06 虚拟DOM:为什么要关心React组件的渲染机制?
你好,我是宋一玮。欢迎回到React组件的学习。
上节课我们从前端组件化这个概念开始,学习了React组件的层次结构,并用第三节课的React项目演练了组件拆分,引出了React拆分组件的基本原则,也顺带着提出React组件树的本质是元素树。
上节课的内容是比较多的。如果你有做过上节课的思考题,我仍然有些好奇,课上学到的内容是不是足够你完成题目。如果你顺利交卷那你真是很棒!当然,做题时遇到些难题也没关系,在这节课我会延续上节课的思路,继续讲React组件,重点会落在React组件的渲染机制上。
这节课会涉及一些React的底层原理,可以为你解答如下问题:
- 为什么我需要关心React组件的渲染机制?
- 为什么数据变了,但组件没重新渲染?
- 为什么数据没变,但组件也重新渲染了?
后两个问题本身都可以作为第一个问题的答案。至于后两个问题,掌握React组件重新渲染的时机,避免无效的重新渲染都需要学习React组件的渲染机制。
我们现在开始这节课的内容。
虚拟DOM
虚拟DOM(Virtual DOM)是前端领域近几年比较出圈的一个概念,是相对于HTML DOM(Document Object Model,文档对象模型)更轻量的JS模型。在React、Vue.js、Elm 这样的声明式前端框架中,都包含了虚拟DOM。
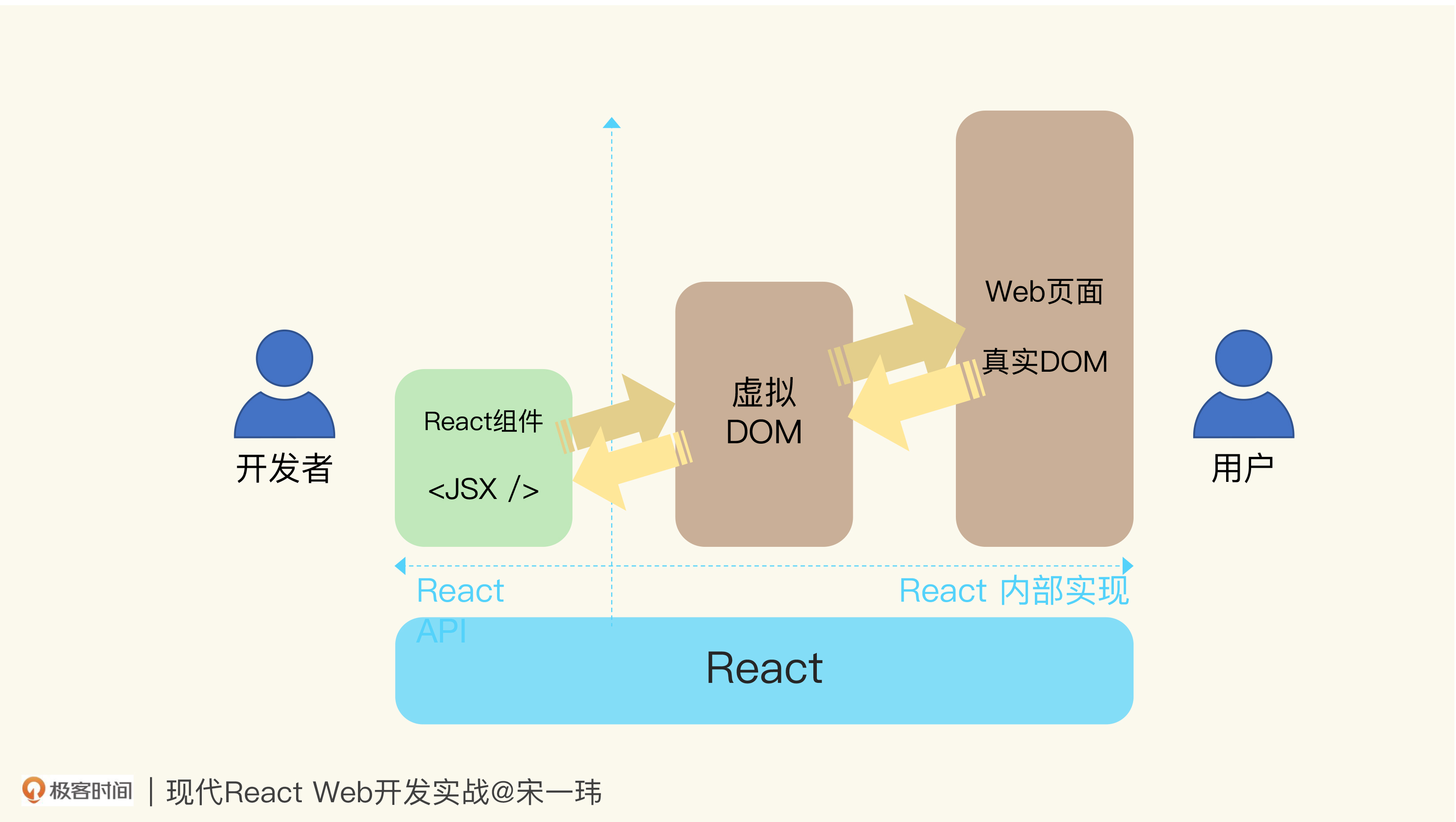
面向前端开发者,React提供了包括JSX语法在内的声明组件API,在运行时,开发者声明的组件会渲染成虚拟DOM,虚拟DOM再由React框架渲染成真实的DOM;虚拟DOM的变动,最终会自动体现在真实DOM上;真实DOM上的交互,也会由React框架抽象成虚拟DOM上的副作用(Side-effect),与开发者编写的交互逻辑关联起来。
理想状态下,开发者在开发React应用时,可以完全不去接触真实DOM(但现实世界中这种情况很少见),一定程度上隐藏了Web原生技术的细节,有助于提高开发效率。
如下图所示,左半边展示了React面向开发者的API,右半边则是React内部实现对DOM API的封装,渲染面向用户的页面:
