04 数据库都需要事务和MVCC吗?
你好,我是彭旭。
想要保证数据操作的一致性、隔离性和持久性,提高数据库系统的并发性和可靠性,事务与MVCC(Multi-Version Concurrency Control,多版本并发控制)是一个绕不开的话题。
MVCC是一种数据库事务并发控制的方法,能够在数据库系统中高效地处理并发事务。在保证事务的隔离性和一致性的同时,也能提升数据库性能。
不同类型的数据库对事务与MVCC的需求不尽相同。在深入了解不同的需求之前,我们要先来看看不同事务隔离级别下可能发生的一些数据问题。
不同事务隔离级别带来的问题
现在有一个银行账户表u_account,这个表有id、account_id、balance等多个字段。基于这个表在不同的事务隔离级别与并发的情况下,我们看看会出现一些什么样的问题。
第1个问题是脏读。
t1时刻:小明的账户有余额200。事务B开启,向小明的账户转入1000,事务还未提交。
t2时刻:小明基于事务A查询账户,发现现在有1200余额。
t3时刻:事务B发现转错账户了,事务回滚。小明账户余额仍然是200。
t4时刻:小明以为余额有1200,消费300,结果要么导致最后余额账户-100,要么交易失败。
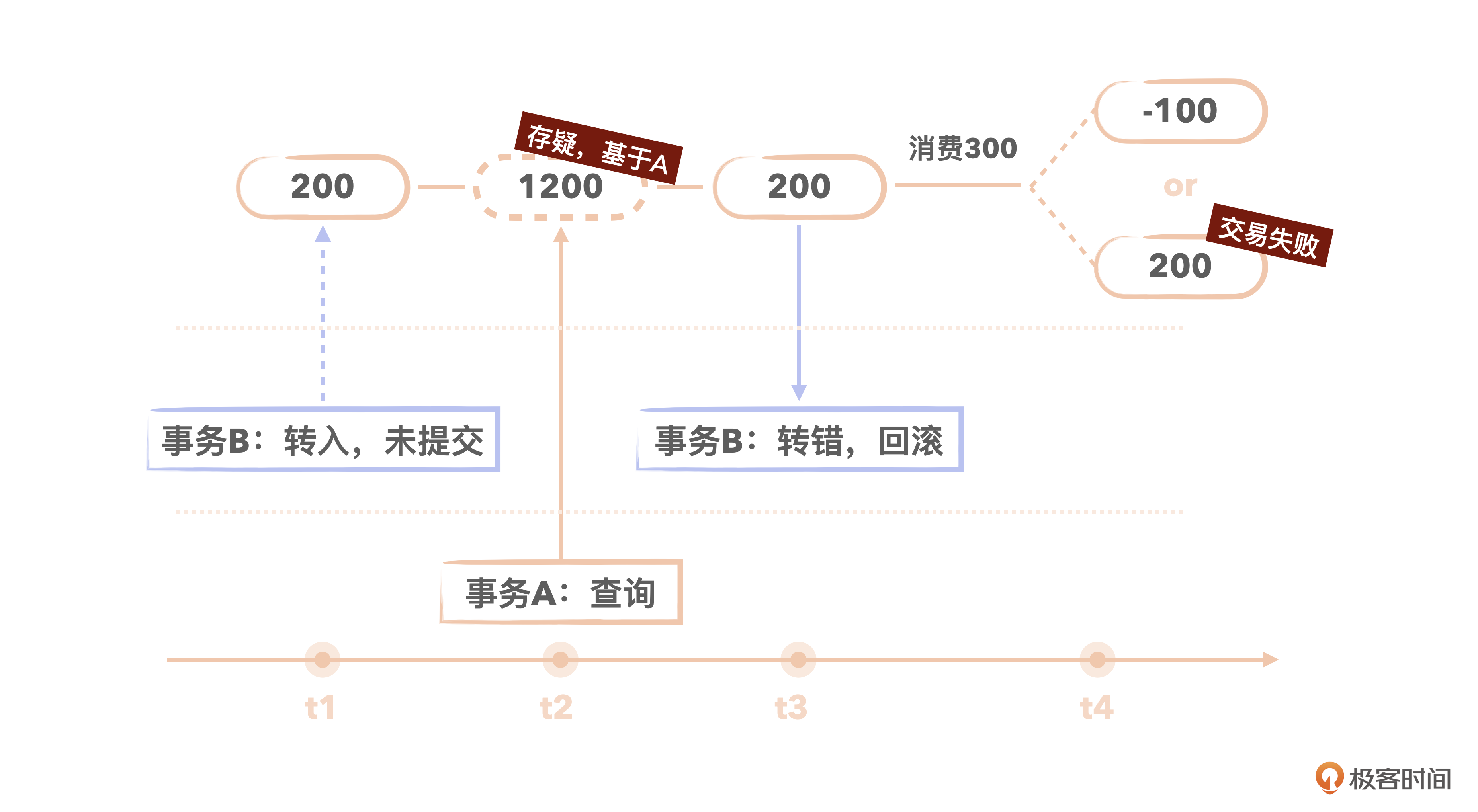
