18 如何使用移动平台的硬件编码器?
你好,我是展晓凯。今天我们来一起学习如何使用移动平台的硬件编码器给视频编码。
在移动平台的视频场景中合理地使用硬件编码器,能够很大程度上提升App的性能,所以这节课我们来学习Android平台和iOS平台视频硬件编码器的使用方法。在Android平台我们一般使用MediaCodec编码器,而在iOS平台我们一般使用VideoToolbox来完成硬件编码。
Android平台的硬件编码器 MediaCodec
上节课我们已经介绍了预览控制器类如何调用编码器模块进行编码,并且也已经实现了软件编码器的子类,这节课我们就来完成硬件编码器子类的实现。
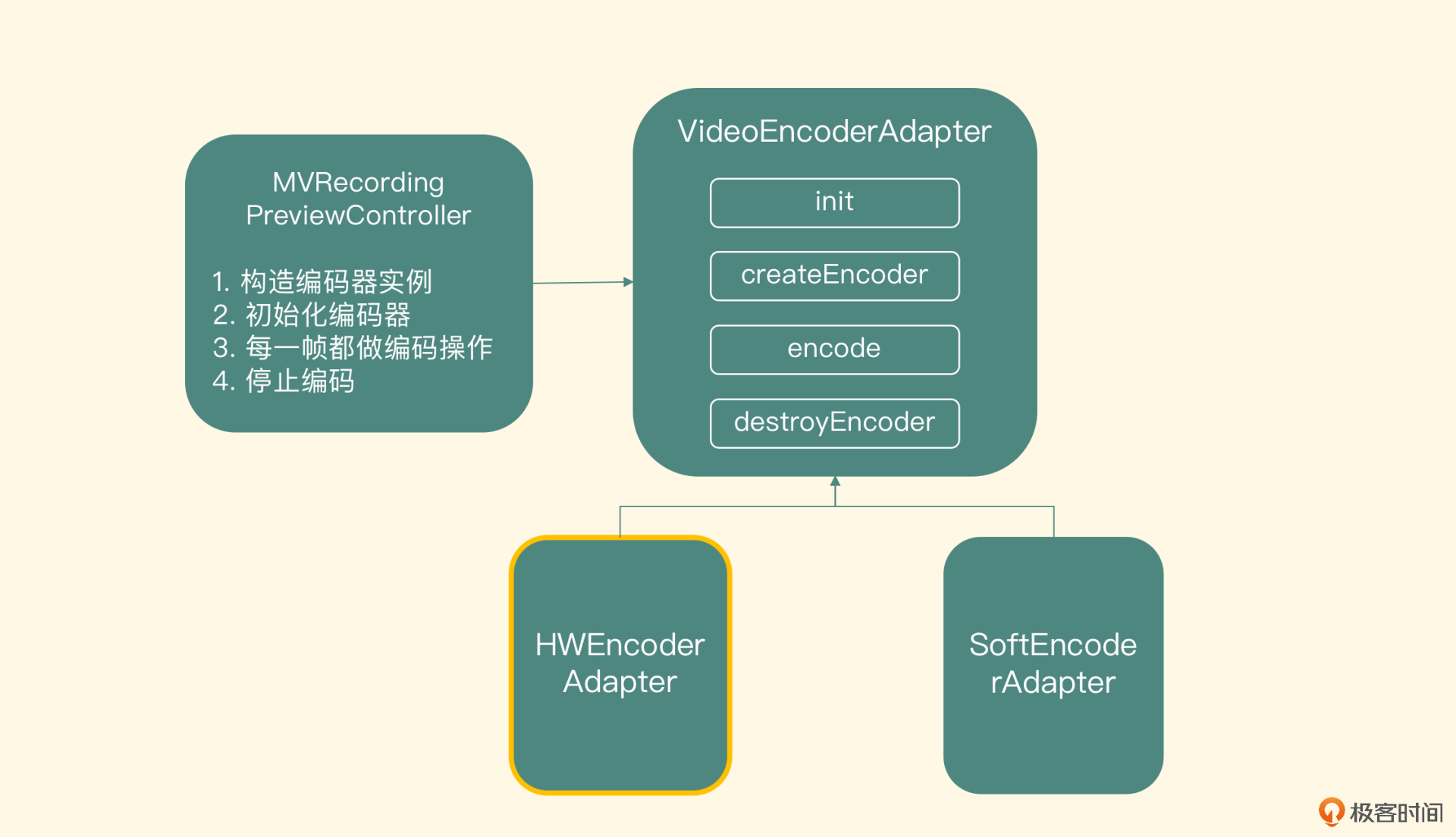
新建的hw_encoder_adapter类继承自video_encoder_adapter这个类,然后实现核心的接口,包括创建编码器的createEncoder方法、实际编码的encode方法以及销毁编码器的destroyEncoder方法。
在Android 4.3系统之后,使用MediaCodec给视频编码是官方推荐的方式。尽管Android的碎片化比较严重,会导致一些兼容性问题,但是硬件编码器的性能和速度提升的收益是非常可观的。并且在4.3系统之后,我们可以通过Surface来配置编码器的输入,降低了显存到内存的数据交换时间,大大提升了整个录制场景的体验。前面我们学过使用MediaCodec来编码AAC数据,而编码视频的工作流程和音频是一样的,我们先来回顾一下MediaCodec的工作流程。

因为MediaCodec的API接口都是在Java层,而我们整个视频预览编码的架构都是在Native层构建的,所以需要在Native层调用Java层MediaCodec的API接口,在这个hw_encoder_adapter类的构造方法中需要把JavaVM和jObject传递进来,方便后续调用。
创建编码器
libx264编码器需要输入内存中的YUV数据,所以我们要在软件编码适配器中进行显存到内存的数据交换操作。而我们这节课使用的MediaCodec是允许直接以显存中的纹理ID作为输入的,这样就减少了显存到内存的数据交换,保证了提供数据的速度。那具体怎么把纹理ID作为MediaCodec的输入呢?
首先在Native层调用Java层封装的创建编码器的方法,把视频的宽、高、比特率、帧率传递过去,创建编码类型为“video/avc”的MediaCodec实例,然后调用configure方法配置编码器。当编码器配置成功之后,调用MediaCodec的createInputSurface方法创建出这个MediaCodec的输入Surface,而这个输入Surface就是纹理ID能直接作为编码器输入的关键。
MediaFormat format = MediaFormat.createVideoFormat(MIME_TYPE, width, height);
format.setInteger(MediaFormat.KEY_COLOR_FORMAT, MediaCodecInfo.CodecCapabilities.COLOR_FormatSurface);
format.setInteger(MediaFormat.KEY_BIT_RATE, bitRate);
format.setInteger(MediaFormat.KEY_FRAME_RATE, frameRate);
format.setInteger(MediaFormat.KEY_I_FRAME_INTERVAL, IFRAME_INTERVAL);
mEncoder = MediaCodec.createEncoderByType(MIME_TYPE);
mEncoder.configure(format, null, null, MediaCodec.CONFIGURE_FLAG_ENCODE);
