04 数据结构(上):如何设计全链路数据模型
你好,我是三桥。
上节课,我简单介绍了前端全链路的3要素和14条路径。在14条路径里面,数据指标占了一大部分,一共有7种不同大类的指标类型数据。那这些指标类型要怎么用起来呢?
想想咱们工作的时候,有些前端同学会觉得,要做到快速发现问题和定位问题非常困难,而且需要大量的日志记录每段代码的异常。虽然大量的记录能帮忙解决问题,但也增加了服务器成本。
我认为,要高效解决问题,就不要只关注日志的成本,相反地,我们应该设计一套更优的字段来解决日志量大和存储量多的问题。
设计的思路,我把它称为“最少字段原则”。
如何定义链路日志数据结构?
做过解决方案设计的同学都知道,一份经过精心设计的数据结构,是需要在写代码前就做好规划的。这样后续的需求迭代也能有更好的扩展性。
这节课,我们首先学习如何用最少字段原则设计基础数据类型的指标。实际上,基础数据指标是全链路日志中的通用数据,也是其他6种指标数据类型必备的字段。
基础数据类型中一共有17个属性字段,又细分为5种类别:基本日志信息、浏览器信息、页面信息、用户信息、业务信息。
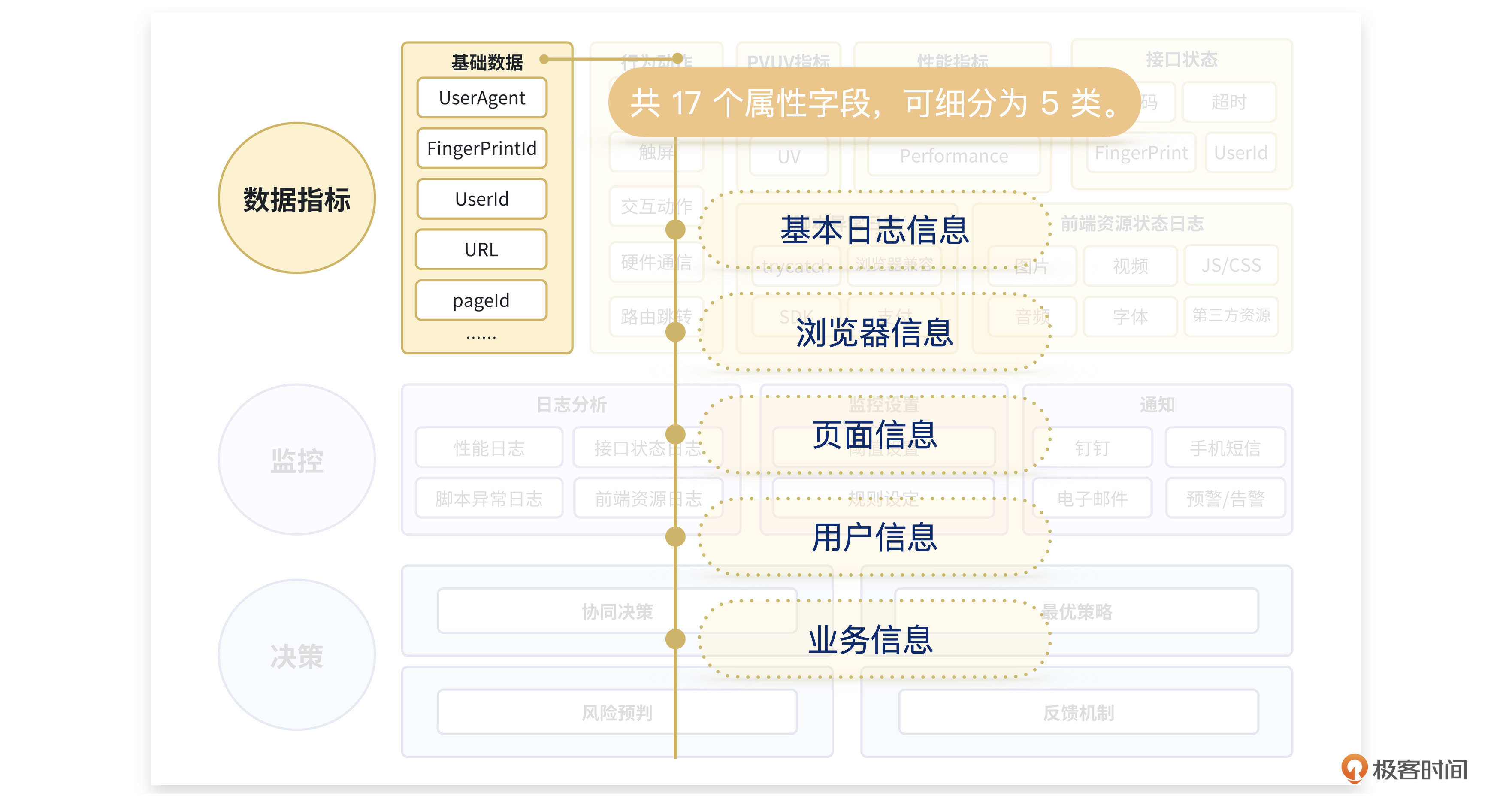
我们一个一个来说。
基本日志信息
先说基本日志数据。顾名思义,这是链路日志的必要数据,包含了唯一键值、时间、类型以及最后更新时间。
为了让你更深入地理解数据结构的定义过程,接下来的数据定义我都会用TypeScript语言设计。
首先,我们定义四个必要的字段,并将类型的名称命名为BaseTrace。
// ./typing.d.ts
// 全链路日志基类
type BaseTrace = {
// 唯一ID,用户侧生成
traceId: string
// 日志类型
type: TraceTypes
// 日志产生时间
createdAt: string
// 日志最后更新时间
updatedAt: string
};
字段并不多,但有两个地方需要注意。
第一,traceId作为链路日志数据的唯一键值,并非由服务端生成,而是在前端生成的。因此,我们很难保证traceId的唯一性。我的解决方案是,不采用自增式,而是使用UUID生成法。
第二,createAt和updateAt字段。这两个字段的含义是日志创建时间和更新时间。从后端角度来看,这两个字段应该从后端生成的,不过在这里同样交给前端生成。因为日志的创建是在前端页面,更新时间会随着用户在页面的操作而实时更新。
