14 数据上报方案:如何在不影响用户体验下实现数据上报?
你好,我是三桥。
前面几节课,我们一直学习如何在前端应用中捕获前端异常信息,并基于全链路数据结构把信息存储起来。这节课,我们就来看下应该如何用最优的方法,把异常信息上报到后端服务。
不少前端同学都非常熟悉监控平台SDK上报埋点数据的流程,那在这节课,我们换个角度探讨3个重要的逻辑,分别是选择上报方式、实现简易的上报接口以及选择上报时机。
前端埋点上报的方式
实际上,前端全链路的埋点上报方案和前端监控埋点的方案是相同的。目前主流的前端监控平台都是使用GIF进行埋点,例如百度统计、谷歌统计等。
什么是上报呢?就是当前端页面产生链路日志后,将日志数据传递给服务器的过程。也就是说,只要能将数据上报到服务器,那么无论是GIF请求还是Fetch请求,监控服务器是不需要关心具体的上报方式的。
不过选择上报方式也很重要。在说如何选择之前,我们先来了解下三种常见的请求上报方式。
为什么不用Fetch和xhr?
虽然使用Fetch特性上报埋点是一个可行的方案,但并不是最优的选择。有三个原因。
第一,Fetch需要遵循同源策略。也就是说,跨域请求可能会因为浏览器的限制而请求失败。
第二,Fetch是新Web浏览器的特性和标准,要满足兼容旧版本浏览器,就需要采用polyfill的方式解决兼容问题,无形中给SDK增加了不少兼容性代码,造成负担。
第三,直接使用Fetch可能会受到网络波动或请求超时等因素影响,导致数据丢失或不准确。
另外提一句,XMLHttpRequest是最早支持前端代码请求的方法,但需要封装更多的代码,而且还不支持Promise。但因为它对低端浏览器的兼容性是最好的,所以,我们可以把它作为向下的兼容方案。
使用sendBeacon的利弊
第二种方案利用了浏览器Beacon API能力。它可以给服务器发送异步和非阻塞请求,这类请求是不需要响应结果的。它最大的优势是浏览器会在保证页面卸载前就把请求发送完成。所以我们经常会利用它将分析数据发送给服务器。
以下是使用sendBeacon的实现代码。
// src/core/util.ts
export function sendBeacon(url: string, data: TraceData) {
if (typeof navigator === 'undefined') return
navigator.sendBeacon && navigator.sendBeacon(url, JSON.stringify(data))
}
需要注意的是,Beacon API存在一定的局限性。例如兼容性问题,像微信内置浏览器和微信小程序这两种场景,Beacon API就无法使用了,需要考虑使用其它方案。
使用GIF图片
第三种方案是通过图片请求的方式完成数据的上报,只要创建一个Image对象,并将其src属性设为“需要上报的URL”就可以了。
这是一种既简单又快速的方式。它解决了前面两个技术的兼容性问题和跨域问题,甚至还有一个明显的优点,就是不会阻塞页面加载,即使请求失败也不会影响用户对页面的正常交互体验。所以,前端监控平台通常会采用这种方案。
那怎么使用图片才是最优的方案呢?我们先选择1x1像素的透明图片,也是最小的合法图片。接着,我们选择GIF格式,因为它的体积比BMP、PNG格式还要小,所以能节省用户的流量。
下面是使用图片上报的逻辑实现代码。
// src/core/util.ts
export function sendByImg(url: string, data: TraceData) {
const spliceStr = url.indexOf('?') === -1 ? '?' : '&'
const imageUrl = `${url}${spliceStr}data=${encodeURIComponent(safeStringify(data))}`;
let img = new Image()
img.src = imageUrl
img.onload = function() {
console.log("Tracking data sent successfully!");
img = null
};
img.onerror = function() {
console.error("Failed to send tracking data.");
img = null
};
}
通过对比三种常见的请求方式,最终我们选择使用GIF图片作为埋点上报的方案。至于其它方案,在真正需要用到的时候再去兼容即可。
简易的上报接口
有些同学可能会好奇,前端使用GIF图片上报埋点的方式,后端服务是怎么实现的?为什么发起一次图片请求,就可以把参数带回服务器端,并且还能把数据保存起来?
