02 分布式存储数据结构LSM,如何优化读写性能?
你好,我是彭旭。
当前数据库都使用硬盘来持久化存储数据。市面上的硬盘主要分为SSD固态硬盘和HHD机械硬盘。其中,SSD固态硬盘读写性能高,但是价格贵,传统关系型数据库用得比较多。
大数据、分布式存储由于数据量大,使用SSD硬盘会导致存储成本过高。所以,大多数分布式存储引擎,比如HDFS都使用HDD机械硬盘作为数据节点的存储设备。
那么问题来了,HHD的读写性能可不像SSD那么高。数据如果排序后存储在数据文件里,直接更新的时候,可能会涉及磁盘的随机IO,使用HDD硬盘会导致性能问题。
那么,这些存储引擎怎么才能在使用机械硬盘存储的情况下,解决更新数据可能需要随机写入,导致性能不好的情况呢?
在大数据领域,针对数据存储出现了很多用来优化随机读写或者说平衡读写性能的技术,从文件的组织形式来说可以分为两种。
第一种,Copy-On-Write。这个类似Java并发编程里面的CopyOnWriteArrayList,数据新增、更新、删除的时候,会去找到数据应该归属的文件,将这个文件用最新的内容覆盖后重写一个新的文件。
这种模式对读非常友好,读取的时候只需要读取最新的文件即可得到最新的内容。但是写入的时候成本很高。因此,它适合写入不多,读取频繁的场景。
第二种,Merge-On-Read。数据写入的时候直接写入新的文件,所以读取的时候可能需要Merge多个文件来获取最新版的数据。这种模式对写入友好,但是读取的代价较高,因此适合写多读少的场景。
当然还有一些如Delta-Store、Delete-And-Insert也在平衡读写的性能,基本都是牺牲一些写入的性能,构建一些索引、排序后让读取性能提升。
