《我们如何看见,又如何思考》 潘旭解读
《我们如何看见,又如何思考》| 潘旭解读
关于作者
理查德·马斯兰,曾任哈佛大学医学院的神经生物学和眼科教授。在四十多年的职业生涯中,他一直致力于研究人眼和大脑的工作机制,确切地说,是视网膜神经元和大脑的神经网络。
关于本书
书中,马斯兰教授为我们讲述了很多针对人类视觉研究的有趣发现,比如你是怎么在人群中快速认出那个熟人的?人眼是怎么和大脑说悄悄话的?这些内容能够帮助我们对当下的对象识别问题,有更透彻的理解。
核心内容
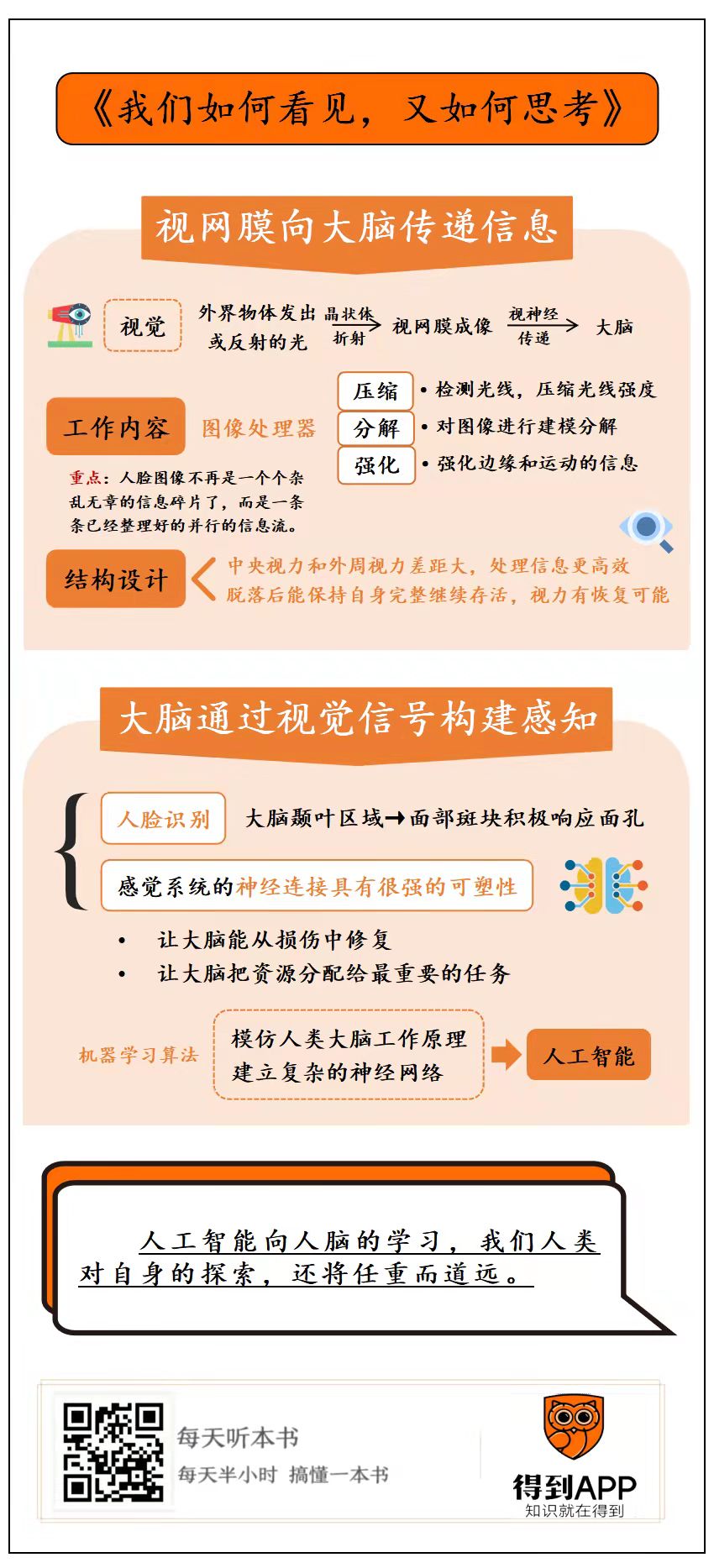
一、我们的视网膜是如何工作的?眼睛是怎么在看到人脸之后,向大脑传递信息的?
