10 数据分析:在“花式对比”中发现玄机
你好,我是刘津。
我们接上一讲内容,继续探讨用户调研中如何进行数据分析。
“比较”胜过千言万语
前面我们说了要强调洞察,也就是发现差异、探索未知。那如何发现差异呢?唯一的办法就是“比较”。如果没有比较,差异就无从谈起。
比如,你想在淘宝上卖一个小巧的录音笔。那么你拍照时,可以在录音笔的旁边再放一个苹果手机或者一张银行卡,这样你的顾客就会清楚地知道这个录音笔到底有多大。一个简单的比较胜过千言万语的描述。

这就解释了为什么在企业中,传统的调研报告内容虽然面面俱到,却难以让人收获意外惊喜,答案就是“缺乏比较”。传统的调研报告只有各种平铺直叙的结论,很难让人有抓到重点、眼前一亮的感觉。
坐标不同,结论不同
那么如何做好数据的对比分析呢?
如果以“铁人三项”数据中的地域数据为例,首先你可以看一下各省/市/城市类型(比如一线/二线/三线……)的占比,然后可以再分别做如下几项对比:
- 和全国或全网平均水平的对比;
- 和同行业平均水平的对比;
- 和主要竞品的对比。
对比分析时,你要注意一点,对比的顺序应该主要按照“从大到小”的原则。为什么呢?当我们想去了解一件未知的事情时,首先需要宏观了解,然后再微观了解。
比如,对一个从未见过树的人形容树,你一定是先说树又高又大,然后再说树上面的枝叶、树纹等其它细节。如果这个顺序颠倒过来,那就似盲人摸象了。
