《人人都会说谎》 吴晨解读
《人人都会说谎》| 吴晨解读
关于作者
赛斯·斯蒂芬斯-大卫德维茨,曾经担任谷歌大数据科学家,离开谷歌之后,在《纽约时报》专门撰写大数据相关的专栏,是大数据领域的资深研究者。
关于本书
这是一本介绍大数据研究领域新发展的书。大数据分析相比传统方法,可以让我们更清楚去了解这个世界到底在怎么运作。
核心内容
利用大数据分析来了解普通人的喜好,了解真实的世界到底怎么运行,是科技推动认知发展的全新研究领域。大数据研究也正在颠覆许多人类常识的认知。随着未来可以搜集的大数据越来越多,颗粒度越来越细,大数据可以揭示的真实世界会更多。了解更真实的世界,是我们做出正确决策的第一步。
你好,欢迎每天听本书。今天为你解读的是《Everybody Lies》,直接翻译成中文就是《人人都会说谎》。这本书还没有中文版,英文原版大约12万字,我会用大约22分钟的时间,为你讲述书中的精髓:大数据研究怎样让我们了解真实的世界。
先来问个问题,一名女子在社交媒体上秀恩爱。如果她同时在谷歌上打出一个问题“我老公是不是……”,她最有可能搜的问题是什么?
一般情况下,大多数人在社交媒体上秀出的一面,都是美化过的。当他们在搜索的时候,常常会暴露自己真实的想法。所以,大多数人很容易凭直觉猜测,她搜索的很可能是:“我老公是不是出轨了?”但是这本书告诉我们,实际上,她最有可能问的问题是: “我老公是不是同性恋?”这个问题的搜索量比“我老公是不是出轨了?”的搜索量高出10%。这个结果,是不是让你吃惊不小?
在《人人都会说谎》这本书里,类似挑战我们直觉的例子比比皆是。当然这可不是一本简单的案例集,而是《经济学人》2017年七月推荐的美国最新出版的一本有关大数据的书。《经济学人》的评论说, “这本书以搜索数据为向导,快速地领略了现代人的内心世界。”
书中挑战了畅销书作家格拉德威尔在他的畅销书《眨眼之间》中提出的观点。格拉德威尔认为,依赖直觉的判断在很多情况下比深思熟虑要来的有效得多。不过,《人人都会说谎》这本书里说,大多数人都会放大自我的感受,以个体的经验来推测群体的想法,而恰恰在这种推导过程中,容易产生谬误。大众到底怎么看待不同的问题,很难简单通过自己的体验来预测。相反,大数据给了我们了解更多人真实想法的最好的机会。
这本书的作者赛斯·斯蒂芬斯-大卫德维茨曾经担任谷歌大数据科学家,他在书中引用了不少谷歌搜索和谷歌内部利用大数据进行社会学研究的例子,其中就包括他和谷歌的首席经济学家哈尔·瓦里安一起做的大量社会研究。而且,这本书还挖掘出大数据的真正价值,并告诉你如何进行大数据分析来增进我们对这个世界的理解。 离开谷歌之后,作者在《纽约时报》专门撰写大数据相关的专栏,成为这一领域的资深研究者。
大数据、人工智能和自动化,是当下最受关注的三大科技热点。利用大数据分析来了解普通人的喜好,了解真实的世界到底怎么运行,是科技推动认知发展的全新研究领域。大数据研究也正在颠覆许多人类常识的认知。随着未来可以搜集的大数据越来越多,颗粒度越来越细,大数据可以揭示的真实世界会更多。就像《经济学人》在《人人都会说谎》书评中说到的那样:大数据将为社会科学带来一场革命,就像显微镜和望远镜彻底变革了自然科学那样。