而我们今天要说的LSM(Log-Structured Merge-Tree,日志结构合并树),利用了MOR(Merge-On-Read)写入的优点,同时又通过Compact来避免了MOR读取时需要读取多个文件的缺点,被很多存储引擎用来提升写入性能。

理解了LSM,一定会让你更快速地定位各种问题原因,比如写入放大、读取延迟或者合并策略配置不当,甚至你也可以在你自己的一些应用设计中采用类似的架构,用各种手段平衡读写、平衡时间与空间、平衡性能与准确性等等。
接下来,我们就详细说说HBase是怎么用LSM提升读写性能的。
LSM怎么提升读写性能?
LSM树的出现是为了解决磁盘随机I/O速度过慢的问题,将数据的随机磁盘I/O读写都转化为内存的读写,然后通过批量写入磁盘和延迟合并操作来提高写入性能。
我们先看下LSM的架构。
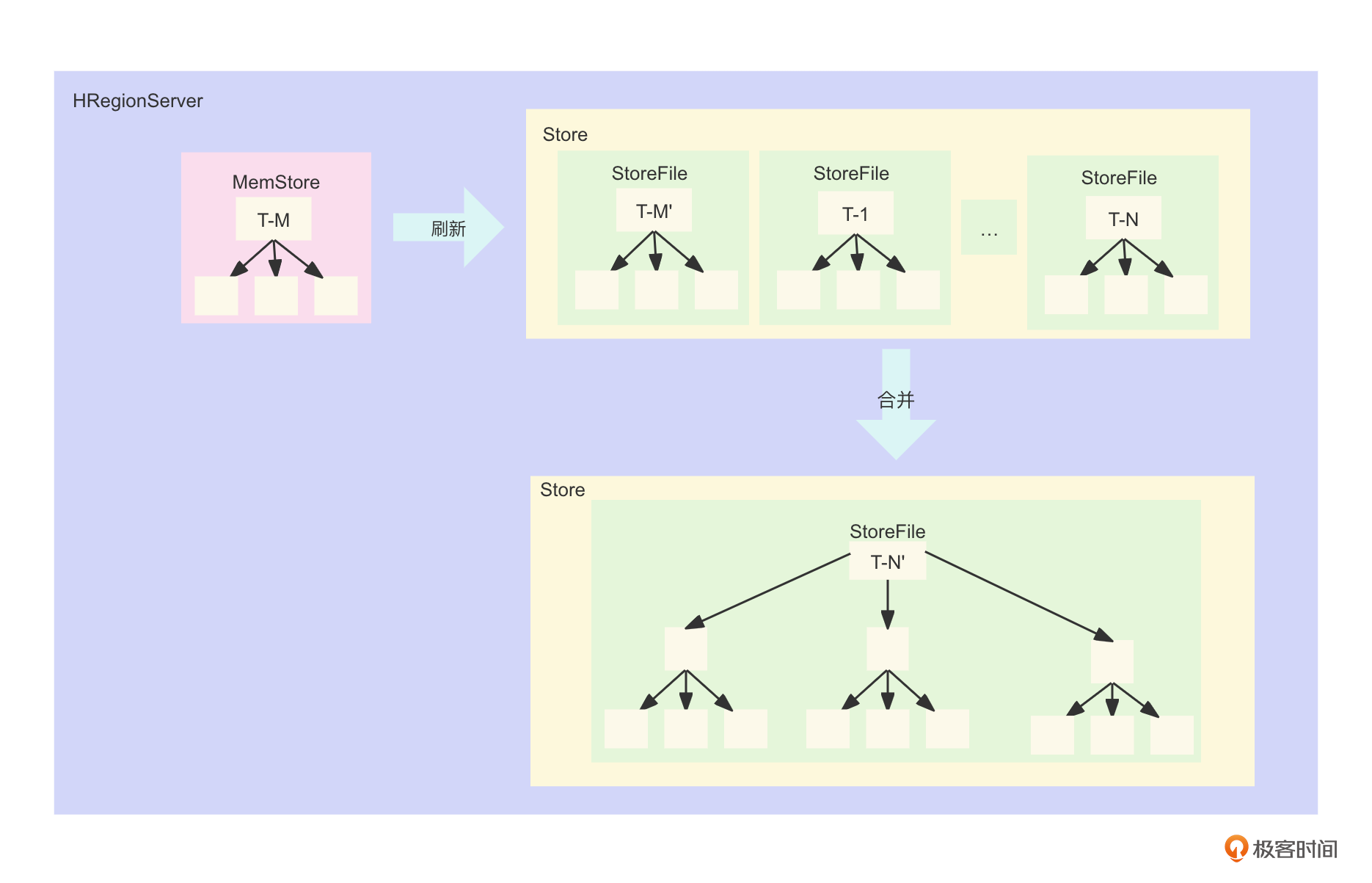
你看,HBase数据写入的时候,无论是新增数据还是更新删除数据,都会先写入内存中称之为MemStore的组件。而MemStore在内存中会使用一个有序的数据结构,比如跳表,给这些写入的数据排好序。
当MemStore的大小达到配置的阈值或者经过一定时间后,MemStore就会将数据刷新输出到磁盘。
这里会是一个磁盘的批量顺序写入,所以速度很快。又因为数据已经排好序了,所以后续数据的读取也能够基于索引去做二分查找等等这样的快速读取。
这样,HBase数据写入的时候,更新、删除数据需要的磁盘随机I/O转化成为了内存的读写与磁盘的顺序写入,而内存的写入基本上是纳秒到微秒级别。所以,数据的写入性能就有了一个巨大的提升。
注意,这个对写入性能的优化带来了两个新的问题。
第一个问题,是数据先写入内存。但如果内存因为程序崩溃或者断电导致数据丢失,又该怎么办呢?
