16 监控规则:设定有效的查询条件规则
你好,我是三桥。
一个完整的监控平台,要确保告警的准确性,就需要从大量的日志数据中提取有用的信息和特定数据,然后分析数据、判断阈值,最终才能准确定位问题。
这节课我们继续学习前端全链路监控实践另一个重要的环节,如何设定有效的监控查询规则。
首先,我们要理清前端全链路数据结构中的关联关系。
全链路数据结构
我们在前面的课程里学习了如何设计前端全链路的数据结构。一份日志数据最多有20个属性值,其中有17个是基础属性,另外3个用于记录问题。
首先,我们来回顾一下前面设计的全链路数据结构,所有属性字段的代码如下。
type BaseTrace = {
// 唯一ID,用户侧生成
traceId: string
// 日志类型
type: TraceTypes
// 日志产生时间
createdAt: number
// 日志最后更新时间
updatedAt: number
// 当前浏览器的UserAgent
ua: string
// 浏览器类型
bt: BrowserType
// 指纹ID,fingerprintId
fpId: string
// 用户ID
uid?: string | number
// 用户名称
userName?: string
// 用户邮箱
email?: string
// 业务ID
appId: string
// 业务名称
appName?: string
// 客户端类型
clientType: TraceClientTypes
// 日志级别
level: TraceLevelType
// 页面ID
pid: string
// 页面标题
title?: string
// 当前页面URL
url: string
// 记录错误信息
data?: TraceTypeData
// 记录操作行为
breadcrumbs?: TraceBreadcrumbs
// 记录性能信息
perf?: TracePerf
};
我们设计的这些字段都是以链路关系为基础的。有了关联关系,我们就可以筛选出有用的日志数据。那这些数据结构的链路关系是怎样的呢?
这些字段里,uid 、fpId、appId 是全链路日志的核心,是串联用户访问页面过程中多个链路日志的关键。至于 type、clientType、level、bt 是链路日志的分类,可以筛选和过滤日志。
好,明白了这些字段功能后,我们就能将日志查询规则分成6种场景,分别是有限信息(时间范围)、已知用户ID、指纹ID、共性问题、核心场景以及相同问题检测机制。
