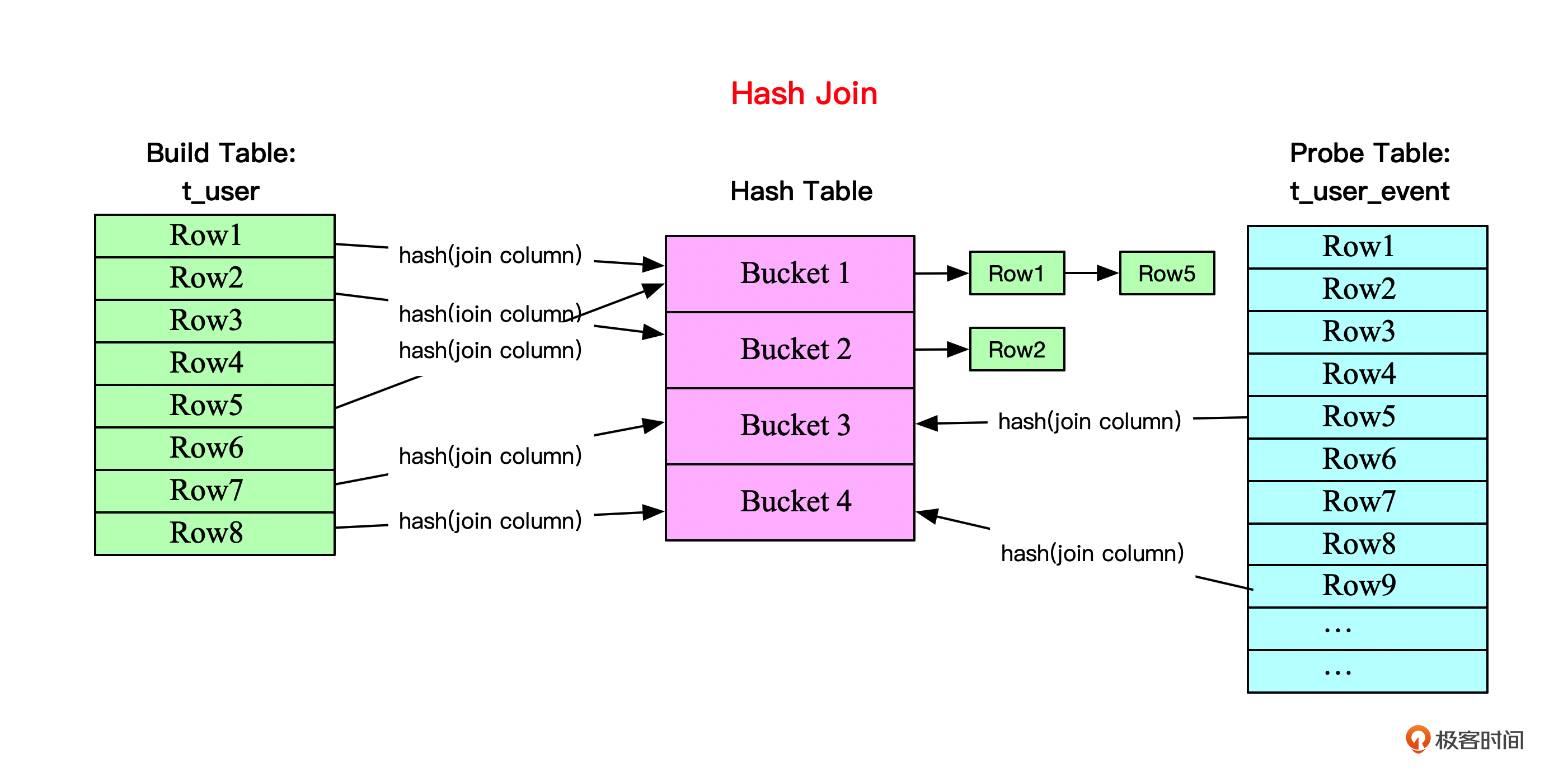
我们例子里的SQL,Hash Join大概可以分为3步。
- 确定Build Table和Probe Table。
Build Table就是用来构建Hash表的数据表。构建Hash表之后,Probe Table会使用Join列探测Hash表,探测成功就获得一行连接好的数据。
通常情况下,小表会作为Build Table,大表作为Probe Table。这里t_user表数据量较少,所以它就作为Build Table。另外一张t_user_event就作为Probe Table。
- 构建Hash Table。
将Build Table(t_user)的每一行数据基于Join列(这里是user_id)进行Hash计算后映射到一个Hash桶,构建一个Hash Table。Hash Table数据一般缓存在内存,如果内存放不下,就需要用到磁盘空间。
- 探测。