这里虽然涉及一些后端的知识,但并不难理解。实际上,实现埋点上报接口,代码逻辑不会很多,反而是最容易实现的接口。
接口的实现
我们以前端同学熟悉的Node.js为例,结合Express框架,实现一个简单的上报接口。具体的代码实现如下。
const express = require('express');
const app = express();
const port = 3000;
app.get('/track.gif', (req, res) => {
const data = req.query.data; // 获取URL中的data参数
// 在实际应用中,这里可以将data存储到数据库或日志文件中
console.log("Received tracking data: ", data);
// 返回一个1x1像素的透明GIF图片
const img = Buffer.from('R0lGODlhAQABAIAAAP///wAAACH5BAEAAAAALAAAAAABAAEAAAICRAEAOw==', 'base64');
res.writeHead(200, {
'Content-Type': 'image/gif',
'Content-Length': img.length
});
res.end(img);
});
app.listen(port, () => {
console.log(`Server running at http://localhost:${port}`);
});
这几行代码有三个重点。
第一是使用track.gif名字作为接口路径,模拟出gif格式的URL地址。这个带有gif后缀的地址相当于说明了这个URL是为了让前端代码发起一个图片格式的请求。
第二,创建一个1x1像素的透明GIF图片。其逻辑是把要编码的字符串以Base64编码格式生成Buffer对象。
第三,在返回结果前,给接口的响应类型设置为gif格式,即“image/gif”。再把响应头的内容长度设置为图片的长度。最后通过res.end方法把生成的图片对象返回给前端。
这三个重点,构成了最简单的模拟GIF格式接口的核心逻辑。
日志存储的方案
细心的你可能会注意到,这里的接口并没有实现处理链路日志的逻辑。因为,这里就真正涉及后端的逻辑了。
一般来说,数据都是使用MySQL关系型数据库来存储的,但是日志就不能这样存储了。因为前端页面会产生大量的链路日志数据,如果使用关系型数据库存储,频繁的写入操作会直接影响数据库的性能,尤其是在高并发的情况下,影响更大。
那怎么做才能有效地存储全链路日志呢?
存储日志最常见的做法是把日志存储在日志服务或NoSQL数据库中。具体的方法有4种,日志文件存储、NoSQL数据库、分布式日志存储系统和日志分析平台。
- 日志文件的存储。这种方案就是将前端埋点的日志数据写入日志文件,然后通过定时,将日志文件上传到日志存储系统。不过这种方案还需要处理日志文件,额外工作比较多,因此并不适合全链路日志。
- NoSQL数据库。这种数据库具有良好的横向扩展性和高性能,比较适合存储大规模的日志数据。但它有个缺点,就是对于复杂查询的处理能力比较弱。对于全链路日志来说,如果无法满足复杂的查询需求,那么存储的意义也不大了。
- 分布式日志存储系统,例如Kafka。这类系统专门用于收集、存储和分析高吞吐量的日志,这些系统通常都比较复杂,而且有较高的学习成本和配置工作,同时还有可能需要额外的维护和监控。
- 日志分析平台。这类平台最大的亮点是提供了强大的日志分析和查询能力,可以帮助我们实时监控和分析日志数据。同样地,其部署和维护成本相对较高,也有较高的学习成本。