Surface mInputSurface = mEncoder.createInputSurface();
mEncoder.start();
拿到这个InputSurface之后(与SurfaceView中获取出来的Surface对象一致),就把它传递到Native层,转换成ANativeWindow,然后利用EGLCore创建出一个EGLSurface作为渲染目标。当绑定了这个EGLSurface后的渲染,就可以给MediaCodec作为视频帧的输入了。
紧接着创建一个jbyteArray类型的buffer,用来接收MediaCodec编码成功后的H264数据。为了不影响预览线程的刷新频率,需要把从MediaCodec中拉取数据的操作放到一个新的线程里,所以在这里要创建出一个线程,单独做拉取编码器的编码数据操作。另外因为MediaCodec编码H264数据的时候,会在前几帧中返回sps和pps信息,所以这里准备好sps与pps的buffer。这样初始化部分就讲完了,接下来我们看一下具体编码数据的过程。
编码数据
编码方法的实现分为两部分,一部分是把纹理ID送入编码器,另一部分是从编码器中拉取H264的码流。
把纹理ID送入编码器
首先调用库EGL的makeCurrent方法,把encoderSurface作为渲染目标,调用renderer把输入的纹理ID渲染到Surface上去,再给编码器设置编码的时间,然后给拉取编码数据的线程发送一个指令,让它去MediaCodec里拉取H264的数据,最后调用库EGL的swapBuffer渲染数据,核心代码如下:
if (startTime == -1) startTime = getCurrentTime();
int64_t curTime = getCurrentTime() - startTime;
int expectedFrameCount = (int)(curTime / 1000.0f * frameRate + 0.5f);
if (expectedFrameCount < encodedFrameCount) {
// need drop frames
return;
}
encodedFrameCount++;
if(EGL_NO_SURFACE != encoderSurface){
eglCore->makeCurrent(encoderSurface);
renderer->renderToView(texId, videoWidth, videoHeight);
eglCore->setPresentationTime(encoderSurface, ((khronos_stime_nanoseconds_t) curTime) * 1000000);
handler->postMessage(new Message(FRAME_AVAILIBLE));
eglCore->swapBuffers(encoderSurface)
}
前8行代码实际上是控制编码帧率的一个实现,首先把第一次编码取得的当前时间戳记录为开始编码的时间戳startTime,之后再调用编码操作的时候,取出当前时间减去startTime,算出编码时长,然后根据帧率和编码时长算出我们期待的编码数目expectedFrameCnt,并在每编码一帧时给encodedFrameCnt加1。通过比较这两者的关系,来控制是否要把当前视频帧送给编码器,在第12行设置视频帧的时间戳的时候,使用这个时间就可以了。
拉取H264码流
拉取MediaCodec编码的H264数据的这个线程是如何工作的呢?
首先在Java层会调用MediaCodec的dequeueOutputBuffer方法,这个方法的返回值有以下几种状态:
- INFO_TRY_AGAIN_LATER,代表获取数据超时,稍后再试。
- INFO_OUTPUT_FORMAT_CHANGED,输出格式发生变化,需要重新获取新的输出格式。