使用相同的Hash函数将Probe Table(t_use_event)的Join列映射到Hash Table中的某个桶,映射成功之后再从桶里面看看能否找到Join列相同的记录。注意,并不是Hash映射成功了就Join成功,因为Hash冲突可能导致一个桶有多条记录。
如果找到了和Join列相等的记录,那就算成功匹配,将这一行数据作为结果返回。
其实,Hash Join是表连接的基础,实际上,另外的Broadcast Join、Shuffle Join也只是在Hash Join上穿上了分布式的皮,接着往下看。
Broadcast Join
顾名思义,Broadcast Join就是广播连接,意味着将Join的A表的所有数据通过广播的方式分发到Join的B表所有所在的节点。这种情况下,因为需要网络传递整个A表的数据到B表所在的N个集群的节点,所以A表的数据量一般较小,而B表数据量较大。换句话说,广播连接适用于小表连接大表的情况。
下面这个图就描述了小表t_user与大表t_user_event进行广播连接的过程。t_user表的所有数据都会复制到t_user_event表分区数据所在的每个节点的内存,然后与这个节点上t_user_event表存储的分区数据进行Hash Join。
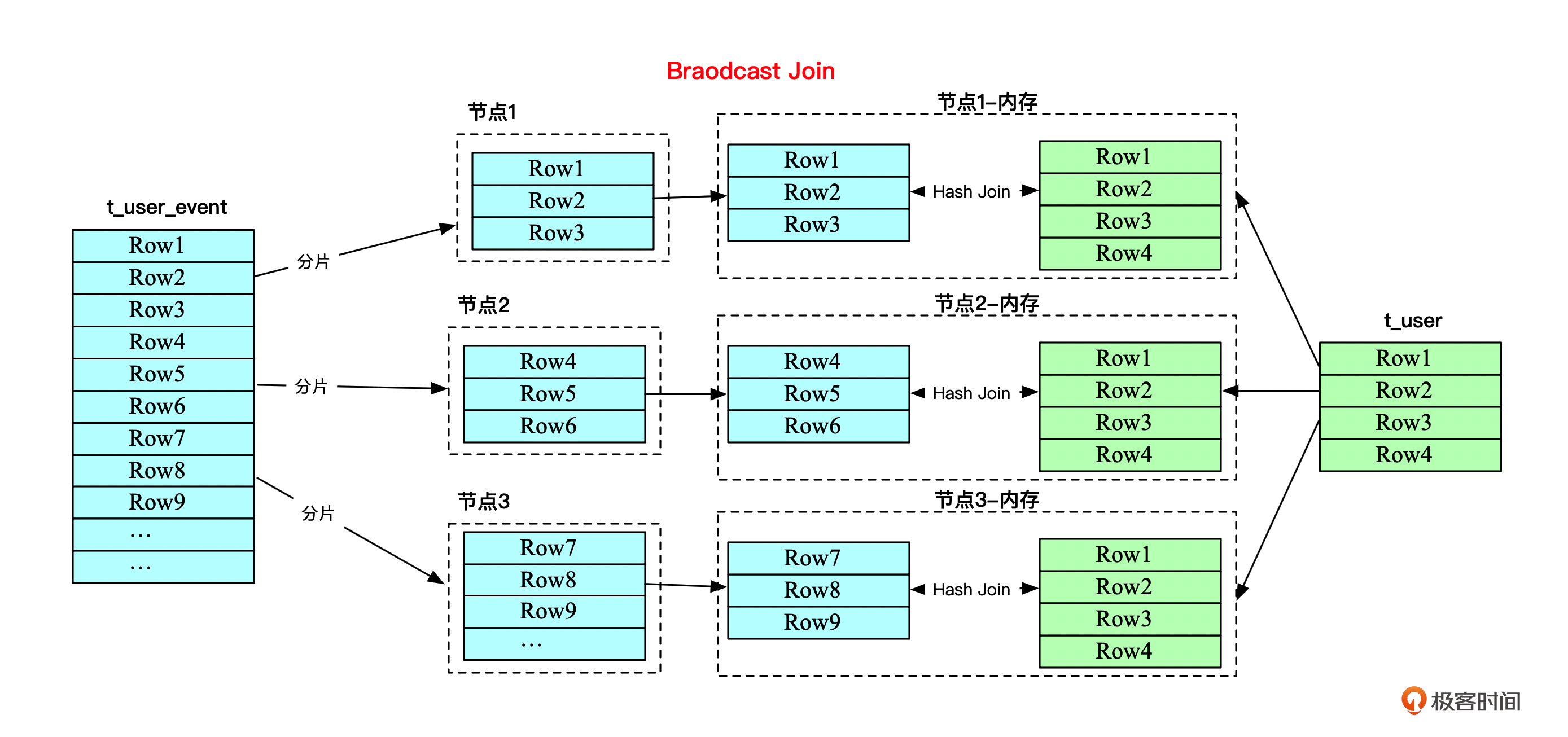
好,我再问一个问题。我们知道了,Broadcast Join适合小表连接大表的场景,那么如果两个分布式表都是大表呢?这时候执行引擎就会选用Shuffle Join。
Shuffle Join
Shuffle Join将Join的A、B表都按照Join列重新进行分区,然后将A、B表分区后的数据匹配Join列放到同一个节点。这样就可以将两个大表的Join分而治之,划分为多个小表的Join,充分利用集群资源并行化。
像下面这个图一样。
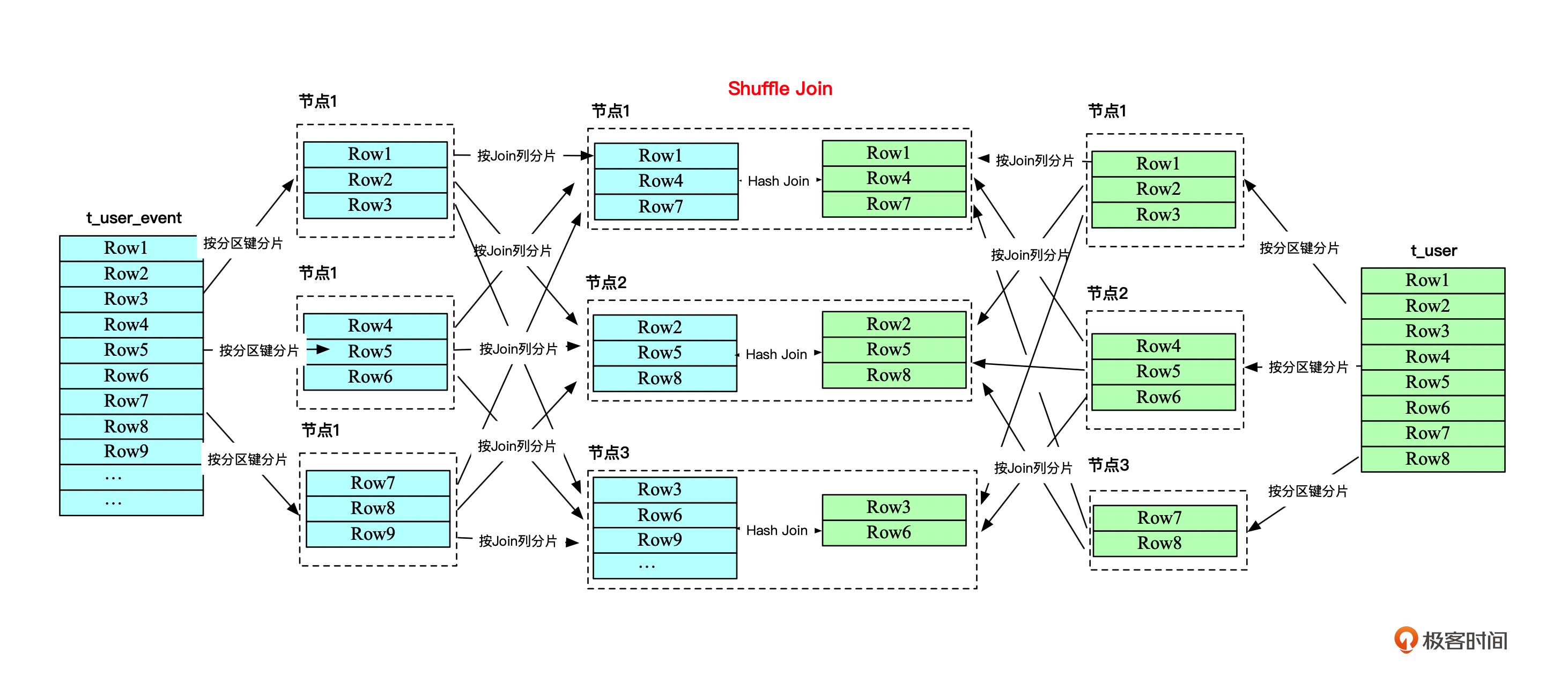
Shuffle Join将原来已经分区的表数据打乱,重新按照Join列分区后,将两个表相同Join列的分区传输到同一个节点。所以,有可能出现需要将A、B表的所有数据都在集群中传输一次的情况,那可能就会影响性能。那应该怎么办呢?