也就是说,脏读导致业务使用的可能是一个中间态的数据,以至于业务的数据出现问题。显然,如果我们的业务系统需要保障数据的准确与一致性,那就应该避免脏读。
第2个问题是不可重复读。
t1时刻:事务C遍历用户余额表,准备每天按余额区间给用户发放利息。首先发放余额在0 - 10000区间的账户,select account_id, balance from u_account where balance > 0 and balance < 10000,假设发现小明余额5000,于是给小明发了5毛钱利息。
t2时刻:小明往账户里面存了20000块,于是小明的balance更新为25000。
t3时刻:事务C开始给余额区间20000 - 30000的账户发放利息了,select account_id, balance from u_account where balance >= 20000 and balance < 30000,发现小明余额25000,符合条件,给小明发了2.5元利息。
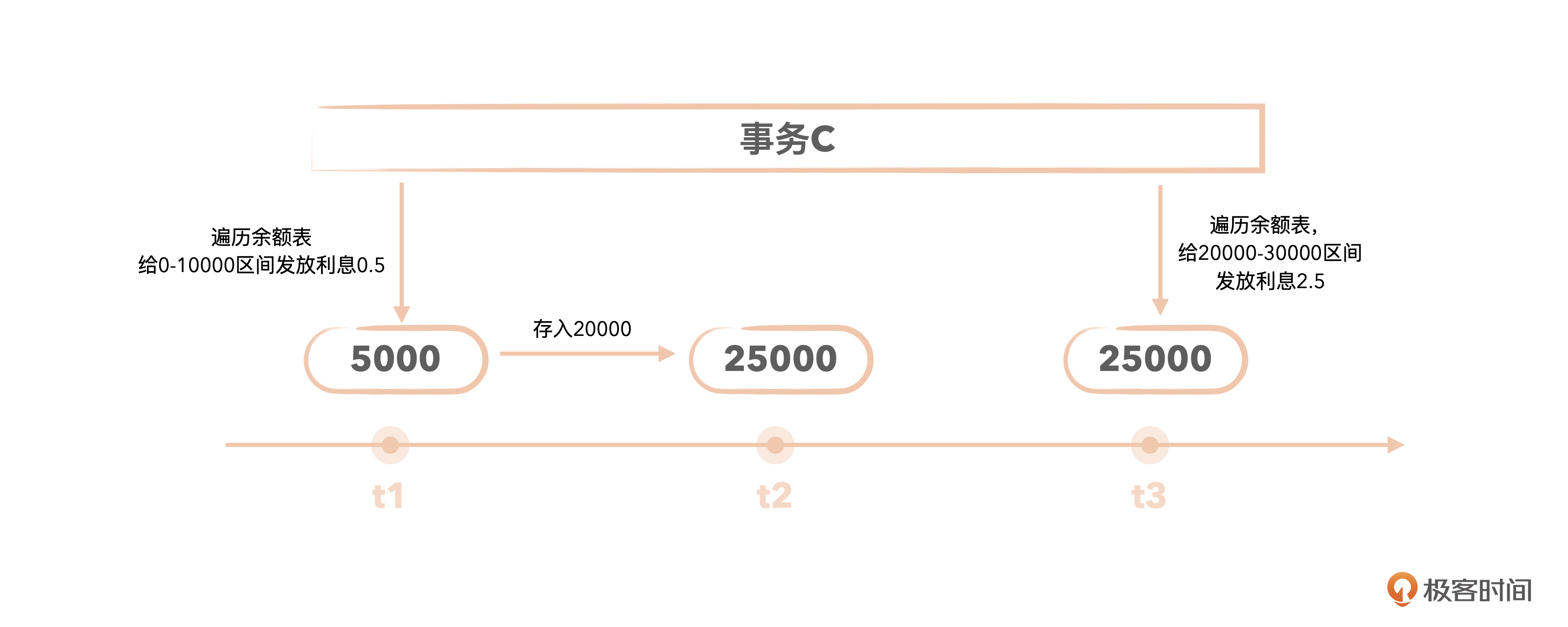
也就是说,银行给小明重复发了利息,至于到底是多发了5毛还是2.5元这个已经不重要了,反正银行产生了资损,得加班数钱盘点对账了。
当然,银行肯定不是用这个逻辑去计算利息的,但如果是我们做一些统计分析的场景,是不是有可能会陷入不可重复读的问题?
