14 iOS平台如何采集视频画面?
你好,我是展晓凯。今天我们一起来学习iOS平台的视频画面采集。
前面我们学习的音频采集与编码的方法,可以用来实现音频录制器的功能。但如果要完成视频录制器的功能我们还需要掌握视频采集与编码方面的内容,所以从今天开始我们来学习如何采集视频的画面。
采集到视频画面之后一般会给用户预览出来,这就要结合之前我们学过的视频画面渲染方面的知识,再加上视频的编码,这样就可以在用户点击录制的时候给视频画面编码并且存储到本地了。这节课我们就先来一起学习在iOS平台如何采集视频画面。
视频框架ELImage架构设计
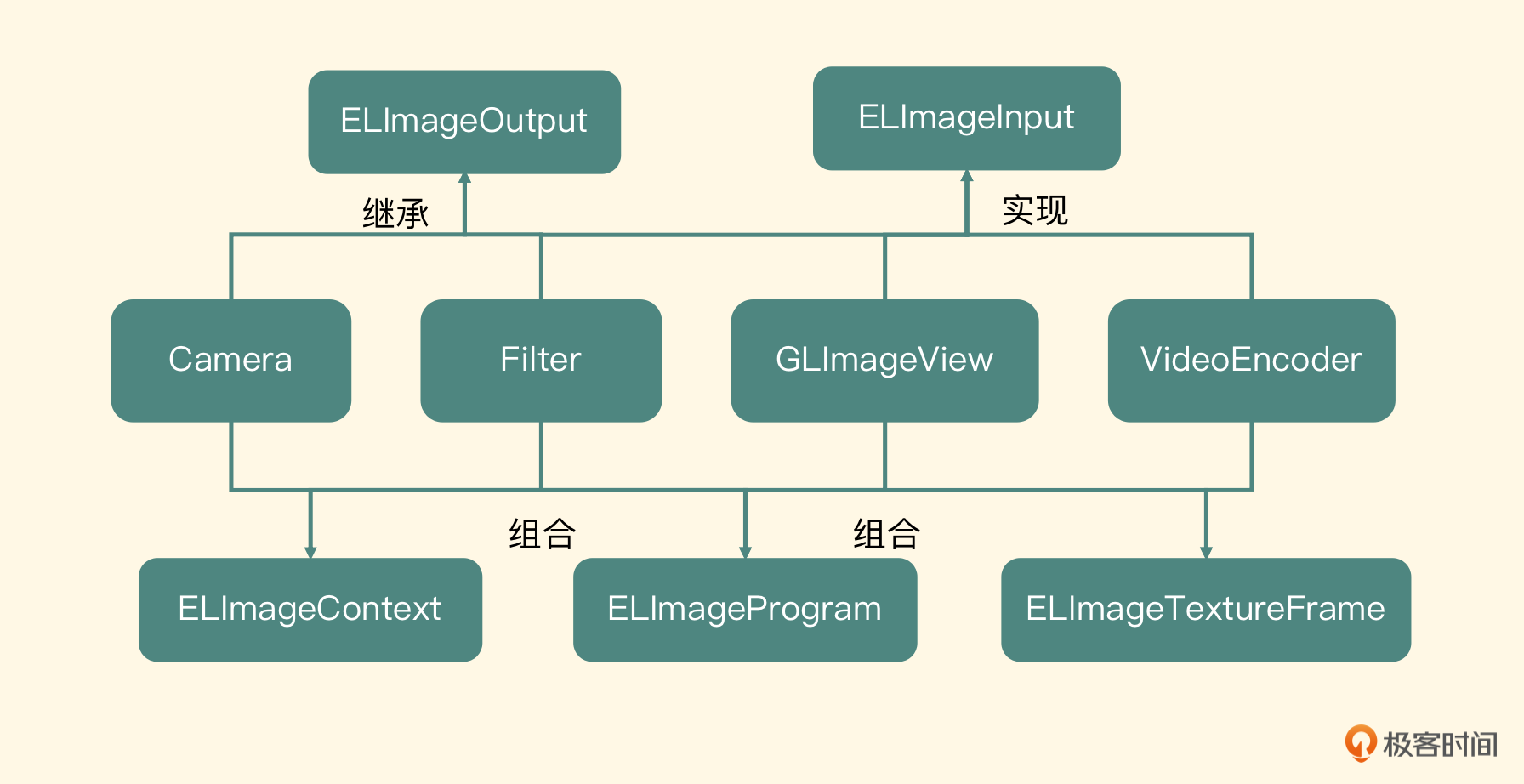
在iOS平台使用Camera来采集视频画面的API接口比较简单,但要设计出一个优秀的、可扩展的架构,也不是一件容易的事情。所以这节课我会带你设计并实现出一个架构,这个架构基于摄像头采集驱动,中间可以支持视频特效处理,最终用OpenGL ES渲染到UIView上,且支持扩展插入编码节点。我们先来看一下整体的架构图。

左边第一个节点是用系统提供的Camera接口,采集出一帧内存中的图像,然后将这个图像上传到显存中成为YUV的纹理对象,最后将这个YUV格式的纹理重新渲染到一个RGBA的纹理上。接着将这个RGBA类型的纹理对象传到中间的Filters节点,这个节点内部会使用OpenGL ES来处理这个纹理对象,最后输出一个纹理对象到下面的节点。
下一级节点是GLImageView或将来扩展出来的组件VideoEncoder,拿到中间Filters节点输出之后,进行屏幕渲染或者编码操作。这样一帧图像就从采集、处理到最后预览让用户看到就完成了,并且可以满足我们之后做编码以及图像处理的需求。
继续看图,你会发现Camera和Filter这些节点是可以输出纹理对象的,也就是它们的目标纹理对象要作为后一级节点的输入纹理对象;另外,Filter、GLImageView以及VideoEncoder需要上一级节点提供输入纹理对象。通过以上两个特点,我们就可以抽象出两个规则。
- 凡是需要输入纹理对象的,都是Input类型。
- 凡是需要向后级节点输出纹理对象的,都是Output类型。
ELImageInput
基于规则一,我们可以定义出ELImageInput这样一个Protocol,因为需要别的组件给它输入纹理对象,所以这个Protocol里面定义了两个方法,第一个方法是设置输入的纹理对象。
节点中的Filter、GLImageView以及VideoEncoder都属于ELImageInput的类型,所以都应该实现这个方法,在这个方法的实现中应该将输入纹理对象保存为一个属性,等绘制的时候使用。此外,这些节点还有一个共同点,就是都需要做渲染操作,所以接下来第二个方法是执行渲染操作。
这是上一级节点(实际上是一个Output节点)处理完毕之后要调用的方法,在这个方法的实现中可以完成渲染操作。
ELImageOutput
基于规则二,我们再建立一个类——ELImageOutput,这个类可以向自己的后级节点输出目标纹理对象,其中Camera、Filter节点是需要继承自这个类。根据这个特点我们建立两个属性,一个是渲染目标的纹理对象,一个是后级节点列表,代码如下:
为什么后级节点是列表类型的呢? 因为后级节点可能有多个目标对象,比如Filter节点,既要输出给GLImageView,又要输出给VideoEncoder,而这个targets里面的对象,实际上就是之前定义的协议ELImageInput类型的对象,因为Output节点的后级肯定是一个Input类型的对象。既然有一个targets,就需要提供增加和删除目标节点的方法。