二、大脑又是如何响应来构建感知的?
你好,欢迎每天听本书,我是潘旭。今天为你解读的书,名字有点长,叫《我们如何看见,又如何思考》,这是一本讲视觉研究的科普书。
这本书一开篇就提出了一个非常有意思的问题:你是怎么能够在几百毫秒内,就从人群中认出熟人的?
乍一听,你可能会有些困惑,因为我认得他啊,这也不费劲。对,问题就出在你是怎么一眼就认出他的?认出这个动作的学名叫,对象识别。光完成这样一个动作,就涉及到转瞬之间,眼睛和大脑大量的复杂运算。
首先你肯定得眼尖,对吧?得在短时间内,把更多的视觉资源调配到人海中,那个熟悉的小脸上。再比如,你得记性好吧?现在你手上可没有他的照片能立马做个比对。所以你能认出来,是不是最起码关于他的记忆,你是存储在大脑中的,能马上能调用出来?
不过,这些还是最基本的操作。更复杂的是,实际上,你每次看到这个人,他的样子落在你的视网膜上都不一样。什么意思呢?你细想一下,看到他的脸,单单一张脸的表情可能就有无数种;再加上脸的朝向,正面侧面,抬头低头;脸距离你的位置,呈现出的大小;脸在不同光线下的阴影面积等等,这些因素每次都不一样。可以说,一张脸的数学变换几乎是无限的。
那么,回到前面的问题,你是怎么在几百毫秒内认出那个人的呢?现在,是不是确实挺奇怪的?我们的眼睛到底是怎么和大脑对话的呢?
这是科学界目前最重要谜团之一,也是我们今天要说的这本书,探讨的核心问题。要知道,对象识别问题,这个我们习以为常的基本操作,放在人工智能领域,足足花了50多年才有所进展。如果你关注新闻,说不定还记得前几年,计算机甚至闹出了把黑人识别成大猩猩的尴尬场面。可见,要想完成准确的对象识别,这个过程是非常困难的。
本书作者理查德·马斯兰,曾任哈佛大学医学院的神经生物学和眼科教授。在四十多年的职业生涯中,他一直致力于研究人眼和大脑的工作机制,确切说,是视网膜神经元和大脑的神经网络。
在这本书中,马斯兰教授为我们讲述了很多针对人类视觉研究的有趣发现。这些发现,将帮助我们对当下热门的机器学习和人工智能的发展,有更加透彻的理解。可以说,长期以来,计算机科学领域中的一个重要目标,也是要让计算机能够更加接近人脑。
接下来,顺着马斯兰教授的研究进展,我们今天的解读将分为两个部分。
第一部分,我们先把注意力放在认识自己的眼睛上,我们得弄清楚视网膜是如何工作的,它是怎么看到人脸之后,向大脑传递信息的?第二部分我们再深入大脑内部,看看大脑是如何响应的,科学界有哪些新的研究发现?好,话不多说,我们赶紧开启这趟认识自我的科学之旅吧。
首先,我们先来说说视网膜。
提到视网膜,我们大多数人对它的认识,可能还停留在高中生物课本上。
视网膜是一层透光的薄膜。我们的眼睛之所以能看到某个物体,就是外界物体的反射光,通过晶状体折射,最终落在视网膜上,形成一个物像。然后这些图像信息通过视神经传给大脑,这样人就产生了视觉。
所以,通俗地说,视网膜的作用有点像是一层幕布,这是我们对视网膜的初级认知。但是科学家研究发现,事情还真没这么简单。视网膜所发挥的实际作用,远远超出了我们的想象。与其说视网膜像一层幕布,倒不如说它更像是一个早期的图像处理器。
什么意思呢?你肯定听过一个词叫“眼见为实”,但实际上,眼见并不为实,我们看到的世界并不是真实的世界。因为视网膜早就已经对真实世界的信息进行了一系列加工处理。最终目的呢,就是要从一大堆杂乱无章的信息中,识别出主要矛盾,给到大脑最显著的视觉信号,其余无关紧要的,所谓“背景噪声”,就被忽略掉了。
当然,这种简化的经济型措施,并不是生物演化在自娱自乐,而是所有感知系统最基本的原则之一,包括听觉、触觉和味觉等等。不过,视觉一般是我们接收信息的主要来源,信息量更大,也更复杂,所以要想完成这些工作,对视网膜的要求也就更高。说白了,它不仅得工作效率高,还得会选择,会思考,它得非常聪明才行。
