05 数据结构(下):如何设计页面业务问题相关的数据结构?
你好,我是三桥。
上节课,我们重点学习了如何根据最少字段的原则设计链路日志格式的17个通用字段。
然而,这些字段并不包含问题信息。假如我们希望提前发现问题,又该怎么把问题涉及的信息提前存储在链路日志里面呢?这节课,我们一起设计记录问题的字段方案。
我从代码维度把日志分成了异常信息、性能数据、操作行为三套数据模型,如下图。
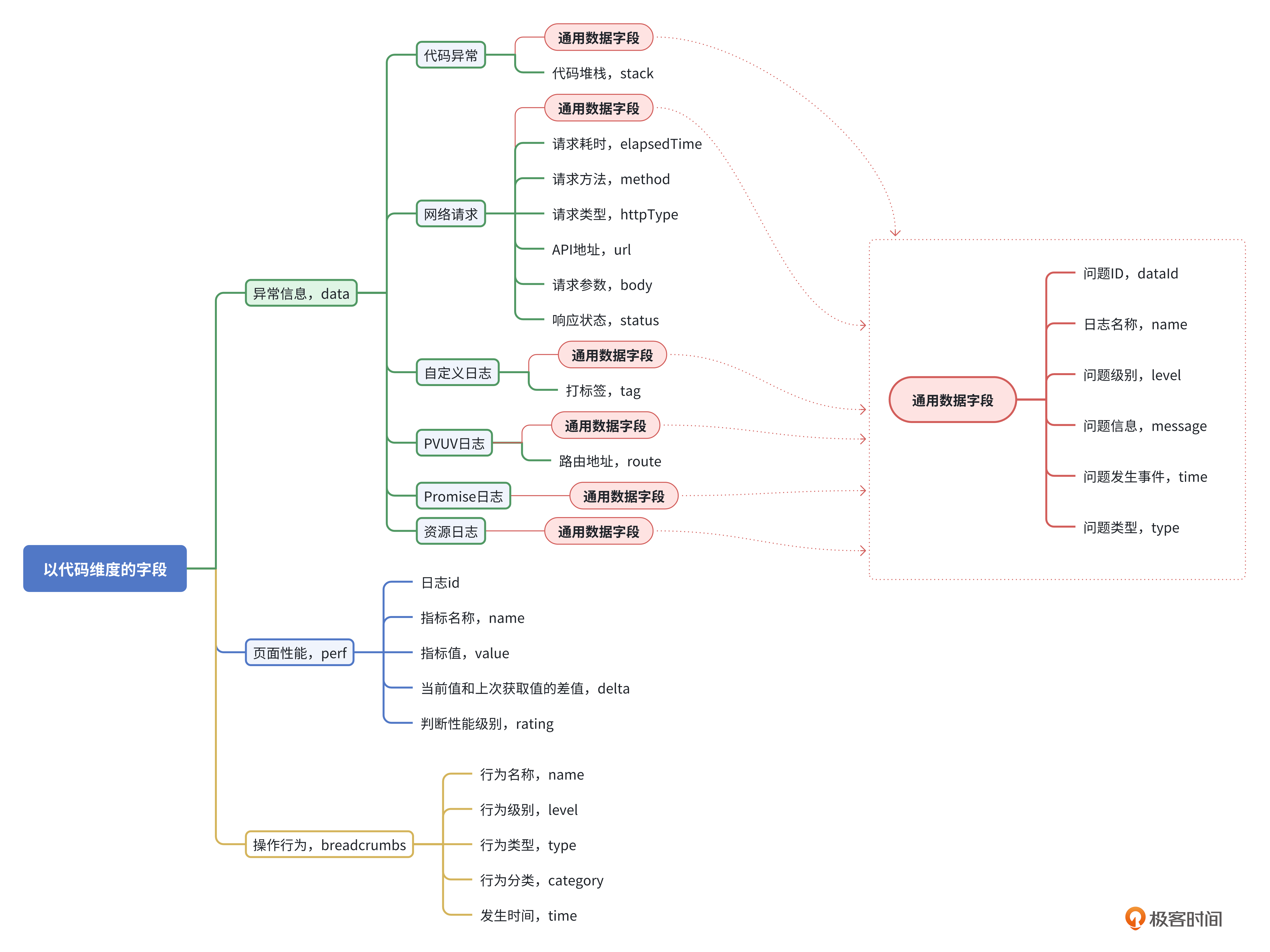
基于这三套数据模型,我们分别用data字段记录异常信息、perf字段记录页面性能信息以及breadcrumbs字段记录用户操作行为。参考代码如下。
// 完整的全链路日志
type TraceData = BaseTraceInfo & {
// 记录错误信息
data?: TraceTypeData
// 记录操作行为
breadcrumbs?: TraceBreadcrumbs
// 记录性能信息
perf?: TracePerf[]
}
关于这三个字段的用法,我会在本节课的最后跟大家探讨。我们先从异常信息类型说起。
异常信息类型
虽然前端异常情况有很多,但总结下来,实际主要就是6种情况。
- 代码异常。不仅包括脚本失败,还应该包含trycatch中的catch异常。
- Promise异常。这主要是由异步代码引起的逻辑问题。
- 网络请求。通常来说,发起http请求都无法保证100%的成功率。
- 资源异常信息。和网络请求同理,但这里的重点在于监控图片和一些外部资源的请求状态。
- PV/UV日志。用于记录用户访问的次数和频率,它也是唯一的非异常日志。
- 自定义日志。目的是在一些特殊场景下记录日志,以便快速定位问题。
我们仍然以最少字段为原则,通过抽象化的方法,将通用数据字段和特殊字段组合,设计这6种场景。
最后得出下面的字段设计图。
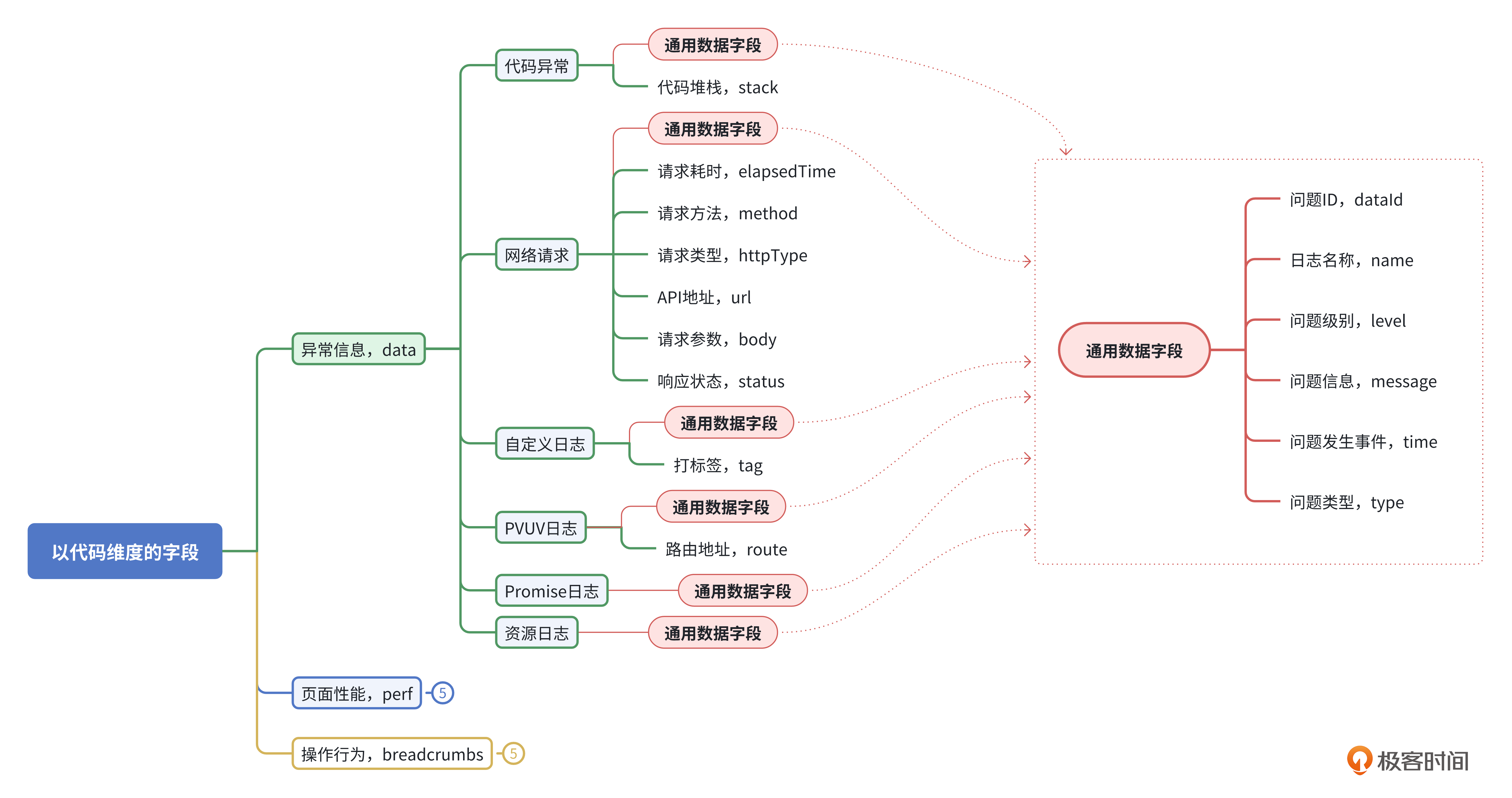
通用数据字段
要成为一名合格的前端工程师,其中一项重要的能力是抽象思维。对于异常信息,我们需要进行抽象化处理。数据的抽象化通常包括一些最常见且最关键的字段属性,如标识、名称、信息、时间。
还是遵循最少字段设计原则,我们看一下已经设计好的抽象结构代码。
type TraceBaseData = {
// id
dataId: number
// 日志信息名称
name: string
// 问题级别
level: TraceDataSeverity
// 异常信息
message: string
// 发生时间
time: number
// 问题类型
type: TraceDataTypes
}
经过最少字段原则的设计,我们可以看到有6个字段。先说其中的4个,dataId、name、message以及time。
