20 数据库方案设计:如何设计运营搭建平台的数据库?
你好,我是杨文坚。
上节课我们学习了运营搭建平台的全栈项目搭建,了解了数据库相关的内容,但是没有深入到如何根据项目做数据库方案的设计,今天我们就进一步学习数据库设计理念,完善课程项目的数据库方案设计。
为什么要用一节课来掌握项目的数据库方案设计呢?这是因为在Web服务项目里,只要数据库设计好,项目设计工作就基本完成一半了。
我们任何项目、任何业务逻辑的功能实现,最终都是用代码编写的程序来操作业务功能的数据,也就是说,所有功能最后都是操作数据库的读写。所以,数据库的设计等于是业务功能的设计。只要数据库设计好了,业务功能设计也就基本成型。
那么如何做项目的数据库操作方案设计呢?我们首先要理解数据库设计的技术规范。这个“技术规范”,在业界有个专业术语“数据库设计范式”。
什么是数据库设计范式?
数据库设计范式,简称“数据库范式”,也经常简称“范式”,英文为Normal Form,简称NF,大部分情况是面向“关系型数据库”的设计规范。
在计算机相关的教科书里,数据库设计范式是这么定义的。
“在关系型数据库里,符合某一种级别的关系模式的集合,表示一个关系内部各属性之间的联系的合理化程度”