首先,我们来看下第一种规则。
情景一:基于时间范围的查询规则
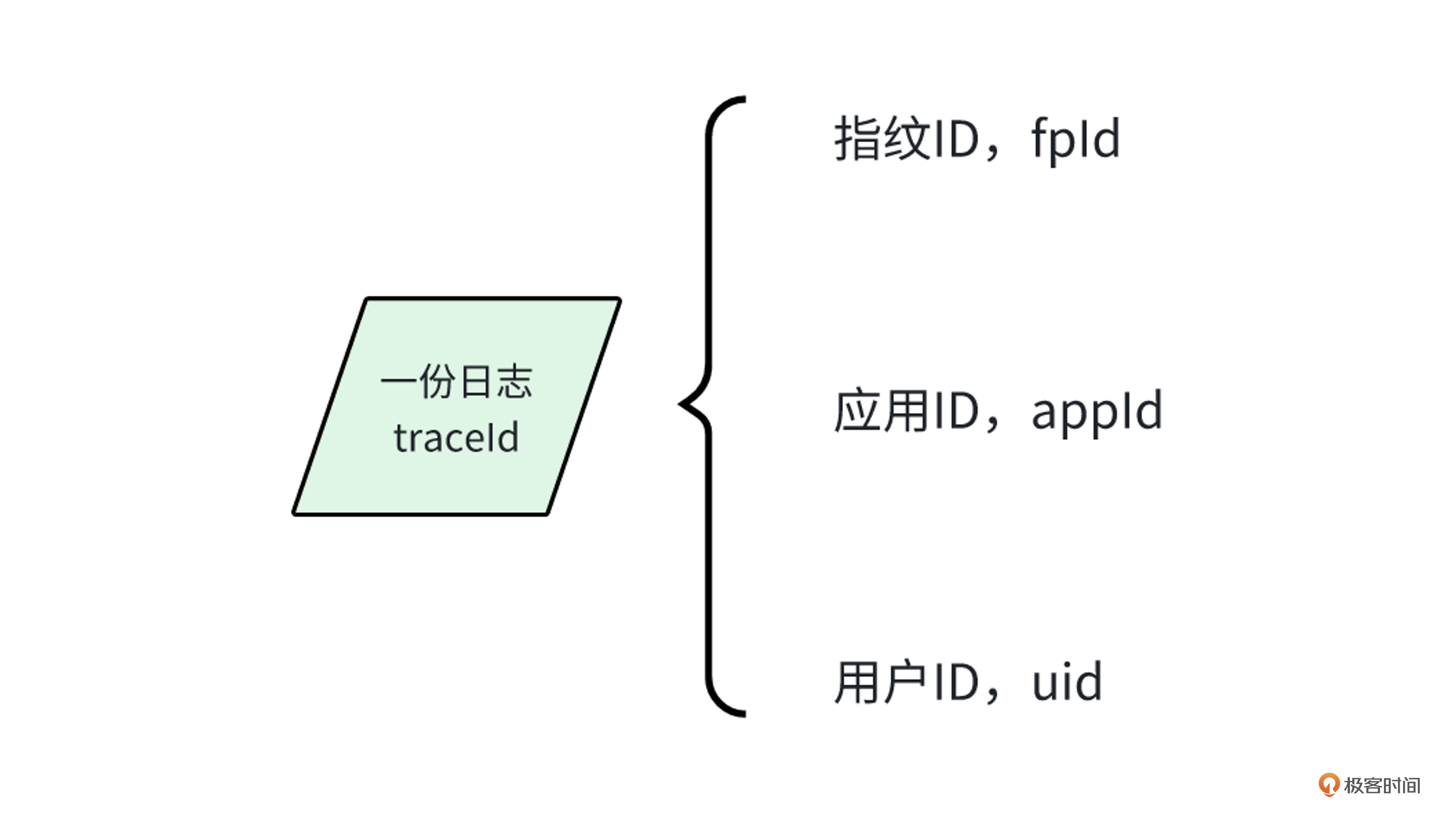
traceId 是日志ID,通过uuid生成,基本上接近唯一值。通过日志数据,我们能查询到 fpId 和 appId ,如果是已登录的用户,还会有 uid 。
简单来说,在一份日志里,我们能查出用户来自哪个前端应用,查出用户ID以及指纹ID。有了这些信息,我们就能快速匹配用户访问过哪些前端应用和相关联的链路日志。这就是第一种关联关系。
有一类用户是这样反馈问题的。
他们通常会说:“我上午通过App打开了某个页面,但点击上课按钮没反应,能帮我解决一下问题吗?”
在这个没有明确信息的前提下,第一步你会怎么查日志?
首先提取线索,“上午”“某个页面”“上课按钮”,有了这些线索,我们就可以粗略地筛选这个“上午”时间的所有错误信息。
例如,参考下面这张图,我们需要充分利用时间选择器,根据线索筛选了指定的日期和时间范围。
接着,我们编写一个查询日志的脚本,通过脚本查询所有日志中的指纹用户和用户ID,参考SQL脚本如下。
level:"error" | select
json_extract_scalar(data, '$.message') AS message,
fpId,
uid
group by
message,
fpId,
uid
该SQL脚本最终查询结果参考如下图。

除此之外,SQL脚本还能分组统计错误信息的数量。通过分析总数,我们可以快速判断问题的严重性和处理问题的紧急程度。参考SQL脚本如下。
level:"error" | select
json_extract_scalar(data, '$.message') AS message,
count(json_extract_scalar(data, '$.message')) as Total
group by
message
该SQL脚本最终查询结果参考如下图。

通过这两个SQL,我们得到了关联信息,错误数据和用户的关联,错误总数的统计。实际上,除了这些,我们还能统计出appId、url等相关的数量。只要我们基于这类SQL脚本,再结合提前预设好的阈值,就能接入监控通知。至于阈值范围,根据实际需求确定即可。
情景二:基于用户ID条件的查询规则
在第一个场景里获取到了用户ID之后,我们就可以关联更多的日志了。
假设我们的前端应用提供了微信和App两种平台,那我们如何判断用户是否已经使用过这两种平台呢?