我们用这两个方法来操作targets属性。 每一个真正继承这个类的节点,执行渲染过程结束之后,就会遍历targets里面所有的目标节点(即ELImageInput)执行设置输出纹理对象的方法,然后执行下一个节点的渲染过程。代码如下:
//Do Render Work
for (id<ELImageInput> currentTarget in targets){
[currentTarget setInputTexture:outputTextureFrame];
[currentTarget newFrameReadyAtTime:frameTime timimgInfo:timimgInfo];
}
ELImageProgram
每一个节点的处理都是一个OpenGL的渲染过程,所以每个节点都需要建立一个GLProgram。我们不可能在每一个节点里面都去分别书写编译Shader、链接Program等代码,所以要先抽取出一个类,取名为ELImageProgram(EL是整个项目的前缀),把GLProgram的构建、查找属性、使用等这些操作以面向对象的形式封装起来,每一个节点都会组合这个类。
ELImageTextureFrame
每一个节点的输入都是一个纹理对象(实际上是一个纹理ID),使用GLProgram将这个纹理对象渲染到一个目标纹理对象的时候,还需要建立一个帧缓存对象(FBO),并且要将这个目标纹理对象Attach到这个帧缓存对象上。所以这里我们抽取一个类,取名为ELImageTextureFrame,将纹理对象和帧缓存对象的创建、绑定、销毁等操作,以面向对象的方式封装起来,让每一个节点使用起来都更加方便。
ELImageContext
要想使用OpenGL ES,必须有上下文以及关联的线程,之前我们也提到过iOS平台为OpenGL ES提供了EAGL作为OpenGL ES的上下文。后面我们书写编码器组件的时候,因为不希望它阻塞预览线程,所以需要单独开辟一个编码线程,也需要一个额外的OpenGL上下文,并且需要和渲染线程共享OpenGL上下文。只有这样,在编码线程中才可以正确访问到预览线程中的纹理对象、帧缓存对象。
所以我们抽取一个类,取名叫做ELImageContext,来封装EAGLContext和渲染线程。因为可能多个对象都要在调用线程和OpenGL ES的线程之间进行切换,所以需要给这个类书写一个静态方法,获得渲染线程的OpenGL上下文,并且提供静态方法可以得到这个dispatch_queue,让一些OpenGL ES的操作可以直接在这个线程中执行,具体的代码如下:
+ (void)useImageProcessingContext;
{
[[ELImageContext sharedImageProcessingContext] useAsCurrentContext];
}
- (void)useAsCurrentContext;
{
EAGLContext *imageProcessingContext = [self context];
if ([EAGLContext currentContext] != imageProcessingContext)
{
[EAGLContext setCurrentContext:imageProcessingContext];
}
}
基于以上分析,我们画出了对应的类图。
GLImageView部分,你可以回顾之前视频渲染方面的内容,这里也就不再赘述了。第18节课我们将实现VideoEncoder,后面你可以自己去实现Filter,所以这节课我们只实现Camera。Camera的实现我会分两部分讲解,第一部分是摄像头的配置,第二部分是将摄像头采集到的YUV数据转换为纹理对象。
摄像头配置