那视网膜到底有多聪明呢?它又是如何工作的?这其中的科学原理非常复杂,书中列举了大量科学概念和术语。为了便于你理解和记忆,我把视网膜的主要工作内容简单总结成了三个关键词,它们分别是:压缩、分解和强化,我们一个个来解释。
先来说什么是压缩。我们比较熟悉的内容是,视网膜的首要任务是检测光线。不同强度的光线从各个角度进入眼睛之后,视网膜上和光线有关的光敏细胞就会开始工作,然后再把这些光学信息转换成其他细胞能够接收工作内容。不过,我们可能不知道的是,在这个过程中,视网膜还需要对不同强度,差异巨大的光线变化做进一步的压缩,以确保它们在一个合适的范围内。
那进行这一步的意义是什么呢?
我简单说个细节你就明白了。想象一下,如果你从一个黑暗的房间走到明亮的客厅,肯定会觉得光线有些刺眼,我们每天早上醒来大多都是这样的状态。不过这还是光线已经经过视网膜压缩处理之后的结果。一旦没有这个步骤,我们眼前就可能是一片光斑,眼花缭乱,或者是陷入黑暗中,彻底看不见任何东西,直到视网膜重新组织起一个合适的亮度范围,我们才能真正看得清东西。
为什么会出现这种情况呢?
简单来说,因为对黑暗敏感和对亮光敏感的不同细胞,它们的信息输出大小相差1000倍,而这样的数值差距,是单个神经元、大脑甚至计算机都无法处理的。所以,视网膜必须得压缩光线变化的范围,在任何给定的环境照明下,让输出的最大光亮强度也只有最小强度的10倍左右,而不是1000倍。
虽然压缩工作的难度很高,但是视网膜必须非常聪明地限定一个合适的亮度范围,以便我们能够在不同光线的环境中自如切换。
不过,相比于后面的工作,这还不算什么。因为除了压缩光线强度的工作之外,“分解”才是视网膜的重头戏。分解工作的精巧设计,真正体现了视网膜集大成的智慧所在。
我们还是拿前面提到的,人脸图像来举个例子。前面说过,如果大老远就要你快速认出那个熟人,实际上是难度极高的。人脸图像每一次都在变,就像你根本无法拍出两张一模一样的照片。
所以,想要解决这么复杂的问题,视网膜必须要会“分解”。把一个复杂难题分解成一个个最简单的部分,再分别针对每个单独的部分去处理,就是我们能立马上手的最快方式。
而视网膜的智慧就在于,它还不是简单的拆分图像,而是对图像进行建模分解。什么意思呢?
简单来说,视网膜的工作并不是机械地把人脸图像,拆分成无数个碎片,然后再像拼拼图一样把它们拼合在一起。视网膜做的工作高级多了,它会条理清晰地把人脸图像,按照不同特征点进行分类,比如这个图像我需要花多长时间识别,它是动态还是静态的、它的边缘、颜色、方向、运动等各个维度分别是什么样。视网膜会根据这些维度进行分类整理,这就是建模。然后再形成几十条并行的信息流,清清楚楚地把这些整理过的内容传输到下一步。
这样一来,人脸图像就不再是一个个杂乱无章的信息碎片了,而是一条条已经整理好的,分门别类并行的信息流。一旦发生任何微小的变化,视网膜也都能有所识别。
这里多插一句,能够完成这么复杂工作的主角,叫神经节细胞,我们有必要认识一下。视网膜中的神经节细胞离大脑最近,承担的工作任务也最重。神经节细胞数量多达100万个,到目前为止,科学家已经数出了30多种不同的类型,不同类型分别负责响应不同的特征,从而确保能捕捉到图像的微小变化,最大限度地在信息传输过程中保留多样性。
那多样性是保留了,怎么确保高效呢?毕竟我们可是能在几百毫秒内,就分辨出来熟人。这就要说到视网膜的第三个重要工作了——强化。强化很好理解,相当于重要的事我们得多强调几遍,告诉大脑它们有多重要。到这一步,从大脑的角度看,图像已经被改善了,因为真实的世界已经被视网膜有所取舍地进行选择了,所以眼见也开始不为实了。
那么,视网膜会选择哪些信息进行强化呢?