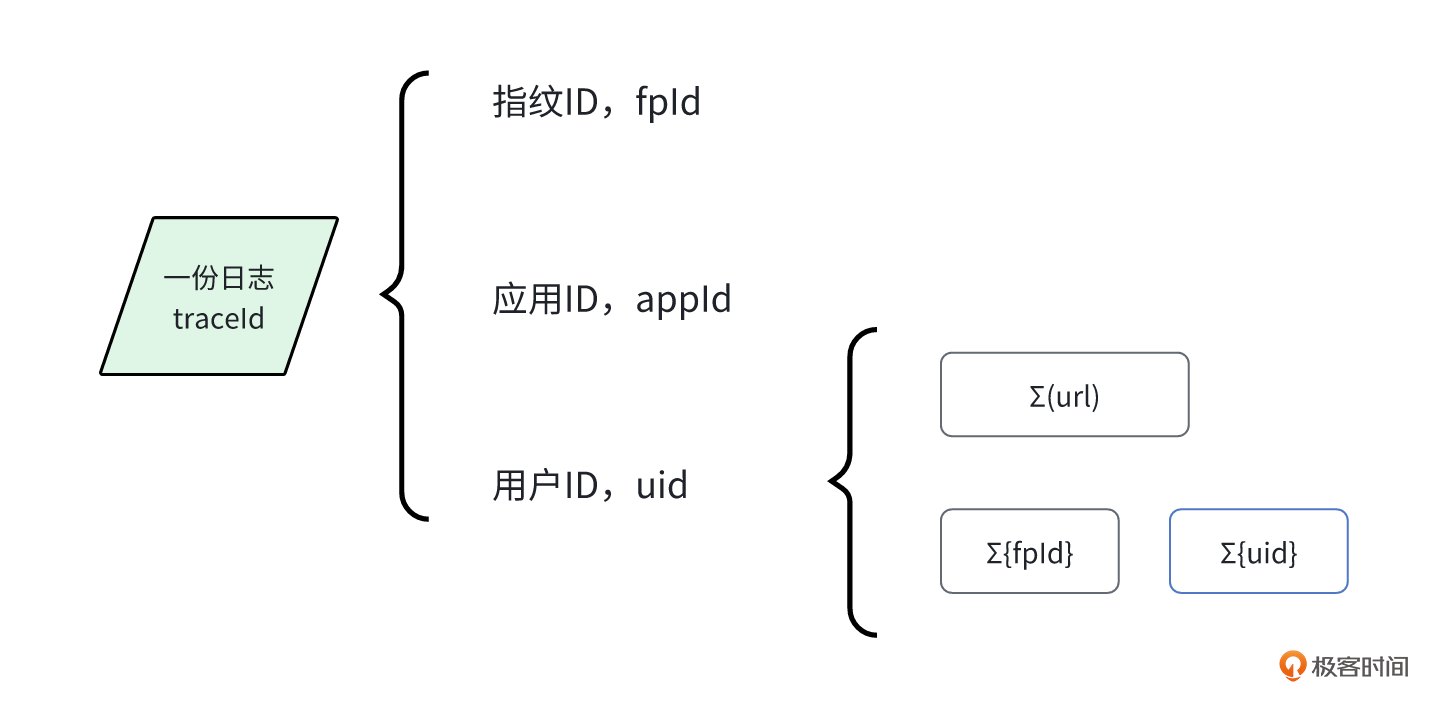
思路是这样的,我们已经知道用户ID(uid),如果日志中查出来两个指纹ID(fpId),那就能判断出用户已经使用过这两种平台。相反,如果只有一个,那我们就可以确认具体的访问平台。同理,我们也可以通过appId来分析用户使用的前端应用。
我们在分析问题时, uid 还有一个作用,就是可以汇总用户访问过的前端页面。再结合时间线,就能分析出用户的访问路径。关于用户ID的关联关系规则,参考下面这张图。
通常情况下,我们有许多方法获取用户的基本信息,包括用户ID、用户名、邮箱等。在用户向团队反馈问题时,我们可以利用这些基本信息来查询用户的相关日志。
我们以用户ID=1000为例。结合筛选错误级别的日志,就能查询出该用户访问过的页面和错误日志。以下是一个例子的脚本。
另外,我们还能按时间排序查询出页面访问路径,快速了解用户的访问历史,例如下面的脚本。
通过SQL查询,我们也能查询出 uid 访问过哪些客户端类型(clientType)的环境,例如下面的脚本。
// 只查询fpId是否存在多个
level:"error" and uid:"1000" | select
uid, fpId
group by uid,fpId
// 更详细的判断用户访问的fpId、客户端类型以及错误类型