不过话又说回来,不可重复读就一定不是我们业务所期望的吗?我们想象一下交易库存校验的场景。
t1时刻:小明基于事务A查询库存,发现某件商品库存还有1件,准备下单。
t2时刻:小红基于事务B查询库存,也发现还有1件,下单成功,库存扣减为0。
t3时刻:小明的事务A下单扣减库存,发现库存已经是0了。
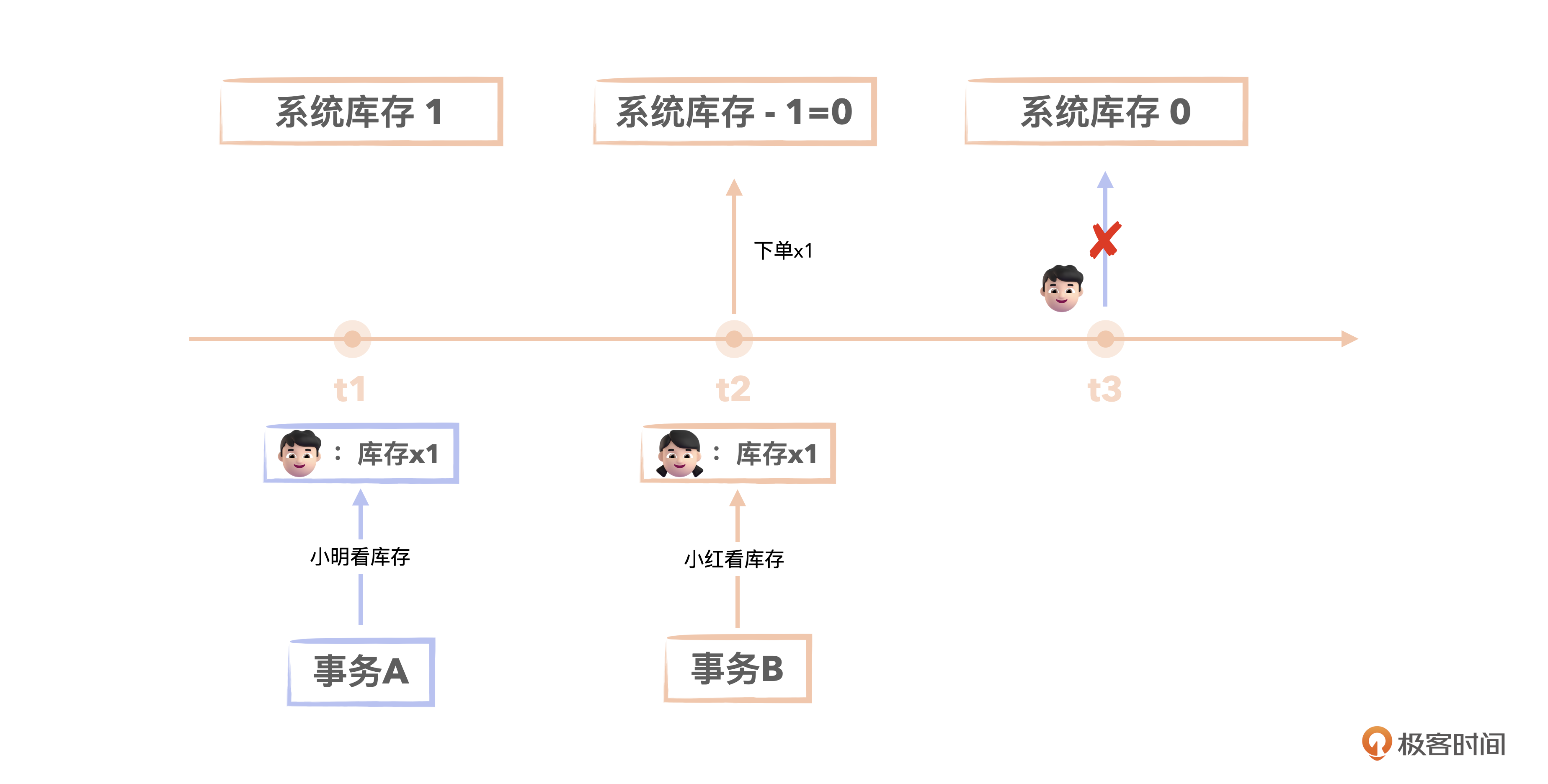
这就是不可重复读。因为t1时刻查询到的库存从1变成了0。因为库存变为0了,所以小明(事务A)不能下单了,这反而是业务所期望的。因为如果小明下单成功了,就超卖了。尤其是在秒杀场景下,可能超卖许多件,造成损失。
这个不可重复读事实上是因为需要更新库存数据了,所以事务A发起了一个当前读,以获取到当前最新的数据。
另外提一下,一般扣减库存的时候还需要加一个乐观锁,也就是在库存表加一个版本列,查询库存的时候将版本列的值查出来,在扣减库存的时候将版本列作为更新条件。这样的话,如果版本变了,库存更新也会失败。这时程序再去重新查询库存,重新下单扣减库存,就能保证数据的一致性了。
第3个问题是幻读。
幻读跟可重复读的区别是,可重复读一般针对的是数据的更新,而幻读针对的是数据的新增。
比如上个例子里,是t2时刻小明往账户存了20000块,如果这一步骤变成小李新建了一个自己的账户,存了20000块,并且事务提交了,那是不是今天也会给小李发放利息了呢?