- INFO_OUTPUT_BUFFERS_CHANGED,输出的缓冲区发生变化,需要重新获取新的缓冲区。
获取出来的返回值如果不是上述的几个状态,并且又大于0的话,代表的是outputBuffers的Index,我们就可以取出这个Index对应的编码数据了。我们通过bufferInfo里面的描述把这部分的数据获取出来,并存入Native层准备好的jbyteBuffer里,最后把这个buffer返还给MediaCodec的输出缓冲队列。
在Native层拿到这个NALU数据之后,要判断这个NALU的类型,也就是要拿出这个buffer数据里面index为4的数据“与上0X1F”。如果是sps和pps,就存储在前面准备好的sps和pps的全局变量中。在后面遇到关键帧的NALU要插入sps和pps形成一个合法的Annexb的码流。代码如下:
int nalu_type = (outputData[4] & 0x1F);
if (H264_NALU_TYPE_SEQUENCE_PARAMETER_SET == nalu_type) {
spsppsBufferSize = size;
spsppsBuffer = new byte[spsppsBufferSize];
memcpy(spsppsBuffer, outputData, spsppsBufferSize);
} else if(NULL != spsppsBuffer){
if(H264_NALU_TYPE_IDR_PICTURE == nalu_type) {
fwrite(spsppsBuffer, 1, spsppsBufferSize, h264File);
}
fwrite(outputData, 1, size, h264File);
}
可以看到第5行代码适用于存储sps和pps信息,第8行代码是在判断出关键帧类型的时候写入sps和pps,第10行代码是直接写入一个ES流的数据。
销毁编码器
最后我们来看一下销毁编码器方法的实现,首先要停掉拉取编码器数据的线程,然后调用Java层的方法关掉MediaCodec,并释放相关的编码器资源,Java层会调用MediaCodec的stop和release方法,最后把分配的jbyteArray类型的buffer释放掉,同时也把全局的sps和pps的buffer释放掉并关闭文件。
这样,Android平台的硬件编码器就讲完了,之后你也可以在我们的视频录制器项目中再结合代码深入研究,接下来让我们一起学习iOS平台的硬件编码器的使用吧。
iOS平台的硬件编码器
在iOS 8.0以后,系统提供了VideoToolbox编码API,这个API充分利用硬件来做编码工作,来提升App的性能和编码速度。使用VideoToolbox可以给系统带来两个好处。
- 提高编码性能,大大降低CPU的使用率。
- 提高编码效率,编码一帧的时间缩短。
当然VideoToolbox既可以充当编码器又可以充当解码器,这节课我们主要介绍它作为编码器的工作流程,讲一讲如何使用VideoToolbox把摄像头采集到的纹理编码成一段H264的码流。我们会创建一个名叫H264HWEncoderImpl类,然后按照ELImage的组件规则把它封装进ELImage框架中,集成进去之后,就可以给原来的预览项目增加录制视频的功能。

VideoToolbox硬件编码器
输入与输出
我们先来看一下使用VideoToolbox进行编解码的输入和输出是什么,只有明确了这一点,才能知道如何给VideoToolbox提供视频帧的原始数据,还有怎么从VideoToolbox里获取编码后的数据。我们可以看一下VideoToolbox的数据流转结构图。

