05 分布式数据库如何合理分区与设计行键?
你好,我是彭旭。
上一讲我们介绍了事务和MVCC,说到分布式数据库(比如HBase)对事务的支持较弱,甚至StarRocks、ClickHouse是不支持传统事务的。这是因为分布式数据库涉及多个服务器,跨表跨行事务需要协调集群多个节点,复杂性大大提高了。
不过,分布式数据库在牺牲了一部分事务的支持之后,也带来了一个主要的优势。它会将数据分片,然后分散到集群的各个节点,合理利用分布式集群的能力,从而实现弹性伸缩和负载均衡。
那么如何更好地分区,从而实现弹性伸缩和负载均衡呢?这就是咱们这节课要讨论的重点内容。
从分库分表说起
在传统关系型数据库领域流传着一个说法,说是MySQL单表数据量如果大于2000万行,性能会明显下降。你有想过这是为什么吗?
我们知道,在InnoDB存储引擎里一般使用B+树作为索引存储数据结构,而B+树的查询性能与树的高度息息相关,树的高度每加1,起码就会多一次磁盘的寻道I/O。InnoDB最小存储单元是页,B+树一个节点(叶子节点或非叶子节点)的大小就是一页。而一个页的大小默认是16KB。
好,现在我们来算一下以B+树为索引的情况下,不同高度的B+树能够索引一个表的多少数据行。注意,这里我们是以主键为索引,数据聚簇存储的情况下计算。
- 假设表主键类型为Bigint,占用空间为8 Byte。指针占用空间6 Byte,总共14 Byte。这样就可以算出一个B+树的非叶子节点大概可以存放16 KByte/14 Byte=1170个“主键+指针”的组合。
- 以表的一行数据大小1K为例,一个B+树的叶子节点就可以存16 KByte/1 KByte=16条(行)数据。
这样我们就可以得到2条结论。
- 高度为2的B+树可以索引 1170 * 16 = 18,720行数据。
- 高度为3的B+树可以索引 1170 * 1170 * 16 = 21,902,400行数据。
如果B+树超过3层,一方面,高度增加会导致磁盘I/O增加,另一方面,数据量太大,查询可能需要经过更多层的内部节点才能到达叶子节点,所以性能急剧下降。于是,就有了这个单表数据大于2000万行后性能下降的说法。
当然,这也不是绝对的,如果索引设计得好,那么基本都是基于索引的少数行查询,也还是可以支持单表亿行数据的。
不过这也提醒了我们,在关系型数据库中,我们到底应该在什么时候开始考虑分库分表。这里的分库分表都以水平拆分为例,不考虑按业务线的垂直拆分或者将一个表的不同字段拆分成不同表的情况。
分库分表需要指定一个分库分表键,对于关系型数据库来说,分库分表键一般使用的是查询中的必填字段。举几个例子。
- 个人云服务:个人云服务中所有数据的查询都会带上user_id,避免越权访问其他人的数据。所以,user_id可以用来做分库分表键,这样一个人的数据就会存储在一个表中。当然,如果用户数据量很大,也可以进一步拆分。
- SaaS系统:SaaS系统中所有的数据查询与写入都会关联到当前租户,所以租户ID可以用来做分库分表键。
- 物联网IoT设备心跳数据:物联网心跳数据一般按日期存储在一起,也按日期分析,所以日期可以做分库分表键。
不过,分库分表之后也会带来一些副作用。比如数据join,可能需要跨库跨表,这又反过来会影响性能。再比如,原本简单的本地事务变成了分布式事务,又需要保障数据的一致性。所以有时候会引入一些分布式事务框架(如seata),或者会在应用程序中使用TCC、本地消息日志表等侵入业务的方式。最后,就是在分库分表中出现热点区间后,可能需要数据迁移,在关系型数据库中可能就需要手动介入了。
好了,回到分布式数据库,分布式数据库的分区或者分片原理其实跟关系型数据库类似,不过从数据分区的自动化、分区路由、分区的运维上,有了很大的一个提升。
分区,弹性伸缩的基础单元
分布式数据库将一个数据表,根据主键/分区键的不同,将这个表的数据根据规则拆分到不同的服务器上,称之为数据分区(Partition)。
分区在不同的分布式数据库中有不同的叫法。
- 在HBase中叫做分区(Region)。