事实上,因为小李账户刚刚入账,按理是不应该发放利息的,相反应该以发放利息任务开始时刻的账户数据来发放利息,而那个时候小李账户还没有钱。所以如果发放利息,那银行就又资损了。
这就是幻读,第二次读取数据时,读取到了第一次读取数据时不存在的数据。
好,到现在我们一共说了3种问题,看起来都是不好的事情,但你会发现“不可重复读”这个“问题”,在某些场景下也是正确、合适的做法。所以,我们要做的就是给不同的问题分级隔离,理解问题、利用问题,去适配每一种业务需求。
SQL-92标准定义了 4 种隔离级别。
- 读未提交(Read Uncommitted):一个事务可以读取另一个事务未提交的数据,但会出现脏读。
- 读已提交(Read Committed):一个事务只能读取另一个事务已提交的数据。解决了脏读的问题,但仍可能出现不可重复读和幻读的问题。
- 可重复读(Repeatable Read):保证在同一事务内多次读取同一数据时,数据保持一致,比如说同一行数据不会被其他事务修改。避免了脏读和不可重复读,但仍可能出现幻读的问题。
- 可串行化(Serializable):最高的隔离级别,确保事务之间完全隔离,避免了脏读、不可重复读和幻读的问题。但是会影响并发性能。
当然,还有一些其他的事务隔离级别如 Read-Only、写倾斜等,这里不做过多讨论。
我们再回过头来看之前的数据问题。脏读是怎么解决的呢?很简单,在读已提交隔离级别下,解决脏读问题只需要事务在读取数据的时候,过滤掉未提交事务的数据即可。
那不可重复读又应该怎么解决呢?第1个实现方式就是对数据加锁,事务开启后,对第一次读取到的所有数据全部加锁,这样其他事务就无法更新、修改这些数据,后续就能够可重复读,但是这样对性能就影响很大了,读阻塞了所有的写。怎么办呢?
这就要说到第2个实现方式了,也就是我们要讲的MVCC。
MVCC解决了什么问题?
还是从一个场景入手去理解。假设银行有1万个客户,每个客户在这个账户表里面都有一条存款余额记录。某个时刻,银行盘点需要统计现在所有的存款总和以便对账。
现在有一个事务A,用来查询统计这1万条记录的balance总和。为了方便描述,我们假设这个统计操作耗时需要10分钟,那么我们就必须要求这10分钟之内不能有其他事务。如果在这10分钟之内,事务B对这个表的数据有任何更新、新增、删除操作,那么事务A统计出来的数据可能就不准确了。
这种情况就相当于我们把整个账户表给锁住了,不让其他的事务进行操作,业务就暂停了,或者准确一点说是涉及转账、存取款的业务都得暂停,但是查询业务还是可以,也就是读(查询)会阻塞写(转账、存取款)操作。
在这个例子里,盘点存款总和的要求是,从盘点开始到结束这段时间的任意时间点,不管查询多少次,查询到的数据必须都是一致的。也就是说,在盘点事务A开启的时候,就需要给他保留一份数据的快照,事务A后续所有的查询操作都是基于这个快照数据进行的。加锁的方式让数据访问串行化,相当于单车道需要排队过车,太堵了,可能会对性能产生一定的负面影响。
相比之下,MVCC多版本控制则类似于孙悟空一下子拔了一堆毫毛,将自己化身为多个分身,每个分身都能独立应对一个请求,从而提升系统的并发与性能。
在可重复读隔离级别下,开启事务后第一个select语句执行时,就会给这个事务开启一个数据的快照,后续这个事务内的所有数据读取,都是基于这个快照的数据来查询的,也就是快照读。如果在这个事务中涉及了对数据的更新,比如使用了“select … for update”等语句,就会去读取最新的数据(也就是当前读),并对这些数据加锁,这样快照读就转化成了当前读。
好了,总结一下,MVCC的核心原理就是在事务A开始读取数据的时候,能够给它维护一份当前数据的快照。MVCC解决了读跟写相互阻塞的问题,提高了系统的并发性能。
在读已提交隔离级别下,因为事务中每次读取都需要看看是不是有其他事务新提交的数据,所以相当于MVCC在每次读取数据的时候都会为事务生成一个新的快照(也叫Read View)。
而在可重复读隔离级别下,开启事务后第一次读取数据就会生成一个快照,然后在事务过程中一直使用这个快照。
好了,这里就有一个新问题了,这个数据快照怎么实现的呢?