类似关系型数据库的Redo日志,LSM也引入了WAL(Write-Ahead-Log,预写式日志)来解决这个问题,数据写入MemStore之前,会将对数据的操作(如Put、Delete等操作)先记录到一个日志文件,也就是WAL预写入日志文件,这个文件以追加的形式批量顺序写入磁盘,所以速度很快,当程序崩溃导致内存MemStore数据丢失后,HBase RegionServer会重放这个WAL日志文件中的数据操作,在内存中重建MemStore的数据。
第二个问题,随着MemStore刷新输出到磁盘形成了StoreFile,这些StoreFile的数量增长得越来越多,可能会影响查询性能,怎么处理?
其实,HBase在后台引入了一个文件合并Compact机制。Compact又分为Minor Compact和Major Compact。
Minor Compact 被触发的情景较多,比如StoreFile文件大小达到配置的compact阈值、小文件过多等等。这时候,Minor Compact会挑选尽量多的小文件来合并,目标是减少文件的数量,移除一些多版本过时的数据。这样可以让数据读取的时候可以扫描尽量少的文件,提升读取效率。
Major Compact 则是根据配置参数hbase.hregion.majorcompaction,按固定的间隔时间触发的。Major Compact会将所有的StoreFile文件合并成为一个大的文件,在合并的过程中会清理被删除、过期的数据。这里要注意,Major Compact对系统的性能影响比较大,所以一般不能在业务高峰期执行,需要用程序脚本在业务非高峰期触发。
正常情况下Minor Compact对性能影响较小,但是如果频繁Minor Compact或者多个Region同时进行Minor Compact,也可能因为资源竞争从而影响集群性能,所以也需要合理地配置compaction相关参数。
咱们这门课要讲到的HBase就提供了多种Compact策略,如StripeCompactionPolicy、DateTieredCompactionPolicy、RatioBasedCompactionPolicy等,但默认的Compact策略是RatioBasedCompactionPolicy,它的逻辑是合并尽量多的小文件,这样对性能的提升最大。
我用一个简化版的代码来介绍一下RatioBasedCompactionPolicy。
先介绍一下影响到compact策略的几个配置项。
- hbase.hstore.compaction.ratio:合并比例参数,默认为1.2,假设为R。
- hbase.hstore.compaction.min(2.0以下版本为hbase.hstore.compactionThreshold):最小待合并文件数,默认为3,假设为A。
- hbase.hstore.compaction.max:最大待合并文件数,默认为10,假设为B。
- hbase.hstore.compaction.min.size:最小合并文件总大小,默认为128M,假设为C。
这里以R=1.2,A=3,B=10,C=100,待合并的文件为L=[8200, 4300, 160, 150, 80, 70, 30, 20, 5] 为例子,文件数组的值为待合并文件的大小,以文件从大到小排序,一般来说越老的文件越大。
这个策略挑选文件合并的步骤是这样的。
- 计算一个待合并文件总大小的数组fileSizes[i,i+B-1) ,得到X = [13015, 4815, 515, 355, 205, 125, 55, 25, 5]。
- 遍历L,从旧到新文件,逐一判断文件大小是否满足 L[i].fileSizes() > Math.max(C, (X[i + 1] * R)) ,当条件不满足后,i即为待合并的文件开始位置,该步骤是为了过滤掉大的文件,此处得到i=2,因为L[2].fileSize()=160 < 355*1.2。
- 最后得到需要合并的文件列表为L.subList(2,L.size-1),得出结果为 [160, 150, 80, 70, 30, 20, 5]。
简化后的代码片段如下所示,你也可以在我的代码仓库找到所有源代码。
package com.mt.hbase.chpt07.compact;
import java.util.Arrays;
import java.util.LinkedList;
import java.util.List;
public class RatioCompactPolicy {
public static List<Integer> applyCompactionPolicy(List<Integer> candidates,
boolean mayBeStuck) {
int minFileToCompact = 3;
int maxFileToCompact = 10;
int minCompactSize = 100;
double ratio = 1.2;
int start = 0;
// get store file sizes for incremental compacting selection.