这两个时间相关字段不是核心的字段,为什么我要这么改呢?因为从发现问题的角度来看,有一个优点。那就是能够通过两者的时间差,判断用户在时间范围内交互操作的完成度,这也是前端同学判断用户页面停留时间的参考值之一。
另外,有些细心的同学可能发现了,有个type字段,类型是TraceTypes。没错,这个就是日志类型。我把它放在基本日志信息里面,是因为它是必需项,也是判断日志类型的核心字段。
在这里,TraceTypes实际上是个枚举类型,我给它定义了9种日志类型,覆盖了全链路日志的各种场景,你可以参考下面的代码。
// ./typing.d.ts
enum TraceTypes {
// PVUV
PAGE_VIEW = 'PageView',
// Event
EVENT = 'EVENT',
// 性能
PERF = 'Perf',
// 资源
RESOURCE = 'Resource',
// 动作、行为类型
ACTION = 'Action',
// 请求类型
FETCH = 'Fetch',
// 代码错误
CODE_ERROR = 'CodeError',
// 日志
CONSOLE = 'Console',
// 其它
CUSTOMER = 'Customer'
}
其中,最核心的类型是EVENT、PERF、ACTION、FETCH和CODE_ERROR,分别对应的是事件、性能、行为、接口和代码异常五大类。Action类型在这里主要是记录用户的交互行为,作为我们分析用户行为的参考。
浏览器信息
前端同学都知道,我们可以通过window.navigator获取很多浏览器特性和能力,例如设备、版本、环境、内核等等。但在前端全链路中,哪些浏览器特性是能够协助我们快速定位问题的呢?
我的方案是不需要太多,两个足够。分别是浏览器的UserAgent以及预定义的BrowserType枚举类型。
我们先来看下定义浏览器信息的类型有哪些,参考如下代码。
// ./typing.d.ts
enum BrowserType {
// 手机端浏览器
MOBILE = 'mobile',
// PC浏览器
PC = 'pc',
// webview
WEBVIEW = 'webview',
// 小程序
MINI_PROGRAM = 'miniProgram'
}
// 浏览器相关字段基类
type BaseBrowserTrace = {
// 当前浏览器的UserAgent
ua: string
// 浏览器类型
bt: BrowserType
}
为什么在众多浏览器的特性中,我选择了UserAgent呢?
