加餐 实战篇思考题答疑(上)
你好,我是杨文坚。
实战篇学到现在,我们已经从前端到后端,基于Vue.js和Node.js,实现了一套全栈服务功能,这些功能覆盖了运营搭建平台的基本功能链路。
我们首先定制了运营拖拽组件,承接基础组件库的开发,也开启了运营搭建业务功能实现,为后面实战的高阶开发做准备。
接着,我们基于Koa.js开发Node.js Web服务,同时结合基于MySQL的项目数据库设计,打通了项目平台服务的全栈链路。通过这个全栈Node.js Web服务开发,我们扩展出面向企业用户管理的后台服务和面向客户展示页面的前台服务,核心的技术思路是做全栈服务的技术分层,以及面向不同场景的服务项目拆分。
然后,我们从业务视角,划分了运营搭建平台的功能维度,分别是用户、物料和页面这三大功能维度。我们基于搭建好的全栈服务底座,实现了用户和物料两大维度的基础业务功能,核心的技术思路是数据库的“增删改”的操作,以及前端静态资源的共享管理。
今天我们对已经学过的实战篇内容做一次统一答疑,如果还有疑问,也欢迎你留言。
15
课程:15 定制运营拖拽组件
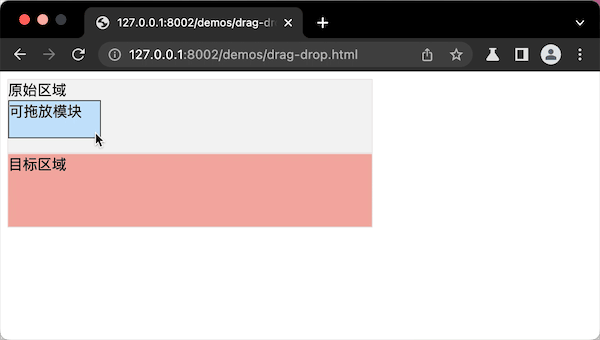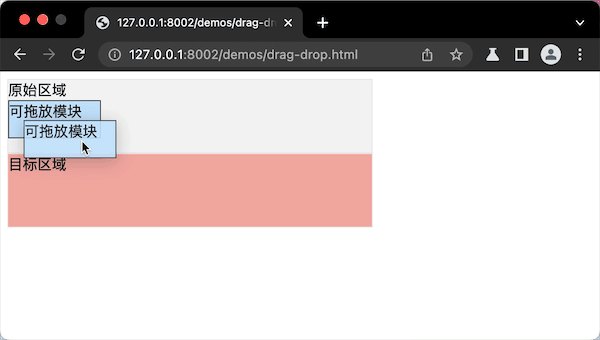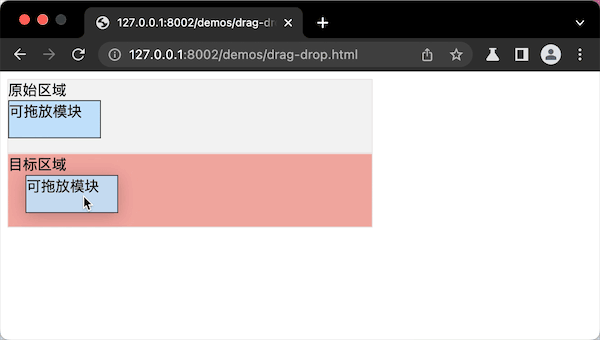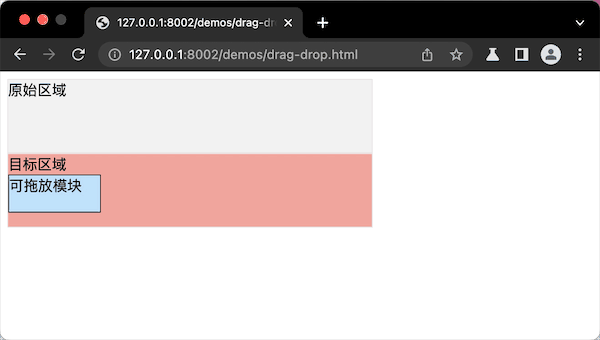
提问:我们实现了拖拽布局组件,只是通过拖拽调整了布局,那么,如果要从一个布局拖拽到另外一个布局里,应该怎么实现这个“拖放”布局布局组件呢?