- StarRocks是分区(Region)后,在分区内部再分桶(Tablet),所以实际上分桶才是最终的负载均衡单元。
- ClickHouse里面又分为分布式表与本地表。分布式表类似一个mycat这样的分库分表代理,将数据代理给本地表。每个本地表都维护着完整表的一部分行,在ClickHouse里面叫做分片(sharding),在本地表中又可以根据不同的字段做分区。
在分布式数据库中,集群中的每台服务器通常会负责多个分区的数据存储,提供分区数据的读写服务。为了充分利用集群的能力,通常需要将数据存储和读写请求均匀分布到每台机器上。如果分区拆分不合理,可能会导致集群中某些服务器的负载很高,另外一些则相对空闲,整体性能不高,甚至引发一些分区的迁移,导致集群雪崩。
总结一下,分区的核心就是均衡,避免热点分区。同时也需要根据分区键优化查询,通过在查询中附带分区键,将读写限定在一个分区的范围。
发现了吗?分区的拆分显得尤为重要。那接下来我们就看一下分布式数据库表分区的几种模式。
分区的几种方式
还是从一个案例开始。假设我们现在需要为物联网传感器IoT设备设计一个基于分布式数据库的数据存储系统,需要按日、月等时间区间统计温度、湿度的趋势。
既然需要按日、月等统计数据,那么最好是数据能够按日、月聚簇存储,这就是我们最常用的一种分区方式,按区间范围分区。

按区间范围分区有多种实现方式。
首先是按时间范围分区。比如前面的IoT传感器数据以日、月、年分区,或者按连续的7天等动态区间分区。这样就可以通过分区键轻松过滤掉不需要的时间的数据,提高查询性能和效率。
其次是按数值范围分区。比如将连续出现的用户ID划分为一个区间,这样同一个用户的数据就会落在一个分区。这种方式适合查询的时候将用户ID作为过滤条件使用,可以将数据范围限定在单个用户的场景。
最后,就是按地理范围分区。比如点外卖时,需要查找周边能够配送的店铺,这个时候就需要用一个矩形或者圆形的区域,把这些能够配送的店铺覆盖上。其实这里还要用到一个叫做geoHash的技术,将经度与纬度做降维处理,这里先不展开介绍。
咱们这个物联网传感器的案例,就很适合按区间范围分区,比如按日期统计数据,或者按用户ID存储数据。对于按日期统计分析来说,需要分析的数据都落在一个或者少数个分区内。而按用户ID存储数据的场景,通常数据的查询也能够基于用户ID定位到目标分区。这样就能够尽量扫描少的数据,提升性能。
但是按区间范围分区也存在一些局限性。比如在用户行为数据表中使用用户ID范围分区。你想想,根据局部性原理,最新的用户一般比较活跃,会产生最多的数据,而最新的分区会将这些连续的新用户ID收入囊中。这就导致这个分区的数据量、请求数都比较大,可能造成热点区间,最终负责这个分区的机器就会压力过大,性能下降。
这时候我们可能就需要另外一种分区方式,Hash分区。

Hash分区通过Hash函数将分区键转化为一串Hash值,然后将Hash值与桶的数量做取模之类的运算,得到桶的位置。
注意,Hash分区选用分区键的时候需要选用一个高基数列,也就是唯一值多的列。这样能够保证Hash后的数据被均匀地分配到各个Hash桶。如果使用单个字段Hash分区后,数据倾斜的情况还是比较严重,也就是某些桶数据量大,而另外桶的数据量少,那也可以选择多个字段作为分区键。但是也不要使用太多的字段,避免影响性能。
Hash分区一般能够保证数据的均匀分布与负载均衡,但是查询的时候同样需要通过分区键Hash后确定分区的位置。所以这种分区方式适合基于分区键的单条或者多条数据查询,不适合区间扫描的数据查询。而且由于Hash后的分区键不可逆,需要额外有字段存储分区键。
你看,两种分区方式都有各自的优缺点,但是我们也可以结合起来一起使用。比如先用范围分区,再Hash分桶。这样就可以消除范围分区的热点问题,同时在一定程度上减少Hash分区不支持区间扫描的问题。
当然还有一些其他的分区方式,其实它们都属于这两者的范畴。比如使用列表分区,用分区键的值列表进行分区,适用于如省、市、区等数据的分区。
那么常用的分布式数据库对分区的支持如何呢?