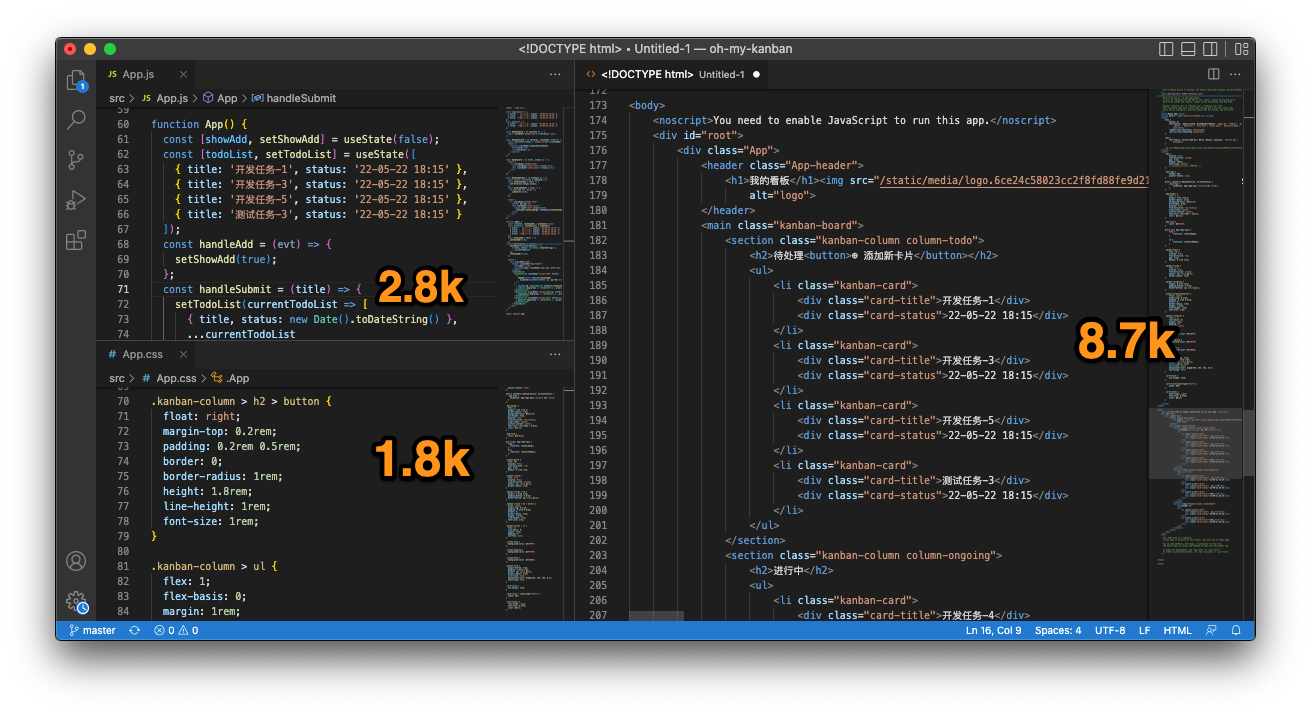
虽然很不严谨,我们姑且可以对比一下 oh-my-kanban 项目目前为止的代码量和它在浏览器运行时生成的HTML的字符数。
如下图,左手边是2.8k JSX + 1.8k CSS = 4.6k,右手边是从浏览器开发者工具的检查器页签里拷贝出来的实际HTML共8.7k。要知道,检查器显示的HTML中并不包含事件处理函数等JS内容,所以实际上 React帮你节省了更多代码量。
比起代码量的减少,虚拟DOM更重要的功能之一,是作为React面向开发者的API与React内部实现对接的桥梁。React API整体都是声明式的,而DOM API是命令式的。我们知道,No Magic(没有魔法),开发者用API声明的React组件,最终成为页面上的动态DOM元素,必然在React框架内部有着一系列命令式的实现,负责最终调用浏览器DOM API。
如果没有虚拟DOM这个中间模型,那么React API就需要直接对接DOM API,耦合程度提高,React概念和API设计也会受制于浏览器,React Native这样对接多端的愿景也无从实现了,React也许就很难称作是React了。
真实DOM有什么问题?
上面是从抽象设计和编程范式角度来介绍虚拟DOM的,有没有什么更有制约性的因素,导致不上虚拟DOM不行的?
有的。前面的课程里我们介绍过React的设计哲学 UI=f(state) ,理论上来说,对于给定的 f() 和状态数据,一定可以重现一模一样的UI;这也意味着,只要状态数据有变化,f()就需要重新执行,整个UI需要重新渲染。
是的,整个。如果这个渲染过程非常快,消耗资源也很低,那么我们让它每秒钟完整跑120次都是ok的,120FPS是什么样的体验呢?李安的电影《比利·林恩的中场战事》就是。
但是正如120FPS的电影拍摄贵,放映更贵,现实世界的 f() 成本也是可观的。对于浏览器网页中的应用,我们降低一档标准,60FPS,意味着1000ms ÷ 60 ≈ 16ms之内至少需要执行完一次 f() ,否则会掉帧,显示和交互都会卡顿。