从上图中可以看到,编码器的输入是CVPixelBuffer类型的结构体,输出是CMSampleBuffer类型的结构体。所以在ELImage框架中,我们需要把纹理ID封装成CVPixelBuffer的数据结构。这个数据结构是使用VideoToolbox编码的核心,必须要了解清楚。Apple Developer官网上对于这个数据结构给出的解释是,在主内存中存储所有像素点数据的一个对象。
那什么是主内存呢?你可以这样理解,主内存其实并不是我们平时所操作的内存,但它可以关联到内存中的地址,简单理解就是这块存储区域在缓存里,但是我们在访问这块区域之前必须先锁定这块区域。
然后才可以访问这一块内存区域,获取出内存中的指针。
操作data这个变量可以给这块内存区域填充内容或读取内容,使用完之后,要解锁这块区域。
从它的使用方式来看,不是普通的内存访问,否则不会在访问内存区域之前和之后加上锁定、解锁等操作。前面我们也说过,做视频开发时有一个原则就是尽量少做显存和内存的交换,在iOS平台上,我们应该使用它提供的加速API来完成这样的操作。 我们可以回顾一下第14节课的内容,Camera回调的YUV数据就存储在CVPixelBuffer类型的对象里,只不过当时使用的引用类型是CVImageBufferRef,但是在iOS头文件定义中可以看到,它们是等同的。
你可以回顾一下当时在Camera的回调中我们是如何把CVPixelBuffer里面的内容构造成纹理对象的。常规手段就是手动获取YUV数据的内存地址,然后利用OpenGL提供的glTexImage2D方法,把内存中的数据上传到显存构建的纹理对象上。而iOS的CoreVideo这个framework提供的加速方法可以把纹理和CVPixelBuffer关联起来。
所以我们需要把一个纹理ID和一个CVPixelBuffer通过上述这个方法关联起来,然后把这个纹理ID作为目标(实际是这个纹理ID绑定的FBO)进行绘制,就可以在CVPixelBuffer中获取到数据了,最后把CVPixelBuffer送给VideoToolbox就可以了。
接下来我们看这个编码器输出的类型,从图里可以看出这是一个CMSampleBuffer类型的对象,如果你还有印象的话,第14节课Camera回调给我们的视频帧也是CMSampleBuffer类型的对象,但是它们所包含的内容完全不一样,Camera预览返回的CMSampleBuffer里存储的数据是一个CVPixelBuffer,而经过VideoToolbox编码输出的CMSampleBuffer里存储的数据是一个CMBlockBuffer的引用,如图所示。

图片展示了CMSampleBuffer的构成方式,左边代表了压缩数据(编码器输出的格式)的构成,右边代表了非压缩格式(摄像头采集到的数据或者解码器解码出来的数据)的构成。而CMBlockBuffer就是编码之后数据存放的对象,我们可以调用CMBlockBufferGetDataPointer方法来获取出内存中的指针,然后可以使用对应内存中的数据去写文件或者发送到网络。
初始化与构建编码器
弄清楚了编码器的输入和输出,下面我们就来看一下如何构建出编码器。
初始化方法签名如下:
- (void)initEncode:(int)width height:(int)height fps:(int)fps
maxBitRate:(int)maxBitRate avgBitRate:(int)avgBitRate;
这个初始化方法的职责就是构建编码器,实现主要分为两部分,一是构建编码器会话,另外一个就是给编码器设置参数。还记得之前我们常说的一句关于iOS多媒体API的规则吗?使用任何API之前都要配置对应的Session。
使用麦克风和Speaker之前,需要配置的是AudioSession,使用Camera之前需要配置的是AVCaptureSession,而这里需要配置的就是VTCompressionSession。这个会话就代表了我们要使用编码器,使用解码能力的时候需要配置VTDecompressionSessionRef。那如何定制一个我们需要的编码器会话呢?