我们来看一个例子。
假设,某借款产品的一线用户占比(一线城市用户占总用户比例)为5%,而一线城市人口占全国比例为4%。这样对比来看的时候,似乎这款产品在一线城市的渗透率还可以。
但如果同行业产品的一线城市用户平均占比达到了10%,该产品比行业平均水平低了5%,这就说明该产品在一线城市其实是有较大的进步空间的。
如果市场规模相似的竞品在一线城市用户占比达到了20%,那就说明该产品在一线城市和它的竞品相比差距很大,你就需要去挖掘差距产生的原因。
如果不方便拿到行业数据或竞品数据,那只看和全国的对比(可参考人口普查结果),也能看出很多问题来。
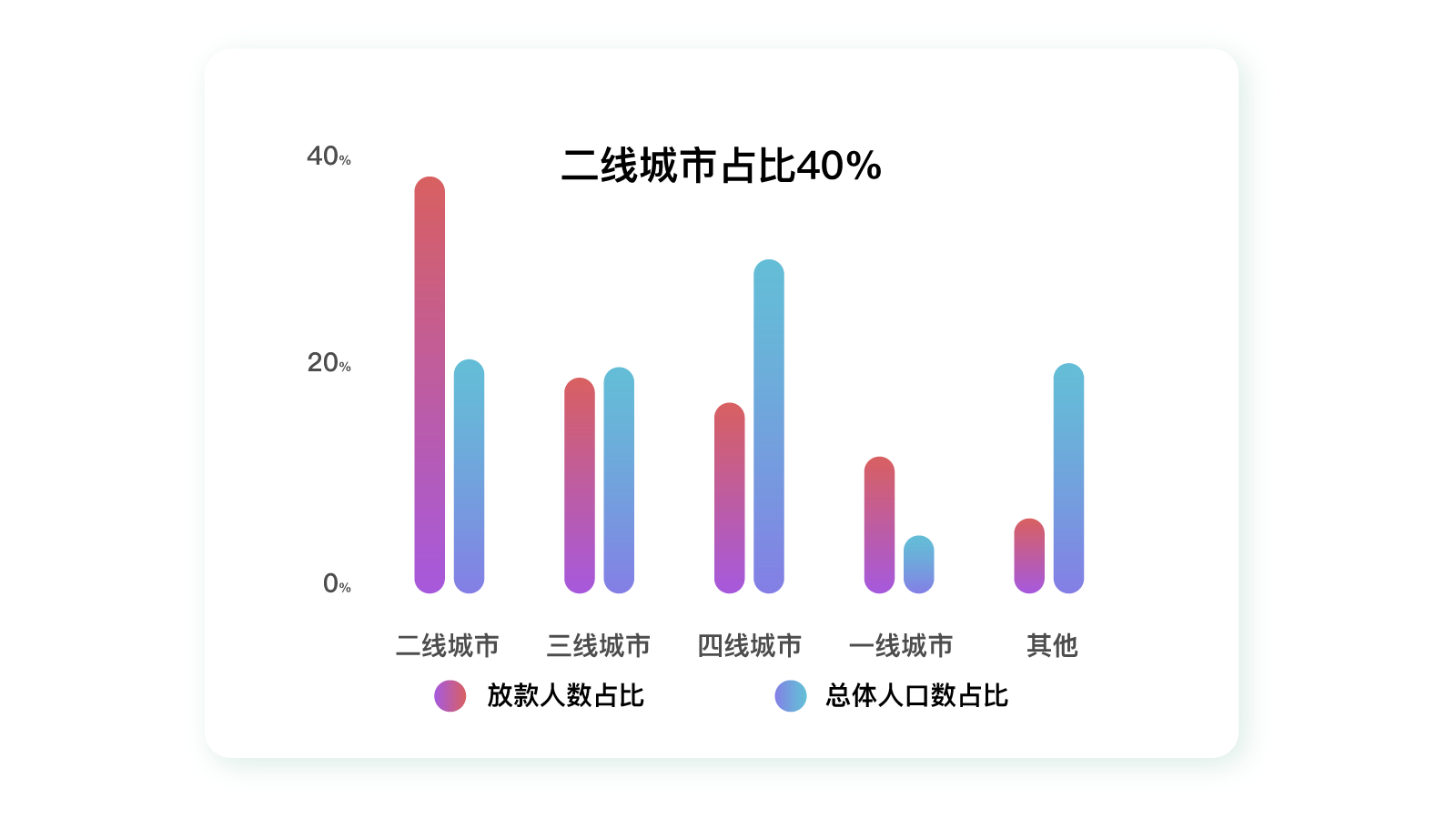
比如上图,如果单独看借款产品的地域数据(当地用户人数占产品总用户人数比例:红色柱状图),我们可以看到该借款产品用户数量在二线城市占比最高,再往后是三线城市、四线城市,一线城市排的很靠后。
这样看来好像该产品适合做人群下沉,去更多小城市发展。但事实真的是这样吗?
如果你结合了全国的人口数据(当地人口占全国人口比例:蓝色柱状图)再进行分析,你会发现一线城市和二线城市的相对比例远高于三线、四线城市。也就是说,该借款产品明显更受一二线城市用户的喜爱。
而三四线城市用户绝对占比之所以比一线城市多,只是因为三四线城市的人口基数大而已,并不能证明产品更适合他们。