简单理解就是,如何用合理的方式来设计项目的数据库,让数据库里各种“表”的“关系”更加清晰和简约,减少数据冗余,便于管理。
根据严格等级划分,通常分成六种范式(或者理解六种范式级别),从上到下分别为。
- 第一范式,简称1NF
- 第二范式,简称2NF
- 第三范式,简称3NF
- 巴斯-科德范式,Boyce-Codd Normal Form,简称BCNF
- 第四范式,简称4NF
- 第五范式,简称5NF
如果数据库设计范式再深入细分或提升严格等级,就不止这六种范式,还可以分成域键范式(Domain-Key Normal Form,简称DKNF)、第六范式(简称6NF)等等。
虽然提到这么多范式,但实际开发工作中常用的就是前三个范式,第一范式、第二范式和第三范式,我们逐个看一看。
第一范式,是指在关系型数据库的表中,每一个字段都是原子性的,也就是最小原子,不能再拆分。看个具体例子,假设运营搭建平台要做一个操作员工用户的数据库表。

这个“员工用户表”内容就符合了第一范式,因为每个字段也就是表中的每一个列,不能再拆分,如果换成下面的表,就不满足数据库设计第一范式。
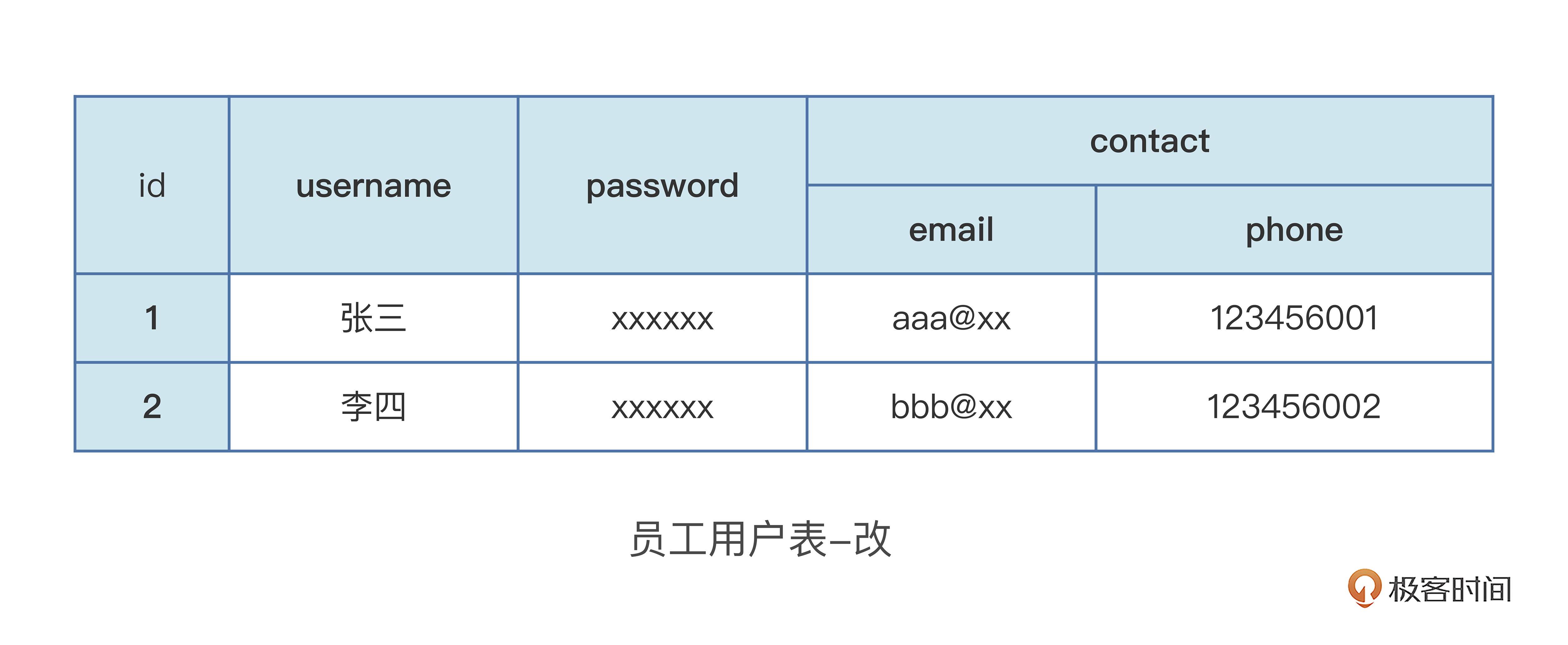
这个表中,联系方式“contact”这一列,拆分成邮箱“email”和手机号码“phone”,不满足字段的“原子性”,也就不满足第一范式了。
