18 告警与决策:如何解决监控警告中焦虑的问题?
你好,我是三桥。
你知道前端工程师最怕的是什么时候吗?是需求不合理?是出现线上故障后不知所措?还是说无法找到解决问题的办法?
我相信,最怕的肯定是线上故障时的不知所措。特别是产品反馈有大范围的用户客诉时,那种身上的焦虑感绝对瞬间暴涨。要是找不到问题根源和解决方案,那真的是令人崩溃。
这种情况大概率是因为系统没有监控,没有日志,无法做到快速查找问题,才会产生“焦虑”“不知所措”“崩溃”等情绪。
我们来看个真实的案例吧。
隐蔽性很强的缺陷
这个案例是我在参与教育产品开发过程的一段经历,也是前端团队花费最长时间解决的缺陷。
问题的背景是这样的。有段时间,产品在一周内陆续收到老师的反馈,说咱们的教学直播PC软件上课时经常崩溃,无法正常上课,希望产研帮忙解决一下。
关于教学直播PC软件这个产品,我简单介绍一下。它是一款提供给老师上直播课用的PC软件,技术的选型是基于Electron和Vue结合的技术栈。并且,这个软件已经持续运行了有3年以上了,每天至少有几百个老师在上课,所以,系统已经相对很稳定,很少出现大范围的问题。
另外,我们在维护这款软件时,软件内部已经有一套完整的日志体系了,有一部分日志是通过埋点上报的,另一部分是直接把日志信息写到本地文件系统里。
有统计,没监控,没报警
好,我们回过来继续看这个崩溃问题。
当产品同学把问题转交给前端团队后,我们通过崩溃次数折线图分析得出一个初步的结论:崩溃问题应该持续了有半年时间了,并且我发现了3个现象。
第一,崩溃的次数从1月份每天不超过10次,直到7月份每天超过150次。说明这是一个明显不正常的现象。参考如下图的折线图。
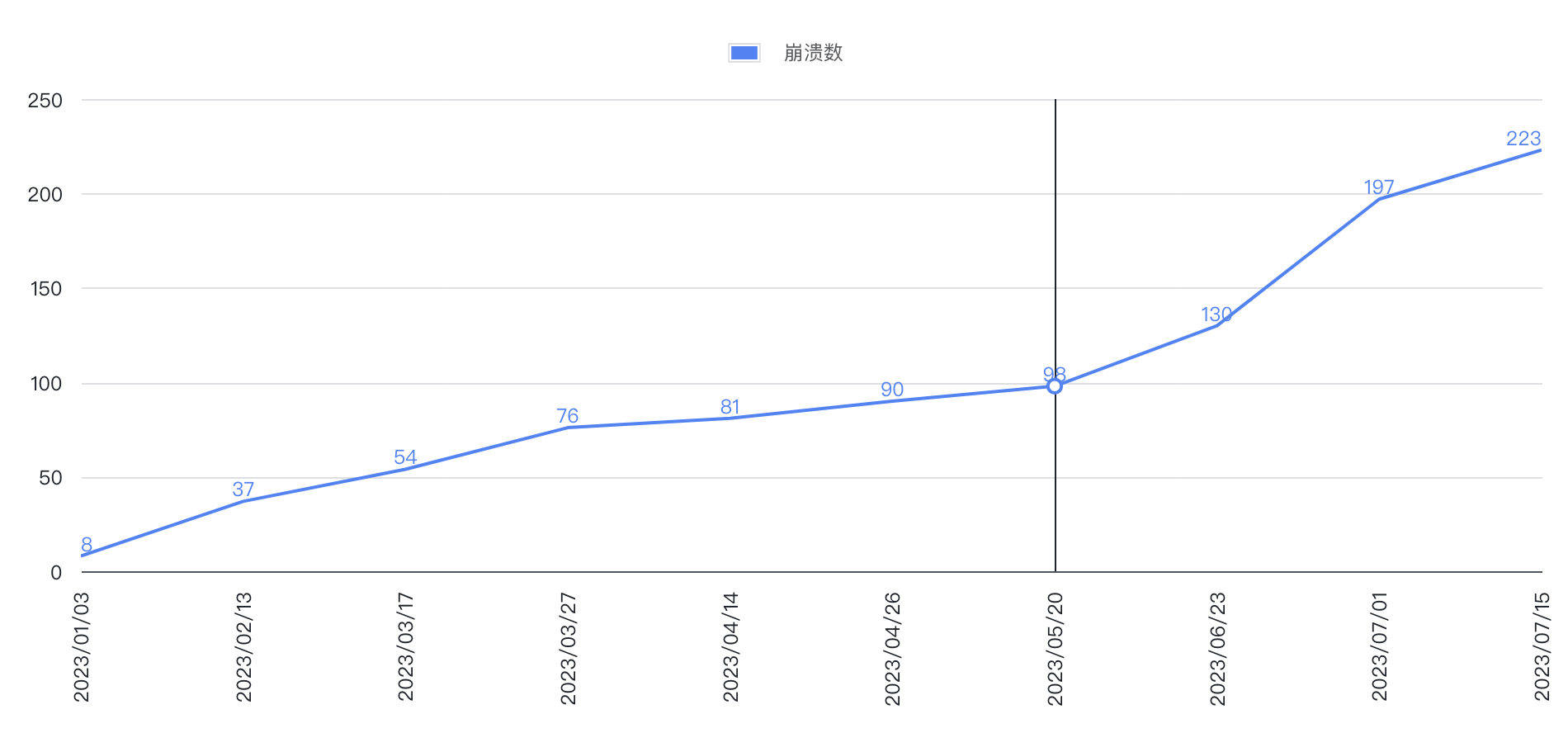
第二,并非所有的老师都反馈崩溃问题,反馈的占比有一半左右,而且每天的崩溃频率最高在晚上7点到10点之间,也是老师上课高峰期。也就是说,这既不是特殊个例问题,也不是大规模的线上故障,极有可能是在特定场景下触发的缺陷。
第三,只有崩溃率统计,没有设定预警和告警策略,所有日志数据都在老师电脑上。
决策:增加全链路、崩溃前后日志
在总结出这三个现象后,我们继续排查老师电脑上PC软件的日志,发现了一个现象:每次崩溃后,软件都没法继续写入日志,最后总会停留在调用摄像头和麦克风。
为了找出问题的根本原因,经过和产品同学沟通后,做出了两个决定。
第一,增加日志,包括接入全链路监控,在调用摄像头和麦克风的逻辑前后增加埋点日志。
第二,优化监控,设定阈值预警通知。同时,增加统计灰度用户的崩溃统计,方便前端同学监控问题解决情况。