我们一直反复强调,在iOS平台只要是与硬件相关的使用都要从会话开始配置,所以摄像头这里需要配置AVCaptureSession。
然后需要配置出AVCaptureDeviceInput,这个对象代表了我们要使用哪个摄像头,比如使用前置摄像头。
AVCaptureDevice * captureDevice = nil;
NSArray *devices = [AVCaptureDevice devicesWithMediaType:AVMediaTypeVideo];
for (AVCaptureDevice *device in devices) {
if ([device position] == AVCaptureDevicePositionFront) {
captureDevice = device;
}
}
captureInput = [[AVCaptureDeviceInput alloc] initWithDevice:captureDevice error:nil];
接着要配置出AVCaptureVideoDataOutput,这个对象用来处理摄像头采集到的数据。
dispatch_queue_t dataCallbackQueue;
dataCallbackQueue = dispatch_queue_create("dataCallbackQueue",
DISPATCH_QUEUE_SERIAL);
captureOutput = [[AVCaptureVideoDataOutput alloc] init];
[_captureOutput setSampleBufferDelegate:self queue:dataCallbackQueue];
构建出captureOutput这个实例之后,要想获取摄像头采集的数据,就需要传入类型为AVCaptureVideoDataOutputSampleBufferDelegate的实例和一个dispatch_queue。
接下来,我们需要设置一下像素格式,默认使用YUVFullRange的表示格式,所谓的FullRange,表示YUV的取值范围是0到255;还有一种是YUVVideoRange的表示格式,为了防止溢出,我们把YUV的取值范围设置成16到235。Range的类型会决定YUV格式转换为RGBA格式时使用的矩阵,所以这里我们要根据支持的格式来设置,并且记录设置的格式,之后用来确定YUV到RGBA的转换矩阵。
接着将captureInput实例和captureOutput实例配置到CaptureSession中。
if ([self.captureSession canAddInput:self.captureInput]) {
[self.captureSession addInput:self.captureInput];
}
if ([self.captureSession canAddOutput:self.captureOutput]) {
[self.captureSession addOutput:self.captureOutput];
}
然后调用captureSession设置分辨率的方法,你可以看一下常见的分辨率以及设置代码。
NSString* highResolution = AVCaptureSessionPreset1280x720;
NSString* lowResolution = AVCaptureSessionPreset640x480;
[_captureSession setSessionPreset:[NSString stringWithString: highResolution]];