- dataId。这个字段不是指唯一键值,而是对异常信息进行哈希后得出的字符串。如果有大量相同字符串,那就说明存在通用异常问题。
- name。这是为异常日志提供的一个名称字段。
- message。这个字段的核心作用是记录异常信息的详情或者描述。
- time。顾名思义,就是时间。指事件触发的时刻。
这4个字段比较好理解,我着重说另外两个,问题级别level以及问题类型type。
问题级别定义的是一条异常日志的严重程度。比如,在前端代码请求接口后,如果结果返回的状态码为400或500,我们可以将该问题级别定义为高危或极其严重,如果频繁出现这种结果,那就说明用户已经无法使用功能,但我们可以在前端链路里提前发现。
可能有同学会想了,上一节也有提到level字段了,那这里的问题级别level和它有什么区别呢?实际上,这两者是不同维度的级别。基础数据的level是以日志完整维度划分的级别,而这里的level是以问题维度划分的级别。也就是说,在监控中,我们可以通过设置两个level维度级别选择性地监控。
为了尽可能覆盖更多的问题级别,我们给level字段定义了8种级别,也就是TraceDataSeverity枚举类型代码。
declare enum TraceDataSeverity {
// 其他
Else = 'else',
// 错误级别
Error = 'error',
// 告警级别
Warning = 'warning',
// 日志级别
Info = 'info',
// 调试级别
Debug = 'debug',
// 低危级别
Low = 'low',
// 普通级别
Normal = 'normal',
// 高危级别
High = 'high',
// 极其严重
Critical = 'critical'
}
特别强调的是,High和Critical属于最高级别。出现这类日志的时候,前端同学需要立即关注,并且分析是否存在线上故障。
再说说另一个字段type,它描述的是错误日志类型。这个类型里我一共定义了10种枚举值。
其中,6种枚举值分别对应的是前端脚本类型JAVASCRIPT、请求类型HTTP、资源RESOURCE、路由ROUTE、性能PERF、调试LOG。
其中,Promise是我们经常用来实现大量的业务逻辑的。而基于异步的特性,我们可以在捕获异常的时候使用PROMISE。UNKNOW则用于一些未知异常的捕获。此外,我们还额外定义了两个枚举值Vue和React,方便前端组件代码在异常时标记对应的技术栈。
最后,我们使用TraceDataTypes枚举名字定义类型。参考如下代码。
declare enum TraceDataTypes {
UNKNOWN = 'UNKNOWN',
JAVASCRIPT = 'JAVASCRIPT',
LOG = 'LOG',
HTTP = 'HTTP',
VUE = 'VUE',