监控、日志、通知等流程补齐后,就将测试版本的软件交给老师更新,并继续观察崩溃问题。
尝试不同解决方案,灰度观察问题
在测试版软件灰度了2-3个老师后,我们针对摄像头和麦克风的使用问题,尝试了延迟调用和关闭两种方式,最后发现只要关闭摄像头功能,软件就能恢复稳定,不再崩溃了。
另外,从链路日志中也没发现接口异常或脚本报错问题,而且也排查过摄像头的代码逻辑,都有超过一年时间没有更新了。
当时我们就怀疑可能是摄像头的问题。然后,我们决定还原现场真实环境,直接使用老师的笔记本上课,重现问题。再对比其它的笔记本,最终得出一个很重要的结论:使用老师的笔记本设备必定会崩溃。
有了这个结论,我们就往着这个线索,一步步地往下查,最终发现是第三方JSSDK的问题,它每次调用摄像头时都有一定的几率导致软件崩溃。
最后,我们跟第三方服务商一起联调排查问题,结果确实是SDK引起的。
奇怪的是,为什么原本稳定性很好的软件,没有升级SDK,也没有更新过调用摄像头逻辑,在这半年时间内崩溃次数变多了?
其实,最隐秘的原因是,从2月份开始,公司陆陆续续地给老师更换了新笔记本设备。而我们的软件并没有适配这款新笔记本,导致SDK在调用摄像头时,容易触发崩溃。
找到问题根源
虽然找到了问题的根源在服务商,但麻烦的事一波接一波。服务商反馈我们的软件使用了较低的SDK版本,要解决崩溃的问题,就要升级SDK,甚至还有Electron版本。
我相信,很多前端同学听到升级Electron版本都会非常紧张,我们也不例外。不过,我们处理问题的目标是很明确的,就是先把崩溃问题解决,至于Electron用哪个版本,其实不是我们重点关心的。
当时,我们对升级Electron一直保持克制,运行中的版本使用的还是7系列老版本,但最新版本已经是23了,如果要升级,成本是非常高的。
经过前端团队内部的商讨,最终决定只升级SDK支持Electron的最低版本,12版本。
制定解决计划
在问题确认了之后,前端同学就开始评估升级SDK和Electron版本,包括设定升级方案、升级工作的工期评估、产品功能的影响面、测试方案、灰度方案和升级方案等。
同时,把解决方案同步给产品和测试同学,并申请研发资源和制定专项计划,按照技术优化需求来跟进。最终敲定约3周时间可以提供灰度版本给产品同学。
有些前端同学可能好奇,解决这样的崩溃问题,也要申请研发资源和专项计划?
没错。作为一个支撑业务的前端团队,原本就是服务于业务需求迭代,要解决产品的缺陷,而且需要3周工期,是需要得到多个方团队的认可,才能执行。所以,无论是任何前端任何角色,要完成技术专项,还是需要获取许可,才能启动的。
灰度和持续跟进进度
修复崩溃问题的直播PC软件,我们如何才能验证?