操作真实DOM是比较耗费资源的,无脑地大量调用DOM API绘制页面,页面很容易就卡了,如果碰巧你的电脑配置不是很理想,浏览器的高CPU和内存占用也会强迫你的电脑风扇发出哀嚎。
这时就需要React提供一系列算法和过程,过滤掉没有必要的DOM API调用,最终把f() 的成本降下来。虚拟DOM就是这些算法过程的中间模型,它远比DOM API轻量,跟最终的DOM API分摊成本后,可以保证React组件的渲染效率。
在这里我就不列举benchmark数据了,你如果感兴趣的话,可以去上手玩一下 https://dom-benchmark.vercel.app/,源码在 https://github.com/Swizec/dom-benchmark,虽然里面React测试程序使用的版本是比较早的v16.2,但它的性能已经明显优于直接调用原生DOM API的测试程序了。
其实在前端开源社区里,也有反对虚拟DOM的声音,比如新兴框架Svelte的作者里奇·哈里斯就曾发文《虚拟DOM纯粹就是额外开销》,认为虚拟DOM的Diffing算法是有代价的,也会误导开发者做一些无用功。
虽然与本课程立场不同,但我很认同他的最后一段文字:
虚拟DOM的价值在于,当你构建应用时,无需考虑状态的变化如何体现在UI上,且一般情况下不用担心性能问题。这减少了代码Bug,比起乏味的编码,你可以把更多时间投入到创造性的工作上。
协调
上节课最后讲到React组件会渲染出一棵元素树。因为开发者使用的是React的声明式API,在此基础上,每次有props、state等数据变动时,组件会渲染出新的元素树,React框架会与之前的树做Diffing对比,将元素的变动最终体现在浏览器页面的DOM中。这一过程就称为协调(Reconciliation)。
Diffing算法
Svelte作者的文章是2018年底发布的,React框架的核心开发团队不可能没看到吧。不过就算没有这篇文章,React框架后续的版本中也在不断优化Diffing算法。近四年算法细节变了不少,但基本逻辑还是能归纳出以下几点:
- 从根元素开始,React将递归对比两棵树的根元素和子元素;
- 对比不同类型的元素,如对比HTML元素和React组件元素,React会直接清理旧的元素和它的子树,然后建立新的树;