这个例子足以说明,如果不加以对比,光看表面数据很容易得出错误的结论。这也是传统调研报告的结果很难被采用的原因。
打破沙锅探究到底
当然仅仅通过对比来解读数据还是不够,这只是让我们能够明白表象,接下来还需要明白为什么会呈现出这种表象,也就是要探寻本质,这样数据才有价值。
所以,数据的使用过程,是先从收集数据开始,然后进行对比,在对比中解读,最后探寻本质。现在很多公司尚未迈出第一步,还有大量的数据分析师和用户研究员停留在第一步。但其实最有价值的是后面两步。
如何通过数据提供的表象探寻本质呢?接着前面的例子来说:在对比中我们发现这个借款产品的地域分布和全国平均地域分布有较大差异,为什么会这样呢?这就是一个很好的切入点,可以继续深挖下去。记住,只要在对比中出现重大差异,都值得我们去研究,顺藤摸瓜很可能就会得出惊人的洞察。
想一下,“地域”这个字段还有什么相关属性值得进一步分析呢?如果你没有头绪,可以先从如何界定地域这个角度来看。
比如,我们现在判断地域,是看用户目前在哪个城市,但是其实他可能并不是当地人。所以每个用户其实可能出现两个地域:一个是出生地,一个是现在生活的地方。
根据这个特殊性,我们可以分析一下不同类型的城市中本地人和非本地人口的占比。
在这里,我们又可以发现特殊的差异:一二线城市的非本地人口占比远高于本地人口占比。而越是外地人占比多的地方,用户就越偏爱这个借款产品。