那这4种方法,我们应该怎么选择呢?
对于小规模的前端应用,我建议直接使用NoSQL数据库就足够了。
如果前端应用需要监控大量实时日志数据,例如直播应用,可以考虑使用分布式日志存储系统。
我建议前端应用可以考虑接入国内云厂商的日志服务,例如阿里云的SLS日志服务、腾讯云的CLS日志服务以及华为云的LTS云日志服务。
下面,我将以存储日志文件为例说明。
首先引入log4js日志库,并配置日志文件为track.log。稍微改造一下前面的代码,最终的效果如下。
const express = require('express');
const log4js = require('log4js');
const app = express();
const port = 3000;
log4js.configure({
appenders: { track: { type: 'file', filename: 'track.log' } },
categories: { default: { appenders: ['track'], level: 'info' } }
});
const logger = log4js.getLogger('track');
app.get('/track.gif', (req, res) => {
const data = req.query.data; // 获取URL中的data参数
// 在实际应用中,这里可以将data存储到数据库或日志文件中
// console.log("Received tracking data: ", data);
logger.info(data);
// 返回一个1x1像素的透明GIF图片
const img = Buffer.from('R0lGODlhAQABAIAAAP///wAAACH5BAEAAAAALAAAAAABAAEAAAICRAEAOw==', 'base64');
res.writeHead(200, {
'Content-Type': 'image/gif',
'Content-Length': img.length
});
res.end(img);
});
app.listen(port, () => {
console.log(`Server running at http://localhost:${port}`);
});
接口上报触发时机
好了,说完埋点接口后,我们就来探讨接口触发的时机。简单来说就是在什么时间和什么场景下把链路日志数据上报到服务器。
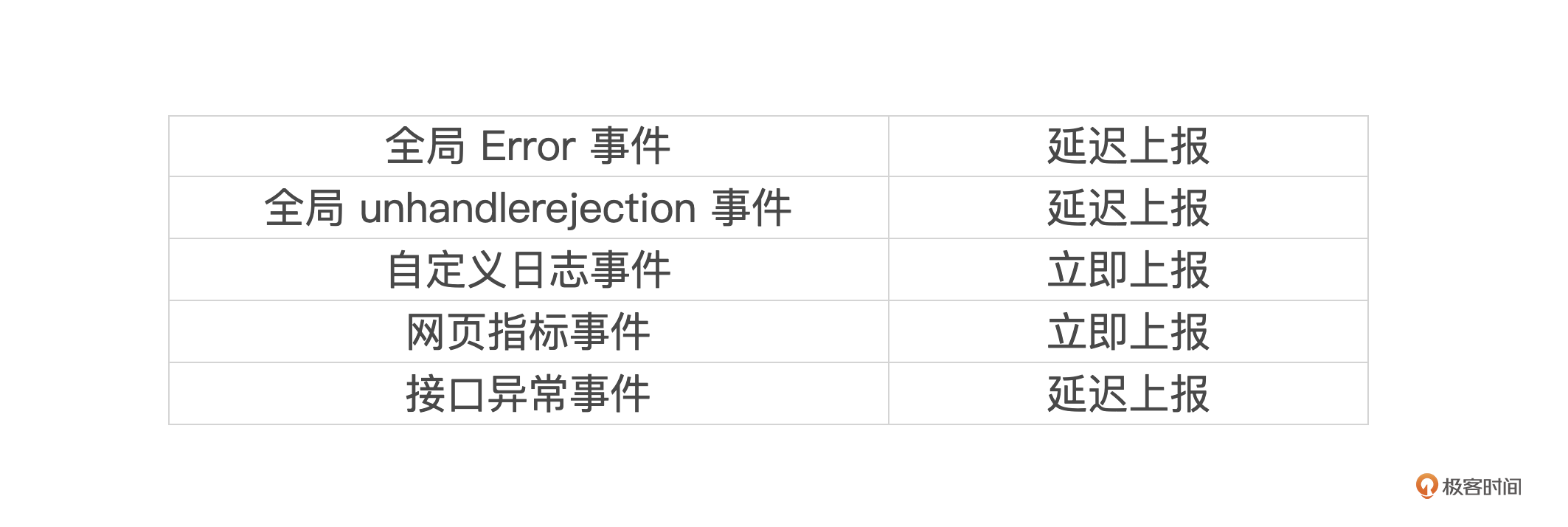
我们在前面几节课学到,触发记录链路日志的事件有5种,全局Error事件、全局unhandlerejection事件、自定义日志事件、网页指标事件、接口异常事件。
网页指标事件在此前已经通过页面pageHide事件和visibilitychange事件自动触发上报,在这里我们就不继续探讨了。
自定义日志事件的主要功能是提供给业务层使用,通过try-catch或特定逻辑进行日志记录。从逻辑角度来看,这种事件并不是高频触发的,所以我们可以提供实时上报的动作。
从代码逻辑的角度看,全局Error、全局unhandlerejection和接口异常应该是触发最频繁的事件,如果每次事件触发就自动上报埋点数据,可能在某个时间点出现大量的图片请求的情况。这种情况不仅会影响用户的体验,还可能会给日志服务带来压力,得不偿失。所以,我们可以考虑使用延迟上报的方法。
通过下图表格,你能更加直观地了解每一种事件的上报时机。
那怎么做才能满足延迟上报的能力呢?