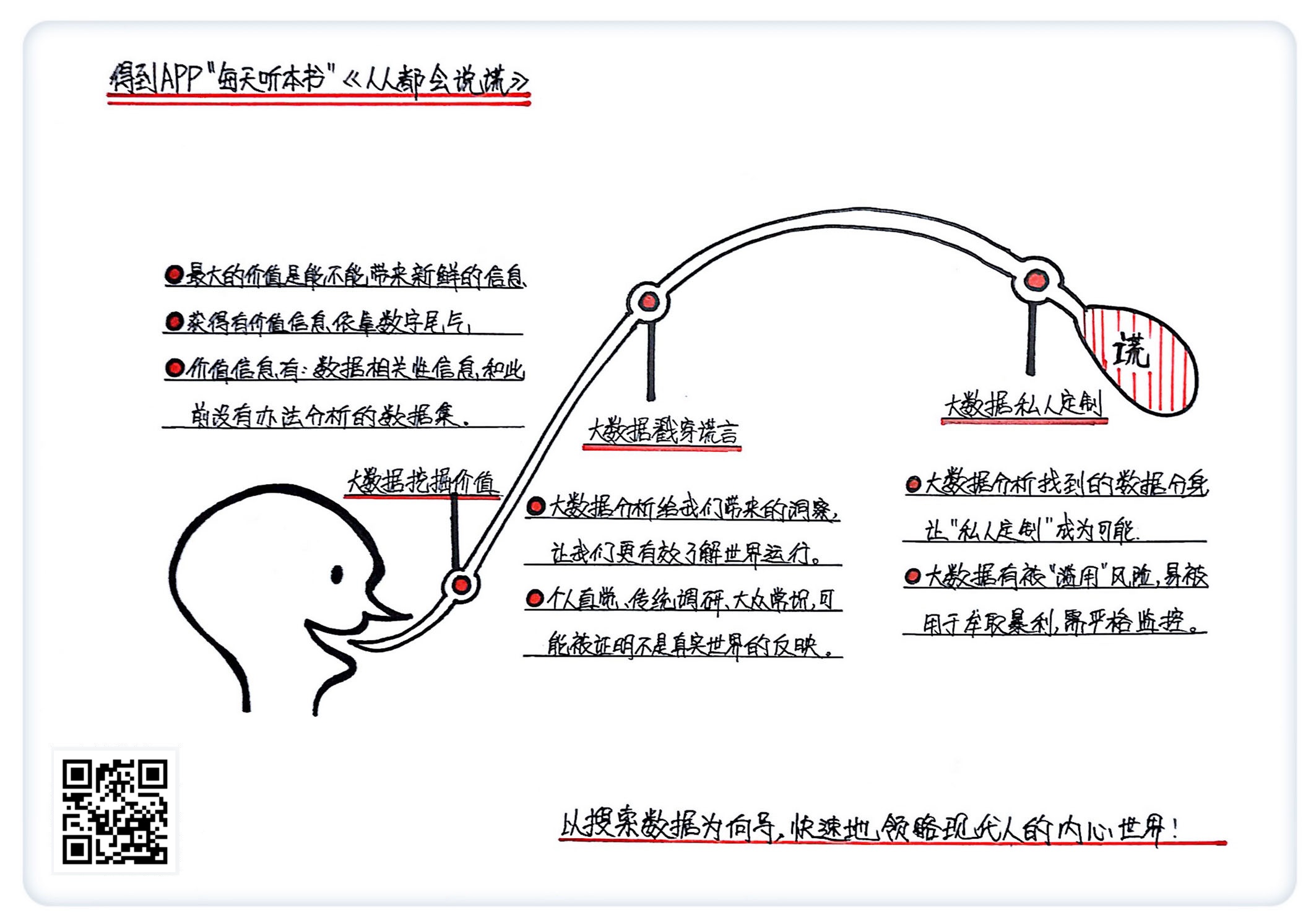
我会带着三个问题,来为你解读这本书的重点内容:第一,什么样的大数据是有价值的?第二,大数据是如何戳穿那些人人都在说的谎言的?第三,大数据分析可以让我们更好地了解每一个个体,为什么这种发展不一定是一件好事?
在一个大数据的时代,什么样的大数据是有价值的?大数据,就是能够涵盖海量信息的数据集,能够帮助我们更好了解所在的世界。我们现在所处的大数据时代已经需要用“流数据”来形容了。什么是流数据?举一个例子,现在一辆无人驾驶汽车每秒钟所产生的数据量大概有100G,你的手机标配大概也就64G吧,也就是它一秒钟产生的数据量,一台手机装不下。所以,流数据显示的是一种动态实时产生大量数据的状态。
在这样的大数据时代,我们需要改变认知。几年前,我们认知是觉得数据越多越好。现在,作者在书中强调,大数据已经不是越多就越好了,相比数量而言,挖掘新的大数据的价值更高。一种大数据有没有用,重点是它能不能提供一些新的信息,特别是此前从没有搜集到的信息。
在这么多数据里,怎么发现更多新鲜的大数据呢?可以依靠数字尾气,尾气就是汽车排放的那个尾气,这是一个形容流数据的名词。
我们现在每个人手里都有一台智能手机,我们无论在哪儿,只要拿着智能手机上网、发微信、买东西,都会留下数字的记录,这就是数字尾气。当然数字尾气不仅仅局限在人,随着越来越多的电子产品,比如说家用电器,也被接入互联网,它们也在实时产生数字记录,这些数字尾气汇流成的数据集,变得越来越重要。
我们未来将面临大数据以几何级别增长的状态,更需要从中找到新的信息。那什么是新的信息?首先是相关性的信息。作者举了和谷歌首席经济学家哈尔·瓦里安做的一个研究的例子。他们利用谷歌的一项功能“谷歌相关性”来做经济学的研究,这个工具能够找到不同数据之间的相关性。研究的问题是,用户搜索哪些信息,能预测一个市场内的房价。两人把特定地区的搜索信息与房价做了比较。研究发现,的确能够从一个地区的搜索中找到房价涨跌的线索。比如,如果更多人搜索 “八成按揭贷款”,或者 “涨幅”、 “涨价的速度”,一个市场的房价就会涨。如果更多人搜索 “快速卖房的流程” 或者 “按揭超过房价了”,那这个市场的房价还得跌。换句话说,关键词和句子的搜索与一个市场房地产宏观的表现的确有相关性。
其次,随着技术的进步,图像、视频等信息,也越来越多地被广泛使用,成为新的大数据。新的数据很可能是混乱复杂的,并不像平常人认为的是那种一目了然、简单清晰的数据。书中就举了一个根据图像大数据进行分析的例子。研究者发现,越来越多的人在照相的时候开始笑了,这是为什么呢?研究者选择的大数据是过去100年里,美国高中生毕业图册上的照片。分析这些照片就发现,随着时间的推进,越接近现在,照片上笑的人就越来越多,而且是从微笑到开口大笑,女生比男生更明显。