- 对比同为HTML元素,但Tag不同的元素,如从
<a>变成<div>,React会直接清理旧的元素和子树,然后建立新的树; - 对比同为React组件元素,但组件类或组件函数不同的元素,如从
KanbanNewCard变成KanbanCard,React会卸载旧的元素和子树,然后挂载新的元素树; - 对比Tag相同的HTML元素,如
<input type="text" value="old" />和<input type="text" value="new" />,React将会保留该元素,并记录有改变的属性,在这个例子里就是value的值从"old"变成了"new"; - 对比组件类或组件函数相同的组件元素,如
<KanbanCard title="老卡片" />和<KanbanCard title="新卡片" />,React会保留组件实例,更新props,并触发组件的生命周期方法或者Hooks。
需要强调的是,在对比两棵树对应节点的子元素时,如果子元素形成一个列表,那么React会按顺序尝试匹配新旧两个列表的元素。
如果对比结果是在列表末尾新增或者减少元素那还好,但如果是在列表头部或者中间插入或者删除元素,React就不知道该保留哪个元素了,干脆把整个列表都推翻了重建,这样会带来性能损耗。
为了应对这种情况,React引入了 key 这个特殊属性,当有子元素列表中的元素有这个属性时,React会利用这个 key 属性值来匹配新旧列表中的元素,以减少插入元素时的性能损耗。
这样的用途就要求在任何一个子元素列表中,key 对于每个元素应该是唯一的且稳定的。比如你的数据来自于数据库,包含了自增ID,那么你就可以用这个ID当作 key 的值。
你一拍大腿,终于知道 oh-my-kanban 在浏览器控制台里的warning是哪里来的了。
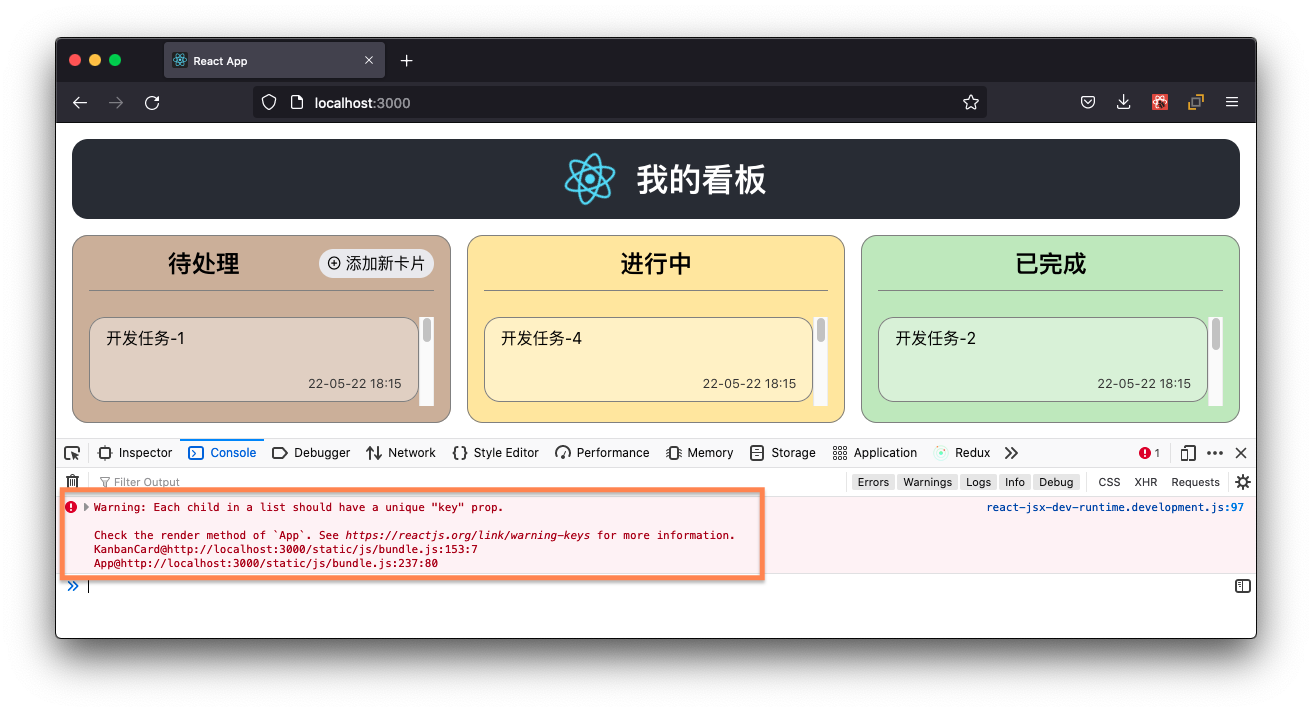
一直放在这里不修倒不是不可以,毕竟已经忽视它3节课了,但你既然知道这个warning的代价了,就不妨把它修掉。手头实在是没有ID,就把 title 赋给 key 属性吧。