HBase分区方式
HBase数据是基于行键做字典序排序的,行键就是分区键。那么很显然,HBase使用的就是区间分区的方式。相邻的行键组成了一个个区间,形成分区。
HBase提供了分区的动态拆分能力。当一个分区的存储文件达到了配置的大小,系统就会自动触发分区的拆分,从分区的中间位置或者说行键的中间值,分裂成两个小的分区。
不过HBase的分区自动拆分如果发生在业务高峰期,对系统的性能影响还是比较大的。所以,我们通常要避免采用自动分区机制,在设计表的时候就考虑好如何拆分数据,如何平衡每个分区存储的数据量与读写请求的压力。
比如如下建表语句将表t_region_split预先分为了10个分区,也就是行键开头小于1是一个分区,1-2是一个分区,一直到8-9是一个分区,最后行键开头大于9是一个分区。
HBase表的分区数也不宜太多,一般设为分区服务器数量的1-2倍。当然,表的数据量过大过小了,都可以随时适当调整分区的数量。
前面说到范围分区有可能造成热点分区,那么在HBase中我们该如何解决这个问题呢?
我们还是以用户行为数据表为例,看一下有哪几种解决方式。
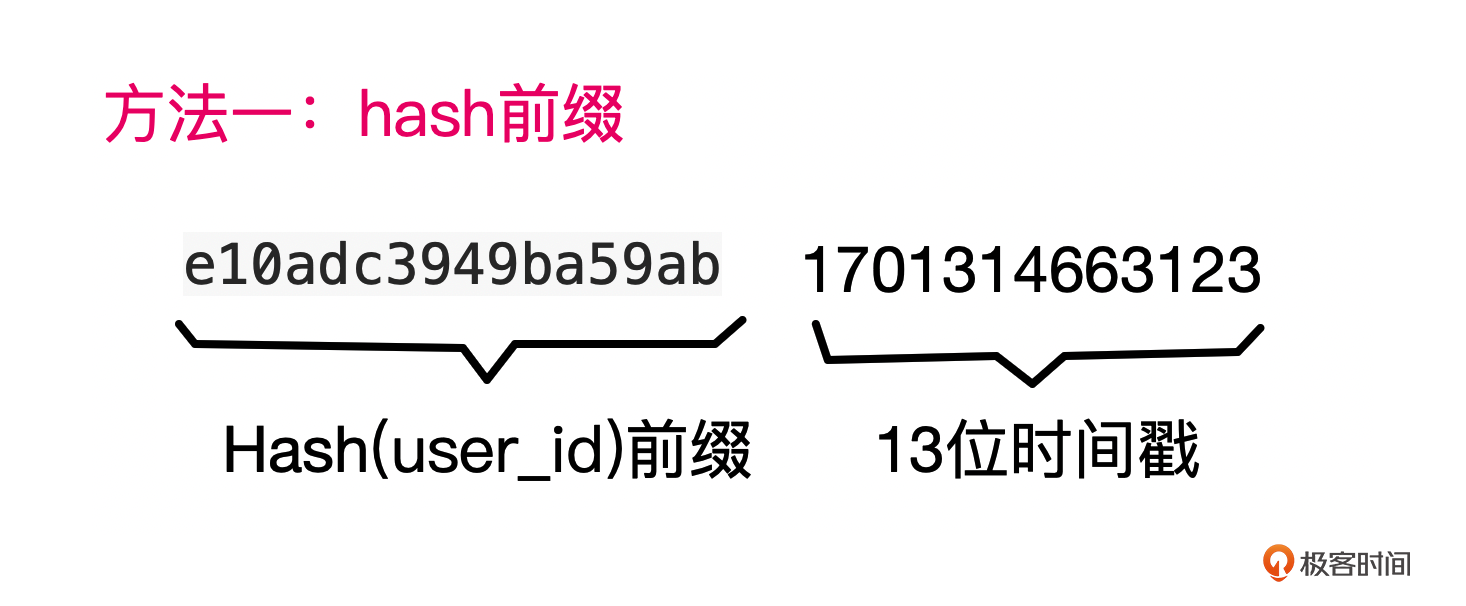
第一种方式,将用户ID Hash后作为行键前缀。
注意,这种方式实际上是基于user_id的哈希值,再加上时间戳得到一个行键,再按行键区间分区。显然,这种方式也和Hash分区一样,不利于区间扫描,但是可以做到基于单个用户数据的区间扫描。不过需要额外的字段存储用户ID,因为Hash不可逆。
第二种方式,将用户ID逆序反转作为行键前缀。一般还会做一个逆序后补齐的动作,这样后续可以将用户ID直接从行键中提取出来。比如下面就是用户ID12345生成的某一条行键记录。
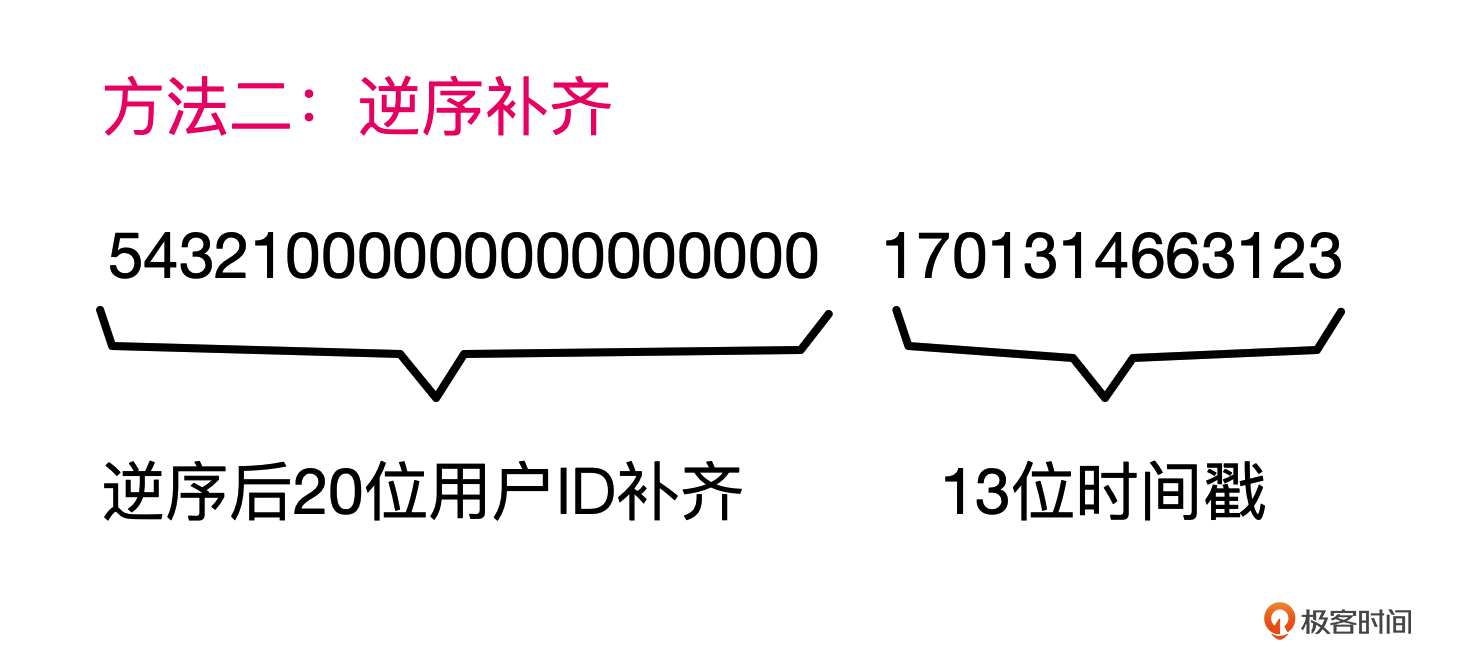
你应该也注意到了,我在行键的后半部分加上了一个13位的时间戳。这是为了保证行键的唯一性。当然,实际使用过程中,用户ID加上时间戳也不一定能保障行键的唯一,还需要加上一些递增的序列等等。
另外提一下,对于HBase来说,行键就是表的唯一索引,跟关系型数据库索引的引导列一样。如果查询中没有将引导列作为查询字段,那就无法命中索引。
比如一个订单表,如果我们以用户ID作为行键前缀,那么在查询条件只有一个订单ID的情况下,就需要全表扫描匹配才能查询到结果了。至于其他的解决方案,在后面的课程我们会详细介绍。