接着调用CaptureSession的beginConfiguration方法,配置整个摄像头会话,最后取出captureOutput里面的AVCaptureConnection,来配置摄像头输出的方向,这是非常重要的,如果不配置这个参数,摄像头默认输出横向的图片,我们使用代码把它设置成纵向图片输出。
当然,也可以给CaptureInput设置帧率等信息,这里就不再赘述。
摄像头采集数据处理
前面我们已经实现了AVCaptureVideoDataOutputSampleBufferDelegate这个协议,重写了接收摄像头采集数据的方法,签名如下:
-(void) captureOutput:(AVCaptureOutput*)captureOutput
didOutputSampleBuffer:(CMSampleBufferRef)sampleBuffer
fromConnection:(AVCaptureConnection*)connection
这个方法会把具体是哪一个captureOutput以及connection返回过来,但是最重要的其实是CMSampleBuffer类型的sampleBuffer,这里面存储着摄像头采集到的图像。一个CMSampleBuffer由以下三部分组成:
- CMTime,代表这一帧图像的时间。
- CMVideoFormatDescription,代表对这一帧图像格式的描述。
- CVPixelBuffer,代表这一帧图像的具体数据。
在这个回调函数里,我们需要完成从摄像头采集到图像渲染的全过程,而渲染部分会使用OpenGL ES来操作。
之前我们也提到过一个问题,iOS平台不允许App进入后台的时候还执行OpenGL渲染,通用的处理方式就是之前在播放器中用到的方式,分别注册applicationWillResignActive和applicationDidBecomeActive的通知,在这两个方法中将这个类中的shouldEnableOpenGL属性设置为NO和YES。然后在回调函数中判断这个变量,决定是否可以执行OpenGL的操作。
-(void) captureOutput:(AVCaptureOutput*)captureOutput didOutputSampleBuffer:
(CMSampleBufferRef)sampleBuffer fromConnection:
(AVCaptureConnection*)connection {
if (self.shouldEnableOpenGL) {
if (dispatch_semaphore_wait(_frameRenderingSemaphore,
DISPATCH_TIME_NOW) != 0) {
return;
}
CFRetain(sampleBuffer);
runAsyncOnVideoProcessingQueue(^{
[self processVideoSampleBuffer:sampleBuffer];
CFRelease(sampleBuffer);
dispatch_semaphore_signal(_frameRenderingSemaphore);
});
}
}
代码显示,首先要判断这个布尔型的变量,如果是NO的话,就不执行任何操作;如果是YES的话,要保证上一次渲染执行结束了(通过dispatch_semaphore的wait来确定)才可以执行本次渲染操作。
执行渲染操作的时候首先要使用CFRetain锁定这个sampleBuffer,因为真正使用sampleBuffer的地方是在OpenGL ES线程中,只有这里Retain住才能保证sampleBuffer不被污染,等这一次OpenGL ES的渲染操作结束以后,再使用CFRelease释放这个sampleBuffer。最后给semaphore发一个signal指令。