事实上,长期以来,大自然已经了解到,有关边缘和运动的信息很重要。科学家们观察到,这部分的信息强化在视网膜的工作过程中也充分体现出来。
首先是边缘。你想,大自然的视觉元素都是有结构,有线条和角度的。边缘意味着,你能在一个毫无规律,什么都不知道的图像中,了解到:哦,信息在这个地方,发生了变化。所以,边缘是信息量最密集的地方了。而视网膜要做的事就是,抓住一条线两边,变化处的结构,然后再对此进行强化,增强明暗边界,这个过程的术语叫“侧向抑制”。
当我们的视觉系统看到由亮到暗的转变,侧向抑制效应会增强这个信号,让我们更明显地感知对比度。比如当一条亮带和一条暗带相邻时,我们经常会觉得暗带的边缘好像比暗的区域更暗一点儿,亮带的边缘比这个亮的区域更亮一点儿,其实这就是视网膜在跟我们强调边缘信息。我们在手机和电脑用软件修图的时候,经常有个操作叫“增强对比”或者“锐化边缘”,你打开这个选项之后,图片看上去就会更清晰,说的也是这个道理。
为了更加高效,视网膜得从视觉世界中选取最显著的特征传输给大脑,所以这个时候视网膜就必须要重视边缘的作用。
除了强化边缘信息之外,运动的信息同样值得关注。视网膜对运动的强化很好理解,一个静止的物体可能不会对我们造成伤害,但是如果是一个突如其来的东西,我们的大脑必须快速做出反应,而且是越快越好,因此,这就需要视网膜对运动的信息进行检测强化。这就是要重视运动信息的作用。
总之,通过我们前面说的,压缩、分解和强化这些工作内容,你肯定也意识到,视网膜可不仅仅是一层会透光的膜这么简单,而是一个充满智慧的图像处理器。它的主要工作也不是拼拼图这么容易,而是主次分明地整理好一条条并行的信息流,传输给大脑,减轻后续工作的压力。其实在计算机处理信息的过程中,策略也是一样。
你看,这么说来,视网膜是不是比我们想象中的要聪明得多。当然,为了达成这么复杂的工作,视网膜在自身结构上,还有更多高级的设计,这里我们简单说两个。
比如我们可能都有这种模糊的感受,那就是眼睛中间的视力比外周要好,但我们很少会察觉到,两者差距到底有多大。科学家们发现,实际上,我们的中央视觉敏锐,而中央以外,可以说我们基本上是看不见的,这是因为中央区域神经节细胞多而集中,越往边缘,就越稀疏。
那有人就提出,为什么自然进化不能让人类拥有更多的神经节细胞呢?毕竟我们眼睛的四周还有很多表面积啊,视力肯定是越清晰越好啊,这样也能更快的分辨危险,做出反应嘛。
话虽然是这么说,但是,生物演化面临的问题从来不是单一维度的问题,而是相互矛盾,让人两难的问题。在这个过程中,你会发现,视网膜的结构设计体现了一种平衡的艺术。
一方面,当前安排最大的好处就是高效。想要拥有更多的神经节细胞,成本是很高的。假如视网膜中央和四周,每个点的神经节细胞密度都一样高,那么它们汇聚在一起形成的视神经,就会像一根橡胶水管那么粗,而我们现在视神经的直径通常只有4毫米。你看,不说别的,像水管一眼粗的视神经,可能会让我们的眼球连转都转不了。
另一方面,外周视力差也有它的用处,它不仅对变化的东西很敏感,而且我们还能用外周视觉来进行导航,粗略地避开一些障碍物,这样大脑处理的信息也会较少。事实上,一些智能武器,比如视觉制导的炮弹就使用了和人类视觉类似的策略,它们会先用粗糙的视觉定位重点区域,如果这个区域有动静,才会在该区域放大像素密度处理更多细节。这样做的目的和人脑一样,用尽可能少的计算资源来处理次要信息。所以,视网膜的中央视力和外周视力差距很大,这样的安排是有道理的。
不过,除了这个结构上精心排布,你肯定无法想象,视网膜本身就是一个很神奇的存在,因为它脱落后还能保持自身的完整,而且可以继续存活。