REACT = 'REACT',
RESOURCE = 'RESOURCE',
PROMISE = 'PROMISE',
ROUTE = 'ROUTE',
PERF = 'PERF'
}
代码异常类型
有了通用的抽象数据模型后,再定义上层数据模型。先来看看代码异常类型。
咱们都知道,当前端代码异常报错时会抛出异常,控制台也会输出堆栈信息。堆栈信息是我们前端同学分析代码位置、快速发现问题的主要信息来源。所以,代码异常类型还需要扩展一个记录堆栈信息的字段,stack。
好了,现在我们得到了获取代码异常信息的代码。
网络请求类型
网络请求类型的作用是追踪前端向后端接口发起请求的状态。相对于脚本错误类型,它需要更多扩展字段,但考虑到最少字段原则,我们仅设计出必要的6个字段就可以了,包括接口地址、请求方法、请求参数、响应状态、执行耗时、脚本请求类型。
最终,我们得到网络请求类型的代码。
// 请求类信息
type TraceDataFetch = TraceBaseData & {
// 执行时间,用于统计耗时
elapsedTime: number
// 请求方法
method: 'POST' | 'GET'
// 请求类型
httpType: 'fetch' | 'xhr'
// 请求地址
url: string
// 请求参数
body: string
// 响应状态
status: number
}
其余类型字段(Promise、资源、自定义、PV/UV)
剩余的其它数据类型,包括Promise类型、资源类型以及自定义日志类型。
由于公共字段已经满足全链路概念的能力,所以,基于最少字段原则,对于Promise和Resource,我不会再扩展过多的字段。
至于自定义日志类型,我会增加一个tag字段作为对上层业务内容的补充,既可以当成标签使用,也可以当作一段需要标记的字符串。还有PV/UV统计类日志,也只补充一个用于SPA的静态路由字段,记录用户当前所在的页面。
这些类型字段的设计,我们都会定义新的命名作为类型名称,之后在代码中定义数据变量的时候也会更方便。
参考代码如下。
// Promise类型
type TraceDataPromise = TraceBaseData
// 资源类型
type TraceDataResource = TraceBaseData
// 普通日志
type TraceDataLog = TraceBaseData & {
tag: string
}
// PV/UV
type TraceDataPageView = TraceBaseData & {
route: string
}
当然,在真实项目中,如果有非常重要的字段能协助定位问题,也是可以扩展的。记得不要盲目增加、过度增加就好。
网页指标类型
学习完异常信息类型的定义后,接下来我们来学习下如何记录页面性能数据。