拖放操作,其实跟拖拽操作类似,技术实现逻辑只有两个步骤。
- 第一步,要确定“可拖的模块”和“可放的目标区域”。
- 第二步,注册“拖”和“放”的DOM事件。
第一步,“可拖的模块”需要设置draggable属性。“可放的目标区域”不需要注册特殊属性,只需在第二步注册“监听放”的事件。
第二步,“可拖的模块”注册拖拽ondrapstart事件,“可放的目标区域”需要注册ondrop事件,就是监听“拖放”的事件。同时要监听ondrapover事件,就是监听“可拖的模块”是否到达“可放”的区域中。
这里我实现了一个代码案例。
<html>
<head>
<meta charset="utf8" />
<style>
.area {
width: 400px; height: 80px; background: #f0f0f0; border: 1px solid #e7e2e2;
}
.area-target {
background: #f0a49e;
}
.module {
width: 100px; height: 40px; background: #bddef9; border: 1px solid #222222;
}
</style>
</head>
<body>
<div class="area">
<div>原始区域</div>
<div id="module" draggable="true" ondragstart="dragModuleStart(event)" class="module">
可拖放模块
</div>
</div>
<div id="target-area" ondrop="dropArea(event)" ondragover="dragOverArea(event)" class="area area-target">
<div>目标区域</div>
<!-- 模块可以拖方这里 -->
</div>
</body>
<script>
function dragModuleStart(event) {
// 将拖拽模块元素的 id 添加到数据传输对象
event.dataTransfer.setData("application/my-app", event.target.id);
event.dataTransfer.dropEffect = "move";
}
function dragOverArea(event) {
// 处理拖拽模块到目标区域时候,目标区域的拖拽悬浮事件
event.preventDefault();
event.dataTransfer.dropEffect = "move"
}
function dropArea(event) {
event.preventDefault();
// 获取拖放模块的id, 并将移动的元素添加到目标的 DOM
const data = event.dataTransfer.getData("application/my-app");
event.target.appendChild(document.getElementById(data));
}
</script>
</html>
代码案例的最终实现效果图,就像这样:
16
课程:16 开发单页面应用
提问:如何处理单页面和多页面项目共存?
要让单页面(应用)和多页面在同一个项目中共存,需要前端和后端一起配合实现,具体实现可以分成三步。
第一步,前端和后端要约定单页面和多页面的路径规范。例如约定 /page/mange/ 路径是单页面路径,凡是URL路径以 /page/mange/ 开头的都是单页面应用。剩下 /page/xxx 都是多页面路径。
第二步,后端路由分别处理单页面和多页面的服务端渲染。服务端路由判断请求URL路径是以 /page/mange/ 开头的,就渲染同一个单页面的HTML,其它多页面路径就渲染对应页面的HTML。
第三步,前端路由处理单页面渲染。前端对页面为 /page/mange/ 的路径,用hash或者history的前端浏览器路由,处理对应的单页面操作。
总结一下,单页面(应用)和多页面共存,不是一个单纯技术问题,更多是一个全栈项目的前端后端的规范约定问题。
17
课程:17 结合 Koa.js 开发 Node.js Web 服务
提问:Koa.js和Express.js的中间件模型有什么区别吗?