刷新页面,浏览器控制台终于清静了!这时查看React开发者工具的组件页签,呈现的组件树是这样的:

Diffing的结果最终会被转换成DOM API调用,我们只修改需要修改的DOM即可。
触发协调的场景
了解了什么是协调,以及协调对比算法的基本逻辑,我们再回到React应用开发者的视角,看一下开发者做什么事情时会触发协调。
首先,开发者在使用React API时,不应该随时想着协调的细节,否则会加重开发者的负担;但协调又是页面最终变化的必经之路,这在前面已经强调过。那么如果你是React框架的设计者,你会选择在什么情况下触发协调?一般而言你会有两个方向的选择,拉(Pull)或者推(Push)。
轮询(Polling)就是一种“拉”的方案,我们假设一个极端的设计,让React间隔每16ms触发一次协调,这从功能上是一定可以实现需求的,只要React元素树有风吹草动,这一次的协调就会算出Diff,更新页面。但很容易就能看出这种方式的问题,也许元素树很长时间都没有变过,这会导致做了太多次没必要的协调,增加了资源的开销。
那么我们选择“推”的方案。我们要有方式告诉React,说我们需要触发协调,而且这个方式应该停留在React API层面,否则会把协调这一内部过程的复杂性暴露给开发者。结合React的设计哲学,UI=f(state) (这个state泛指组件数据,不是React接口里哪个state),我们认为只有数据变化时,才需要触发协调。
这就好办了,在React API里有哪些是操作组件数据的?是的, props 和 state ,除此之外再加一个 context。其中props 从组件外面传进来,state 则是活跃在组件内部,至于 context ,在组件外面的Context.Provider提供数据,组件内部则可以消费context数据。
只要这三种数据之一发生了变化,React就会对当前组件触发协调过程,最终按照Diffing结果更改页面。
关于 props、state 和 context 的细节,我依然计划留到后面的课程讲解。在这里先划出一个重点,props 和 state 都是不可变的(Immutable)。