level:"error" | select
uid, fpId, clientType,type
group by uid,fpId,clientType,type
不过,我们的脚本并不适合全链路监控,是因为我们监控的目的是发现问题,特别是共性问题,而非针对某个特定用户的问题。而且,通常大型前端项目一旦拥有一定的用户量,监控平台就很少会从单用户的角度来监控每个用户的问题。
因此,这部分的脚本规则是用来快速提取用户的全部日志,帮助前端同学分析问题的。
情景三:基于指纹ID条件的查询规则
有一种场景是这样的。
有一个用户有两个账号,分别访问过前端应用。可是其中一个账号出现问题了,我们该如何排查多账号的问题呢?
当遇到这种问题时,我们通常会询问用户是否曾经使用两个不同账号切换登录,然后再去寻找问题的原因。解决这种问题的方法是,第一步先通过 uid 找到指纹ID,第二步通过指纹ID找到两个账号的相关日志,并按时间线进行排序,这样就能知道用户在这期间做了什么操作(例如切换账号)。
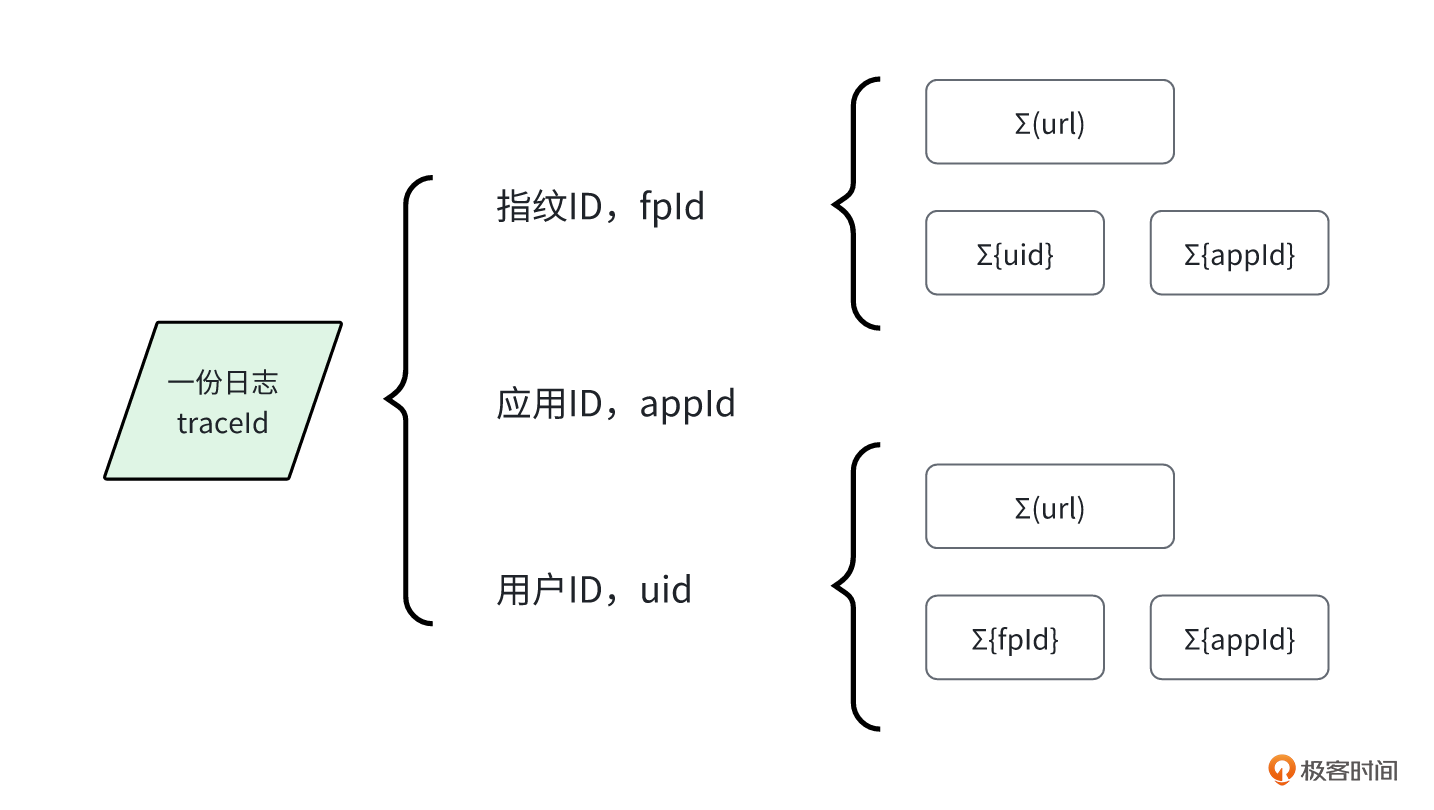
实际上,指纹ID的作用和 uid 相似,但指纹ID的覆盖范围会更广,而且能够发现多账号现象,汇总更复杂的页面流程。这就是指纹ID的价值。
我们通过一张图来看一下整体的关系情况。