第二范式,在第一范式的基础上新增了一个规则,“不存在非关键字段对任意一候选字段的部分函数依赖”。描述可能有点拗口,我们看具体例子,在“员工用户表”上,再设计一个搭建平台的“页面操作记录表”。

这张表就不符合第二范式,因为表中使用了员工用户user_id这一个用户表的“主键”数据,还使用了员工名称“username”和员工邮箱“email”,不满足“不存在非关键字段对任意一候选字段的部分函数依赖”。其中员工用户名称“username”和邮箱“email”这个就是“部分函数依赖”这技术概念。
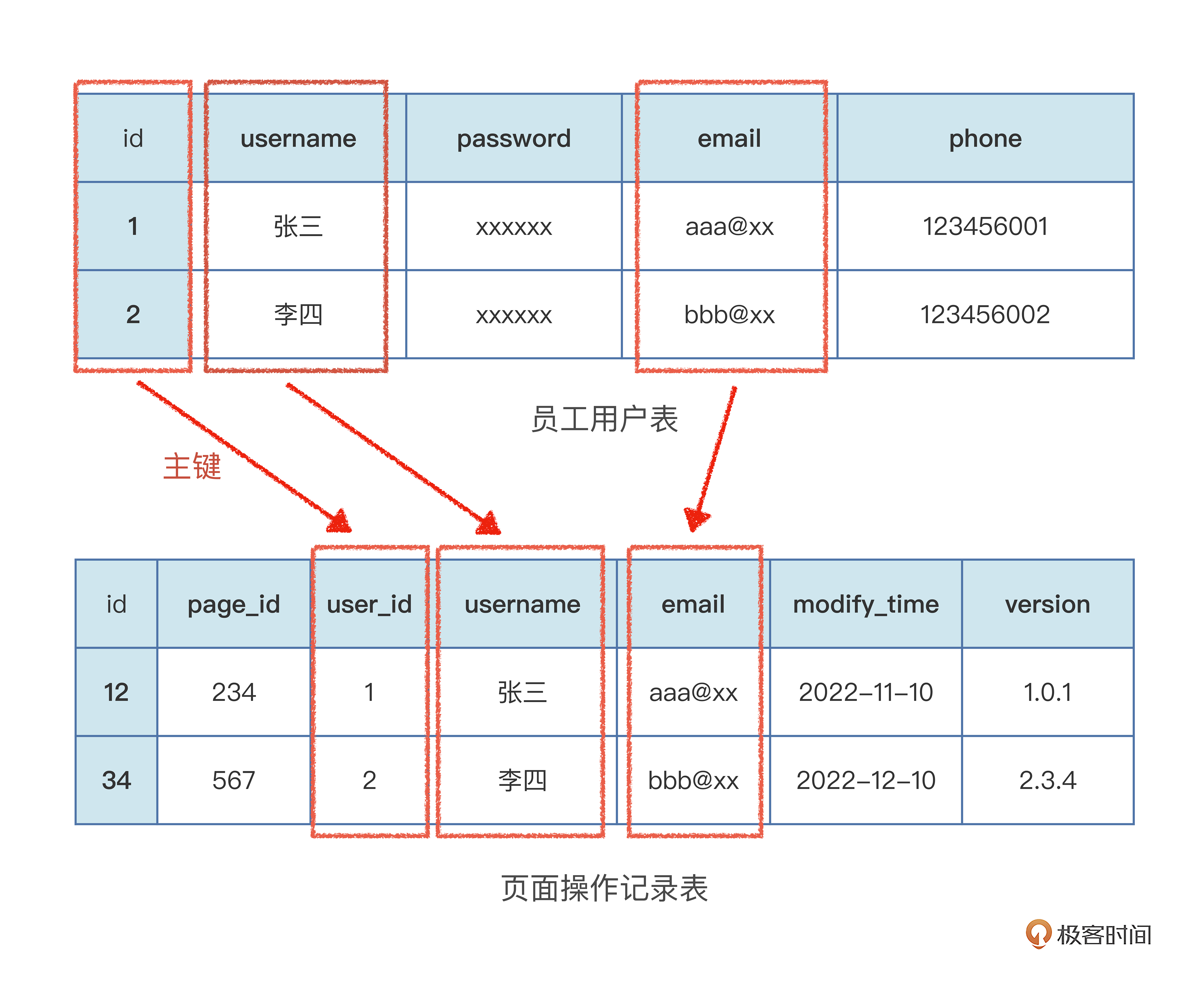
因为“页面操作记录表”里用了员工用户“user_id”,也就是员工用户表里“id”这个字段,我们其实可以通过员工用户这个user_id,去“员工用户表”中获取用户名称和邮箱信息。如果额外添加这两个数据,会造成数据的冗余和不同步。
用户的名称和邮箱数据本来在“员工用户表”就有了,在“页面操作记录表”记录用户操作时候又存了一份,这就造成数据的冗余。如果用户更新了邮箱或者名字,“页面操作记录表”不一定能同步更新,这就会造成数据的不同步。