我们继续通过灰度的方式验证问题,不过,这次第一批灰度用户数量控制在了10位左右。
在灰度期间,我们不断观察这10位老师的使用体验,只要出现崩溃都发送通知到钉钉群。同时,每天都会将日志系统收集的灰度用户崩溃数,通过钉钉发送出来。
结果灰度持续了一周,崩溃次数瞬间归零。
然后,我们连续两次扩大灰度用户数,从10位老师加到100位,再到200位。最终,所有老师的直播PC软件都不再崩溃了。
通过三次灰度,我们确定问题已经修复了,最后就和产品、测试沟通协商全量计划。
你看看,这次崩溃的问题,隐秘性很强,前后经历了将近2个月时间才把问题修复。而在这个过程,我们不断地和产品、测试、老师各方团队保持沟通、协调解决方案。同时,补齐前端全链路日志,崩溃数统计,警告通知等能力,最终用数据说话。
决策的重要性
在这个案例中,虽然前端全链路的日志并不是主角,但我们依然是通过日志和监控观察着用户状况,最终用数据证明问题已解决。
协同决策
有没发现,在解决这个缺陷过程中,我们一共做了5次决策,每次决策和结论都对后续工作有着推进作用。
- 第一次,我们根据用户的反馈和项目的实际情况,做了两个决策:补充日志和增加警告。
- 第二次,由于无法找到问题原因,我们决定选择还原现场问题。
- 第三次是关于Electron版本升级,这次决策由团队共同决定。
- 第四次是制定解决方案,同时跟业务方沟通落实灰度计划、升级方案。
- 最后一次就是产研团队继续采用灰度加监控并行,同时每天汇报进度,通过监控和数据观察问题。
你看,每次决定都离修复问题越来越近,协同决策并非由一人来决定,而是多人多团队一起商讨出来的。
最优策略
我相信前端同学很少会遇到这样奇怪问题的经历:由于更换笔记本导致软件的不兼容,实际上是第三方服务商的问题。
这个过程里,升级Electron是我们最不希望遇到的一件事情,但问题摆在这,如果不升级,根本就没其它方案,所以最优方案是选择兼容最低版本。
事实证明,这个决策是完美的。因为,我们在升级版本过程中,发现Electron提供的API都没有任何变化,也没有影响到产品功能和性能问题。
风险预判
最开始,我们收到的问题反馈,只是一些零碎的崩溃信息。直到分析崩溃统计报表后,就预判出这是高优先级别的问题。
另外,为了确保软件是否被修复成功,我们采用了灰度机制,降低发生二次故障的风险。
总之,最好的风险预判是有数据支撑。如果没有,我的建议是跟产品、前端、测试三方同学沟通并做出风险预判决策。
反馈机制
在这次处理问题的过程中,我们持续地更新崩溃统计报表、增加全量和灰度两种报表统计,同时又补充崩溃通知机制。
再结合钉钉的能力,把崩溃日志、统计崩溃信息实时发送到钉钉群。通过这样的反馈机制,能够帮助我们快速了解用户现场情况。
还有,通过实时反馈机制,让专项团队每个成员都能看到问题修复的进展,管理者还能快速了解情况。这是一件很有价值的影响力事项,建议你尝试下。
总结
这节课,我们讲述了一件从问题反馈到查找问题,再到处理问题的真实案例。在处理这个案例过程中,每个环节,每个步骤,每个结论,每个决策,我们都有直接有效的方案持续跟进。
虽然前端全链路监控在这个案例中没有起到重要作用,但从这个案例我们可以得到一个结论。
不管用任何方式的日志数据,遇到问题时,我们要学会用数据说话,通过数据分析问题,这样才能让我们解决问题的道路越走越顺。
下节课,我们就马上进入前端全链路的优化实战部分,期待你继续往下学习。
思考题
这是一个典型的非前端业务逻辑引起的问题。现在,给你布置一道思考题。
在这个案例中,哪个环节或步骤给你的印象很深刻呢?为什么?如果让你负责的话,这个环节还有哪些地方可以优化?
欢迎你在留言区和我交流。如果觉得有所收获,也可以把课程分享给更多的朋友一起学习。我们下节课见!
- 苏果果 👍(0) 💬(0)
完整源码入口: https://github.com/sankyutang/fontend-trace-geekbang-course
2024-07-18 - 若水清菡 👍(0) 💬(1)
修复周期两个月比较长,在这期间有没有考虑把用新笔记本的老师们先补发旧笔记本,保证他们用这个软件的稳定性,不影响老师们的正常工作,然后再进行修复呢?
2024-07-25