相信现在的你已经非常了解指纹ID的作用了。之前我们介绍过如何通过uid查询出多个fpId,那反过来,我们知道指纹ID后,也能反查出 uid 。例如,你可以参考下面的脚本。
在上述脚本里,我们以 fpId 作为筛选条件,然后再增加url字段,方便我们了解哪些访问页面的指纹用户是已登录的,哪些是未登录的。通过这种方法,我们就能了解用户在登录前后的访问页面状态。
同理,我们还能利用 fpId 查找用户是否访问过多种不同的应用入口,例如以下的SQL脚本。
实际上, fpId 和 uid 在监控当中的应用原理是相同的,只是fpId的查询范围更广。因为并非所有页面都需要登录访问,也就是 uid 有可能不存在。因此,我们可以通过 fpId 查询、分析和还原完整的用户访问历史记录。
不过由于 fpId 是在全链路SDK当中是自动生成的,用户并不知道这个字符串,所以前端同学通常很难获取。也因此,只有知道了 uid ,才能快速找到 fpId 。还有另一种查找 fpId 的方法就是根据具体的时间、访问页面、访问设备类型等多个条件进行筛选过滤。
总的来说, fpId 和 uid 是我们排查用户问题时最有价值的属性。
情景四:基于共性问题的查询规则
我们知道,一个大型的产品项目通常会同时运行许多不同架构的前端项目。那当线上出现故障时,你能快速判断出是哪个前端项目的问题吗?