在分区或分桶的场景下,我们假设A、B表做Join,如果Join列是A表的分区/分桶列,那么A表的数据其实可以不用去移动。B表通过向A表的数据分桶发送数据就可以完成Join的计算。这就是Bucket Shuffle Join,它相当于在Shuffle Join上减少了A表的数据传输,提升了性能。
再进一步,其实还有一个最理想的Join模式Colocate Join。它会将数据与计算都本地化,最大化提升性能。
Colocate Join
在我们的例子中,t_user表与t_user_event表都是基于use_id分区的。如果两个表分区/分桶的数量相同,而且正好相同分区范围的数据都由同一个服务器节点存储,那么这两个表的Join是不是就只需要在每个节点分别Join,然后再将Join后的数据汇总就得到Join结果了呢?
就像下面这张图。
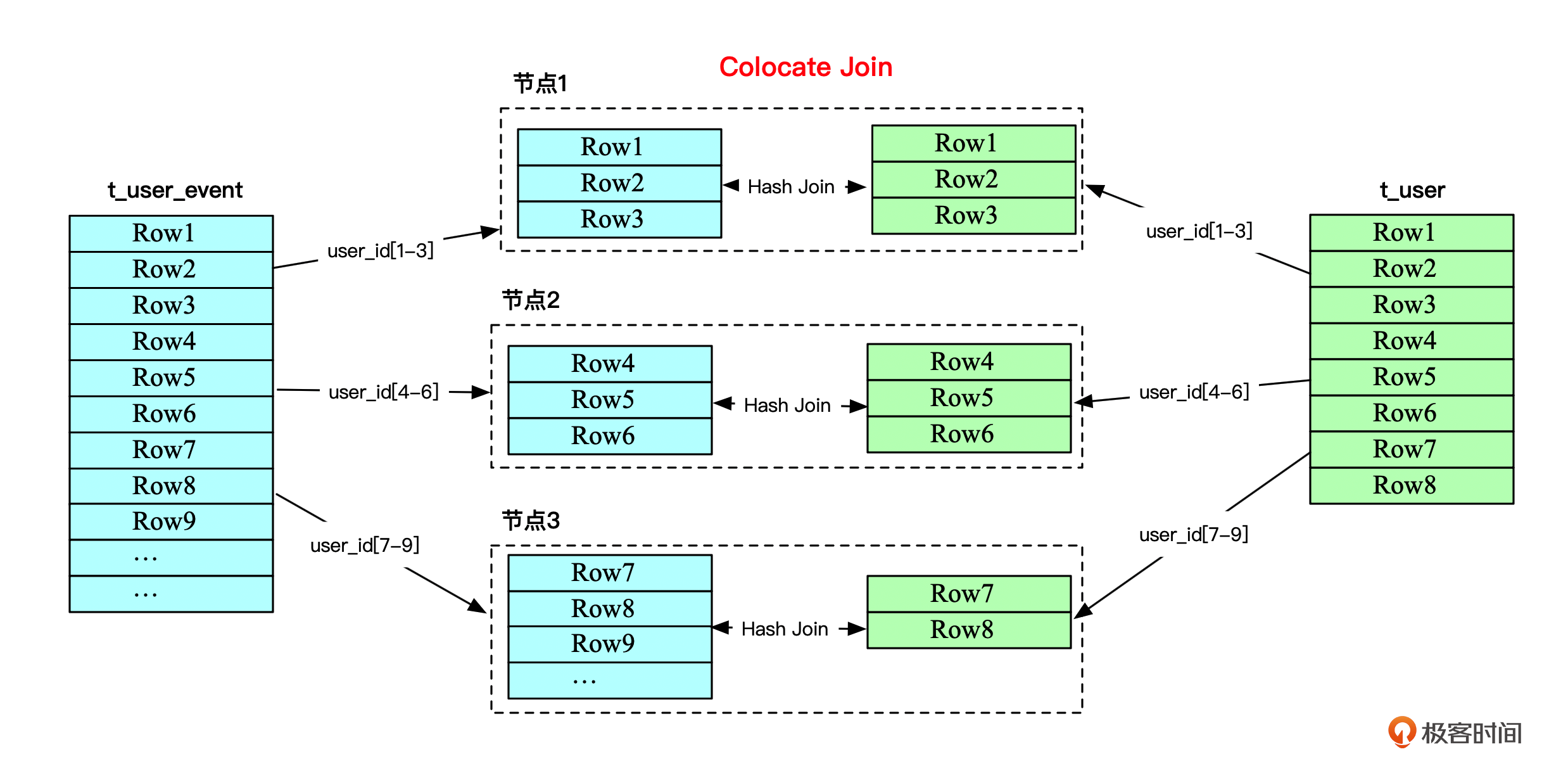
t_user与t_user_event两个表的数据由user_id分成了3个分片,正好两个表的user_id[1-3]分片数据都分布在节点1,user_id[4-6]分片的数据都分布在节点2,user_id[7-9]分片的数据都分布在节点3,以此类推。
这样两个表由user_id做Join的时候,相同user_id范围的数据正好分布在同一个节点机器了,所以整个分布式表的连接都可以转化为多个本地表的连接,也无需在集群间传输数据,大大提升了连接性能。
好了,最后来总结一下,在分布式数据库中,这几种表Join方式的适用场景。

了解了几种Join方式之后,咱们再看看课程里要讲到的几种数据库表是如何Join的。
HBase表如何Join?
HBase虽然是一个数据库,但是本身是不提供SQL语言支持的,所以原生上是不支持多表Join的。我们只能通过程序查询出主表数据,再根据主表数据补充子表相关内容。