所以,第二范式可以理解是“数据的唯一性和一致性”,通过“主键”(例如user_id,员工用户表主键),来关联对应详细数据,避免造成数据的冗余和不一致。
第三范式,在第二范式的基础上再新增了一个规则,“任何非主属性不依赖于其他非主属性”。换句话讲,就是要“消除传递依赖”,我们继续看例子,修改一下运营搭建平台的“员工用户表”。
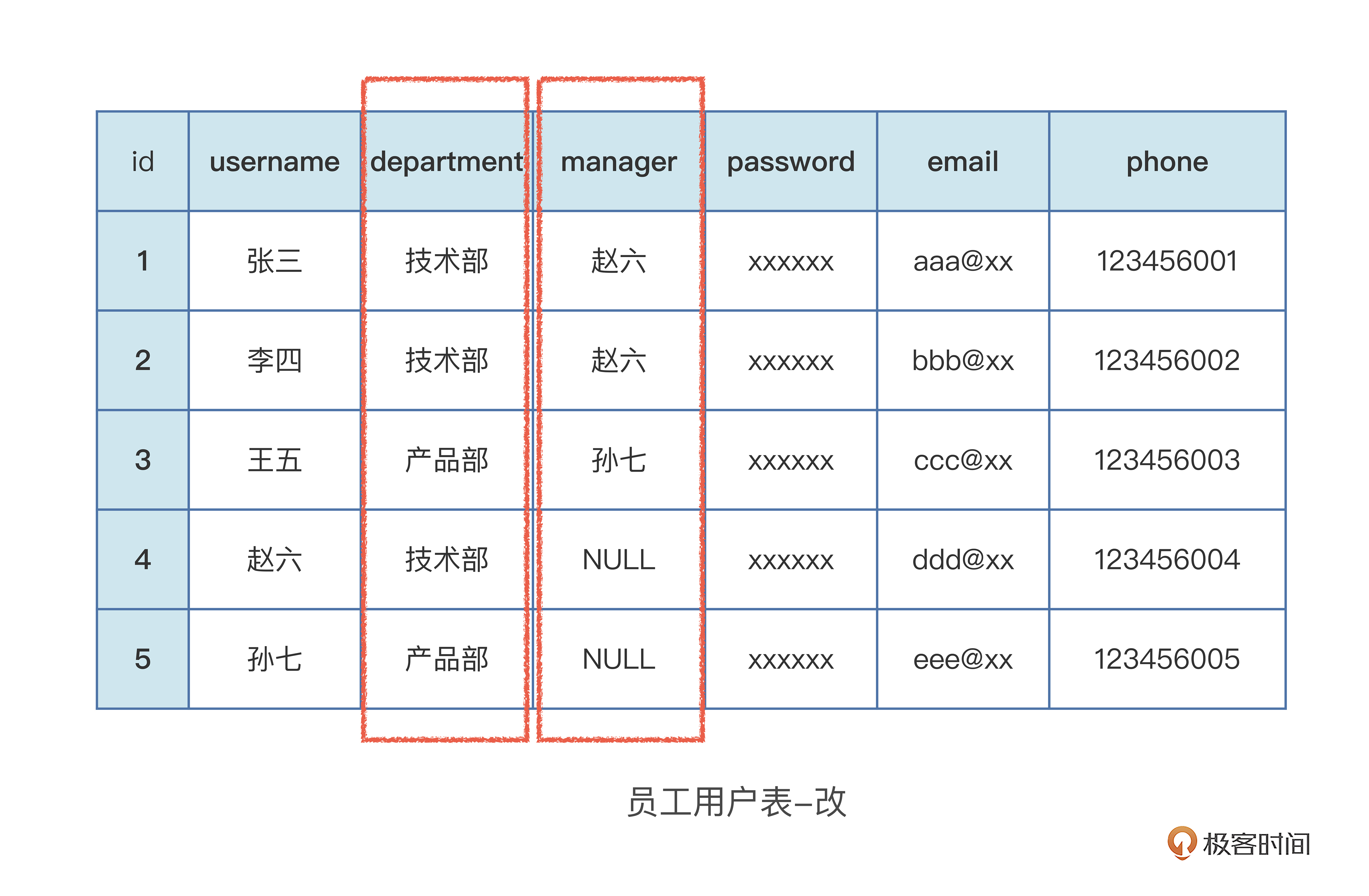
添加了员工部门“department”和员工主管“manager”的数据字段,这个两个字段就是“非主属性”或“非主键”,但是存在依赖关系,不符合第三范式。所以这个表需要拆分成两张表。
拆分也很简单,先精简用户表数据,把部门数据抽离出来,抽出部门的数据,用独立一张表来存储数据。
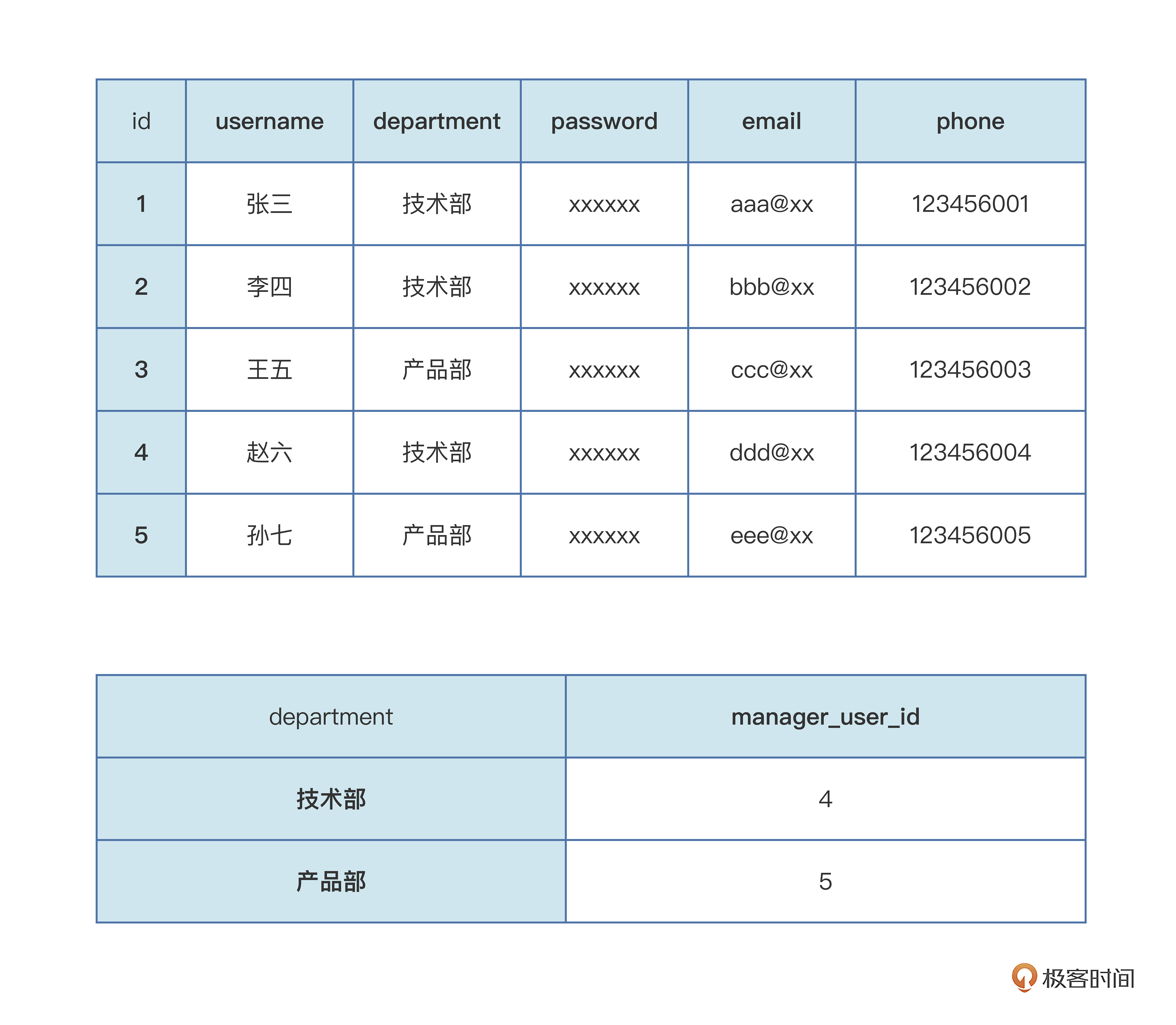
企业开发常用的前三种数据库范式就了解得差不多了,基于这第三范式的严格程度,基本能解决大部分项目数据库的设计问题和冗余问题,我们课程的数据库也会按这个来设计。如果你想在项目中用上更严格的范式设计数据库,也可以,只不过要耗费更多时间和精力。
接下来,我们就一起看看遵循第三范式,如何设计运营搭建平台的数据库。
如何做运营搭建平台项目数据库设计?