关系型数据库下的MVCC
以MySQL为例,如果同一行数据被多个事务更新了,那么这行数据在数据文件里面的存储就长这样子。
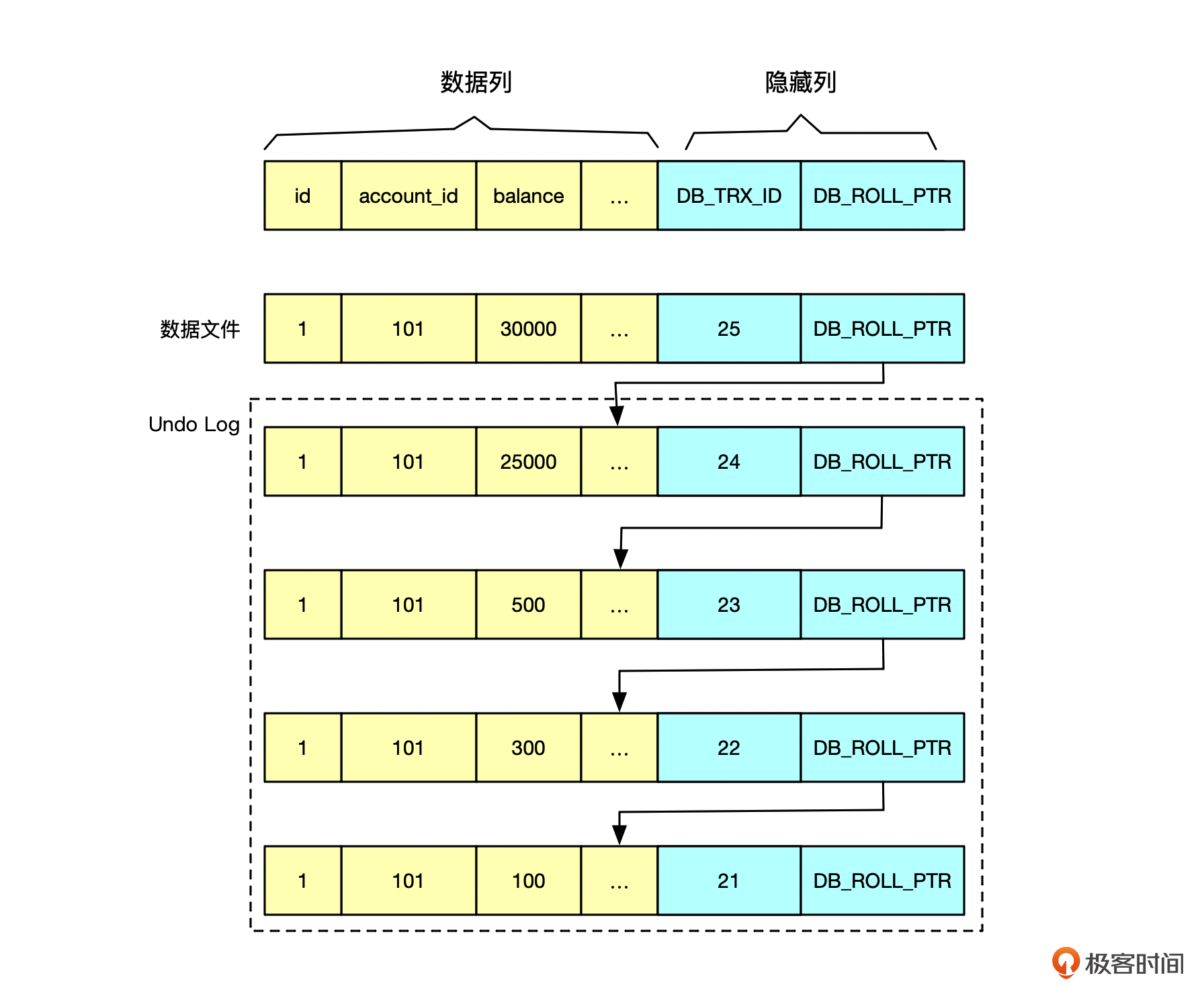
你看,除了最新的一条数据是在MySQL的数据文件里面,旧版本的数据都存储在一个叫做Undo Log的文件里面。
而且,图里的数据库在数据列的基础上为每行数据附加了2列。
第1列是DB_TRX_ID,表示的是这行数据是由哪个事务ID给更新的,是一个递增的ID。
第2列是DB_ROLL_PTR,用来指向这行数据的前一个版本在undo log文件中的位置。如果表没有定义主键,数据库还会自动为这行生成一个唯一的DB_ROW_ID。
显然,如果一个事务开启的时候需要创建一个快照,是不是只需要记录下当前事务ID,假设为X,然后读取的时候,对满足条件的每行数据都读取事务ID<=X 的那行数据就OK了?