假设啊,有个用户反馈他在前端报名页面反复点击报名按钮都没有响应,而且连续两天都没能成功报名。最后,我们发现问题的根本原因是我们只能支持微信页面打开,但用户不是在微信内打开的页面,所以无法报名。
你看,用户打开页面的载体是不可预估的。而UserAgent能很好地帮助我们快速判断用户的访问场景是浏览器还是微信,我们就可以判断这个交互行为是否在产品的支持范围内。
同理,BrowserType类型也是为了快速判断用户的使用场景,只不过这是由我们提前定义好的。
什么意思呢?举个例子,这次用户反馈的问题依然是报名页面点击报名按钮无反应。因为我们提前定义了一种可能的打开方式“miniProgram”,而这个字段在日志里出现了,我们通过总结发现,BrowserType值为miniProgram的用户都无法正常报名,也就是说,遇到这个问题的用户都是在微信小程序中打开的报名页面。所以我们就能快速判断是微信小程序下的报名页面存在BUG,需要进行修复。
BrowserType类型还有个最大的好处,就是我们能通过它在前端全链路的监控和告警中过滤和筛选我们关注的核心日志。至于怎么做,我会在后面的课程里为你详细讲解。
页面信息
第三个需要关注的类型是页面类型。页面类型记录的是用户访问当前页面的一些基本信息,例如页面URL、标题等。
页面类型属性的其中一个功能是帮助我们快速判断哪些页面出现了严重BUG。同时,在监控中通过URL筛选,也可以判断是通用性问题还是个例问题。
总之,URL和标题能通过过滤或分组,把海量的链路日志进行细化或分组,帮助我们在更细的维度分析问题。
我还是以最小字段为原则去设计属性字段,字段不多,能定位问题即可。
我们用BasePageTrace命名页面类字段,参考下面的代码。
// 页面相关字段基类
type BasePageTrace = {
// 页面ID
pid: string
// 页面标题
title?: string
// 当前页面URL
url: string
}
相信有些同学看到这个页面类的定义后,会有两个疑问。
第一,title属性为什么不是必填项?
其实title属性是否必填并不重要,为什么这么说呢?
因为在实际项目中,有些页面的title是固定的,也有些是千人千面的。如果是第二种,并且title的内容很长,再加上业务相关信息,那收录这个字段确实能快速定位,但从另一个角度来看,这对我们链路日志的存储空间也是一个比较大的挑战。
所以,以最小日志为原则设计字段,title属性就是非必选项。如果在前端项目中确实需要用到title来定位问题,那就把title的内容提供上去就可以了。
第二,我新增了一个pid字段,也就是pageId的简写。这个操作怎么理解呢?
由于现在的前端项目都是基于Vue或React技术栈,最终的效果大部分都是SPA单页面。也就是说,用户使用我们的前端产品页面时,通常都是加载页面一次后就不会加载第二次了,页面的切换都是采用静态路由方式进行的。
而pid的设计方案是从用户输入网址访问页面加载成功后,直到下一次重新刷新页面前,这个时间周期范围内,只生成一次UUID值。
我们试想想,假设用户访问前端页面时,经过多次的交互,产生了多条链路日志,那如果我们要了解这个用户的所有链路日志,该怎么查询呢?pid就是为这种场景来设计的,它能帮助我们快速查询某个用户当前访问一次前端页面时的所有链路日志,从而帮助前端同学判断用户在使用前端页面过程中有没有异常。
用户信息
好,我们再说第四个类型,用户信息。顾名思义,就是记录用户基本信息的字段。同样的,我们在设计的时候也以最小字段原则为依据。因此,像用户ID、用户名、电子邮箱这些信息都在我们的设计范围内。