相信很多前端同学听到收集页面性能数据,就会联想到Performance对象。不过我并不推荐使用Performance,这里我会使用WebVitals来评估页面性能。关于为何选择WebVitals,我会在后面的小课中详细讲解。
由于我们用到WebVitals网页指标,设计字段的时候就需要参考WebVitals提供的能力,例如指标值、指标衡量等字段。最后我们设计了出6个指标、12个属性值的数据模型,参考如下代码。
// webVitals性能收集信息对象
type TracePerf = {
id: string
LCP?: number
LCPRating?: TracePerfRating
FID?: number
FIDRating?: TracePerfRating
FCP?: number
FCPRating?: TracePerfRating
TTFB?: number
TTFBRating?: TracePerfRating
CLS?: number
CLSRating?: TracePerfRating
INP?: number
INPRating?: TracePerfRating
}
设计12个指标属性的目的,是为了更清晰地知道每个指标值的实际情况,不用做二次处理,就能直接在监控和通知上使用。
另外,由于这6个网页指标的计算时机存在差异,不可能在同一时刻获取,所以我把12个指标属性定义为非必选项属性。
操作行为类型
最后我们探讨一下用户的操作行为类型。在真实项目中,行为数据的记录通常都是自动化的,比如用户点击一次按钮,程序就会自动识别用户的点击操作,把相应的行为数据记录下来。
先来看下如何定义操作行为的类型。一共有5个属性字段,参考代码如下。
// 基类行为日志类型
type TraceBaseAction = {
// 动作名称
name: string
// 动作参数
level: TraceDataSeverity
// 动作时间
time: string
// 日志类型
type: BreadcrumbTypes
// 行为分类
category: BreadcrumbsCategorys
}
// 行为日志
type TraceAction = TraceBaseAction & {
// 行为动作相关的信息,可以是DOM,可以是错误信息,可以是自定义信息
message?: string
// 请求参数
request?: any
// 请求结果内容
response?: any
// 错误堆栈信息
stack?: string
}
其中level字段跟TraceBaseData类型的level字段一样,因为它们都是定义问题严重性的,而且两个字段是同步的。
另外,type和category看着很像,实际上是有区别的。