首先调用VTCompressionSessionCreate方法,把我们要编码的视频的宽、高、编码器类型(kCMVideoCodecType_H264)、回调函数以及回调函数上下文传递进去,构造出一个编码器会话。这个函数的返回值是一个OSStatus类型,如果构造成功则返回的是0,否则就要给出初始化编码器会话失败的提示。构造成功之后要给这个会话设置参数,设置参数的代码如下:
VTSessionSetProperty(EncodingSession, kVTCompressionPropertyKey_RealTime, kCFBooleanTrue);
VTSessionSetProperty(EncodingSession, kVTCompressionPropertyKey_ProfileLevel, kVTProfileLevel_H264_High_AutoLevel);
VTSessionSetProperty(EncodingSession, kVTCompressionPropertyKey_AllowFrameReordering, kCFBooleanFalse);
VTSessionSetProperty(EncodingSession, kVTCompressionPropertyKey_MaxKeyFrameInterval, (__bridge CFTypeRef)(@(fps)));
VTSessionSetProperty(EncodingSession, kVTCompressionPropertyKey_ExpectedFrameRate, (__bridge CFTypeRef)(@(fps)));
VTSessionSetProperty(EncodingSession, kVTCompressionPropertyKey_DataRateLimits, (__bridge CFArrayRef)@[@(maxBitRate / 8), @1.0]);
VTSessionSetProperty(EncodingSession, kVTCompressionPropertyKey_AverageBitRate, (__bridge CFTypeRef)@(avgBitRate));
代码里的第一个参数设置的是需要实时编码;第二个参数设置的是H264的Profile,使用的是High的AutoLevel规格;第三个参数的设置代表不要B帧;第四个参数是设置关键帧的间隔,也就是gop size;第五个参数是设置帧率;第六个参数和第七个参数共同来控制编码器输出的码率。设置完这些参数之后,调用VTCompressionSessionPrepareToEncodeFrames方法,告诉编码器可以开始编码了。
编码视频帧
接下来,我们看encode的方法,函数的输入参数是一个CVPixelBuffer, 然后还需要构造出当前编码视频帧的时间戳和时长,最后把这三个参数传递给编码方法,给这一帧视频编码。
int64_t currentTimeMills = CFAbsoluteTimeGetCurrent() * 1000;
if(-1 == encodingTimeMills){
encodingTimeMills = currentTimeMills;
}
int64_t encodingDuration = currentTimeMills - encodingTimeMills;
CMTime pts = CMTimeMake(encodingDuration, 1000.); // timestamp is in ms.
CMTime dur = CMTimeMake(1, m_fps);
VTEncodeInfoFlags flags;
OSStatus statusCode = VTCompressionSessionEncodeFrame(EncodingSession, imageBuffer, pts, dur, NULL, NULL, &flags);
if (statusCode != noErr) {
error = @"H264: VTCompressionSessionEncodeFrame failed ";
return;
}
在创建编码器会话的时候,我们指定了一个回调函数,这个回调函数是在编码器编码成功一帧之后,把编码的这一帧数据封装到CMSampleBuffer结构中回调这个函数,而我们需要做的就是在这个回调函数里拿出编码之后的H264数据。回调函数原型如下:
void didCompressH264(void *outputCallbackRefCon, void *sourceFrameRefCon,
OSStatus status, VTEncodeInfoFlags infoFlags, CMSampleBufferRef sampleBuffer)
在这个回调函数里,我们需要处理编码之后的数据。首先判断status,如果编码成功就返回0(实际上头文件中定义了一个枚举类型是noErr);如果不成功不作处理。成功了的话,首先判断一下编码成功后的当前帧是否是关键帧,判断关键帧的方法如下:
CFArrayRef array = CMSampleBufferGetSampleAttachmentsArray(sampleBuffer, true);
CFDictionaryRef dic = (CFDictionaryRef)CFArrayGetValueAtIndex(array, 0);
BOOL keyframe = !CFDictionaryContainsKey(dic, kCMSampleAttachmentKey_NotSync);
为什么要判断关键帧呢?