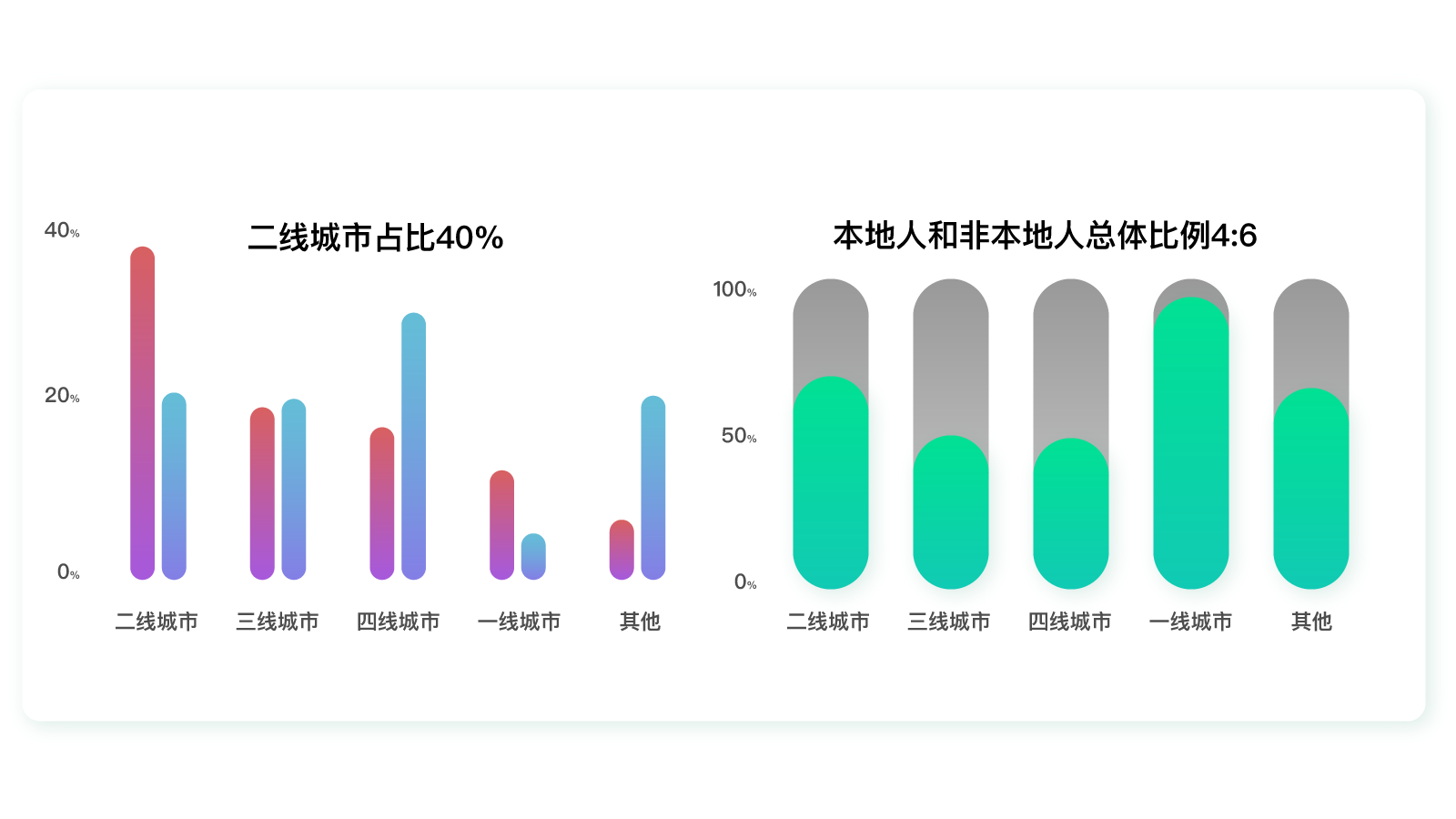
这是为什么呢?通过后面的用户访谈,我们发现外地人生活压力大,需要买房、贷款、还有教育、日常开支等。而本地人往往都有房子住,生活压力小很多,自然就没有太多贷款需求。所以,对于这个借款产品来说,未来考虑“人群上移”可能比“人群下沉”更合适。
不知道你有没有发现,分析到这里,其实又出现了一个新的问题:对于一二线城市的用户来说,可以接触到的借款产品非常多,那这个产品的核心优势是什么呢?这个确实难以通过数据呈现出来,所以我们后续还需要通过用户访谈来洞察。
分析完地域,我们可以以此类推,分别分析“性别”“年龄”数据。接下来,我们还可以把铁人三项数据进行交叉对比分析。任意选择两个字段,比如“年龄”“性别”,就可以看到不同年龄段性别比例的差异。如果在两个不同的年龄段,性别比例差异过大,那么就值得深挖一下了。
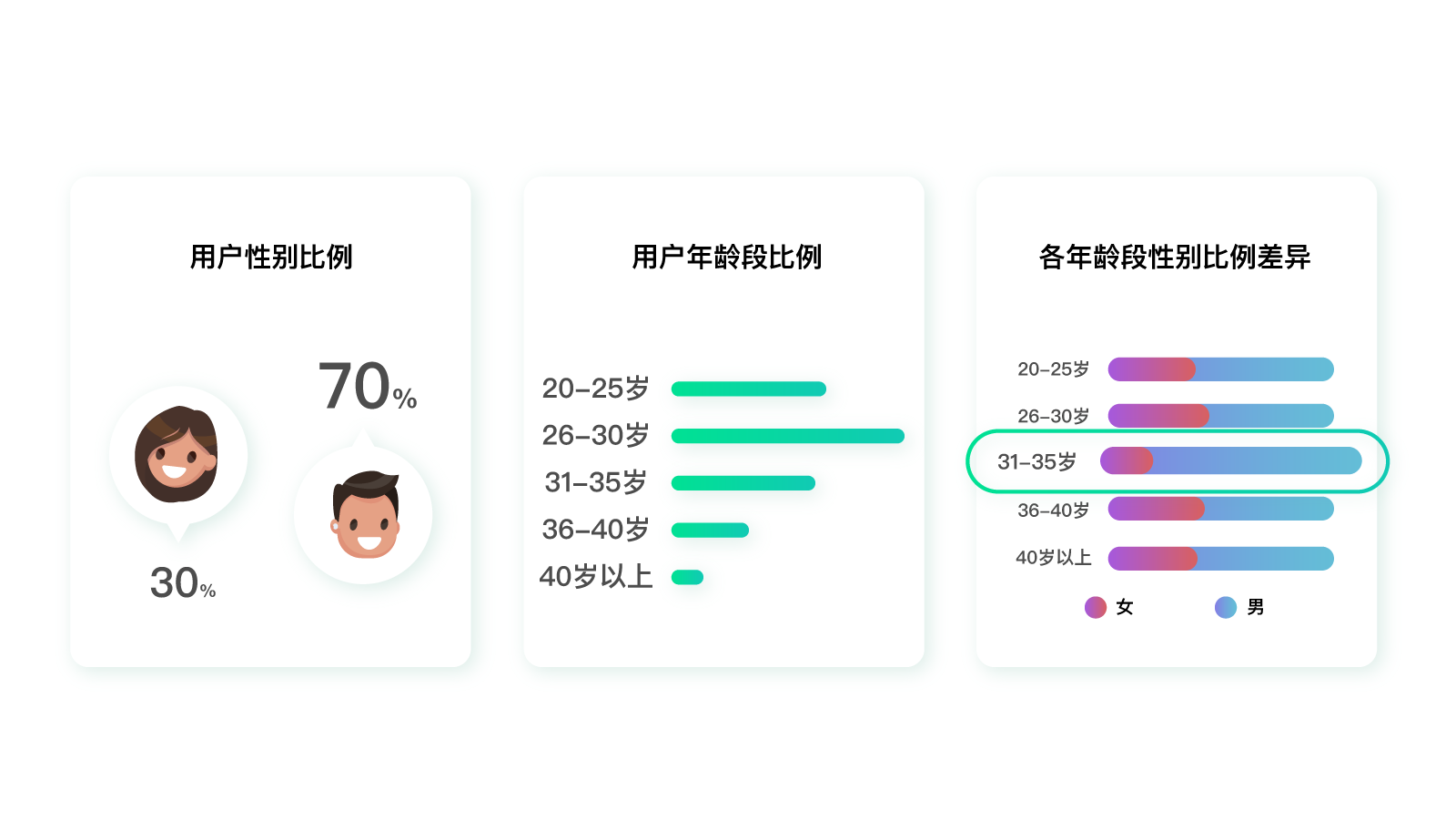
比如上图,如果一款产品的用户性别比例是30%女性、70%男性。
那么正常情况下,该产品在任何一个年龄段的性别比例数值都应该是相近的。如果在某一个年龄段,比如31~35岁,突然出现了女性10%,男性90%的情况,那么这个地方就值得去探究了。
怎么样?整个过程是不是就像探案一样?任何与常理违背、或者和平均水平不一致的地方,可能都是金矿。
我再带着你把整个“探案”的过程回顾一遍:
- 调取产品“性别”“年龄”“地域”数据。
- 在对比中发现“性别”“地域”与全国平均水平差异较大。
- 增加地域字段进一步交叉分析,发现和外地人占比多少有关。
- 通过常识或后期调研判断出,本地人和外地人生活方式不同导致对产品需求不同,外地人需求更大。
- “性别”“年龄”“地域”间可再交叉分析,进一步探索差异(可省略)……
以上这些思路只是参考,欢迎你在实际工作中多多发散,发掘出更多有意思的“花式对比”和“探案”心得。
用户调研知识地图
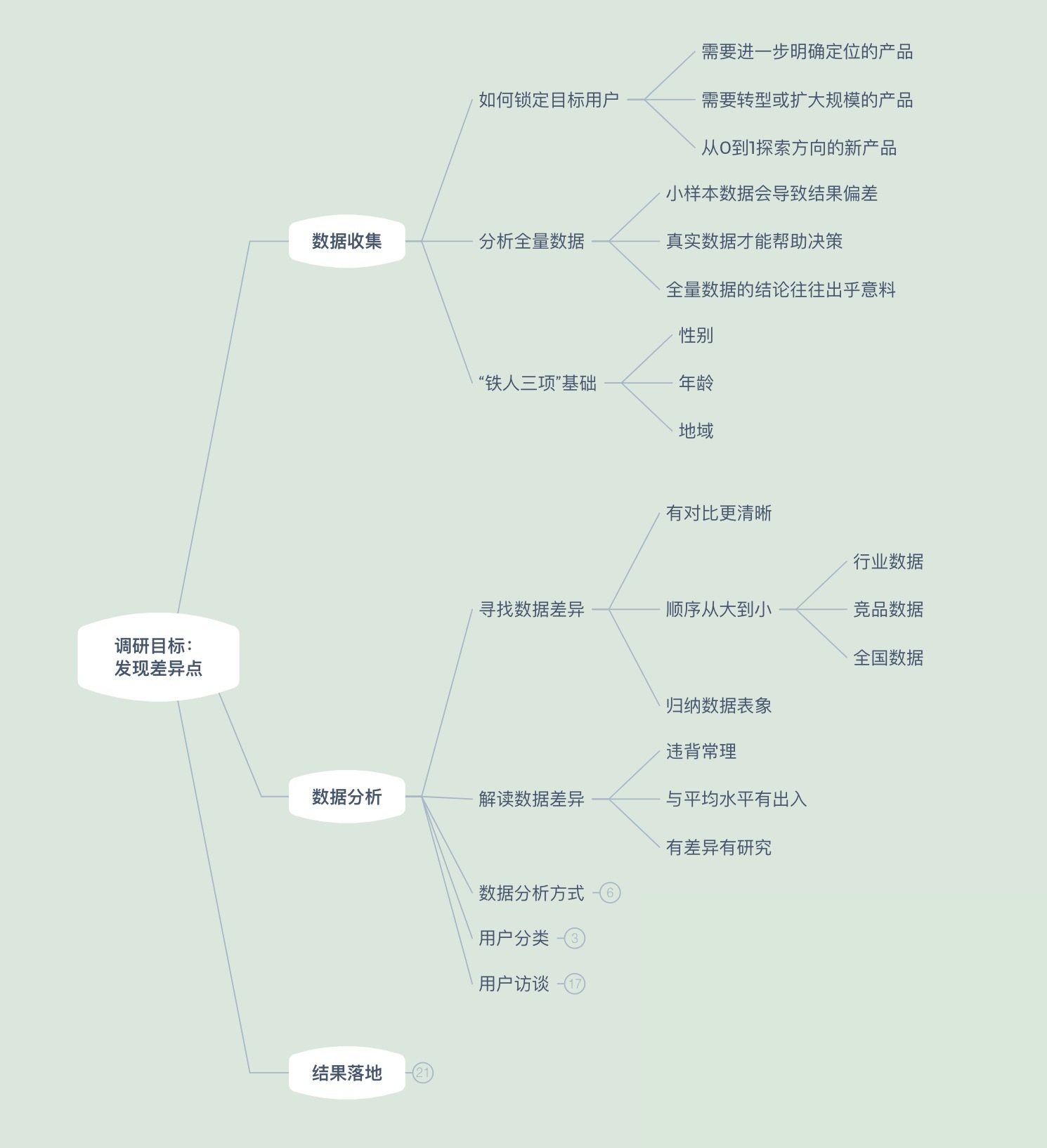
今天我们的用户调研知识地图推进到了数据分析的部分。希望你可以在知识地图中,根据自己的见解和实际情况进行补充。

思考题
尝试分析一下目前你负责的产品的用户数据,试着通过对比来解读,看看有没有不一样的发现?
欢迎把你的思考和疑问通过留言分享出来,与我和其他同学一起讨论。
如果你觉得有所收获,也欢迎把文章分享给你的朋友。
- nata 👍(9) 💬(1)
上面文章提到:宜人贷的阶段是“有用户但不知道产品定位”,因此要对现有用户做一个数据分析,明确产品定位和增长方向。 这里提到:通过城市对比,发现宜人贷明显受到2/3线城市,非本地人的偏爱,因为房贷压力下,需要借贷来投资或消费。结论就跳到了“未来考虑“人群上移”可能比“人群下沉”更合适。 中间似乎缺了一环:该产品在2/3线城市的占有率。