Koa.js和Express.js的中间件模型是不一样的。Koa.js是基于Promise的嵌套实现“洋葱中间件模型”,Express.js是基于“回调”的嵌套来实现中间件模型。
Koa.js的中间件模型,通过Promise的嵌套,处理实现了洋葱模型中间件。不管怎么“use”中间件,最后都是结构成一层层Promise的嵌套,大致解构出来代码就像这样。
// Koa.js中间件的使用
app.use(middleware1);
app.use(middleware2);
app.use(middleware3);
// 可以解构类比成
Promise.resolve(
middleware1(context, async () => {
return Promise.resolve(
middleware2(context, async () => {
return Promise.resolve(
middleware3(context, async () => {
return Promise.resolve();
})
);
})
);
})
).then(() => {});
Express.js通过“回调方法”的嵌套形成中间件数组,再自上而下“线性”执行中间件,通过next这个方法来控制“线性”的过程。看大致解构出来代码。
// Express.js中间件的使用
app.use((req, res, next)=> {
console.log('001');
next();
console.log('004');
});
app.use((req, res, next)=> {
console.log('002');
next();
console.log('003');
});
// 可以解构成以下代码
app.use((req, res, next)=>{
console.log('001');
((req, res, next)=>{
console.log('002');
// 其它中间件
console.log('003');
})()
console.log('004');
});
18
提问:单页面应用如何优雅设计Vue.js项目的SSR和CSR?
多页面的SSR和CSR结合,主要是从编译视角做功夫,把一套Vue.js的前端代码,稍做编译处理,输出另一份代码,来支持Node.js服务环境渲染HTML。那么单页面应用,也可以遵循这个思路来低成本地优雅实现。
在单页面应用中,每个子页面都是就是基于CSR进行修改路由,然后渲染的。这时候需要SSR的出现场景,就只是“刷新”或“首次”加载子页面时候,在服务端输出子页面的HTML。
如果单页面应用要支持SSR,那就需要支持每个“子页面”的服务渲染HTML。这时候最低成本的方式,或者说是最优雅的方式,就是从编译视角做修改。
也就是一套Vue.js的单页面应用代码,在编译时候做处理,输出每个子页面的Node.js代码,在Node.js服务对应子页面路由上做处理。
19
提问:为什么不能用读写静态文件的方式来代替数据库使用?
用静态文件,理论上是可以当做“数据库”使用的,就当做是用一个Excel文件来管理数据。
如果用静态文件管理数据,那就需要自己写一堆服务端代码实现数据的“新增”、“搜索”、“更新”的操作支持。
但是,数据量积累到一定量的程度,“搜索”数据的代码将会遇到性能瓶颈,这时如果要实现数据“更新”,必须基于“搜索”来找到数据,然后做“更新”操作,将会叠加了性能瓶颈问题。此时,操作静态文件的代码,将会大大增加维护成本,甚至做性能优化都无从下手。
数据库的出现,其实就是解决了数据的“管理”问题,一般会内置一个或者多个“引擎”来处理数据的“搜索”操作。而且数据库是独立的服务,独立处理服务器里资源开销问题。如果自己读写静态文件来管理数据,必将占用同一个服务的资源(例如内存和CPU)。
当然,数据库也不是处处适用,如果实际需求只需要管理少量数据,用静态文件的读写作为数据管理反而更省事。因为数据库是需要独立开启服务的,也需要运维成本的。
所以,如果数据量极少时候,可以用静态文件的读写方式来管理数据。如果数据量多了,就尽量选择用数据库来管理数据。
20
提问:如何用SQL实现数据库联表查询操作?例如,联合员工用户表、物料信息表和物料快照表,查询具体用户的操作记录日志。
可以通过“JOIN”的方式来联表查询。我们先用SQL来插入模拟数据。
-- 插入模拟用户数据
INSERT INTO user_info
(uuid, username, password, status, info)
VALUES
(
'00000000-aaaa-bbbb-cccc-ddddeeee0001',
'admin001',
'1f22f6ce6e58a7326c5b5dd197973105',
1,
'{}'
),
(
'00000000-aaaa-bbbb-cccc-ddddeeee0002',
'admin002',
'1f22f6ce6e58a7326c5b5dd197973105',
1,
'{}'
);
-- 插入模拟的物料数据
INSERT INTO material_info
(uuid, name, current_version, status, info, extend )
VALUES
(
'11110000-aaaa-bbbb-cccc-ddddeeee0001',
'@my-material/promoted-products',