事实上也差不多。但是可能有一些事务ID<X的事务在创建快照时还在进行当中,并未提交,所以,这部分事务产生的数据需要在事务X中排除掉。
所以你会发现,其实最后一个快照记录的信息很少。主要有什么呢?
- m_ids :创建快照时,当前数据库中活跃的未提交的事务 id 列表。
- min_trx_id :创建快照时,当前数据库中未提交的事务中最小的事务id,也就是 m_ids 的最小值。
- max_trx_id :创建该快照时,当前数据库中应该给下一个事务的 id 值,也就是全局事务中最大的事务 id 值 + 1;
- creator_trx_id :创建该快照事务的事务 id。
有了快照的这些信息后,一条记录对事务X是否可见,就很简单了。
我们捋一下思路。如果数据行的 DB_TRX_ID<min_trx_id ,那就表示这个版本的记录是在创建快照前已经提交的事务生成的,所以该版本的记录对当前事务可见。
其次,如果数据行的 DB_TRX_ID>=max_trx_id,那就表示这个版本的记录是在创建快照后才启动的事务生成的,所以该版本的记录对当前事务不可见。
最后,如果数据行的 min_trx_id<=DB_TRX_ID<max_trx_id ,就需要判断 DB_TRX_ID 是否在 m_ids 列表中。
这里有两种情况,如果数据行的 DB_TRX_ID 在 m_ids 列表中,说明快照时该数据行的事务仍然未提交,所以该版本的记录对当前事务不可见。而如果数据行的 DB_TRX_ID不在 m_ids列表中,就说明快照时该数据行的事务已经提交,所以该版本的记录对当前事务可见。
好,到了这里,我们已经了解了MVCC的原理与作用。其实在关系型数据库中,MVCC相对比较复杂的,接下来我们看一下HBase这个NoSQL数据库中的事务与MVCC设计。
HBase的事务与MVCC
HBase的分布式特性是数据存储在多个节点上,如果需要用到多行事务或者跨表事务,就会增加复杂性和性能开销,协调多个服务器节点来配合。而大部分情况下,行级事务已经能够满足大多数的数据操作需求了。
所以,HBase只支持行级事务,只能保障一行数据所有列的同时修改成功或者失败。当客户端向HBase服务端提交多行数据的修改时,就有可能某些行成功,某些行失败。HBase会返回每行数据对应的处理状态,把这种异常场景交给客户端来处理。所以,你在批量提交数据变更的时候,一定要检查一下服务端返回的每行数据的处理结果,如果有处理失败的,需要重试。
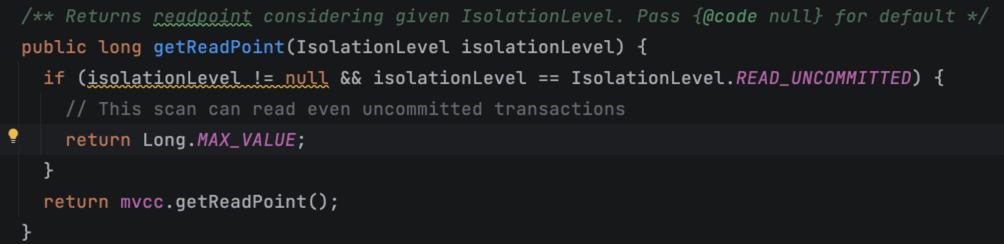