科学家们发现,其实视网膜、脊髓和大脑一样都属于中枢神经系统,这三处结构具有相同的胚胎起源、相同类型的神经元和支持细胞。这也是为什么,我们可能听说过,有人在受到运动创伤后会出现视网膜脱落的情况,但是只要及时进行手术,大部分视力还是可以挽回的。所以,视网膜其实比我们想象的,要强大得多,它是一个更独立的存在。
好,到这,我们对视网膜已经有了比较清晰的认识。接下来,第二部分,我们要准备深入大脑内部,看看科学界目前有哪些研究进展,大脑又是如何通过视觉信号来构建感知的。
其实进入大脑,我们的科学知识就显得很匮乏了。作者在书中提到,科学家通过观察视网膜神经节细胞的活动,已经基本弄清楚,视网膜的输出主要通往大脑的视觉皮质。但是对大脑视觉皮质的研究工作,我们就像是一群航行在迷雾中的航海者,凭借着地图上的少数标记,向着更多的未知进发。确实,大脑还有很多谜团亟待解决。
所以今天的解读,我们针对前面提出来的那个对象识别问题,为你结合计算机领域的发展,介绍一些关于大脑处理视觉信息的研究成果。
科学家们第一个有趣的发现是,我们的大脑对某些具体的视觉对象,响应地会更活跃,其中比较特别的视觉对象就是“人脸”。可以说,大脑对识别人脸,有一套特殊的功夫。
科学家们通过核磁共振成像观察到,当人和猴子看到一张脸的时候,在大脑颞叶中,也就是在我们耳朵上方的这个位置,就会出现6个特定的小斑块,斑是斑点的斑。
通俗地说,这些小斑块有点像是专门为识别脸部准备的细胞。有一些斑块功能比较局限,只能响应脸的特定朝向,比如当我坐着的时候,对面这个人的脸,方向是朝着我左边肩膀看的时候,这个角度它才会响应。另一些斑块则更高级,无论这张脸朝着哪个角度,它都可以识别出来。但是不管怎样,科学家们发现,这6个斑块可以作为一个系统来协同工作。
那它们是如何协同工作的呢?我们都知道一张脸的样子,但是当我们说一个细胞“识别”一张脸,这到底意味着什么?
有人就推测,这些细胞可能会各司其职。比如说这个细胞负责识别眼睛,那个负责识别鼻子,另外一个就负责识别分别嘴巴。
为了弄清楚这些问题,科学家们按照视觉信息的拆分机制,把一张脸拆分成了不同的元素。比如两只眼睛,就是两条横线,一个鼻子,一条竖线,最下方还有一张椭圆形的嘴等等,这里我也在文稿中贴了一张图。科学家们在实验过程中,想要通过增加或减少这些面部特征,来观察这些细胞的工作原理。

中间的实验过程有些复杂,这里就不多说了,我们直接说结果。首先,这些细胞对不同的脸部组合特征,都有一定的响应,它们确实对“脸”感兴趣,通过增加或减少一些面部特征,细胞的反应强度也有所不同。
不过,最有意思的发现是,这些细胞可不是像之前人们推测的那样,各管各的,有些专门识别眼睛,有些专门识别鼻子。它们的工作方式非常高级,它们会测量一堆面部参数,然后联合分析这些参数,来确定某个对象是否是一张脸。
什么意思呢?比如科学家观察到,有些细胞对一张脸的长宽比敏感,另一些细胞则对眼睛之间的距离敏感,还有一些对眼睛的位置参数更感兴趣。换句话说,如果我们单独来看每一个参数,没有一个参数是很直白地告诉这些细胞,脸的存在,但是如果用某种方式把这些参数组合在一起,细胞就能做出判断,眼前的对象是否是一张脸。好,这就是第一个有趣的研究成果。你看,这些细胞的工作机制是不是和我们想的还真的不太一样。
科学家们发现的,第二个重要的研究成果是,感觉系统的神经连接具有很强的可塑性。什么是可塑性呢?别急,我们还是顺着前面的那个对人脸的研究,往下深入。
虽然科学家们发现了细胞识别面部的工作方式,但是他们更想了解的是,为什么偏偏这些斑块中的细胞会选择性地对面部敏感呢?我们假设,如果一个人,他的视觉信息中,从来没有接触过和脸有关的任何参数呢?这些细胞还会对面部特征敏感吗?