其中 state 的不可变性你可能还有印象,第三节课中你写 oh-my-kanban 的过程中,使用了 setTodoList() 这样的setState方法来更新state数据,页面才能正确做出反应。
至于props,我们尝试一下用这种方式改写 KanbanCard (临时改动),在组件内部给props多加一个属性,看看会发生什么:
const KanbanCard = (props) => {
props.justWantToSetNewProp = '尝试修改props对象';
return (
<li className="kanban-card">
<div className="card-title">{props.title}</div>
<div className="card-status">{props.justWantToSetNewProp} {props.status}</div>
</li>
);
};
页面白了,React并不允许这样操作props:
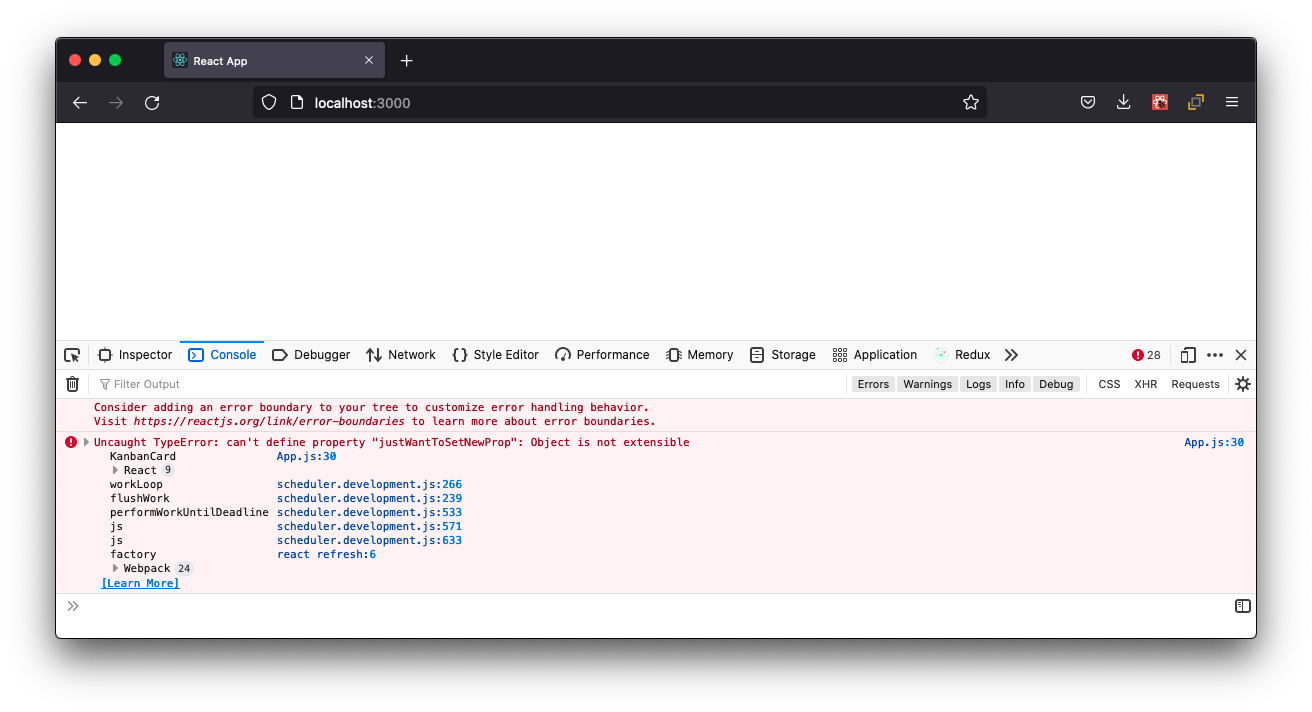
简单来说,一个组件的props应该由父组件传进来,props数据的变动也应该由父组件负责。
什么是Fiber协调引擎?
虽然前面一直在提虚拟DOM,但翻遍React的API文档和源代码,也找不到任何一个类、函数或者变量叫 VirtualDOM ,它更多还是一个抽象概念。React中最接近这个概念的实现,你猜是什么?你说是React元素。嗯,是个好答案。不过要深究React协调的技术细节,那么这个答案也对也不对。
在React的早期版本,协调是一个同步过程,这意味着当虚拟DOM足够复杂,或者元素渲染时产生的各种计算足够重,协调过程本身就可能超过16ms,严重的会导致页面卡顿。
而从React v16开始,协调从之前的同步改成了异步过程,这主要得益于新的Fiber协调引擎。从此在React中更贴近虚拟DOM的,是在Fiber协调引擎中的核心模型 FiberNode。
FiberNode依靠对元素到子元素的双向链表、子元素到子元素的单向链表实现了一棵树,这棵树可以随时暂停并恢复渲染,触发组件生命周期等副作用(Side-effect),并将中间结果分散保存在每一个节点上,不会block浏览器中的其他工作。