final int countOfFiles = candidates.size();
long[] fileSizes = new long[countOfFiles];
long[] sumSize = new long[countOfFiles];
for (int i = countOfFiles - 1; i >= 0; --i) {
fileSizes[i] = candidates.get(i);
// calculate the sum of fileSizes[i,i+maxFilesToCompact-1) for algo
int tooFar = i + maxFileToCompact - 1;
sumSize[i] = fileSizes[i] + ((i + 1 < countOfFiles) ? sumSize[i + 1] : 0) - ((tooFar
< countOfFiles) ? fileSizes[tooFar] : 0);
}
while (countOfFiles - start >= minFileToCompact &&
fileSizes[start] > Math.max(minCompactSize, (sumSize[start + 1] * ratio))) {
++start;
}
if (start < countOfFiles) {
System.out.println("Default compaction algorithm has selected " + (countOfFiles - start)
+ " files from " + countOfFiles + " candidates");
} else if (mayBeStuck) {
// We may be stuck. Compact the latest files if we can.
int filesToLeave = candidates.size() - minFileToCompact;
if (filesToLeave >= 0) {
start = filesToLeave;
}
}
System.out.println("sumSize=" + Arrays.toString(sumSize));
System.out.println("start=" + start);
candidates.subList(0, start).clear();
System.out.println("fileToCompact =" + candidates);
return candidates;
}
public static void main(String[] args) {
int[] candidateIntArray = new int[]{8200, 4300, 160, 150, 80, 70, 30, 20, 5};