不过,我们不用userId命名用户ID,采用uid更合适。其余字段命名则参考如下代码。
// 用户相关字段基类
type BaseUserTrace = {
// 指纹ID,fingerprintId
fpId: string
// 用户ID
uid?: string | number
// 用户名称
userName?: string
// 用户邮箱
email?: string
}
同样的道理,uid、userName、email三个字段都是非必填项。因为用户在访问一些非登录态的前端页面时,基本上不会有这三种字段值。
我们看到还有个必填项字段fpId。这个就是指纹ID,设计指纹ID的作用是把同一个用户未登录和已登录两个状态的操作日志关联起来,这样就能快速查询用户登录前后的全链路日志。
关于指纹ID的实现方案,我会在后面的课程为你详细讲解。
业务信息
最后我再来说一个开放类型,业务信息类型。既然是一个开放性业务类型,就没有任何标准答案。但我希望通过抛砖引玉,引导你思考一个问题:如何把这类型日志设计得更好。
在我带过的团队里面,有一段经历特别有趣:只有10人的前端团队,却要负责公司200个以上的前端项目。
一个团队需要维护这么多项目,既有App端内H5,也有基于Electron的PC端,还有纯B端的后台系统。
这时候的考验就是如何分类不同场景的业务。这样,前端全链路监控和告警就能更准确地触达到我们团队,并给出出现问题的关联项目。
所以,在我们实施前端全链路的时候,有个很重要的字段就是appId,它的意义就是区分前端项目。
下面是具体代码设计。这类的类名命名,我是以BaseAppTrace作为类名,同时也以业务基类场景作为通用类的,可以仔细看一下。
enum TraceLevelType {
// 告警级别
error = 'error',
// 预警级别
warn = 'warn',
// 普通日志
info = 'info',
// 调试日志
debug = 'debug'
}
enum TraceClientTypes {
// 安卓
ANDROID_H5 = 'android',
// iOS
IOS_H5 = 'ios',
// PC端
PC_H5 = 'pc',
// 浏览器
BROWSER_H5 = 'browser'
}
// 业务相关字段基类
type BaseAppTrace = {
// 业务ID
appId: string
// 业务名称
appName?: string
// 客户端类型
clientType: TraceClientTypes
// 日志级别
level: TraceLevelType
}
很显然,我设计BaseAppTrace类的字段最多也就4个。你也可以基于此类进行字段扩展,如果确实能帮你快速定位问题,那就去补充。如果只是纯粹用于记录,那就是非必需项。
还是回到所谓的“最少原则”。一条链路日志,不应该被过度设计。业务类字段也是同样的道理。毕竟有前面提到的AppId、fpId、uid、url等关键字段信息,这些基础数据已经足够帮助我们实施前端全链路的全流程监控了。
最后,我们把上述介绍的5种类型组合成新的基础数据类型。参考下面的代码。
好了,到这里,5种数据类型我就都讲完了。我采用定义常量的方式,展示了一份链路日志的标准例子。一定能让你对本节课设计的数据结构有更清晰的了解。
下面是完整代码。
const exampleBaseData: BaseTraceInfo = {
traceId: '0bdf6c8e-25c8-427d-847a-9950318a2e14',