接下来我们看一下真正的渲染操作,也就是方法processVideoSampleBuffer的实现,这个方法需要将sampleBuffer对象渲染成为一个纹理对象,然后调用后续的targets节点进行渲染。
我们先取出这个sampleBuffer中的图像数据,即它的属性CVPixelBuffer,然后我们需要确定这个CVPixelBuffer里面YUV转换成RGB的矩阵。我们根据两方面的内容来确定这个矩阵。
- 给摄像头配置的像素格式,是YUVFullRange还是YUVVideoRange;
- 取出PixelBuffer里面的YUV转换类型,我们判断这个类型是ITU601还是ITU709格式,ITU601是SDTV的标准,而ITU709是HDTV的标准,因为标清与高清对应的YUV转换为RGB的矩阵是不同的。
这两方面共同决定了YUV转换成RGB的矩阵,其中只有ITU601分为YUVFullRange和YUVVideoRange两种,而ITU709就只有一种,根据组合从以下三个矩阵中选出合适的矩阵。
GLfloat colorConversion601Default[] = {
1.164, 1.164, 1.164,
0.0, -0.392, 2.017,
1.596, -0.813, 0.0,
};
GLfloat colorConversion601FullRangeDefault[] = {
1.0, 1.0, 1.0,
0.0, -0.343, 1.765,
1.4, -0.711, 0.0,
};
GLfloat colorConversion709Default[] = {
1.164, 1.164, 1.164,
0.0, -0.213, 2.112,
1.793, -0.533, 0.0,
};
准备工作完成之后,接下来就进入真正渲染过程。
先绑定OpenGL ES的上下文,需要调用前面我们封装的ELImageContext绑定上下文的方法。然后创建这个节点的输出纹理对象,就是构建一个ELImageTextureFrame对象,并且激活这个纹理对象(代表这个渲染过程的目标就是这个纹理对象)。
准备输入纹理,要将CVPixelBuffer中的YUV数据关联到两个纹理ID上。如果是在其他平台上,只能通过OpenGL ES提供的glTexImage2D方法,将内存中的数据上传到显卡的一个纹理ID上。但是这种内存和显存之间的数据交换效率是比较低的,在iOS平台的CoreVideo framework中提供了CVOpenGLESTextureCacheCreateTextureFromImage方法,可以使整个交换过程更加高效。
由于CVPixelBuffer内部数据是YUV数据格式的,所以可分配以下两个纹理对象分别存储Y和UV的数据。
需要在使用CVPixelBuffer这块内存区域之前,先锁定这个对象,使用完毕之后解锁。以下代码可锁定这个PixelBuffer。
然后拿出这里面的Y通道部分的内容,上传到luminanceTexture里。
CVOpenGLESTextureCacheCreateTextureFromImage(
kCFAllocatorDefault, coreVideoTextureCache, pixelBuffer,
NULL, GL_TEXTURE_2D, GL_LUMINANCE, bufferWidth,
bufferHeight, GL_LUMINANCE, GL_UNSIGNED_BYTE, 0,
&luminanceTextureRef);