'1.2.3',
1,
'{}',
'{}'
),
(
'11110000-aaaa-bbbb-cccc-ddddeeee0002',
'@my-material/promoted-banner',
'4.5.6',
1,
'{}',
'{}'
);
--- 插入模拟的物料快照数据
INSERT INTO material_snapshot
(version, user_uuid, material_uuid, material_data, status, extend )
VALUES
(
'0.1.0',
'00000000-aaaa-bbbb-cccc-ddddeeee0001',
'11110000-aaaa-bbbb-cccc-ddddeeee0001',
'{"a":123}',
1,
'{}'
),
(
'0.2.0',
'00000000-aaaa-bbbb-cccc-ddddeeee0001',
'11110000-aaaa-bbbb-cccc-ddddeeee0001',
'{"a":123}',
1,
'{}'
),
(
'1.2.0',
'00000000-aaaa-bbbb-cccc-ddddeeee0002',
'11110000-aaaa-bbbb-cccc-ddddeeee0001',
'{"a":123}',
1,
'{}'
),
(
'1.2.1',
'00000000-aaaa-bbbb-cccc-ddddeeee0002',
'11110000-aaaa-bbbb-cccc-ddddeeee0001',
'{"a":123}',
1,
'{}'
),
(
'3.2.1',
'00000000-aaaa-bbbb-cccc-ddddeeee0001',
'11110000-aaaa-bbbb-cccc-ddddeeee0002',
'{"a":123}',
1,
'{}'
),
(
'4.3.2',
'00000000-aaaa-bbbb-cccc-ddddeeee0001',
'11110000-aaaa-bbbb-cccc-ddddeeee0002',
'{"a":123}',
1,
'{}'
)
;
如果要联合员工用户表、物料信息表和物料快照表,查询具体用户的操作记录日志,需要分步操作。可以分成三步。
- 第一步,联合物料信息表和物料快照表,整合一个物料快照详细信息的“临时物料快照联合表”。
- 第二步,联合员工用户表和“临时物料快照联合表”,整合成一个“临时完整员工操作物料日志表”。
- 第三步,按需查询“临时完整员工操作物料日志表”。
第一步,联合物料信息表和物料快照表的SQL实现。
SELECT
mi.name AS material_name,
ms.user_uuid AS user_uuid,
mi.current_version AS current_version,
ms.version AS snapshot_version,
ms.create_time AS create_time
FROM
material_snapshot as ms
LEFT JOIN material_info AS mi ON mi.uuid = ms.material_uuid
第二步,联合员工用户表和“临时物料快照联合表”。
SELECT * FROM (
SELECT
mi.name AS material_name,
ms.user_uuid AS user_uuid,
mi.current_version AS current_version,
ms.version AS snapshot_version,
ms.create_time AS create_time
FROM
material_snapshot as ms
LEFT JOIN material_info AS mi ON mi.uuid = ms.material_uuid
) AS m
LEFT JOIN user_info AS u ON u.uuid = m.user_uuid;
第三步,按需查询“临时完整员工操作物料日志表”。
SELECT
u.username AS username,
m.material_name AS material_name,
m.snapshot_version AS snapshot_version,
m.create_time AS time
FROM (
SELECT
mi.name AS material_name,
ms.user_uuid AS user_uuid,
mi.current_version AS current_version,
ms.version AS snapshot_version,
ms.create_time AS create_time
FROM
material_snapshot as ms
LEFT JOIN material_info AS mi ON mi.uuid = ms.material_uuid
) AS m
LEFT JOIN user_info AS u ON u.uuid = m.user_uuid;
21
提问:通过Cookie作为登录态唯一数据存在浏览器里,如果Cookie被其他人拿到,是否能伪造Cookie所属用户的登录行为?有办法避免出现这个问题吗?从Web服务平台提供方视角出发,一般怎么做登录态的保护?