type字段定义了TraceBreadcrumbTypes枚举类型,它和TraceDataTypes枚举类型很接近,但不完全相同,比如TraceDataTypes枚举则包含有PERF值和LOG值,而category字段主要定义行为日志的类别,比如用户点击、请求、日志输出、组件生命周期等。
所以,type的定位是异常信息的类别,category则是行为日志类别,两者是不相同的。
这两个枚举类型的代码定义如下。
declare enum BreadcrumbsCategorys {
Http = 'http',
User = 'user',
Debug = 'debug',
Exception = 'exception',
Lifecycle = 'lifecycle'
}
declare enum BreadcrumbTypes {
ROUTE = 'Route',
CLICK = 'UI.Click',
CONSOLE = 'Console',
FETCH = 'Fetch',
UNHANDLEDREJECTION = 'Unhandledrejection',
RESOURCE = 'Resource',
CODE_ERROR = 'Code Error',
CUSTOMER = 'Customer'
}
整合一份完整的链路日志
至此,我们探讨完了最常见的异常信息数据类型。那我们应该如何把这节课记录的问题信息和上节课的基础数据结构整合在一起,形成一份完整的链路日志呢?
首先,为了确保两者之间的字段命名不重复,我的方案是新增data字段来记录日志,让记录问题信息和基础数据字段不在同一层级,参考前面的TraceData类型代码定义。
其次,由于性能数据是通过对象的方式存储每个网页指标的,它不是一种异常或错误信息,因此也要新增perf字段。
最后,用户行为类型。它和记录问题信息、性能数据不同,是贯穿用户整个行为过程的一个快照。所以我们也扩展一个字段breadcrumbs记录行为信息。
最终,一份完整的链路日志类型就定义完毕,我们用TraceData命名,代码参考如下。
// 一份错误信息的类型集合
type TraceTypeData = TraceDataFetch | TractDataCodeError | TraceDataPromise | TraceDataResource | TraceDataLog | TraceDataPageView
// 操作行为日志
type TraceBreadcrumbs = TraceAction[]
// 完整的全链路日志
type TraceData = BaseTraceInfo & {
// 记录错误信息
data?: TraceTypeData
// 记录操作行为
breadcrumbs?: TraceBreadcrumbs
// 记录性能信息
perf?: TracePerf[]
}
这里有一个问题,为什么data、breadcrumbs以及perf都是非必要字段呢?