代码中传入了pixelBuffer以及格式GL_LUMINANCE,还需要传入宽和高。这样这个API内部就知道访问pixelBuffer的哪部分数据了,里面还有一个非常重要的参数,就是纹理缓存,而创建的纹理会从这个纹理缓存中拿出来,纹理缓存的创建代码如下:
可以看到,创建纹理缓存必须要传入OpenGL上下文,所以我们一般在ELImageContext中维护一个纹理缓存。使用Y通道的数据内容创建出来的纹理对象可以通过CVOpenGLESTextureGetName来获取出纹理ID。以下代码可以把UV通道部分上传到chrominanceTextureRef里。
CVOpenGLESTextureCacheCreateTextureFromImage(kCFAllocatorDefault, coreVideoTextureCache, pixelBuffer,
NULL, GL_TEXTURE_2D, GL_LUMINANCE_ALPHA, bufferWidth/2,
bufferHeight/2, GL_LUMINANCE_ALPHA, GL_UNSIGNED_BYTE, 1,
&chrominanceTextureRef)
YUV420P格式规定,每四个像素会有一个U和一个V,用GL_LUMINANCE_ALPHA来表示UV部分,即U放到Luminance部分,V放到Alpha部分。理解这一点是非常重要的,因为这关乎后面在FragmentShader中如何拿到正确的YUV数据。
接下来,就是实际的渲染了,在渲染过程中需要注意两点,一是确定物体坐标和纹理坐标;二是在FragmentShader中,怎么把YUV转换成RGBA的表示格式。我们先来看如何确定物体坐标和纹理坐标,物体坐标其实是固定的,物体坐标如下:
GLfloat squareVertices[8] = {
-1.0, -1.0, //物体左下角
1.0, -1.0,//物体右下角
-1.0, 1.0, //物体左上角
1.0, 1.0 //物体右上角
};
而确定纹理坐标会麻烦一点,记得我们之前讲过,OpenGL纹理坐标系和计算机坐标系是不同的吗?所以默认情况下,纹理坐标如下:
进行旋转以及镜像的时候,都是根据这个纹理坐标来实施的。左边第一张图是前置摄像头采集到的图像。
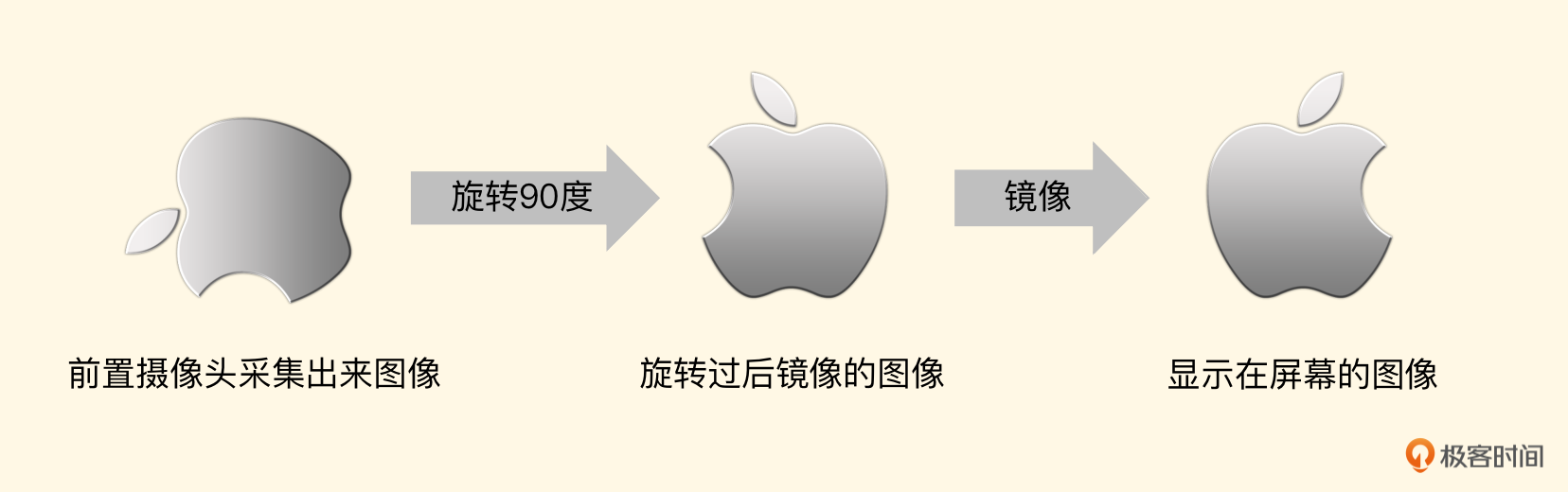
要想正确地显示,需要先按照顺时针旋转90度,由于是前置摄像头,还得做一个镜像处理,所以我们的纹理坐标如下:
如果是后置摄像头,那么我们应顺时针旋转90度。
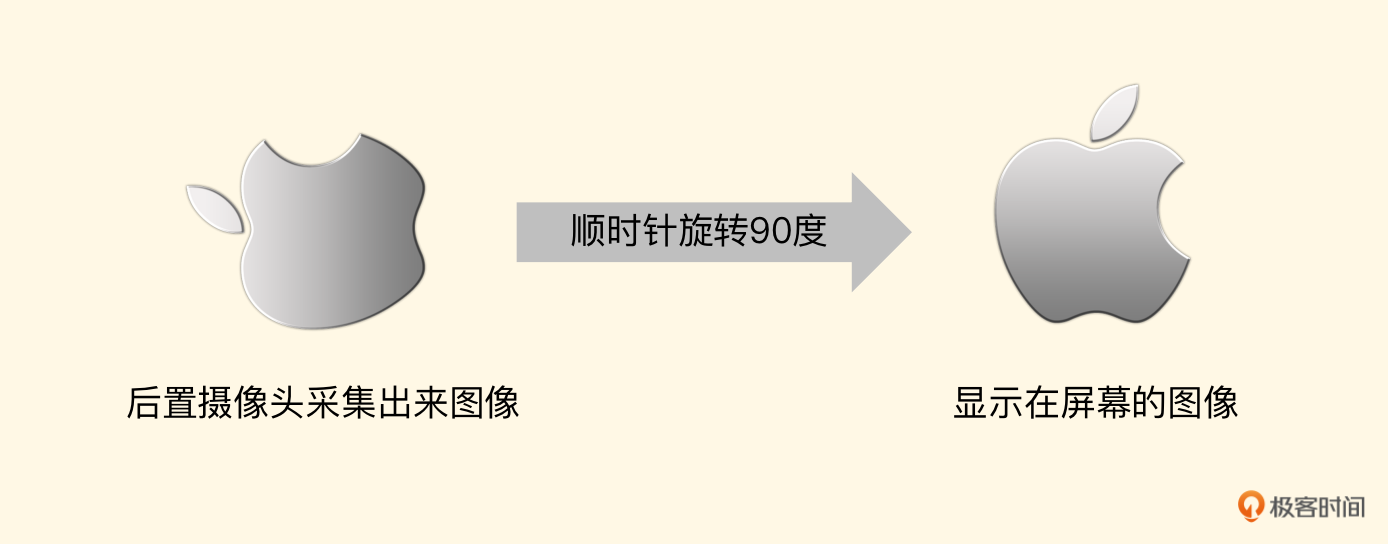
顺时针旋转90度的纹理坐标如下:
这里有一点需要特别注意的是,由于把纹理做了90度的旋转,所以目标纹理对象宽高和输入纹理(CVPixelBuffer)的宽高需要对调一下。
上述纹理坐标是默认摄像头给出的图像纹理坐标,但前面我们给摄像头做过一个特殊的设置,就是给 AVCaptureConnection设置videoOrientation这个参数,摄像头默认是横向视频输出,当把这个参数设置为Portrait时,就要求摄像头按照竖直方向输出视频。这时候目标纹理对象的宽高和CVPixelBuffer的宽高一致了,那么后置摄像头采集出来的图像直接绘制即可。
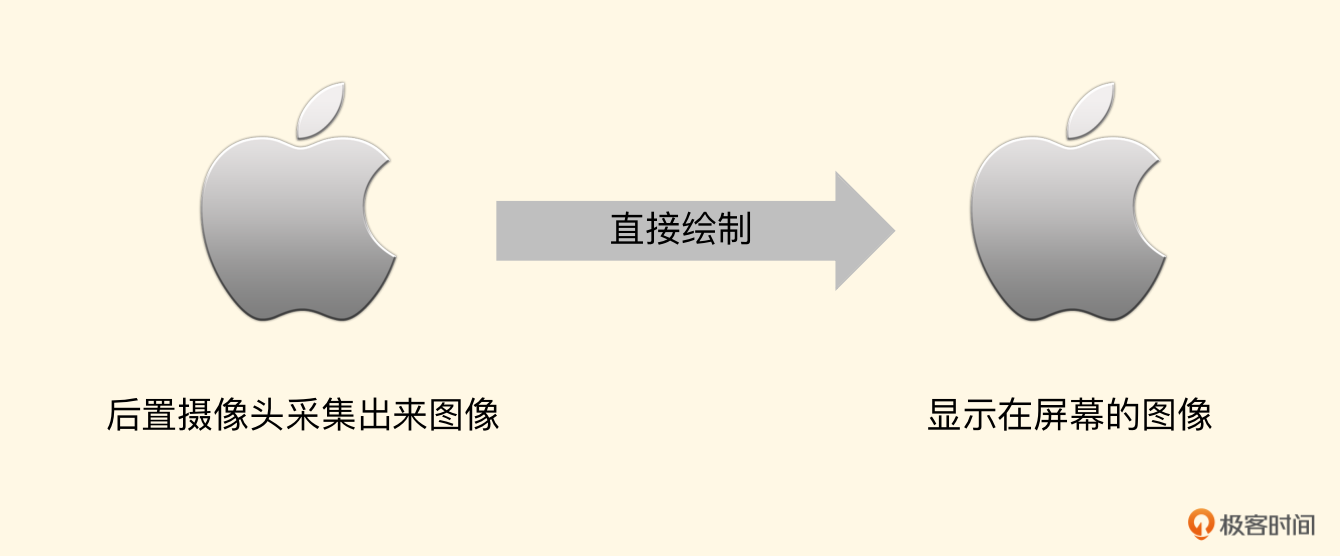
所对应的纹理坐标为:
而前置摄像头由于镜像的原因,所以绘制过程如下图所示。
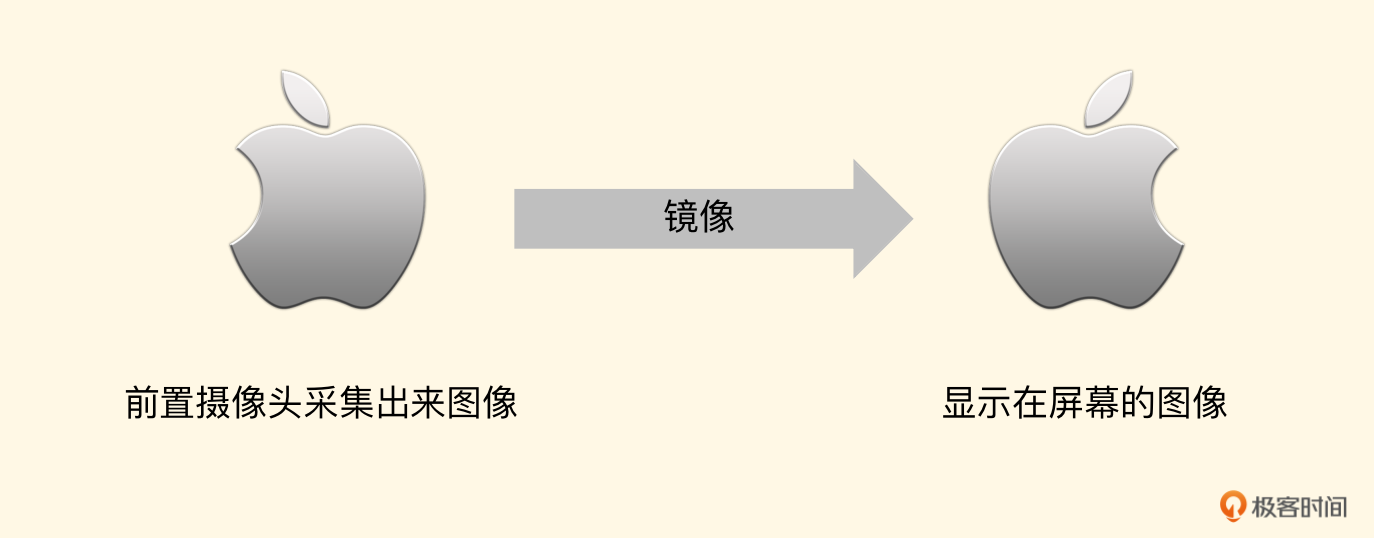
此时的纹理坐标正好和后置摄像头的每一个坐标的X点相反。