List<Integer> candidateList = new LinkedList<Integer>();
for (Integer candidate : candidateIntArray) {
candidateList.add(candidate);
}
applyCompactionPolicy(candidateList, true);
}
}
代码执行如下图所示。
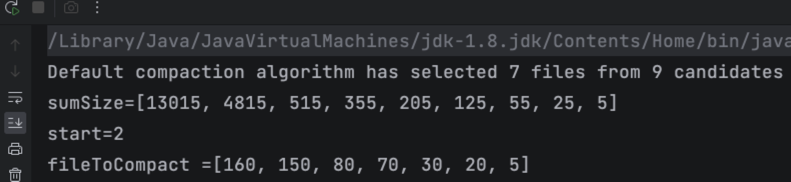
从结果我们也可以看出,这个策略挑出了待合并文件中的小文件,过滤掉了大文件。也就是从文件列表 L=[8200, 4300, 160, 150, 80, 70, 30, 20, 5] 中过滤掉了8200、4300这两个大文件,而挑出其他剩下的小文件做了合并。
你可能注意到了,Compact过程中其实存在一定的写放大,尤其是刚才提到的Minor Compact和Major Compact这种分层的设计。
我来详细解释一下。在一行数据从MemStore刷新输出到StoreFile后,Minor Compact会将这行数据从一个StoreFile文件读取出来,合并后写入一个稍大的StoreFile文件,然后继续经过多次合并,最后在Major Compact过程中,所有的文件又被合并成为一个总的StoreFile。
这个过程循环往复,这行数据就被读取、写入了很多次,这就是我们说的写放大。写放大可能会影响系统的性能,甚至影响存储介质的寿命。这也是我们提升读性能必然会带来的一些负面影响。
但是类似写扩大的写扩散模型,在某些场景下会是一个非常优秀的设计,比如微信朋友圈的设计。
布隆过滤器
此外,为了进一步提升数据读取性能,减少读取数据时需要扫描的StoreFile数量,HBase还引入了布隆过滤器来过滤掉一些明确不存在数据行的文件。
设想一下,你走进了一个巨大的图书馆,想要找一本特定的书。这个图书馆非常庞大,拥有成千上万的书籍,但没有一个标准的目录系统。相反,它使用了一个特殊的“排他目录”。这个“排他目录”不能告诉你“书在图书馆”或者书架的精确位置,但它可以迅速告诉你图书馆里有没有这本书。
当你询问“排他目录”一本特定的书是否存在的时候,它会进行一系列的快速检查。如果所有检查都显示这本书可能在图书馆里,那么你就得亲自去书架上确认书的存在。但如果“排他目录”的结果显示图书馆不存在这本书,你就可以立即确定图书馆中没有这本书,从而节省了很多时间。
例子里面的“这本书”,在HBase里一般对应数据的行键。有些表如果使用ROWCOL作为布隆过滤器的话,那么“这本书”就对应数据的行键加列名。
至于这个“排他目录”,就是布隆过滤器。使用了布隆过滤器后,HBase的每个StoreFile里面都会存储一个“排他目录”。图书馆一系列的快速检查,其实就是对“这本书”进行一系列的hash函数计算得到一个对应的值,然后再检查hash表上对应的桶是否存在已经写入的值。