通过Cookie作为登录态唯一数据存在浏览器里,如果Cookie被其他人拿到,是否能伪造Cookie所属用户的登录行为?
- 能伪造,理论上讲,如果Cookie被别人拿到了,可以被人“种”到他自己浏览器里,那么就等于别人的浏览器也有登录态,也就能拥有Cookie用户的登录权限了。
如果Cookie被其他人拿到了,伪造了登录,那有办法避免出现该问题吗?大厂一般怎么做登录态的保护?
有办法避免的。一般在大厂里,会有专门的部门做统一用户登录等权限管理。而且会从多个纬度来进行校验用户登录态的有效性。例如这三种维度:
- 用户IP维度。每次登录或者HTTP访问时候,会在数据库、或者缓存、或者日志记录登录用户当前的IP地址,并且与上次记录的做比对,如果判断不是同一个地区的IP地址,就需要用户做二次验证,例如邮箱验证码,或者短信验证码验证。上述用户所在的IP地址是可以从HTTP请求里获取到的。
- 用户常用浏览器标记维度。例如用浏览器的存储能力,例如localStorage来存储一些用户标记,下次请求时候,判断是否为常用浏览器,如果不是,就进行二次验证。
- 用户Cookie的时效性维度。对Cookie进行短时间内的定时更新,即使某个时间的Cookie被别人获取,也只是在短时间内的泄露问题。
大厂里除了上述维度进行验证用户是否异常,还有更高阶的维度判断,例如基于用户HTTP请求的算法分析等,就是算法分析实时日志时候,发现当前时间段内用户请求某个HTTP的API异常多,就会对用户进行二次验证。
22
提问:前台场景运行页面时,通过ESM或者AMD格式进行异步加载物料的代码文件,如果页面依赖的物料变多了,物料文件请求也会变多,这会影响页面打开时间吗?有什么办法可以提高页面打开时间吗?
页面上物料请求文件变多,会导致用户加载页面时间变长。
解决思路就是减少首屏文件请求,来提高用户体验。核心的解决点就是“减少首屏文件请求”,那么就要在物料组装的运行时中,做好物料的“懒加载”,主要实现方式是首屏只渲染首屏的物料组件,第二屏开始监听页面滚动情况,按需加载加载对应的物料文件。
23
提问:在今天的技术方案设计中,物料组件版本号只能升级不能降级,这是为什么呢?
物料组件的升级版本号,只能升级不能降级,这是为了让物料版本号跟CDN和NPM远程静态资源最新版本保持一致。页面级别的数据发布和管理才是允许版本降级,所以这不是一个技术问题,而是一个项目的业务逻辑问题。
物料最终是给页面组装使用的,那么最终上线的数据是页面级别的版本数据,每个页面的每个版本数据里,使用了哪个物料都是有对应版本号。如果使用版本出问题,就在页面级别上,把版本号降级或升级。
思考题就解答到这里,下一讲我们继续实战篇的学习,下一讲见。
- ifelse 👍(0) 💬(0)
学习打卡
2024-09-25 - 行云流水 👍(0) 💬(0)
从前面看下来大概意思: 1. 搭建组成页面的 基础组件 业务组件 2. 把这些组件 通过vite工具 编译打包成不同格式,并上传cdn。 3. 在 web管理系统有 组件物料的 注册 编辑列表管理 4. SSR CSR 通过 页面配置拿到组成页面的json,然后拿到cdn静态资源 然后组组装页面输出 现在的问题是: 这种编译模式,在SSR的时候不能处理前端路由和后端路由匹配? 纯原生vuessr需要处理路由匹配,还是说活动营销页面 其实就是一个多页面模式,没有前端路由一说?
2024-01-29