确定物体坐标与纹理坐标之后,我们就来看一下如何在FragmentShader中,将YUV转换成RGBA。注意:这里是一定要转换为RGBA的,因为在OpenGL中通用的渲染纹理格式都是RGBA的,包括纹理处理、渲染到屏幕上以及最终编码器,都是以RGBA格式为基础进行转换和处理的。在播放器的部分我们已经做过一次YUV转RGB的操作,但是由于使用了CoreVideo这个framework下的快速上传,输入的纹理变得不一样了,所以我们来看下具体的FragmentShader。
varying highp vec2 textureCoordinate;
uniform sampler2D luminanceTexture;
uniform sampler2D chrominanceTexture;
uniform mediump mat3 colorConversionMatrix;
void main(){
mediump vec3 yuv;
lowp vec3 rgb;
yuv.x = texture2D(luminanceTexture, textureCoordinate).r;
yuv.yz = texture2D(chrominanceTexture, textureCoordinate).ra - vec2(0.5, 0.5);
rgb = colorConversionMatrix * yuv;
gl_FragColor = vec4(rgb, 1);
}
其中textureCoordinate是纹理坐标,而这两个sampler2D类型就是从CVPixelBuffer里面上传到显存中的纹理对象,3*3的矩阵就是前面根据像素格式,以及是否为FullRange选择的变换矩阵。我们重点看一下如何取出Y和UV。
- 由于luminanceTexture使用的是GL_LUMINANCE格式上传上来的纹理,所以这里使用texture2D函数拿出像素点之后,访问元素r就可以拿到Y通道的值了。
- 而UV通道使用的是GL_LUMINANCE_ALPHA格式,通过texture2D取出像素点之后,访问元素r得到U的值,访问元素a得到V的值。但为什么UV值要减去0.5(换算为0-255就是减去127)?这是因为UV是色彩分量,当整张图片是黑白的时候,UV分量是默认值127,所以这里要先减去127,然后再转换成RGB,否则会出现色彩不匹配的错误。
最后使用传递进来的转换矩阵乘以YUV,得到这个像素点的RGBA表示格式,并赋值给gl_FragColor。
到这里,ELImageVideoCamera这个类的核心逻辑我们就学完了,最终这个节点会输出一个纹理ID,这个纹理ID可以直接渲染到ELImageView中让用户看到摄像头预览的效果。
小结
最后,我们可以一起来回顾一下。
这节课我们设计并实现出一个ELImage视频框架的架构,包含ELImageInput、ELImageOutput、ELImageProgram、ELImageTextureFrame和ELImageContext五个基础类。然后基于这五个类可以扩展出众多组件。
我们利用框架核心完成了视频画面的采集,用的就是ELImageVideoCamera这个类。这个节点最终会输出一个RGBA类型的纹理,这个纹理可以给到后续的ELImageFilter节点做美颜处理,最终输出到ELImageView中,显示出来,而这个过程就是打开摄像头预览的过程。
ELImage这个核心框架很重要,我们需要好好“消化”这部分内容,因为这个视频框架后续会用到,并且基于这个视频框架,我们还会增加一些其他节点,比如ELImageVideoEncoder等,也就是当用户点击录制的时候,将纹理ID传入到Encoder节点就可以录制出视频文件来。
思考题