首先,我们要做数据种类的划分,根据第三范式的严格程度,我们需要尽可能让数据“原子化”、“唯一性”和“消除传递依赖”。运营搭建平台的数据,我们可以分成五类。
- 员工用户数据,企业内部操作搭建页面的员工用户
- 物料数据,用于搭建页面的业务组件配置数据
- 物料操作快照,业务组件的日常更新迭代的备份数据、操作日志和版本信息
- 搭建的页面,搭建页面的布局和配置数据
- 页面操作快照,页面日常更新迭代的备份数据、操作日志和版本信息
这五个数据种类落在数据库里,也就是五张数据“表”,可以这么定义。
- 员工用户表 user_info
- 物料信息表 material_info
- 物料快照表 material_snapshot
- 页面信息表 page_info
- 页面快照表 page_snapshot
我们逐一实现每张数据表。
员工用户表 user_info
第一张是员工用户表 user_info,我们列出需要的数据字段和数据类型。
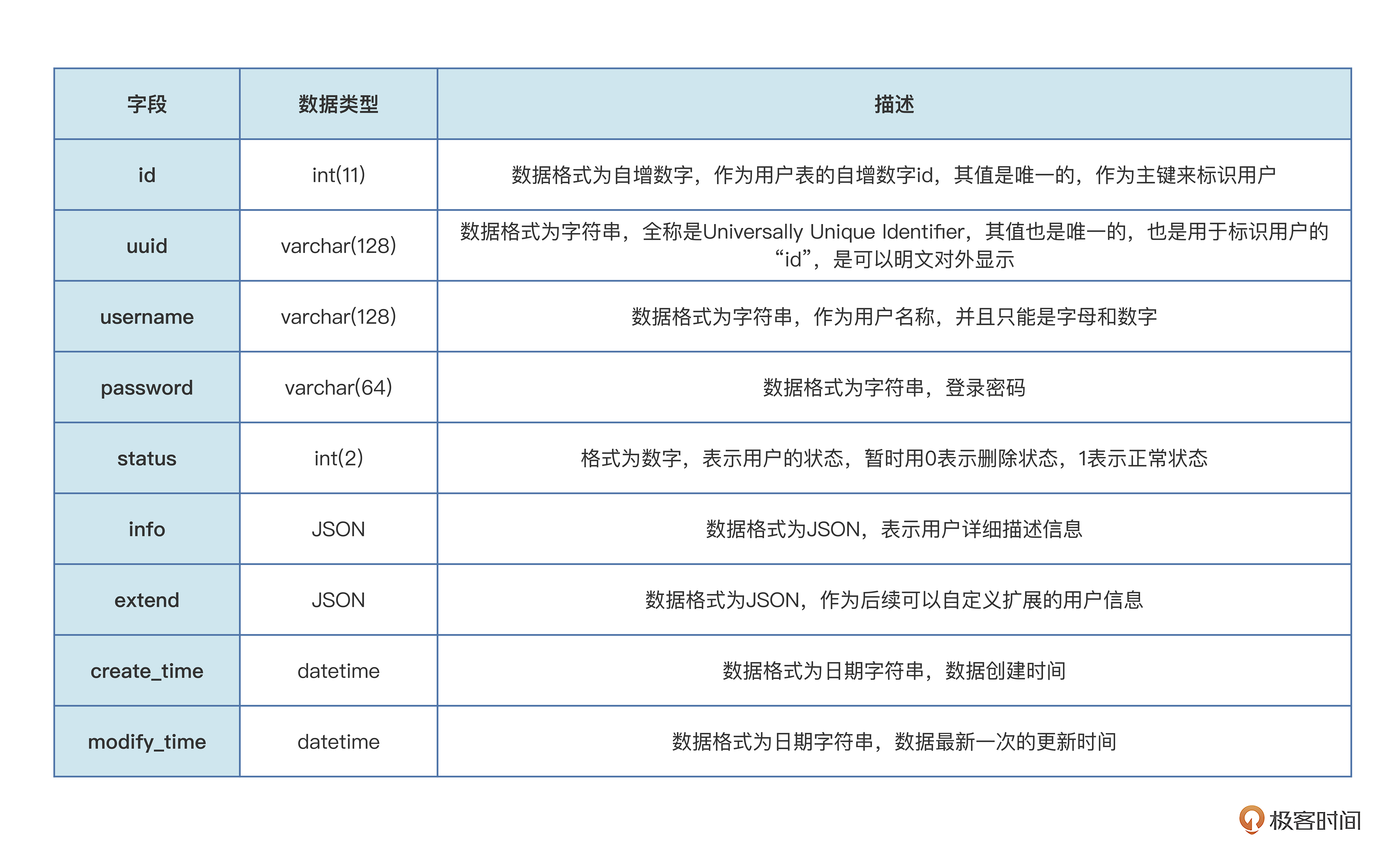
我解释几个数据字段。
首先是“id”和“uuid”的设计,你估计会有疑惑,为什么要出现两个描述(id、uuid)用的“唯一值”?难道不会造成数据冗余吗?