因为逻辑应该是:如果我在2/3线城市的占有率很高了,市场几乎饱和了,那我就要寻找其他增长渠道了。 也还有一个假设:3/4线城市人口的经济压力不大,因为房贷还是较低,无需借贷。 一要看现有用户使用率,二要看未来目标群的需求度,三要看增长天花板。
2019-06-23 - J.M.Liu 👍(44) 💬(3)
抖个机灵:五一期间,本专栏留言量明显下降了,而技术类的专栏留言量基本保持不变。这说明,程序员比较宅,个人生活空间很小,即使放假他们也喜欢专研技术。而产品们的个人生活则要丰富多彩得多,放假都去玩了。哈哈
2019-05-05 - 完美世界 👍(5) 💬(0)
程序员打卡。。。干货啊
2019-05-07 - 程序员小跃 👍(3) 💬(0)
原来我已经无形之中在做这个事情了。我会时不时地去看下公众号的后台数据,看下地域、性别分布;但是还没开始做进一步的分析,老师给了我一个提醒和思路,要行动起来,去实践
2019-05-06 - 黄杲 👍(2) 💬(2)
刘津老师,关于用户调研我一直有个疑问没有想明白,问题是:如何调研没有激活的用户是什么原因流失的? 这里的疑惑是:这些用户已经离开产品,显然产品内的用户调研这时候已经来不及,他们又没有联系方式,我们怎么才可能触达这些用户呢?这种情况下如果只通过行为漏斗对比差异性,只能知道是哪里流失的,而不知道为什么流失。 非常感谢!