不过,Phoneix为HBase提供了一个SQL引擎,能够将SQL转化为HBase原生的API进行数据操作。但是,我的建议是避免在Phoenix中使用Join操作,尤其是处理大型数据集时。因为Phoenix的Join操作相对于传统关系型数据库更复杂,而且可能对性能产生很大影响。
由于HBase的优化目标是大规模数据集的读写性能,而非复杂关联查询,所以,执行Join可能导致查询速度下降并影响整个集群性能。
ClickHouse表如何Join?
ClickHouse在使用模式上是建议使用一个大宽表的模式,而尽量避免Join。这样能更好地利用ClickHouse的并行计算和向量化查询优势。尽量避免Join操作,避免数据在不同表之间进行频繁的关联操作,从而减少查询的复杂度,提高系统的整体性能。
不过,很多时候还是避免不了Join,我们简单说说。
ClickHouse中因为涉及分布式表与本地表,如果两个分布式表进行Join,那么假设为A Join B,处理过程大致如下。
- 将SQL中分布式表A转化为A的本地表,然后SQL分发到各个节点执行。
- 在每个节点执行SQL时候发现,B也是分布式表,然后就会去其他所有节点执行B对应的子查询,拉取数据。拉取到数据后再本地执行Join操作,Join成功后得到数据。
- 最后将第2步所有节点Join成功后得到的数据汇总,返回最后的结果。
你应该发现了,这个过程其实就是两个遍历循环,类似一个笛卡尔乘积的Join,这样开销就很大了。所以,我们应该尽量避免这种分布式表之间的Join。不过据字节跳动的一些分享,他们内部对ClickHouse做了一些改造,也实现了将两个分布式表之间的Join转化为Colocate Join。顺着这个方向,你也可以思考下,如果是你会怎么做?