布隆过滤器可以非常快速地检查出一个元素是否在一个集合中。不过要注意一点,当布隆过滤器说某样东西不在集合里时,它是100%正确的;但当它说某样东西可能在集合里时,它可能是错误的,这种情况称为“假阳性”。
换句话说,就是有时布隆过滤器会告诉你某样东西可能存在,但实际上并不存在,就像“排他目录”可能错误地暗示一本书是在图书馆里,还需要你亲自去书架上确认有没有这本书一样。
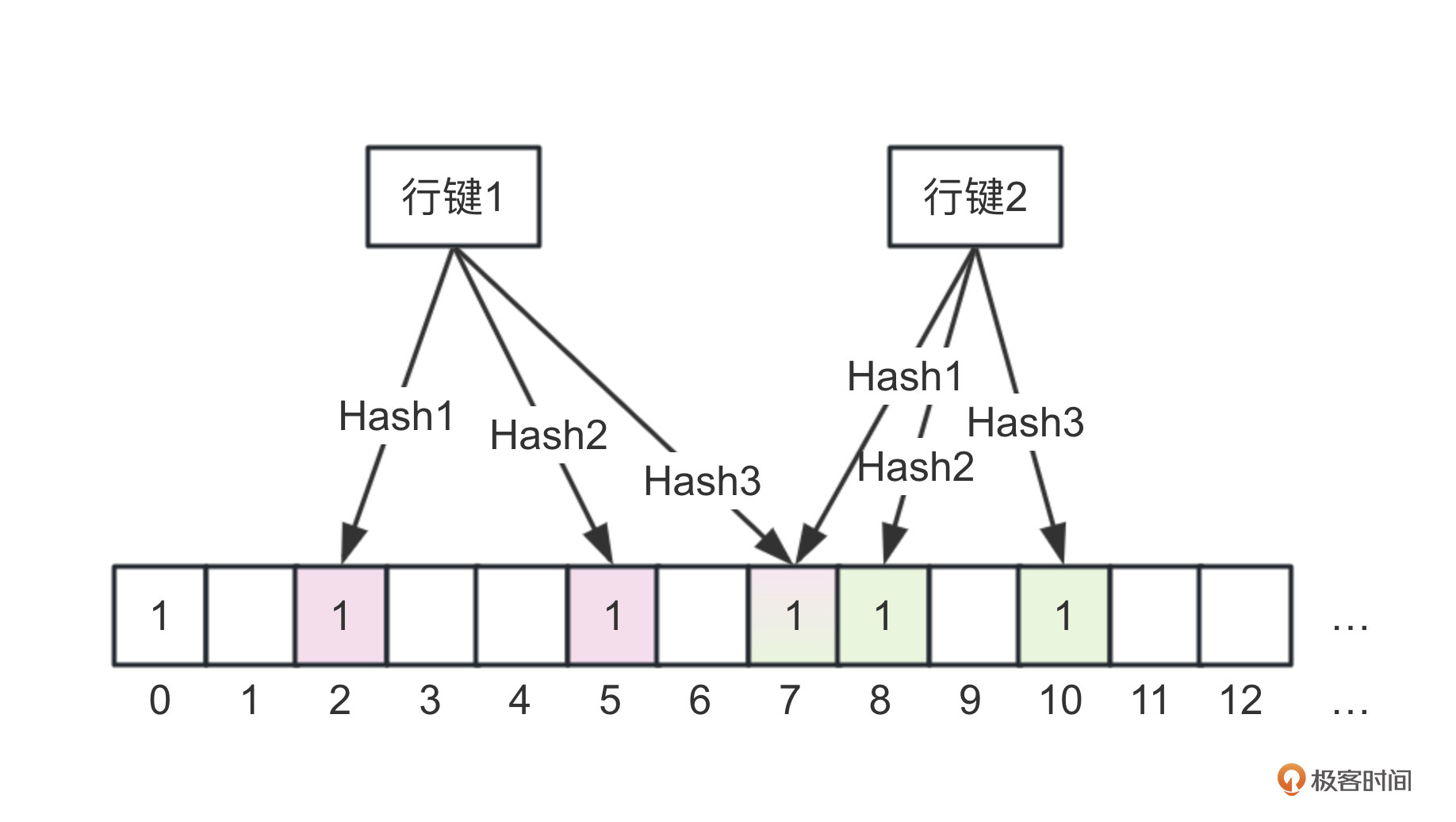
那为什么会出现这种情况呢?我们看上面这张图,布隆过滤器使用一个位图作为数据存储结构。
以一个基于行键的布隆过滤器为例。
数据写入的时候,用数据的行键,这里是“行键1”进行了一系列的hash计算,比如图中进行了Hash1、Hash2、Hash3总计3个函数计算,将每个hash函数计算结果映射到了位图的一个bit位或者说hash桶。这里我让“行键1”映射到了下标为2、5、7的3个bit位。
数据查询的时候,同样将行键进行一系列的hash运算得到映射到位图的bit位,然后检查位图对应的所有bit位是不是都为1。如果有任意1个bit位数据不为1,即表示数据不存在。如果为1,则需要进一步扫描文件查询数据,因为有可能位图中某些bit位是其他行键hash后写入的。
所以,布隆过滤器的位图长度不能太小。如果是过小的位图,那么很快所有的 bit 位都会被置为1,那么查询任何值都会返回“可能存在”,起不到过滤的目的了。
同时,哈希函数的个数也需要权衡。个数越多,则布隆过滤器 bit 位置变为1的速度越快,且布隆过滤器的效率越低;如果个数太少的话,误报率就会变高。
比如使用2个hash函数将行键hash后映射到2个bit位,这两个bit位可能很快就被其他数据hash后写入了。这样就导致布隆过滤器提示数据“可能存在”的误报。但是如果使用了10个hash函数将行键映射到10个bit位,那么这10个bit位全部被其他数据写入的概率就会大大降低了,从而降低了误报率。
小结
数据的写入一定是需要持久化到磁盘才能算是成功,某些场景下甚至要写入多个副本才算成功,但是磁盘的随机写入性能堪忧,所以很多数据存储引擎都会采用各种手段,消除或者延后随机写入,转化为顺序写入。
HBase就通过LSM来将磁盘的随机写入转化为内存的读写以及磁盘的批量顺序写入,大大提升了数据写入的性能。所以,HBase非常适合批量写入较多、查询较少的场景。
同时,HBase在数据读取上也做了很多优化,比如后台Compact数据合并减少需要扫描的文件数量,使用布隆过滤器来排除扫描肯定不存在数据的文件。
当然,HBase还有很多性能优化手段,比如使用缓存、对数据进行编码、压缩等。总体来说,HBase通过这些设计,即使在使用机械硬盘的情况下,也能够实现毫秒级的响应。
思考题
你知道微信朋友圈的设计,是如何使用写扩散模型来提升读取性能的吗?
欢迎你在留言区和我交流。如果觉得有所收获,也可以把课程分享给更多的朋友一起交流学习。欢迎你加入我们的读者交流群,我们下节课见!