科学家拿猴子做了实验。他们饲养了一些猴子,从小就没见过任何关于脸的参数,不仅仅是没见过人的脸,也包括它们的同类猴子的脸。每次实验人员在和这些猴子的接触过程中,他们都会戴上电焊工的面罩,把自己的脸捂得严严实实。
除了看不到脸,这些猴子在一个完全正常的视觉世界中长大:它们可以看到笼子和周围房间中的一切;它们可以看到实验人员的身体、手臂和脚;可以看到喂奶的奶瓶,可以听到猴群发出的正常声音,也能够与同伴开心地交流。它们唯一被剥夺的是对面部的视觉体验。那如果在这样的环境中长大,它们的大脑中,还会存在特定的面部斑块吗?
科学家们通过扫描这些猴子的大脑就发现,当看到人脸或同伴的脸,它们脑中并没有亮起来的斑块。不过,值得注意的是,原本在面部斑块会出现的大脑区域,当这些猴子看到关于手的图像之后,这些细胞就做出了一系列的响应。说明我们原先判断的,那些对面部敏感的细胞,如果从小就接触不到关于脸的图像之后,它们就会对手更加敏感。
这是什么原因呢?科学家们发现,原来在正常的社交环境中,对于灵长类动物来说,最重要的视觉对象就是脸。不管是人类的脸还是猴子的脸,它们会传递一些愤怒、恐惧、敌对、爱以及所有和生存繁衍有关的情感信息。但是如果看不到脸,怎么办呢?显然,环境中第二重要的特征就是手,包括猴子自己的手,以及培育和喂养它们的实验人员的手。因此,原本我们可能判断是面部斑块的脑区,就变成了“手部斑块”。
不过,更有意思的是,在猴子被允许,可以看到实验人员或者其他猴子的脸之后,大约过了6个月,科学家们再次观察到,手部斑块中的细胞又逐渐恢复为对脸敏感。显然,面部传达的信息如此重要,以至于它们重新夺回了手的图像所占据的大脑区域,而这个过程就是一种感知学习的过程。
可以说,我们的感觉系统一直在通过调整自身去适应自然界的统计规律,而这个规律指的就是在视觉输入中对于我们来说最重要的特征。当然,这也恰恰说明了,感觉系统的神经连接具有很强的可塑性。
现在,对于什么是可塑性,相信你心中其实已经有了答案。可塑性指的就是大脑重新组织神经之间连接的能力,可塑性不仅让大脑能从损伤中修复,还能让大脑把资源分配给当下最重要的任务。
好,到这,我们刚刚说完了,大脑对识别人脸有一套特殊的功夫,我们的感觉系统的神经连接具有很强的可塑性。
但是再往后,作者在书中就说道,他必须很负责任地告诉我们,信息一旦进入大脑高级中枢,几乎所有脑区都在相互交流。我们能看到的就像是一团乱麻:所有脑区之间都相互连接,而且大多数连接中的功能我们现在还不太了解。说白了,从科学层面分析,人类大脑的学习能力有多强,也是科学界在不断深入研究的课题。
不过,好在,虽然我们目前对人脑的了解还不算太多,但是依据已掌握的脑科学研究成果,其实也大大促进了人工智能领域的发展,比如“神经网络”这个词最早就是由加拿大神经科学家唐纳德·赫布提出的,又过了一段时间,这个概念才被计算机科学家借用。
事实上,20世纪后期,计算机科学家们刚刚开始研究人工智能的时候,就分成了两个战队。一边支持固定规则的算法,另一边支持机器学习算法。