话说回来,如果某些业务场景确实需要在ClickHouse中进行一些关联多表的复杂查询,建议可以先试用Spark、Flink之类的任务,将数据先进行预处理形成大宽表。然后基于这个宽表查询,毕竟这也是ClickHouse擅长的。
StarRocks表如何Join
前面我们例子中查看SQL执行计划的时候,StarRocks自动为两个表的Join选择了最高效的一种Join方式。根据官方的一些性能基准测试,StarRocks在多表连接上的性能要超过ClickHouse。对于星型或者雪花模型进行建模的支持上,StarRocks的支持要更好。
StarRocks基于代价的执行引擎会自动帮我们选择哪个表作为驱动表、使用什么样的Join方式。执行引擎会基于统计的信息,自动帮我们重写,优化Join与查询。
不过有一点要注意,如果需要用到Colocate Join,StarRocks在创建需要关联的表时,需要为这些表指定同样的配置参数值 colocate_with ,并且,这几个关联的表需要满足几个条件。
- 设置同样的分桶键,分桶键的类型、数量、顺序完全一致。
- 设置相同的分桶数量,以便相同键的数据划分到同一个桶。
- 设置相同的分区副本数,这样就能够保证每个节点上都能够同时具备这几个关联表的一个副本。
看下具体代码。
CREATE TABLE t_user_event
(
`event` varchar(64) COMMENT '事件名称',
`event_time` date COMMENT '事件时间',
`user_id` bigint COMMENT '用户ID',
`app_id` bigint COMMENT '应用id',
`device_id` varchar(64) COMMENT '设备ID',
`event_json` varchar(64) COMMENT '事件详情',
`create_date` date COMMENT '创建时间'
)
DUPLICATE KEY(`event`,`event_time`)
PARTITION BY (`event`,`event_time`)
DISTRIBUTED BY HASH(user_id)
PROPERTIES (
"replication_num" = "1",
"colocate_with" = "user_id"
);
小结
不同类型的Join对查询性能影响很大,我们在业务设计过程中应该尽量避免复杂的Join。比如阿里巴巴Java编码规范就禁止在业务系统中超过3个表的Join。这也是为什么之前复杂的存储过程在逐步消亡。
Colocate Join是分布式数据库中大表Join的一个最优解。它通过优化数据分布,将分布式的表连接转化成了多个小的本地表连接。其次是Bucket Shuffle Join,最后是Shuffle Join。
小表与大表连接则使用Broadcast Join,不过可能带来集群网络传输上的压力。
数据库层面看,HBase不支持SQL语言,只提供了一些数据访问API。ClickHouse则优选宽表的查询。StarRocks则对Join支持更好,如果业务上存在星型/雪花模型的需求,比如事实表与多个维度表的灵活分析,可以选用StarRocks。
思考题
考虑到数据传输、本地化,Colocate Join是正常情况下性能最优的一个选择。但是从并行度与扩展度上来讲,你觉得Colocate Join一定优于Shuffle Join吗?
欢迎你在留言区和我交流。如果觉得有所收获,也可以把课程分享给更多的朋友一起学习。欢迎你加入我们的读者交流群,我们下节课见!
- lufofire 👍(5) 💬(1)
思考题: Colocate Join 并不一定优于 Shuffle Join。 因为Colocate Join因为本身也具有局限性。比如上一讲说的关于片健选择,在多租户场景中,考虑到某些租户数据量很大,我们选择的片健一般是租户ID+时间的复合片健,更有利于负载均衡。而对于这种复合片健,相同的租户数据失不可能放在同一个Shard中,使得Colocate Join方式无法开展的, 而这个时候Shuffle Join就会是更好的选择。简单来说,Colocate Join会存在扩展性问题,负载均衡的问题, 它比较适合数据量适中,节点间的数据分布均匀,且查询模式稳定的场景。而对于需要高度扩展性和并行处理的大规模数据集,Shuffle Join 可能是更合适的选择, 当这种场景下使用join查询会消耗大量的I/O, 延迟也会很高, 需要谨慎使用。
2024-06-25 - ls 👍(1) 💬(0)
join问题还是能少就尽量少,不像关系型数据库 ,有时上来先来7个表关联
2024-08-09