- zheng 👍(7) 💬(1)
朋友圈存储可能以看的人为key,也可以以发的人为key。A发的B看。 把A发的一起存在文件a的话,B刷的时候就需要查询所有朋友(ABCDE)发的在以时间线合并。这样肯定是随机读。好处是写的性能高。 如果把B能看的存一起的话,那看的时候就拿自己的文件就行,顺序读。但是如果A删除了或者更改权限,那就复杂一些,但这是低频操作
2024-06-21 - xzy 👍(3) 💬(1)
思考题:当一个人发朋友圈时,这个朋友圈的信息会被写入其每个好友的收件箱中;然后每个人读取自己的收件箱就可以看到自己好友发的所有的朋友圈内容了。 老师有没有兴趣讲讲timeline数据库的设计。
2024-06-17 - 完美坚持 👍(1) 💬(1)
### 微信朋友圈的写扩散模型 在微信朋友圈的设计中,写扩散模型被广泛应用以提升读取性能。这种模型的核心思想是,当一个用户发布朋友圈时,系统会将这条朋友圈的信息写入每个好友的收件箱(或时间线)。这样,每个用户在查看朋友圈时,只需读取自己的收件箱,避免了大量的随机读操作。以下是详细解释: #### 基本思路 - **以发的人为主**: 当用户A发布一条朋友圈时,这条信息会被写入一个存储单元,该单元以A为key。这种方法写入效率高,但读取时需要合并多个用户(朋友们)的数据,导致大量的随机读。 - **以看的人为主**: 当用户A发布一条朋友圈时,这条信息会被写入每个好友B、C、D等的收件箱中。这样,当B查看朋友圈时,只需顺序读取自己的收件箱即可。这种方法优化了读操作,减少了随机读。 #### 实现细节 1. **发布时写扩散**: - 用户A发布一条朋友圈,系统将这条信息异步写入每个好友的收件箱。 - 由于朋友圈不需要实时呈现,异步写入可以减少发布操作的延迟。 2. **读取时顺序读**: - 用户B查看朋友圈时,只需顺序读取自己的收件箱,获取好友们发布的所有朋友圈内容。 - 这种方式优化了读性能,因为顺序读比随机读更快。 3. **删除和权限变更**: - 如果用户A删除了一条朋友圈或修改了其权限,系统需要更新每个好友的收件箱。 - 由于删除和权限变更是低频操作,虽然这种操作复杂,但整体影响较小。 ### 优缺点分析 #### 优点 1. **提升读性能**: - 通过将发布的朋友圈信息写入每个好友的收件箱,用户在读取时只需顺序读取自己的数据,从而大大提升了读取性能。 2. **简化读操作**: - 每个用户只需读取自己的收件箱即可看到所有好友的朋友圈,避免了从多个存储单元中读取数据并合并的复杂过程。 3. **减少随机读**: - 顺序读取用户的收件箱可以显著减少磁盘的随机读操作,提高读取速度和系统性能。 #### 缺点 1. **写放大**: - 每次发布一条朋友圈,都需要将信息写入多个好友的收件箱,导致写操作的放大。这会增加系统的写入压力,并可能影响存储介质的寿命。 2. **数据一致性复杂**: - 删除或修改朋友圈信息时,需要同步更新每个好友的收件箱,增加了数据一致性的复杂性和维护成本。 3. **存储空间**: - 由于每条朋友圈信息需要在多个好友的收件箱中保存副本,存储空间需求较大。
2024-07-07 - -Hedon🍭 👍(1) 💬(1)
Copy On Write 读取的是旧数据还是新数据?
2024-06-17 - Hadesu 👍(2) 💬(1)
lsm提升读性能的做法比本文介绍的更加复杂。
2024-06-23 - 完美坚持 👍(0) 💬(0)
总结 微信朋友圈的写扩散模型通过在发布时将数据写入每个好友的收件箱,优化了读取性能。这种设计在读取操作频繁的社交网络场景中非常有效,但也带来了写放大和数据一致性管理的挑战。整体上,这种模型在提升用户体验和系统性能方面表现出色,尽管需要在存储空间和写入压力方面进行平衡。
2024-07-07