HBase支持两个事务隔离级别,分别是读未提交(Read Uncommitted)、读已提交(Read Committed)。我准备了一段测试代码,你可以通过修改第62行来看一下在不同隔离级别下数据查询结果的异同。
//第62行代码,可以调整隔离级别为 IsolationLevel.READ_UNCOMMITTED
scan.setIsolationLevel(IsolationLevel.READ_COMMITTED);
这段代码里面首先启动了2个数据插入线程,分别批量向表’s_transaction_test’插入了行键相同的1000条数据。
这里注意两点。
- 线程t1插入的数据的值以t1开头,线程t2插入的数据值以t2开头。
- 两个线程并发插入,但是最终结果是所有数据值都为t2开头。
插入数据同时启动一个scan线程,通过修改Scan的事务隔离级别,我们可以发现两点。
- 读已提交隔离级别下,scan到的数据都以t1开头。
- 读未提交隔离级别下,scan到的数据部分以t1开通,部分以t2开头。
为什么是这个结果呢?接着往下看。
对于MVCC来说,HBase有一个天然的优势就是支持数据的多版本。HBase为每行数据保留了一个时间戳的版本号,维护了一行数据的多个版本。但实际上MVCC是基于数据上存储的一个SequenceId序列号。
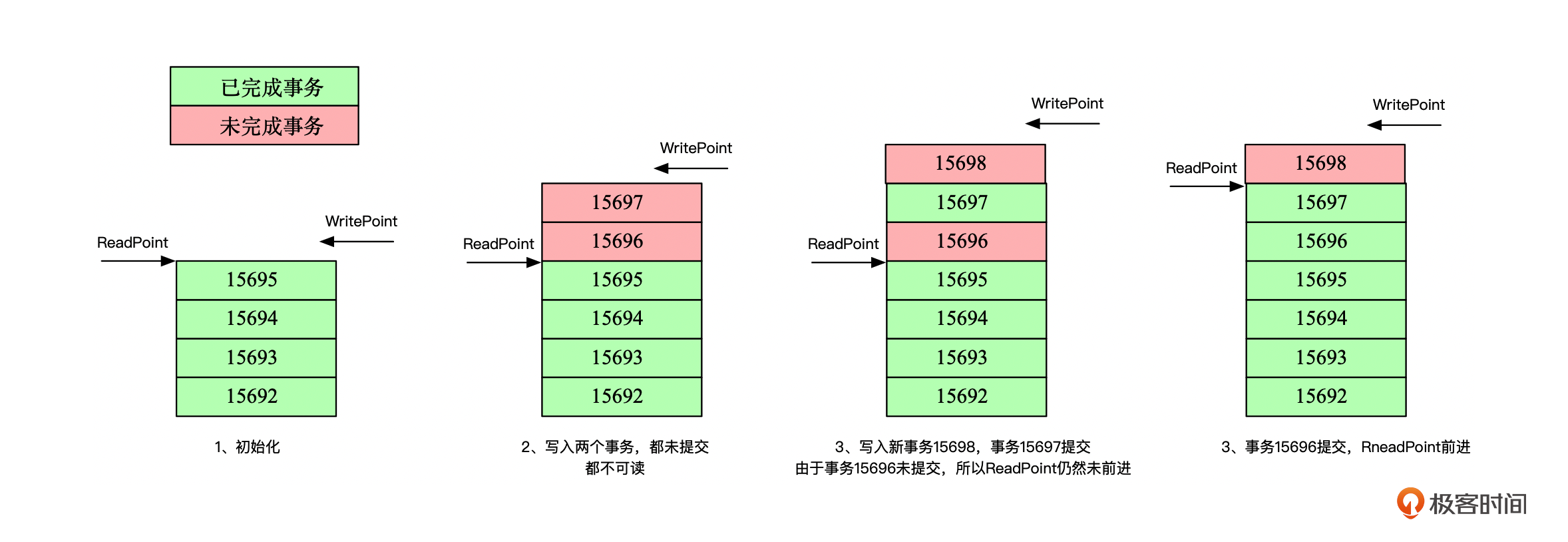
Region初始化的时候,会获取Region存储文件上数据最大的SequenceId(简称为MaxSeqId)作为初始化的最大可读版本,我们称之为ReadPoint。然后以MaxSeqId+1作为WritePoint,分配给接下来写入的事务。
数据写入的时候,就反过来将WritePoint作为SequenceId的写入数据。读取的时候就先获取Region当前可读的ReadPoint,然后在返回的查询结果中过滤掉SequenceId > ReadPoint的数据,也就是后面写入的数据都会被过滤掉。这样就能保证数据在读取开始时就已经确定了。
为了方便你理解,我画了一张图。你可以看到ReadPoint能够往前推进的条件是前面没有碰到未提交的事务。
只要碰到一个未提交的事务,比如步骤3中的事务15696,那么尽管事务15697已经提交了,但是ReadPoint仍然不会前进。这其实是为了保证事务的顺序提交,在读的时候能够保障数据的一致性。
那HBase的事务隔离级别跟MVCC有什么关系,又会有哪些影响呢?