因为VideoToolbox编码器在每一个关键帧前面都会输出sps和pps信息,所以如果这一帧是关键帧,就取出对应的sps和pps信息。
那怎么取出对应的sps和pps信息呢?图里提到CMSampleBuffer里面有一个成员是CMVideoFormatDesc,而sps和pps信息就在这个对视频格式的描述里面。取出sps的代码如下:
CMFormatDescriptionRef format = CMSampleBufferGetFormatDescription(sampleBuffer);
size_t sparameterSetSize, sparameterSetCount;
const uint8_t *sparameterSet;
size_t paramSetIndex = 0;//代表sps
OSStatus statusCode = CMVideoFormatDescriptionGetH264
ParameterSetAtIndex(format, paramSetIndex, &sparameterSet, &sparameterSetSize,
&sparameterSetCount, 0 );
取出pps的代码如下:
size_t pparameterSetSize, pparameterSetCount;
const uint8_t *pparameterSet;
size_t paramSetIndex = 1;//代表pps
OSStatus statusCode = CMVideoFormatDescriptionGetH264
ParameterSetAtIndex(format, paramSetIndex, &pparameterSet, &pparameterSetSize,
&pparameterSetCount, 0 );
这样我们就成功地取出了sps和pps的信息了,接着再把这一帧(有可能是关键帧也有可能是非关键帧)的实际内容提取出来进行处理。首先,取出这一帧的时间戳,代码如下:
CMTime pts = CMSampleBufferGetPresentationTimeStamp(buffer);
double presentationTimeMills = CMTimeGetSeconds(pts)*1000;
然后可以拿出具体的压缩后的数据,代码如下:
取出真正的压缩后的数据CMBlockBuffer,就可以访问这块内存,拿出具体的数据了,然后再根据是否是关键帧,决定要不要在前面加入sps和pps,写成Annexb格式的H264码流。
释放编码器
最后是释放编码器,首先调用VTCompressionSessionCompleteFrames方法,强制编码器完成编码行为,然后调用VTCompressionSessionInvalidate方法,结束编码器会话,最后调用CFRelease方法,释放编码器会话。
到这里,我们已经把VideoToolbox的使用封装到了这个H264HWEncoderImpl类里,并提供出了初始化、编码和销毁的接口,那接下来就把这个类集成到我们的ELImage框架中吧。
把编码器集成到ELImage框架
回顾第14节课的内容,我们已经把Camera连接到了GLImageView上面,用户也可以在屏幕上预览到摄像头采集到的图像了。在这个设计里,Camera是输入节点,它把采集到的YUV数据渲染成为纹理对象,然后传递给GLImageView,GLImageView把纹理对象渲染到UIView上。
而这节课我们要书写的VideoEncoder也是一个输出节点,在Camera的targets里增加这个VideoEncoder的输出节点,然后这个输出节点负责把纹理对象编码成H264码流,并写到磁盘里。怎么构建这个节点并集成入ELImage框架里呢?