Fiber引擎细节比较多,这里暂不展开。你若感兴趣的话请在留言区告诉我,后期也许会有加餐。
螺旋学习曲线
在本节课收尾之前,我想聊些题外话。认真学习的你一定还记得,前面的课程中我挖了不少坑,比如props、state、单向数据流、组件生命周期、事件处理、高阶组件、编译工具等等,那到底什么时候才填坑呢?不急,这节课依然会涉及部分概念,但还没到填坑的时候。
对于学习一门新技术,大家普遍认为过程符合下图这样的学习曲线:

然而我从自己和身边同事朋友的经历中,观察到实际上的学习曲线并不是二维的,而是三维的螺旋曲线,如下图所示(用PowerPoint画3D简直自虐,谁能教我Blender):
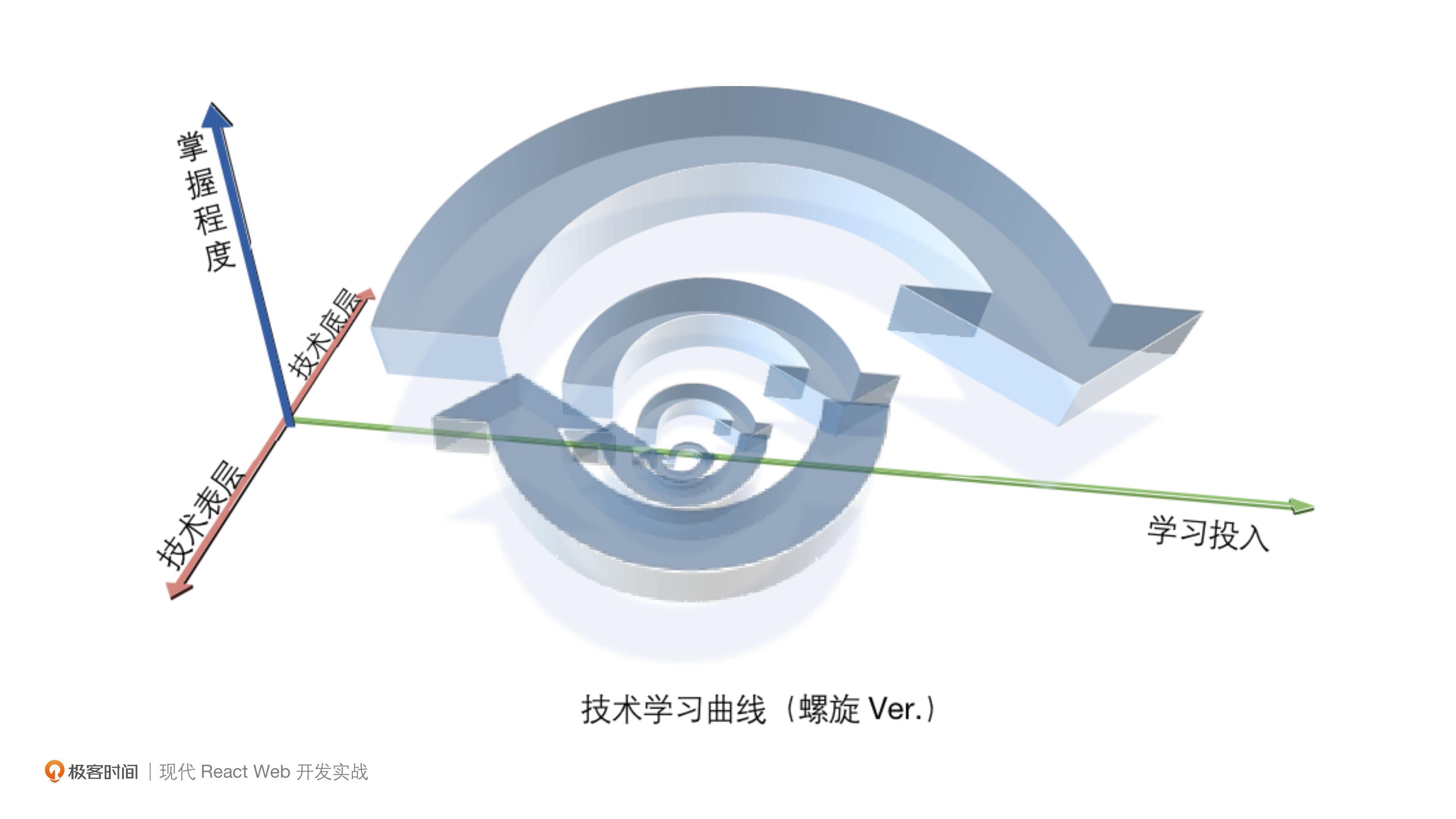
在螺旋曲线中学习过程会经历:学习技术表层 → 学习技术底层 → 回过头来理解表层 → 继续学习更多表层 → 底层 → …如此往复… → 掌握技术。当然,并不是所有人都是这样学习的,但我希望在这门课程中用这一方法能帮到你。
小结
在这节课里,我们学习了React中的虚拟DOM远是真实DOM的抽象,且远比后者更轻量,是React面向开发者的API与内部实现对接的桥梁。也介绍了React组件的props、state或者context改变时,React会触发协调过程对比新旧两棵元素树,计算出有哪些真实DOM需要变更。
这些就是React组件的渲染机制。理解了渲染机制,你就更清楚该如何写出对的组件、快的组件。
下节课我们会稍微轻松一下,转过头来聊聊决定Web应用样式的CSS,看看在React应用中如何写CSS。
思考题
- 这节课中间讲Diffing对比算法时,提到React将会保留相同Tag的HTML元素,并记录有改变的属性。请你思考这里该如何判断属性是否被修改了?对于JS各种数据类型是如何判断相等的?这些判断相等的逻辑在React内部很多地方都有应用。
- 既然每次协调都会调用组件的
render()方法,而render()方法都是开发者实现的,那万一没写好,导致render()每次执行都有很大开销,会对React渲染产生什么后果?另外在JS里,写什么样的代码会产生很大开销呢?