首先,我们定义一个queue队列属性,用于存储需要延迟上报的链路日志数据。同时,我们再设定一个时间间隔,规定每隔多长时间上报一次数据。具体实现代码如下。
// src/baseTrace.ts
export class BaseTrace implements BaseTraceInterface {
// 存储链路日志数据
public queue: TraceData[] = []
// 发送请求时间间隔
public sendTimer = 1000
}
然后,设置默认时间间隔为1000毫秒,从queue中提取日志数据,发送到后端服务。具体的实现逻辑是,在SDK初始化的时候,我们通过使用setInterval函数增加一个定时器,监听queue队列数组是否有日志数据,如果有就提取数据并发送。具体代码如下。
// src/baseTrace.ts
export class BaseTrace implements BaseTraceInterface {
// 初始化实例
public static init(options: TraceOptions): BaseTrace {
const traceSdk = new BaseTrace(options)
// ...省略部分代码
setInterval(() => {
const data = traceSdk.queue.shift()
if (data) sendByImg(traceSdk.dsn, data)
}, traceSdk.sendTimer)
window.traceSdk = traceSdk
return traceSdk
}
}
接下来,我们针对三种不同的事件,将错误事件的链路日志数据存储在queue队列中。具体实现的代码如下。
// src/baseTrace.ts
export class BaseTrace implements BaseTraceInterface {
// 存储链路日志数据
public queue: TraceData[] = []
// 发送请求时间间隔
public sendTimer = 1000
public setTraceData(data: TraceTypeData | TracePerf) {
let type = TraceTypes.CONSOLE
let level = TraceLevelType.Debug
let _data = null
let perf = null
if (!!(data as TraceTypeData).dataId) {
type = getTraceDataType((data as TraceTypeData).type)
level = getTraceDataLevel((data as TraceTypeData).level)
_data = data as TraceTypeData
}
if (!!(data as TracePerf).id) {
type = TraceTypes.PERF
level = getPerfLevel(data as TracePerf)
perf = data as TracePerf
}
const traceData: TraceData = {
type,
level,
createdAt: getTimestamp(),
updatedAt: getTimestamp(),
data: _data,
perf,
breadcrumbs: this.breadcrumb,
traceId: uuid(),
ua: this.userAgent,
bt: this.browserType,
fpId: this.fpId,
appId: '',
clientType: TraceClientTypes.BROWSER_H5,
url: document.URL,
pid: this.pageId,
}
return traceData
}
public send(data: TraceTypeData | TracePerf) {
const traceData = this.setTraceData(data)
sendByImg(this.dsn, traceData)
}
public saveError(event: ErrorEvent) {
// ...省略部分代码
if (!isResTarget) {
// ...省略部分代码
this.queue.push(this.setTraceData(traceData))
} else {
// ...省略部分代码
this.queue.push(this.setTraceData(traceData))
}
}
public onFetchError(message: OnFetchError) {
// ...省略部分代码
this.queue.push(this.setTraceData(errorData))
}
}
目前为止,我们实现了延迟上报的功能,出现大量错误日志的时候,就不会一次性发起大量图片请求了。
总结
这节课,我们重点探讨了全链路埋点中3个重要知识点,如何选择上报方式,实现上报接口以及确定上报时机。
关于前端埋点的上报,我们对比了三种方案,Fetch和xhr、Beacon API和GIF图片。Fetch和xhr由于受到同源策略和兼容性问题的限制,存在一定的局限性。另外,虽然sendBeacon可以在浏览器后台异步发送数据,但可能会因浏览器在发送前关闭页面而导致数据丢失。幸好GIF图片上报方案相对简单快速,解决了兼容性问题和跨域问题,即使请求失败也不会影响用户和页面的正常交互体验。因此,我们最终选择使用GIF图片作为埋点上报方式。
至于上报时机,我们需要根据实际情况,结合事件类型来决定是立即上报还是延迟上报。
我们还利用Node.js和Express框架,创建了一个1x1像素透明GIF图片的URL接口地址,并以日志文件存储为例展示了链路日志数据的存储方式。
需要特别强调的是,收集用户链路日志必然涉及一些用户隐私数据,我们应该在上报数据前就进行敏感数据的脱敏。如果不进行脱敏操作,那一些敏感数据(例如token)就会被人利用,甚至篡改数据。
思考题
现在给你布置两道思考题。
第一题,如果前端埋点的链路日志中存在敏感数据,例如手机号、密码、token等信息,我们应该怎么做才能脱敏呢?脱敏的算法又是怎么实现呢?
第二题,课程中提到了立即上报和延迟上报两种上报方法。那如果使用批量日志上报,我们应该如何实现这段代码逻辑?
欢迎你在留言区和我交流。如果觉得有所收获,也可以把课程分享给更多的朋友一起学习。我们下节课见!
- 苏果果 👍(0) 💬(0)
完整源码入口: https://github.com/sankyutang/fontend-trace-geekbang-course
2024-07-18 - 天天 👍(0) 💬(1)
一般怎么脱敏呢,老师的答案可以给一下吗?
2024-12-04 - 谢谢 👍(0) 💬(1)
你好,请问下,在总结里看到 sendBeacon 是但可能会因浏览器在发送前关闭页面而导致数据丢失,这不是 sendBeacon 的优势吗?而且其他两种上报方式是否也会遇到浏览器关闭或者页面卸载的时候,数据丢失的情况呢?
2024-07-02 - 天天 👍(1) 💬(0)
是可以延迟发送日志,上报时机和上报数据讲需要考虑
2024-11-28 - JuneRain 👍(1) 💬(2)
有个问题,图片方式上穿日志是GET请求,如果日志数据量大,字符串化后拼接的URL长度超限制怎么办?
2024-05-24 - Ryan 👍(0) 💬(0)
两个思考题的答案有了吗?急需解惑
2024-11-09 - Alex酱 👍(0) 💬(0)
如果接收端配置了kafka的情况下,是否可以不用队列存储的方式呢?
2024-05-27