首先建立ELImageVideoEncoder实现ELImageInput这个Protocol,代表我们新建立的这个节点是可以被输入纹理对象的,然后书写初始化方法,可以让调用端在创建这个节点的时候把编码参数传递进来,初始化方法定义如下:
- (id) initWithFPS: (float) fps maxBitRate:(int)maxBitRate
avgBitRate:(int)avgBitRate encoderWidth:(int)encoderWidth
encoderHeight:(int)encoderHeight;
因为实现了ELImageInput这个Protocol,所以需要重写保存输入纹理和渲染纹理的方法,在这个类里新建一个ELImageTextureFrame指针类型的纹理,来保存输入的纹理对象,然后建立一个EncoderRenderer,把输入纹理对象渲染到编码纹理对象上。但这个渲染过程有两个细节需要注意。
- 要把纹理对象渲染之后送到编码器里,就会涉及OpenGL坐标系转换到计算机坐标系的问题。所以在渲染到目标纹理对象的时候,要把整个图像HFlip一下,也就是把每个坐标的Y顶点0、1互换一下。
物体坐标如下:
纹理坐标如下:
static const GLfloat hFlipTextureCoordinates[] = {
0.0f, 1.0f,
1.0f, 1.0f,
0.0f, 0.0f,
1.0f, 0.0f,
};
- 渲染到的目标纹理对象需要交给编码器编码,也就是说我们的目标纹理对象必须和一个CVPixelBuffer关联起来,所以在构建目标纹理对象的时候,一定不能和创建普通的纹理对象一样。其实,把一个纹理对象和一个CVPixelBuffer关联起来的方法,在ELImageVideoCamera这个类里已经使用过了,只不过这里关联的纹理格式会使用iOS特有的BGRA格式。代码如下:
CVOpenGLESTextureCacheCreateTextureFromImage (kCFAllocatorDef
ault, coreVideoTextureCache, renderTarget, NULL, GL_TEXTURE_2D,
GL_RGBA, _width, _height, GL_BGRA,GL_UNSIGNED_BYTE, 0,
&renderTexture);
代码里的renderTarget就是一个CVPixelBuffer的引用,和之前的渲染一样,上述代码将源纹理对象渲染到了目标纹理对象,只不过这里的处理就是把图像做一个上下翻转。
再来看最关键的一步,渲染完成之后,实际上渲染的内容就会在这个CVPixelBuffer里,这样我们就可以把这个renderTarget传递给编码器进行编码操作了。当然,在交给编码器之前要先锁定这个CVPixelBuffer,编码器使用完了之后再解锁。书写完这个节点,整个ELImage框架就可以完成预览、录制这两个场景了。
接下来,我们了解一下iOS系统为开发者提供的非常强大的多媒体API库,扩展一下知识面。当然万变不离其宗,这一些高级的API都是基于最底层的VideoToolbox进行封装的,并且提供了单一的接口来完成某些具体的功能。
iOS高层次的硬件编解码API
先来看一下图片,它展示了AVFoundation与VideoToolbox的关系。

如图所示,iOS平台提供的AVFoundation底层使用了VideoToolbox,但是它们的关注点不一样。VideoToolbox更关注编码成内存中的CMSampleBuffer结构体,以及解码成主内存(或者理解为显存)里的CVPixelBuffer结构体,而AVFoundation更关注解码直接显示以及编码到文件中。
下面我们来看一下AVFoundation这个层次提供的几个重要的API。
- AVAssetWriter
从名字就可以看出,这是为了写入本地文件提供的API,这个类可以方便地把图像和音频写成一个完整的本地视频文件。它是如何利用VideoToolbox编码视频文件的呢?我们可以参考下面的图片来理解。

可以看到,AVAssetWriter是从OpenGL ES中拿到纹理对象,关联到CoreVideo这个framework提供的CVPixelBuffer里,然后使用VideoToolbox编码,最后把编码的H264码流写到H264文件或者封装到一个视频文件中。但如果只是封装成一个MP4文件,其实并不需要这么麻烦,我们可以利用iOS给我们封装好的API很简单地完成这种场景,如下图所示。

可以看到,AVAssetWriterInput把编码器的编码和后续的处理和封装的工作组装到了一起,提供了更单一的接口调用,完成的功能也更加清晰,这也是iOS平台提供的多媒体API强大的地方。当然这仅限于本地文件,如果在直播场景中需要把编码后的码流推送到流媒体服务器的话,就不能使用这个API了。