StarRocks分区方式
相比于HBase基于行键的范围分区,StarRocks跟ClickHouse的分区方式则更类似于关系型数据库,可以选择任意字段作为分区键。
StarRocks的3.0以上版本,支持表达式分区、List分区。实际上,这都是设置分区分桶的方式。但是整体逻辑都可以归纳为先分区,再Hash或者随机分桶,也就是一种复合分区的方式。
仍然以前面的用户行为数据为例。在StarRocks中就很简单了,先用用户ID分区,然后基于事件时间戳做Hash。
类似这样:
CREATE TABLE t_behavior (
user_id INT NOT NULL,
event_type INT DEFAULT '10',
event_value VARCHAR(100),
event_time date not null
)
DUPLICATE KEY(user_id, event_type)
PARTITION BY(user_id)
DISTRIBUTED BY HASH(event_time);
前面HBase通过灵活定义、组装行键如反转补齐来避免热点区间。StarRocks只能选用已有的表字段作为分区键,相对来说没那么灵活。但是通过分区后的分桶机制,也可以进一步拆分热点区间。比如将存在热点用户数据的分区,再根据事件时间分桶,同样也可以将这些用户的数据均衡拆分到不同的桶,分配到不同的集群节点来平衡性能。
注意,StarRocks的分区分桶字段定义,同样需要尽量将查询的条件糅合进去。在生产环境下,一个千万级表的复杂查询,查询条件匹配分桶键与不匹配分桶键的情况下,性能可能相差3倍以上。
ClickHouse分区方式
ClickHouse的分区方式跟StarRocks类似,同样支持通过一个表达式将表字段处理后做为分区键,也支持多个字段组合作为分区键。比如前面的用户行为表,基于用户ID和事件类型分区就是下面这样的。
CREATE TABLE t_behavior (
user_id UInt32,
event_type UInt32,
event_value VARCHAR(100),
event_time DateTime
)
ENGINE = MergeTree()
PARTITION BY (user_id,event_type)