尤其是在微前端项目里,如果没有日志,你也许只能盲猜。即使有日志,如果日志中没有记录哪个项目出了问题,你可能还需要花费一些时间来定位是哪个前端代码工程。
链路日志中的 appId 就是为了解决这类问题而存在的。有了 appId ,我们就能快速准确地知道是哪个项目的问题,从而快速查询错误日志。
除此之外,我们还能利用 appId 统计出所有error类型的错误日志,统计用户数或指纹用户数。这种统计的主要目的是帮助前端同学快速判断问题的影响范围。我们可以通过一张图来看看整体的关系情况。
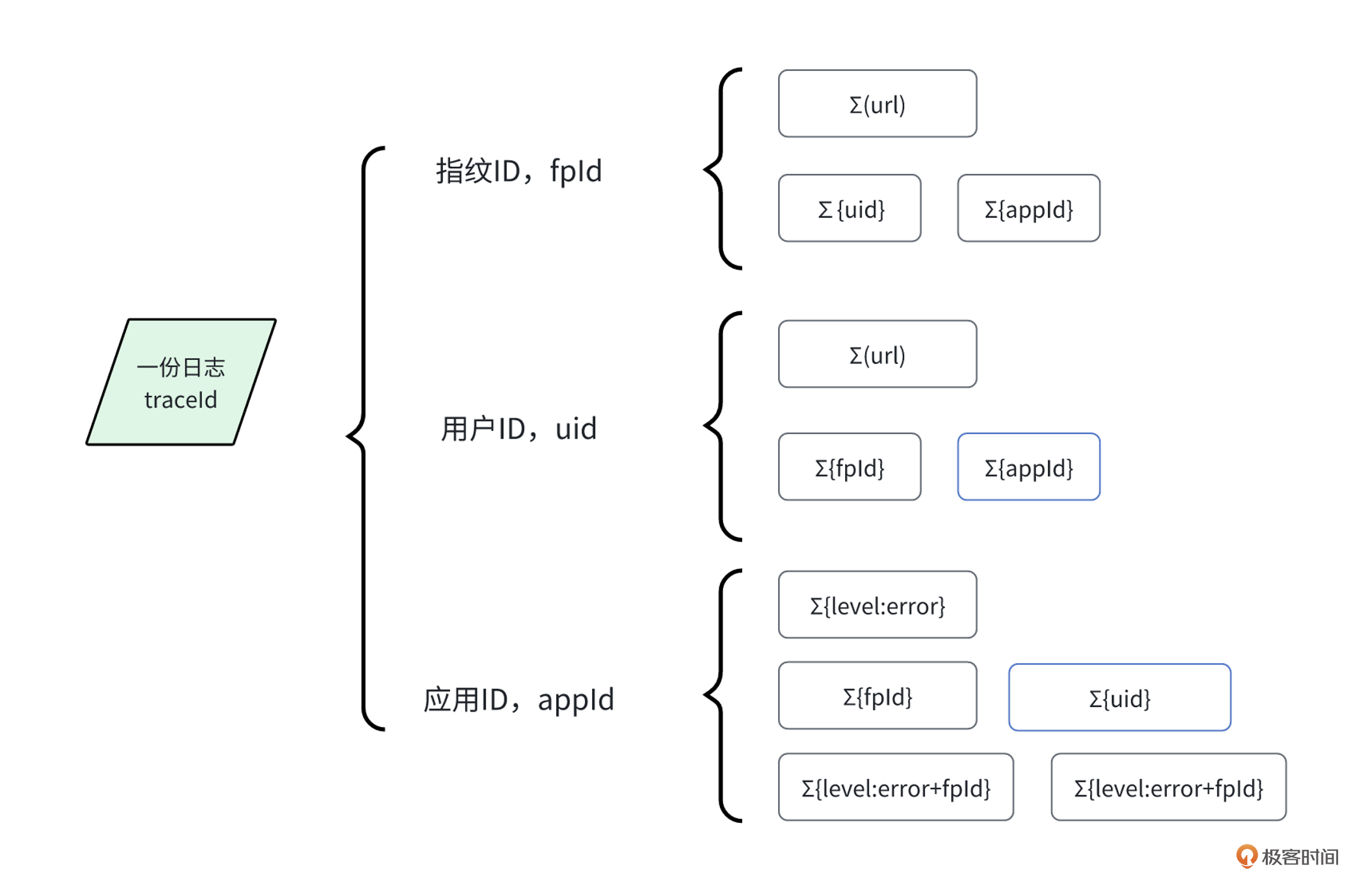
一般情况下,线上故障都是共性问题,例如接口错误或脚本报错等。既然是共性的,那上报的问题、错误信息以及堆栈信息肯定是一致的,因此,我们可以统计共性问题错误数。例如以下的SQL脚本。
level:"error" | select
approx_distinct(fpId) as FPUV,
approx_distinct(uid) as UV,
appId
group by
appId
这段SQL的作用首先是筛选出错误级别的日志,然后查询统计出 fpId 的总数、 uid 的总数以及 appId 。最后,再基于 appId 分组显示数据。最终效果如下图所示。

情景五:基于核心场景的查询规则
相信你肯定遇到过这种情况,就是在后端同学更新系统版本后,过了十几分钟才发现有一个接口出现故障,而且前端应用一点动静都没有,但是用户已经开始频繁的客诉了。
这是一个典型的全链路监控不完整的例子。
但是,如果我们把 type 属性值设定为Fetch,将level属性值设定为error,就能筛选出请求类日志。这样我们可以能做很多事情了,例如监听核心接口。
那具体怎么设定呢?