其实这是企业内的常见做法。因为“自增数字类型”的“id”数据,如果显示出来,容易暴露太多信息,例如会暴露当前用户是第几位注册的账号、系统里可能存在的用户量,甚至可能因为数据HTTP接口的不安全调用,外部“灰黑产”能通过自增id进行枚举“拖库”,循环遍历id数值,获取所有用户数据。
所以,为了避免出现这样的问题,我们会新增字段“uuid”,一个随机生成的、不重复的字符串数据,代替自增数值的id。uuid可以在URL、网页等地方明文显示出来,因为是随机不重复的字符串,所以安全性会比较高,不容易暴露太多信息。
有了“uuid”,同时保留自增数值的“id”,主要是id可以方便系统内部弄清楚数据量或者定位数据的位置。
然后看“info”和“extend”这两个数据字段,为什么选择用“JSON”的数据格式,JSON数据格式意味着这个字段可以继续“拆分”,是不是违背了“第二范式”的规则?
其实,用JSON数据格式,字面上理解是已经不符合“第二范式”,但是在实际业务开发和使用中,却提升了数据操作的灵活度。
例如用户详细描述字段“info”,我们后续可以继续通过动态增加JSON内置字段,来动态扩展用户的描述信息;用户扩展字段“extend”,后续如果有需求要对用户做归类或者“打标签”等数据操作,可以在通用的扩展JSON里做处理,不用改变整个表的字段,毕竟,改变表字段,存在一定的数据库操作风险。
当然在企业里,大厂也一样,由于业务快速变化,增加或修改数据字段是常见的事情。这是因为“在商言商”,我们需要在“遵守技术规范”和“业务迭代盈利”之间找到一个平衡点。
了解员工用户表的内容后,我们就可以进入SQL建表语句的设计了。
SQL建表语句
基于上面的字段描述,在MySQL数据库环境里,我们实现员工用户表的建表SQL代码。
CREATE TABLE IF NOT EXISTS `user_info` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`uuid` varchar(128) NOT NULL UNIQUE COMMENT '员工用户UUID',
`username` varchar(64) NOT NULL UNIQUE COMMENT '员工用户名称',
`password` varchar(64) NOT NULL COMMENT '员工用户密码',
`status` int(2) NOT NULL COMMENT '状态,0为删除,1为正常状态',
`info` json COMMENT '描述(JSON数据格式)',
`extend` json COMMENT '扩展数据(JSON数据格式)',
`create_time` datetime DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`modify_time` datetime DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '最后修改时间',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
这段SQL代码,可以直接在MySQL命令环境中执行进行建表。其中“create_time”和“modify_time”的数据操作,利用了数据库的默认能力,当我们插入新数据或修改旧数据时,MySQL数据库会自动输入创建时间“create_time”或更新最后修改时间“modify_time”。
基于员工用户数据表的SQL创建语句,实现其他维度的建表SQL就方便多了。因为id,uuid,create_time和modify_time等这几个字段,是每张表都需要的基本字段,代码可以复用,再根据不同表的信息特征,我们稍作数据字段的修改就可以了。
看剩余4张表的建表SQL代码的设计实现。
物料信息表 material_info。
CREATE TABLE IF NOT EXISTS `material_info` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`uuid` varchar(128) NOT NULL UNIQUE COMMENT '物料UUID',
`name` varchar(128) NOT NULL UNIQUE COMMENT '物料名称(字母和数字)',
`current_version` varchar(64) NOT NULL COMMENT '当前版本',
`info` json COMMENT '描述(JSON数据格式)',
`extend` json COMMENT '扩展数据(JSON数据格式)',
`status` int(2) NOT NULL COMMENT '状态,0为删除,1为正常状态',
`create_time` datetime DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`modify_time` datetime DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '最后修改时间',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
物料快照表 material_snapshot。
CREATE TABLE IF NOT EXISTS `material_snapshot` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`version` varchar(64) NOT NULL COMMENT '快照版本',
`user_uuid` varchar(128) NOT NULL COMMENT '操作者的用户UUID',
`material_uuid` varchar(128) NOT NULL COMMENT '物料UUID',
`material_data` json COMMENT '物料快照数据(JSON数据格式)',
`extend` json COMMENT '扩展数据(JSON数据格式)',
`status` int(2) NOT NULL COMMENT '状态,0为删除,1为正常状态',
`create_time` datetime DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
页面信息表 page_info。
CREATE TABLE IF NOT EXISTS `page_info` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`uuid` varchar(128) NOT NULL UNIQUE COMMENT '页面UUID',
`name` varchar(128) NOT NULL UNIQUE COMMENT '页面名称(字母和数字)',
`current_version` varchar(64) NOT NULL COMMENT '当前版本',
`layout` json COMMENT '布局互数据(JSON数据格式)',
`info` json COMMENT '描述(JSON数据格式)',
`extend` json COMMENT '扩展数据(JSON数据格式)',
`status` int(2) NOT NULL COMMENT '状态,0为删除,1为正常状态',
`create_time` datetime DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`modify_time` datetime DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '最后修改时间',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
页面快照表 page_snapshot。
CREATE TABLE IF NOT EXISTS `page_snapshot` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`version` varchar(64) NOT NULL COMMENT '快照版本',
`user_uuid` varchar(128) NOT NULL COMMENT '操作者的用户UUID',
`page_uuid` varchar(128) NOT NULL COMMENT '页面UUID',
`page_data` json COMMENT '页面快照数据(JSON数据格式)',
`extend` json COMMENT '扩展数据(JSON数据格式)',
`status` int(2) NOT NULL COMMENT '状态,0为删除,1为正常状态',
`create_time` datetime DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
更详细的SQL操作代码,你可以看课程的完整案例代码。
现在,我们设计了所有数据库表的建表SQL代码,怎么批量在数据库里实现建表操作呢?