你看,如果当前日志是记录性能的,那么data和breadcrumbs其实就没必要收集了,对不对?同样的,在正常情况下,如果有异常日志,perf字段也没必要记录,因为关联意义不大。同时,有了breadcrumbs的设计,日志量会非常庞大,而从实际情况来看,只有需要定位问题的时候,我们才需要用户的上下文操作信息。所以,breadcrumbs字段可以根据实际情况来设定是否需要上报到服务器端。
好了,现在我们以极客时间移动端H5请求一个接口作为例子,写一份请求正常状态的完整日志。
// trace data json
{
"traceId": "0bdf6c8e-25c8-427d-847a-9950318a2e14",
"level": "warn",
"type": "Action",
"ua": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36",
"bt": "mobile",
"fpId": "c77a37f4",
"uid": 1002,
"appId": "geekbang-h5",
"clientType": "browser",
"pid": "088c8a92-5a24-4144-9c37-310848c397e1",
"url": "https://time.geekbang.org/",
"createdAt": "2024-03-13T15:35:30.292Z",
"updatedAt": "2024-03-13T15:35:30.292Z",
"data": {
"dataId": 2384780,
"name": "fetch-api",
"level": "info",
"message": "success",
"time": 1710345961943,
"type": "HTTP",
"elapsedTime": 166.34,
"method": "POST",
"httpType": "fetch",
"url": "https://time.geekbang.org/serv/v3/product/infos",
"body": "{\"ids\":[100035801,100002401,100024001,100007001,100003901,100029601,100027801,100034101,100042501,100023701]}",
"status": 0
},
"breadcrumbs": [
{
"name": "fetch-api",
"level": "info",
"time": "string",
"type": "Fetch",