2019-05-05 - 深白浅黑 👍(1) 💬(0)
了解了如何通过洞察寻求差异点的具体方法——对比。个人认为单看表面数据容易出现错误这个观点再本文中不太合适,改为使用单一数据指标作为决策依据容易出现错误,更为恰当。 通过举例,了解到可对比的元素或者标签很多,组合的种类繁杂,可以分为两类,一类是基础标签,一类是扩展标签,用程序员的话说,就是封装变化。更多地对比要结合实际目标从扩展标签中有侧重的选择,同时也要做到多元化,避免使用单一标签造成决策失误。这个需要经验积累了……
2019-08-21 - ywqqjw 👍(1) 💬(0)
满满的干货,作为程序员假期出去玩了,属于exception case
2019-05-08 - 李沛欣 👍(1) 💬(0)
印象深刻的三点: 数据发现要从大到小, 数据差异凸显可能存在的机会和问题, 性别年龄地域是基本法。
2019-05-08 - eds 👍(1) 💬(0)
打卡
2019-05-03 - 嘟嘟酱Sunny 👍(0) 💬(0)
可是有没有可能三四线城市人口更多,导致它的比例整体覆盖没一线城市快,导致其整体占有率相对没一二线城市多,这其中的一个评判临界点要怎么定才合适呢?我觉得单纯通过一个绝对值相差大的相对比例来判断出产品更受一二线城市人口喜爱有失偏颇
2024-12-29 - ifelse 👍(0) 💬(0)
学习打卡
2024-12-19 - Geek_7ef8cd 👍(0) 💬(0)
在刚开始入行增长就遇到了刘津老师的课程,非常幸运!这节课不仅纠正了之前的一些错误的数据分析思维,还为我目前的增长工作提供了一些宏观思路。之前错误的数据分析思路是这样的,实习时候参与一款K12学习工具的产品设计,当时组内的用户画像分析文档就只是展示了用户画像的绝对数据而没有展示相对数据,也就是只分析了当前app的三四线城市占比居多,小高用户居多,因此产品更受到这部分人喜爱,产品要服务且要增长的主要就是这部分人群,现在看来这是非常错误的思想,没有关照到总体样本的年龄和地域分布。给我当前增长工作的启发是,要先找到并分析产品当前的已有用户数据,然后找到全国总体样本数据,然后在产品的已有用户和总体样本做对比分析,找到当下要增长的目标群体画像。 可是有个疑问是,老师是怎么获得的这么精细的总体样本数据啊,我看全国人口普查的数据划分的都很粗,15岁以下,15到65岁,65岁以上这样,去哪里找比较细的数据呢,有知道的朋友可以分享一下吗~
2021-10-11 - 老炎 👍(0) 💬(0)
根据百度指数的数据,公司注册多发生在20~29岁,公司注销多发生在30~39岁,公司变更多发生在40~49岁,可见年轻人的创业热情很高,其中大部分会在几年后失败,而中年人恰恰才是把公司带向稳定发展的主力。
2021-07-15 - Geek_8hym02 👍(0) 💬(0)
打卡,讲的不错
2019-06-13 - 张洪磊 👍(0) 💬(0)
老师,如果产品面向C端的,从地域,年龄分析对比是很有意义的,但作为B端的用户,可能就适用了,对于B端产品,可否重点介绍一下呢
2019-05-13