第一种方法,我们编写一个脚本,统计日志总数量,并设置一个监控通知的阈值。超过这个阈值就发送一次告警。例如,下面的SQL脚本用于统计每个应用请求接口错误的总数。
第二种方法,我们可以统计接口的错误数,然后进行重点分析。例如通过 data.url。
level:"error" and type:"Fetch" | select
appId,
json_extract_scalar(data, '$.url') as url,
count(json_extract_scalar(data, '$.url')) as total
group by
appId,
url
这样做,我们就能解决前端没动静的问题了。只要后端出现故障,前端就能立即发现并发出警报。当然,通过这个例子,我们发现 type 和 level 还能够匹配出更多的规则,从而帮助我们快速发现不同类型的问题。我们还是通过一张图看看这个组合的关系情况。
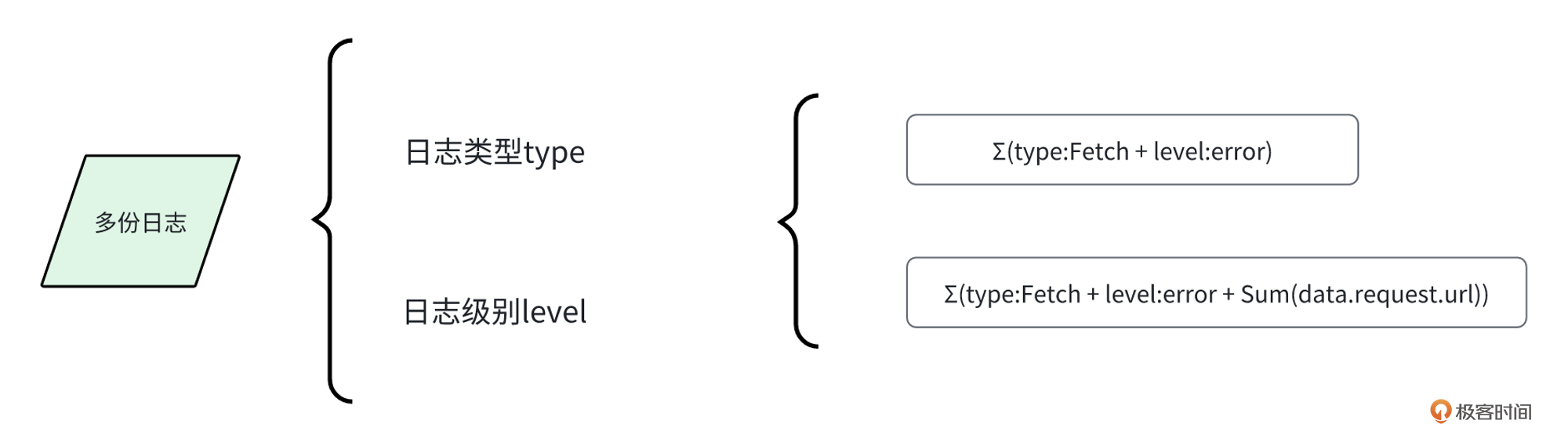
情景六:基于相同问题的查询规则
我曾经遇到一个问题。团队交接了一个运行很久的前端项目。在上线全链路监控后,我们发现有一个接口每天都有固定的报错量。通过查看日志,我们发现该接口使用了GET请求方法。然而,在与后端沟通后,才发现该接口实际是要用POST请求方法的。
我不清楚是什么原因使用了GET,但这无疑是一个接口问题,而我们之前提到的 data.url 属性正好可以用来发现这类问题。
事实上,我们还能用 dataId 来检测这种问题。由于dataId生成公式的机制能够统计出相同问题的错误次数,所以我们能通过判断错误次数来分析问题的严重性。
例如下面SQL脚本,通过计算 data.dataId 的总数,就可以统计相同问题的数量。
level:"error" and type:"Fetch" | select
appId,
json_extract_scalar(data, '$.message') as message,
json_extract_scalar(data, '$.dataId') as dataId,
count(json_extract_scalar(data, '$.dataId')) as total
group by
appId,
dataId,
message
最终的查询效果图参考如下。

我们再通过组合、汇总加分组的方式来分析当前应用存在多少种错误。如果其中一种错误出现大量的日志,那就说明我们需要立刻关注这个问题。
总的来说, dataId 不仅能找出相同的问题,还可以通过判断问题的总数是否超过阈值来发出告警通知。如果结合 type 类型和 level 级别,还可以细化问题类别。
持续调优监控规则
其实,监控规则并没有具体的监控标准或规定。例如共性问题和核心问题,就需要我们根据项目的实际情况设计监控脚本。
为什么需要优化SQL脚本和规则条件呢?