如何实现项目的数据库初始化操作?
基于SQL批量建表这个没有标准答案,不同企业里不同程序员都是“八仙过海各显神通”,有的用MySQL的可视化建表工具,有的用企业内部的数据库工具,也有的直接用MySQL的命令工具。
那么有没有优雅的办法,实现项目的数据库建表初始化呢?最低成本的方式,就是用脚本实现自动化建表,初始化数据库。
既然我们用Node.js来做Web服务,也可以用Node.js这个脚本环境来实现自动化建库。主要分成三个步骤。
- 第一步,准备Node.js环境里的建库方法和建表方法。
- 第二步,准备所有初始数据库的SQL代码。
- 第三步,编写建表逻辑脚本。
第一步,准备Node.js环境里的建库方法和建表方法,我们沿用上节课的数据库操作方法。
import mysql from 'mysql';
import dotenv from 'dotenv';
dotenv.config();
export const database = process.env.MYSQL_DATABASE;
const config = {
host: process.env.MYSQL_HOST,
port: parseInt(process.env.MYSQL_PORT),
user: process.env.MYSQL_USER,
password: process.env.MYSQL_PASSWORD
};
const pool = mysql.createPool(config);
const poolDatabase = mysql.createPool({ ...config, ...{ database } });
export function querySQLByPool(sql: string) {
return new Promise((resolve, reject) => {
pool.query(sql, (err, results, fields) => {
if (err) {
pool.end();
reject(err);
} else {
pool.end();
resolve({ results, fields });
}
});
});
}
export function queryDatabaseSQLByPool(sql: string) {
return new Promise((resolve, reject) => {
poolDatabase.query(sql, (err, results, fields) => {
if (err) {
pool.end();
reject(err);
} else {
pool.end();
resolve({ results, fields });
}
});
});
}
export function queryDatabaseSQL(sql: string, values: (string | number)[]) {
const conn = mysql.createConnection({ ...config, ...{ database } });
conn.connect();
return new Promise((resolve, reject) => {
conn.query(sql, values, (err, rows) => {
if (err) {
conn.end();
reject(err);
} else {
conn.end();
resolve(rows);
}
});
});
}
export function closePools() {
pool.end();
poolDatabase.end();
}
第二步,准备所有初始数据库的SQL代码,参考前面写好的所有建表的SQL代码。
第三步,编写建表逻辑脚本。
/* eslint-disable no-console */
import {
database,
querySQLByPool,
queryDatabaseSQLByPool,
queryDatabaseSQL,
closePools
} from './util';
import sqlUserInfo from './sql/user_info.sql?raw';
import sqlPageInfo from './sql/page_info.sql?raw';
import sqlPageSnapshot from './sql/page_snapshot.sql?raw';
import sqlMaterialInfo from './sql/material_info.sql?raw';
import sqlMaterialSnapshot from './sql/material_snapshot.sql?raw';
async function initDatabase() {
const sqlDB = `CREATE DATABASE IF NOT EXISTS ${database};`;
await querySQLByPool(sqlDB);
console.log(`运营搭建平台 - 数据库 ${database} 建库成功!`);
await queryDatabaseSQLByPool(sqlUserInfo);
console.log(`运营搭建平台 - 数据库 ${database} 建表 user_info 成功!`);
await queryDatabaseSQLByPool(sqlPageInfo);
console.log(`运营搭建平台 - 数据库 ${database} 建表 page_info 成功!`);
await queryDatabaseSQLByPool(sqlPageSnapshot);
console.log(`运营搭建平台 - 数据库 ${database} 建表 page_snapshot 成功!`);
await queryDatabaseSQLByPool(sqlMaterialInfo);
console.log(`运营搭建平台 - 数据库 ${database} 建表 material_info 成功!`);