在读未提交隔离级别下,HBase数据读取获取ReadPoint的时候,直接返回了一个Long.MAX_VALUE。所以,只要数据对应的sequeceId小于Long.MAX_VALUE,就都能够返回。所以所有的数据都能够返回。
而在读已提交隔离级别下,ReadPoint就按我们正常的sequeceId推进了。开始读取的时候,事务会获取到这个Region全局的ReadPoint,读取到的数据行的sequeceId如果大于ReadPoint,就会被过滤掉。
到这里,你应该就知道前面的测试代码为什么是这样的结果了。
总结一下,HBase的读写逻辑都很简单,不需要考虑那么多并发的场景,读数据前获取到一个全局的ReadPoint,相当于得到了一个基于ReadPoint时刻的数据快照,读写相互不影响。而写入的时候,会对行键加锁,所以同一行数据同时只有一个线程或者事务更新,这样针对同一行数据的写入,就是一个串行的写入了。
那么对于OLAP的两个数据库,他们对事务与MVCC的支持又是怎样呢?
StarRocks、ClickHouse的事务与MVCC
OLAP分析型数据库其实并不需要支持传统的事务,OLAP型数据库唯一需要考虑的点是,如果我在执行一个很长的数据分析SQL,过程中数据有变化了怎么办?
像ClickHouse会在查询开始时对数据进行快照,然后在查询期间使用这个快照来执行查询操作。其实这也是MVCC,因此,即使在查询期间有新数据插入,查询也会继续使用快照中的数据进行分析。这可以确保查询的一致性和准确性。
像StarRocks在批量导入导出的时候,也能够保障数据的批量导入,一起成功或者一起失败。
小结
事务与MVCC在少数行数据,高并发实时存取的OLTP系统中是不可或缺的。事务,可以用来保障数据的完整性与隔离性。而MVCC可以用来提升并发能力,解决读写相互阻塞的问题。
事务隔离级别的设置对性能的影响比较大,隔离级别越高,性能就越低。比如到了可串行化(Serializable)级别,数据库在同一时间只能支持一个读写操作。
所以,我们需要根据自己的业务场景来选用合适的事务隔离级别。比如Oracle默认事务隔离级别是读已提交,MySQL默认事务隔离级别是可重复读。通常来说,我们业务系统对可重复读的场景需求不多,那你想想,实际使用的时候可不可以把MySQL的事务隔离级别设置为读已提交,从而提升性能呢?
这节课我们还了解了MVCC的原理和它在不同数据库中的表现。我们将要介绍的几个数据库,HBase、StarRocks、ClickHouse是从实时随机存取到批量分析的代表,所以它们对事务的支持需求也越来越弱,甚至在ClickHouse中,可以说不支持事务。
了解数据库的并发机制,可以帮助我们更顺利地调优系统,在出现一些并发导致的数据问题时,知道如何发现与解决问题。
举个例子,有个统计任务在每天凌晨0点开始统计数据,事务隔离级别为读已提交,但是经常发现会漏掉几条接近0点的数据,你知道是什么原因吗?
其实就是因为接近0点写入的数据,创建时间可能是23:59:59。但是统计任务执行的时候这行数据可能还未提交,在读已提交级别下,统计任务是没法读取到这行数据的,所以这行数据就被漏了。
思考题
你碰到过哪些因为事务隔离级别或者MVCC机制引起的数据不一致或者异常情况吗?
欢迎你在留言区和我交流。如果觉得有所收获,也可以把课程分享给更多的朋友一起学习。欢迎你加入我们的读者交流群,我们下节课见!
- Hadesu 👍(3) 💬(1)
如果老旧的undolog被删除了,会影响mvcc的正确性吗?
2024-06-23 - 注意力$ 👍(0) 💬(0)
请问MySQL的undo保留周期由那个参数决定呢
2025-02-08 - 蓝山 👍(0) 💬(0)
Oracle中ora15333应该属于这种情况
2024-09-24 - ls 👍(0) 💬(0)
感觉各种数据库 oracle ,mysql ,ch 事务一致性实现方式大的方向都差不多。
2024-08-09