你想想看,前端页面每天都要应对不同环境和交互行为的用户,问题种类是非常难以预测的。因此,我们无法一开始就设定出完全合理的监控脚本和规则。但是,我们可以先从常见的问题入手,逐步优化和完善SQL脚本,直到告警数量和作用能覆盖大部分的问题。
还有一个问题,业务形态是不断变化的,问题数量和用户数量也在波动。我们又该怎么设定脚本规则的阈值呢?
其实,阈值的设定也没有具体标准,不同的项目,用户量级和问题数量的变化都会影响阈值的设定。例如,这个月我们设定错误监控告警的阈值为10,可能下个月流量翻倍,我们就要重新调整阈值,比如20。
因此,我们在建立监控和告警体系时,需要持续优化SQL脚本、规则条件以及阈值,才能确保监控通知的准确性、有效性。
总结
在这节课中,我们详细讨论了如何基于全链路数据结构来设计有效的告警脚本和规则。我们一共讨论了6种规则,包括两种基于用户ID和指纹ID的问题查询规则,它们能帮助前端团队快速定位日志和分析问题。其余四种规则是为了帮助团队设定告警通知。
学习了这些规则后,我相信你应该知道如何使用前端全链路数据来定制告警脚本和规则了。实际上,随着对数据的深入理解和分析,我们可以更精准地定制告警规则。
再次强调的是,每个项目都有其独特的需求和问题,这意味着我们需要根据项目的具体情况,不断调整和优化监控策略。只有这样,我们才能确保监控策略能适应业务环境的变化,快速应对问题。
下节课,我们继续探讨监控体系中的另一个部分,可视化监控。
思考题
现在,给你布置两道思考题。
第一,你的团队在使用监控系统时,设定了多少个告警规则和条件?它们都有效地发挥作用,帮助团队快速发现问题吗?如果需要优化,我们应该如何进行?
第二,结合你的实际项目,除了课程中提到的各种监控规则和SQL脚本,还有哪些方面可以监控?
欢迎你在留言区和我交流。如果觉得有所收获,也可以把课程分享给更多的朋友一起学习。我们下节课见!
- 苏果果 👍(0) 💬(0)
完整源码入口: https://github.com/sankyutang/fontend-trace-geekbang-course
2024-07-18 - 若水清菡 👍(0) 💬(1)
我们用grafana监控预警发现对流量异常做监控就很麻烦,业务流量有低峰和高峰。某个核心接口流量异常,比如qps大于多少或小于多少就报警,再通过复杂的函数去计算现在的流量相对前五分钟增加或减少多少,这些监控规则的设置比较考验开发和运维。
2024-07-24 - westfall 👍(0) 💬(0)
在后端有自己的告警的前提下,前端还需要对后端接口异常做告警吗?
2024-05-29 - Geek_daf4db 👍(0) 💬(1)
有交流群吗
2024-05-28