固定规则算法指的是,比如我们要识别一个苹果,固定规则就是要找到描述这个苹果的准确定义,然后编写程序,这样计算机就能根据固定规则识别出任何一个苹果。
而机器学习算法指的是,同样要识别苹果,人们就倾向于提供大量的各式各样的苹果图片,或者再提供一些反面案例的,比如说香蕉、梨子的图片等,让计算机自己通过学习找到规律。
你会发现,实际上,机器学习这边,才更像是我们大脑学习的过程。确实,机器学习算法的核心理念,也是通过模仿人类大脑的工作原理,建立复杂的神经网络,从而逐渐拥有人类的智能,所以它更广为人知的名字,叫“人工智能”。
那从20世纪后期发展到现在,哪一边的计算机科学家战队发展得更好呢?答案我们现在肯定都知道了,人工智能。近十几年,借助数据资源的发展,也就是样本量的剧增,和大型专用计算机强大的运算能力,利用软件来快速识别人脸,已经不再是一个艰巨的任务。人工智能的各种应用,包括语音识别、智能翻译、智能家居、智能医疗等已经出现在我们生活中的方方面面。
而人工智能领域的快速发展,也让神经科学家对研究大脑中的神经网络更感兴趣。现如今,神经生物学和计算机科学,这两个领域之间也已经展开了很多有趣的合作。这也是为什么作者会说,针对人类视觉的研究成果,也将帮助我们对当下热门的机器学习和人工智能的发展,有更加透彻的理解。
好,今天的这本《我们如何看见,又如何思考》就先说到这。总结一下,对于如何在几百毫秒,从人群中识别出熟人这个问题,我们了解了,视觉图像信息主要是经过视网膜的压缩、分解和强化传输给大脑,视网膜的功能和构造远比我们想象的要复杂精巧得多。
而后,这些视觉信号到达大脑的视觉皮质,我们发现,大脑颞叶区域,有一些特别的面部斑块对脸的参数,响应非常积极。科学家们通过观察猴子的手部斑块转化成面部斑块的实验,我们了解到,神经连接的可塑性。
最后,作为脑科学研究专家,作者在书中提到:有一个违反直觉的知识是,我们的大脑的运行速度其实很慢。大脑里的神经元和它们之间的突触的运行速度,只有现代计算机的百万分之一。然而,大脑却可以在许多感知任务上打败计算机。
大脑当中存在许多谜团,但是最重要的一点是,大脑并不是一台有着固定连接的通信机器,而是有一群由神经元交联而成的,具有可塑性的神经网络组成。这些神经网络之间的对话神秘又强大。就像哪怕是完成一个最简单的任务,把这个任务交给人工智能,它就需要许多硬件和能源支持,而与之形成鲜明对比的是,我们的大脑只需要消耗一盏小夜灯的电量就可以做更多的事情。
从这个角度来看,人工智能向人脑的学习,我们人类对自身的探索,还将任重而道远。
好,以上就是这本书的精华内容,点击音频下方的“文稿”,查收我们为你准备的全文和脑图。你还可以点击“红包分享”按钮,把这本书免费分享给你的朋友。恭喜你,又听完了一本书。
划重点
-
视网膜的功能和构造非常精巧,视觉图像信息主要是经过视网膜的压缩、分解和强化工作传输给大脑。
-
大脑对识别人脸有一套特殊的功夫,视觉皮质中的面部斑块,对脸的图像响应非常积极。
-
感觉系统的神经连接具有很强的可塑性,不仅能让大脑从损伤中修复,还能把资源分配给最重要的任务。
-
人工智能向人脑的学习,人类对自身的探索,还将任重而道远。