await queryDatabaseSQLByPool(sqlMaterialSnapshot);
console.log(
`运营搭建平台 - 数据库 ${database} 建表 material_snapshot 成功!`
);
console.log(
`运营搭建平台 - 数据库 ${database} 建表 material_snapshot 成功!`
);
await closePools();
const userInfoCount: { user_count: number }[] = (await queryDatabaseSQL(
'SELECT COUNT(*) AS user_count FROM user_info;',
[]
)) as { user_count: number }[];
if (userInfoCount?.[0]?.user_count === 0) {
console.log(`运营搭建平台 - 数据库 ${database}.user_info 表暂无数据`);
await queryDatabaseSQL(sqlInsertUserInfo, []);
console.log(
`运营搭建平台 - 数据库 ${database} 插入初始数据到 user_info 表成功!`
);
console.log('运营搭建平台 - 完成数据库初始化!');
}
}
async function init() {
await initDatabase();
}
init();
我是用vite-node这个工具来启动我们的TypeScript脚本,在Node.js环境里,自动地初始化数据库。其中,“import”加载SQL代码文件的“?raw”标记是Vite环境的支持操作,不要误会成TypeScript或者Node.js的规范。
这个自动化建库建表的初始化操作,也可以对企业项目不同环境的数据进行初始化,比如本地开发环境、项目测试环境、预发布环境和生产环境。主要操作是更换MySQL的环境地址和对应账号密码,执行脚本,就可以进行初始化了。
总结
通过今天的学习,相信你已经比较系统地掌握了企业级项目的数据库设计和实现。今天的内容已经不是“纯前端技术”,是全栈的技术范畴,如果你是只从事网页开发的前端程序员,可能有些学习和理解成本。我们做个总结,再次巩固一下。
首先,数据库的设计规范,也就是“数据库设计范式”,一般企业内部用到“第三范式”的严格程度,就能满足开发需要了。
- 第一范式,每个数据字段都是最小原子化,不能再拆分了。
- 第二范式,数据要唯一性,尽量通过id或者uuid来关联详细的数据,减少数据冗余。
- 第三范式,数据要避免“传递依赖”,尽量做好表的拆分,减少数据冗余。
数据库的设计范式,就是为了让数据的关系清晰,结构精简和减少冗余。不过,实际项目的数据库设计,与范式之间会有一些矛盾。
- 为了扩展灵活,不可避免“打破范式”,实际项目中可能会用一些可扩展的数据格式,例如JSON,提升数据管理的灵活度,但是打破了“第二范式”的规则。
- 不能明文使用数据的“自增id”,容易间接泄露信息,尽量用随机字符串的uuid来做明文的唯一标识。
- “id”和“uuid”,两者都是唯一标识,都可以作为“主键”,某种意义上也会带来数据冗余,但是为了业务的使用安全,牺牲一定的规范也是可以接受的。
总的来说,在实际项目中,我们有些时候面对一些实际场景,要做一些技术规范的妥协,尽量在两者间找到一个平衡点,灵活解决实际的技术问题。
思考题
如何用SQL实现数据库联表查询操作?例如,联合员工用户表、物料信息表和物料快照表,查询具体用户的操作记录日志。
期待看到你的思考,我们下节课再见。
完整的代码在这里
- 刘大夫 👍(2) 💬(1)
这节太棒了,想接触后端就离不开数据库,这一节的数据库设计对于前端来说可以说是引入门了,路子一下清晰了
2023-02-10 - 一只鱼 👍(0) 💬(1)
关于物料表和物料快照表有一些疑惑: 我的理解:物料表记录当前所有物料的最新信息,物料快照表记录所有物料的历史变化信息。 问题1:物料快照表是必须的吗?在这个项目中的主要作用是什么? 问题2:因为记录的是变化信息,随着时间的推移,物料快照表的数据量会不断增加,进而导致存储成本变大,怎么对其进行约束呢? 一点小建议:有5张表,估计是篇幅原因,主要对第一张用户表进行展开讲解,后续的没有详细介绍,这个能理解。但如果能有对后续几张表的讲解,以及为什么需要这几张表,那就更完美了,可以作为选读部分,不一定要放在正文中。PS: 最近正在经历第一次表设计,所以对这块比较感兴趣,希望老师能够解答。
2023-03-01 - 静心 👍(0) 💬(1)
感觉这一节,对于前端开发来说,用处不是太大,一般的项目不会这么设计。
2023-01-12 - ifelse 👍(0) 💬(0)
学习打卡
2024-09-21 - escray 👍(0) 💬(0)
在准备 Node.js 环境里的建库方法和建表方法的代码中,相对路径是:packages/init-database/src/util.ts, queryDatabaseSQLByPool 方法里面,使用了 poolDatabase.query 来执行 SQL 语句,但是在后面的 if-else 里面确使用了 pool,感觉似乎是一个笔误。 但是如果在代码里面修改之后,在执行完前一条操作之后会报错 Operation Platform - Database hello_vue_project create success! Operation Platform - user_info Table created sucdess node:internal/process/promises:289 triggerUncaughtException(err, true /* fromPromise */); ^ Error: Pool is closed. 有点没看明白,我感觉其实可以等所有的 SQL 语句都执行完之后,再关闭 poolDatabase 和 pool。对比来看,pool 是每次执行完都关闭(end)的,却不影响下一次的执行。
2024-01-15