level: TraceLevelType.warn,
type: TraceTypes.ACTION,
ua: 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36',
bt: BrowserType.MOBILE,
fpId: 'c77a37f4',
uid: 1002,
// 例如:极客邦App的命名
appId: 'geekbang-app',
clientType: TraceClientTypes.iOS_H5,
pid: '088c8a92-5a24-4144-9c37-310848c397e1',
url: 'https://time.geekbang.org/',
createdAt: '',
updatedAt: '',
}
5种类型,17个字段,构成了一份全链路日志的基础数据。但要知道,这些只是链路日志的基本字段,还没涉及问题记录、行为记录相关的内容讨论。关于问题类型的数据结构,我会在下一节课给你拆解。
小结
在本节课中,我们学习了如何在前端全链路的实施过程中设计链路日志的基础属性字段。
首先,我们先将众多的基础属性字段分成5大类别,基本日志信息、浏览器信息、页面信息、用户信息、业务信息。
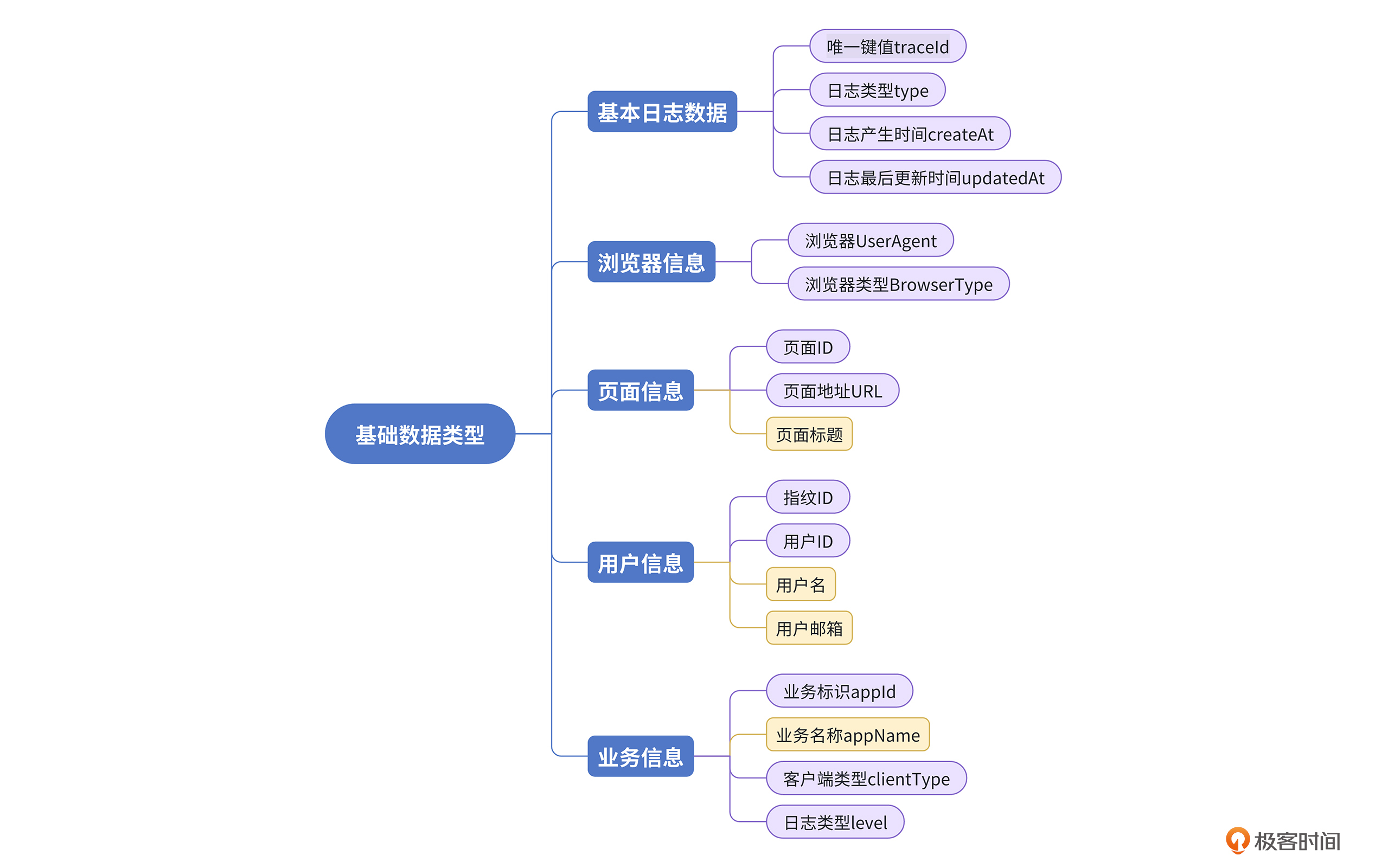
在这5大类里,咱们一共设计了17个属性字段帮助自己分析和解决问题,包括用于判断用户停留时间的createAt和updateAt,用于判断用户场景的ua和bt,用于筛选页面的url,用于关联上下游日志的pid,用于关联同一个用户的fpId,用于区分前端项目的appId等等。
最后划个重点。咱们在设计链路日志字段中一直遵守一个原则:最少日志字段原则。这个原则的核心作用是约束。属性字段只用于协助前端同学快速定位问题,而非进行数据分析。如果一条链路日志的字段设计过多,会严重影响服务器端的存储空间,从而增加研发成本,得不偿失。
下一节课,我们继续对全链路日志剩余的业务字段进行拆解,和你一起设计实现。
思考题
本节课我们重点在探讨如何设计一份尽可能满足项目的全链路日志基础数据,不过目前前端全链路的方案中并没有一套适用所有业务的标准答案。因此,留个思考题给你,思考一下你负责的业务场景中,除了这节课我谈到的17个通用字段,你认为还有哪些通用属性字段可以帮助你快速定位问题?
欢迎你在留言区和我交流。如果觉得有所收获,也可以把课程分享给更多的朋友一起学习。我们下节课见!
- 苏果果 👍(0) 💬(0)
04源码: https://github.com/sankyutang/fontend-trace-geekbang-course/blob/main/trace-sdk/src/typings/common.ts 完整代码入口:https://github.com/sankyutang/fontend-trace-geekbang-course
2024-07-18 - 天择 👍(1) 💬(1)
这套链路日志定义有成熟的框架或标准参考和借鉴吗
2024-04-24 - westfall 👍(0) 💬(1)
唐老师你好,请问生产 traceId 可以确保同一个用户只会生成唯一一个吗?另外这句话没理解:'pid 就是为这种场景来设计的,它能帮助我们快速查询某个用户当前访问一次前端页面时的所有链路日志',为什么是 pid 不是 traceId?
2024-04-30 - hao-kuai 👍(0) 💬(2)
要如何处理前端框架报错的调用栈信息?
2024-04-22