欢迎把你的思考和想法分享在留言区,我们下节课再见!
- Dearest 👍(21) 💬(1)
想多了解 React Fiber, 想了解React18对实际开发的影响
2022-09-11 - 学习前端-react 👍(5) 💬(1)
思考题一:也是猜测。对于相同的标签元素,可能变化的就是children 和 attr。那attr来说,因为到最后都会生成一个对象去描述jsx,所以这些attrs可以做对比 简单类型可以直接做对比,引用类型可以比较是否同一个引用。类似浅拷贝。 判断数据类型目前比较常规的是通过object prototype to string call 去判断。 这时同样有一个问题如果父组件的属性发生变化 那么子组建会重新渲染吗?
2022-09-08 - 海华呀 👍(3) 💬(1)
1、相同tag,属性修改的实现 应该新旧属性都遍历一遍,遍历旧的因为要移除一些可能存在的事件监听,遍历新的是为了查看属性新增更新情况。 2、尽量不要在JSX中写大量JS语句,对事件的处理,要另外写在函数中,不要直接在JSX中写
2022-10-17 - joel 👍(2) 💬(1)
老师咨询一个问题: 比如一个函数组件: function A (){ return (<span>我是组件A</span>) } 是不是只要这个函数执行了,就会生成一个虚拟节点,然后通过diff 算法对比是否需要在真实的dom 结构中更新这个节点。
2022-09-15 - 里脊 👍(1) 💬(2)
当一个组件的状态发生变化,会触发整个虚拟dom的比对吗?
2022-10-23 - 学习前端-react 👍(1) 💬(1)
小结一下: 我们讲述了 react的分层。我们在上层使用了jsx ,中间抽象了一层中间层,中间层用来操作底层dom,同时接收上层的UI 。 中间层的操作被称为协调 reconcilation 。react使用了fiber来做这个事。渲染方式是对比两颗fiber树,在对比的过程中寻找最优解,例如我们需要在list中加上key就是如此。 一般协调会有两种方式 推或者拉。轮训造成的开销过大,一般会选择push的方式。 fiber的特点是一个链表的形式所以是可以更好的启动停止渲染过程,降低对于主进程的占用。
2022-09-05 - Geek_0c843c 👍(1) 💬(2)
想多了解下react fiber
2022-09-05 - 学习前端-react 👍(0) 💬(1)
fiber 的理解: 首先不是普遍意义上的 parent-children 结构 而是 parent-child的结构,他是一个链表结构。 Parent-child - child - sibling,即父子关系是单向的,通过sibling完成兄弟之前的链接。 ”这棵树可以随时暂停并恢复渲染, 触发组件生命周期等副作用(Side-effect), 并将中间结果分散保存在每一个节点上, 不会 block 浏览器中的其他工作。“ 这里引用了文档中描述fiber 简要做了四件事情,但是好像都不太理解他是怎么操作的。
2022-09-17 - 01 👍(0) 💬(1)
html元素 主要是判断 props 是否相等, 简单粗暴
2022-09-16 - Pioneer 👍(0) 💬(1)
想学习下react fiber
2022-09-11 - 船长 👍(0) 💬(1)
思考题 1:以我目前后端的水平我能想到的是:React 先判断属性的类型变没变,如果变了,则直接触发渲染。否则再进行值的对比
2022-09-07 - 杨永安 👍(0) 💬(2)
开销一般会在DOM操作和大数据数组等操作上发生吧
2022-09-03 - 阳宝 👍(1) 💬(0)
打卡
2022-09-04 - Geek_24d08b 👍(0) 💬(0)
思考题1:使用Object.is()判断属性是否修改 思考题2:如果render开销很大可能会造成页面卡顿情况,会在造成大开销的代码场景: 1)多余的setState,引起页面重复渲染 2)文章中提到的直接对DOM元素进行操作
2024-03-06