ELImage框架还可以扩展出许多其他的节点,组成复杂的场景,比如视频编辑器场景,如果让你书写一个ELImageMovie节点,然后与ELImageFilter以及ELImageView组合成视频编辑器,你将如何完成ELImageMovie的设计呢?在评论区中给出你的思考,也欢迎你把这节课分享给更多对音视频感兴趣的朋友,我们一起交流、共同进步。下节课再见!
- keepgoing 👍(0) 💬(2)
老师有三个问题想请教一下: 1. 通过这个采集渲染框架,能否理解为摄像头采集->编辑->渲染的过程就是从摄像头中拿到原始图像,然后经过每一个节点不断渲染到显存中的一个纹理ID上,最终在显示节点上把每一层渲染好的纹理显示到目标view上? 2. 如果需要编码这个最终的图像,是需要编码节点每一帧都从显存中获取吗? 3. 老师在文中提到了每次将内存图片上传显存是一个很低效的做法,可以使用CVOpenGLESTextureCacheCreateTextureFromImage API,请问这个API的原理是什么呢,是怎么做到高效内存->显存的操作呢 感谢老师的解答,辛苦了
2022-12-19 - 一个正直的小龙猫 👍(0) 💬(2)
请教老师一个问题: 这个是摄像头采集视频画面,如果是webrtc直播视频流呢? 想录制视频,采集直播流的视频和音频,用什么技术方案实现是最佳的?replaykit2还是ffmepg,他俩对比优缺点是什么?
2022-08-24 - Neil43 👍(0) 💬(1)
老师你好,我在使用AVFoundation框架的AVAssetWriterinput ,追加SampleBuffer报错,关键代码: AVAsset WriterInput *videoInput = [AVAsset WriterInput asset WriterInput WithMediaType:AVMediaTypeVideo outputSettings:videoSettings]; assetWriter = [[AVAssetWriter alloc] initWithURL: _URL fileType:AVFileTypeQuickTimeMovie error: &error]; [assetWriter addInput:_videolnput]; BOOL success = [videoInput appendSampleBuffer:sampleBuffer]; 具体报错信息: userInfo={ NSLocalizedFailureReason = An unknown error occurred (-12780), NSLocalizedDescription = The operation could not be completed, NSUnderlyingError = Error Domain=NSOSStatusErrorDomain Code=-12780 "(null)”} 请问老师知道大概是什么原因吗?如果appendSampleBuffer方法报错,再调用finishWritingWithCompletionHandler方法,能正常生成视频吗?谢谢。
2022-08-24 - peter 👍(0) 💬(1)
请教老师一个问题: Q1:AI唱歌,有能够使用的软件吗?(开源、付费的都可以)。 AI唱歌,是指用一个人的声音把一首歌完整的唱出来。比如有特朗普的一段音频(比如30s声音片段),然后软件根据这个声音片段,就可以把《好汉歌》唱出来。效果就是听众认为是特朗普唱的《好汉歌》。
2022-08-24 - 月半木子🎊 👍(0) 💬(0)
请问老师,这个实现如何自测是否满足需求呢,自测需要关注哪些测试点呢
2023-06-13