- AVAssetReader
从名字上来看,这是为了读取本地文件而存在的一个类。这个类可以方便地把本地文件中的音频和视频解码出来。下面我们来看一下怎么用VideoToolbox解码视频,然后经过处理,最终再使用VideoToolbox编码成为一个本地的视频文件。

虽然前面没有介绍怎么使用VideoToolbox解码H264数据,但是你可以认为它就是编码的一个逆过程,上图中需要我们自己写很多代码来控制多种状态,包括输入、输出等。而在AVFoundation里,针对解码部分,iOS平台直接封装了一个更高级的API,你可以看一下图片左边的内容。

AVAssetReaderOutput也只支持本地文件的解码,不支持网络媒体文件的输入。同样,在这里也不再展示代码了,你可以参考GPUImage框架里的GPUImageMovie这个类,我们在里面的离线处理操作的场景,详细地对AVAssetReaderInput这个API的使用做出了说明。
- AVAssetExportSession
这个类可以用来拼接视频、合并音频和视频、不做任何处理的转换格式以及压缩视频等多种场景,其实它是对VideoToolbox解码、编码的一个更高层次的封装,如图所示。

通过图片可以看到,这个类不允许我们进行中间的处理操作,显然它是一个更高层次的封装,只允许我们设置一些预设和提供输入输出文件路径等,所以相比使用VideoToolbox,或者使用AVAssetReader和AVAssetWriter来实现,AVAssetExportSession提供的功能更单一,接口也更简单。
在我们工作中,在不同的场景下选用不同的技术实现是非常重要的,这不单单会影响开发的效率,也会直接影响产品的体验。学习iOS平台的多媒体时,了解这些API对我们的工作有很大帮助。
小结
最后,我们一起来回顾一下今天的内容。
Android平台推荐使用的硬件编码器是MediaCodec,把这个编码器集成到Android的摄像头预览项目中需要以下几步:
- 创建硬件编码器,并获取出它的输入Surface。
- 在预览的OpenGL ES线程中将纹理ID渲染到上一步获得的Surface上。
- 从MediaCodec中拉取H264码流,然后转换成Annexb格式的码流写到文件中。
在iOS平台,我们使用VideoToolbox编码视频,其中的重点就是书写一个编码节点集成入ELImage框架中,主要分为以下几步:
- 初始化与构建VideoToolbox编码器。
- 将纹理ID渲染到关联了CVPixelBuffer的纹理上去。
- 将CVPixelBuffer送入编码器进行编码,得到编码之后的CMSampleBuffer。
- 取出CMSampleBuffer中的H264数据,并封装成Annexb格式的码流写入文件。
最后我们讲解了iOS的AVFoundation是如何对VideoToolbox进行封装,并实现各种场景的,主要包括AVAssetWriter、AVAssetReader和AVAssetExportSession三个类。
这节课输出的都是H264文件,当使用ffplay观看H264文件的时候,播放的速度是非常快的。这是因为裸的H264流是没有时间戳概念的,它不像音频只要指定好采样率、声道数、表示格式,声音的渲染端,就可以以固定频率来渲染音频数据了。虽然sps和pps中也指明了视频的宽、高以及fps等信息,但是普通的播放器并不支持按照一定频率进行播放。播放这个H264文件的时候也没有声音,不过不要着急,我们完成视频录制器后,会输出一个完整的视频。
思考题
最后我来考考你,H264的码流分为几种封装格式?MP4文件是哪一种格式?欢迎在评论区写出你的思考,也欢迎你把这节课分享给更多对音视频感兴趣的朋友,我们一起交流、共同进步。下节课再见!
- peter 👍(1) 💬(1)
请教老师几个问题啊: Q1:MediaCodec可以做解码操作吗? Q2:MediaCodec是硬件还是软件? 我的理解是:MediaCodec并不是硬件,是软件,相当于硬件的接口; 调用关系是:Java层API ---》MediaCodec---》具体的硬件(应该是一个芯片) Q3:MediaCode如果是软件的话,属于哪一层?Native层吗? 从Android系统架构来说,MediaCodec属于哪一层?FrameWork层吗? Q4:iOS部分,主内存是缓存,此缓存是指CPU的三级缓存吗? Q5:加锁与解锁是针对内存还是缓存?
2022-09-02 - 我的無力雙臂 👍(0) 💬(1)
请教下为啥不讲讲h265呢
2022-09-02