"category": "hhtp"
}
]
}
这份代码相当于拆解了一份完整链路日志。将通用基础数据结构、异常信息类型、操作行为类型、性能数据类型结合,我们可以整理成一套如下的链路日志关系图。
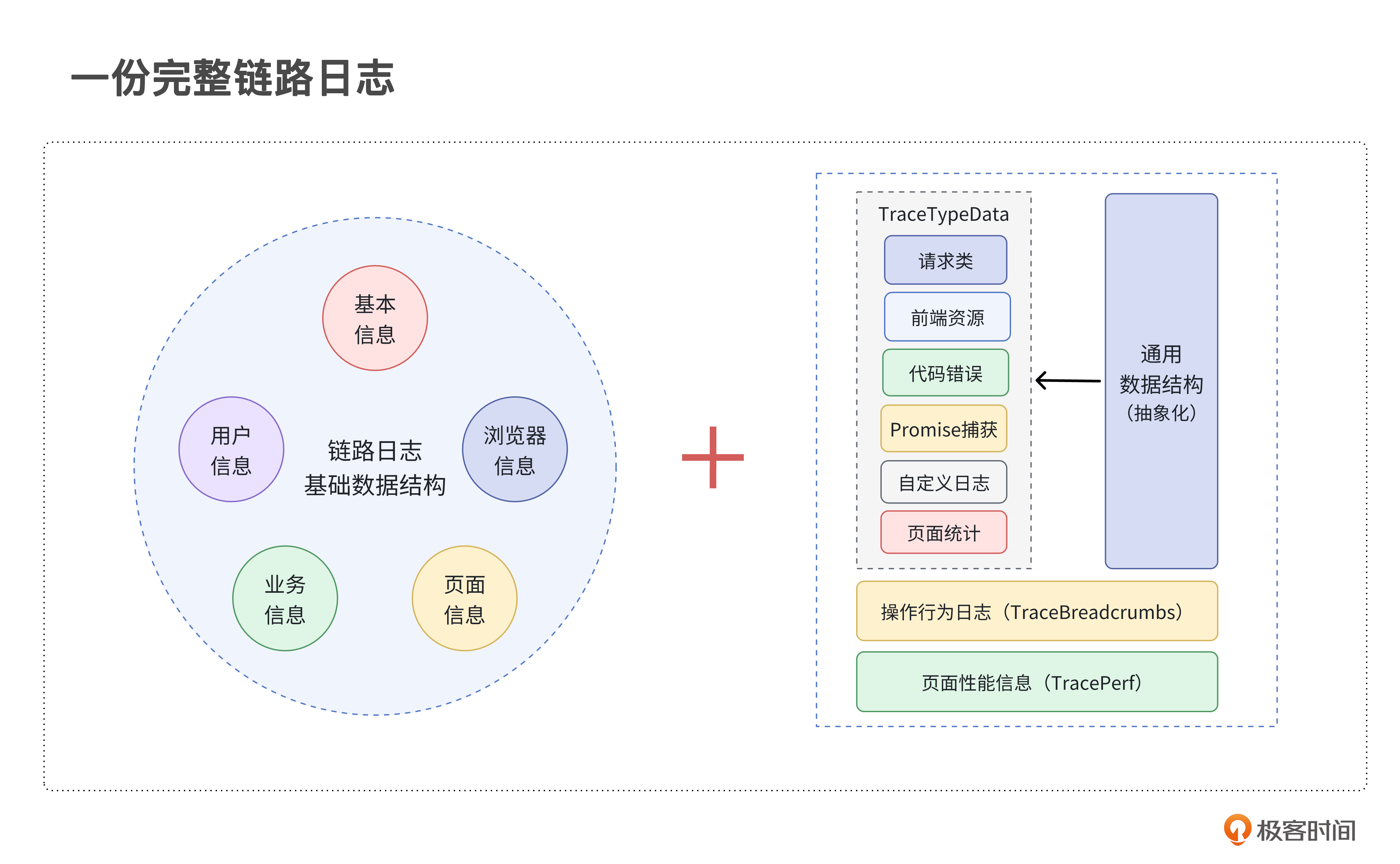
总结
这节课,我们进一步探讨了前端全链路日志中记录问题字段的设计。
需要强调的是,我们仍然是以最少字段为原则去设计的。从记录问题的维度考虑,我们可以把众多的信息字段分成三大类,异常信息类、网页指标类和操作行为类。
异常信息类型的主要作用是在程序代码异常的时候,把异常堆栈信息记录下来,然后提供给前端同学做分析。其中,代码异常和网络请求是我们最常见也是最重要的两种场景,是影响用户体验的核心问题,需要特别重视。
网页指标类型,是基于WebVitals的理论设计出的6个核心指标,由于考虑到每个页面指标的获取并不同步,所以,提前定义12个字段属性更合适。
除了记录异常和性能,用户的操作行为也非常重要。我们基于最少原则和行为特性,设计出了6个字段,以保证能够还原出用户交互的一个快照,帮助我们快速了解用户的真实情况。
思考题
此刻,我希望你能对自己的前端项目经验进行一些反思。在你所参与的前端项目中,最常遇到到的线上问题是关于哪一类业务的?在没有链路日志和监控的情况下,你又是如何通过埋点解决这些问题的呢?
欢迎你在留言区和我交流。如果觉得有所收获,也可以把课程分享给更多的朋友一起学习。我们下节课见!
- 苏果果 👍(0) 💬(0)
05源码: https://github.com/sankyutang/fontend-trace-geekbang-course/blob/main/trace-sdk/src/typings/typing.d.ts 完整代码入口: https://github.com/sankyutang/fontend-trace-geekbang-course
2024-07-18 - Aaaaaaaaaaayou 👍(0) 💬(1)
感觉老师的设计中有很多 Sentry 的影子,像 dataId 就类似于 fingerprint
2024-09-14 - 李家的风 👍(0) 💬(1)
课程有源码链接吗
2024-06-27 - Loogeek 👍(0) 💬(1)
课程有源码链接吗
2024-05-22 - Cloudy 👍(0) 💬(1)
请问本文中使用到的类型 BaseTraceInfo 是在哪儿定义的?看最后的案例,感觉是前一篇文章中定义的类型 BaseTraceData
2024-04-24 - Sklei 👍(0) 💬(1)
pv数据是自动采集还是需要用户手动埋点采集
2024-04-24