ORDER BY event_time;
需要注意的是,ClickHouse中有一个分布式表-分片的概念。实际上,一个ClickHouse表默认情况下由一个服务器节点提供服务,包括数据的存储、读写请求的处理等,即使表做了分区也是如此。
在ClickHouse中,为了利用整个集群的大规模并行计算能力,快速返回查询结果,就需要额外新建一个分布式表,以这个表作为本地表的代理。建立分布式表的时候,需要指定一个分片键(sharding_key),然后ClickHouse就会基于这个分片键再次拆分分区数据。
拆分后的数据叫做分片,然后ClickHouse会将这些分片分布到集群的多个节点,想一想,实际上这个分片是不是可以看做分区后的二次分区呢?
这样分布式表查询的时候,实际上需要查询所有分片所在的节点,然后汇总一份完整的数据,再返回结果。
这种二次分片模式,也类似于StarRocks分区后的分桶。
小结
分区是一个典型的分治法,通过将数据划分成多个小的子集,用来提升数据的处理效率。
一般情况下,关系型数据库的表在超过了2000万行数据的时候就需要考虑分库分表。而在分布式数据库中,一般是基于分区存储文件的大小来决定是否需要拆分分区。
比如HBase建议StoreFile超过10G后需要拆分分区。StarRocks建议分桶后每个分桶数据文件大小在1GB左右。ClickHouse没有官方建议,不过分区文件也不要太大,也不建议太多分区,否则打开太多文件会导致查询性能不佳。
常用的分区方式包括范围分区与Hash分区,不同数据库通过不同的表达式、列表、Hash甚至随机的方式,来将数据划分到不同区间。而分区的核心是基于查询条件来分区,在避免热点区间的同时,查询键能够匹配分区键,从而过滤掉大部分不需要扫描的区间数据,做到精细化的“区间裁剪”。
思考题
分区的核心仍然是提升查询性能,那你有没有碰到过哪些场景下,分区键无法作为查询条件,导致需要扫描全部分区数据的场景?你是怎么优化的?
欢迎你在留言区和我交流。如果觉得有所收获,也可以把课程分享给更多的朋友一起学习。欢迎你加入我们的读者交流群,我们下节课见!
- Hadesu 👍(3) 💬(1)
数据分区的难点之一是,如何保证在数据分区变化期间让写入的最新数据能读出来。这是非常多书,博客都没提及的。希望出一期介绍一下。
2024-06-23