为什么会出现这种变化?研究者发现,主要原因竟然是柯达的市场营销术。早期人们拍照时,总会很正式,正襟危坐,很严肃。当时用的老式照相机,个头比今天的电影摄像机还要大很多,摄像师要把头钻在黑布套里面,拍个照片费事得很。结果,照相变成了很重要的场合,不是随时随地就做的事情。柯达对此很担心,为了推广更多人使用的照相机器,柯达想出了新的市场推广方式,把照相和快乐捆绑在一起,鼓励更多人随手拍下身边快乐的场景。当人们不再把照相那么当回事之后,也就开始习惯对着镜头微笑,而且笑得越来越开。
上面就是这本书的第一个重点:在一个流数据,也就是随时随地产生数据的时代,大数据最大的价值是能不能带来新鲜的信息。这种新鲜的信息可能是某些数据之间的相关性,也可能是一些此前没有办法分析的数据集,比如说文本、照片和视频。
用《人人都会说谎》作为标题,作者在陈述一个事实:无论是有意还是无心,每个人都可能说谎,他们可能在调研时掩藏自己真实的想法,他们的常识可能是错误的。一句话,无论是调研的结果,还是人们的直觉,甚至是许多人相信的常识,都不一定能反映真实的世界。而大数据研究恰恰可以戳穿各式各样的谎言。
过去的认知,总以为市场调研的数据可信。但如果你用调研的方式去了解每个人的想法,每个人都可能说谎,因为人们没有动力在调研中提供真实的想法。
一个明显的例子就是,为什么美国2016年总统大选的民调那么不靠谱。在大选前一天,希拉里还领先特朗普好几个百分点,哪知道大选结果却是特朗普反超。作者就解释说:美国人不真实的回答可能导致川普的支持率少报了至少两个百分点,因为不少特朗普的支持者并不愿意在接受民调的时候说出自己真实的想法。社会学中将这种行为称作社会期望偏差,也就是人们会把自己非主流的想法藏起来,担心自己的想法跟别人不一样而遭到歧视。美国选民对待特朗普的态度就凸显了这种偏差。这些 “地下”的特朗普支持者觉得,主流民意把特朗普包装成一个大嘴巴的笨蛋,自己如果公开对他的支持,就可能会被别人嘲笑,因此选择在人前隐藏自己的想法。
类似的偏差很多。比如说一些人明明心里存在性别歧视,但是如果别人问起来,他会说自己支持男女平等。像谷歌的工程师公然在内部邮件里鼓吹男性比女性更适合当软件工程师的案例,凤毛麟角,非常少。无论是出于社会压力,还是希望表现得“政治上正确”,调研可能无法发现很多隐藏着的性别歧视者,这就是社会期望偏差在起作用。
人们撒谎的例子还很多,有些时候是善意的谎言,有些时候是情不自禁的 “自欺欺人”。有时候我们对自己撒谎,很可能自己有好高骛远的想法,或者宏大的计划,却无法抵挡住诱惑。比如我们说要读高深的书,其实更喜欢小道消息;声称自己喜欢文艺片,其实还是更愿意看火爆的商业大片。
那么,大数据如何发现人们在说谎呢?可以观察人们在互联网上的行为,就能更好反映他们的倾向。说回2016年美国总统大选,其实,仅仅对搜索信息做一个梳理,也能发现特朗普获胜的苗头。比如说在特朗普逆袭的美国中西部几个州——这几个州的选前民调数据显示,都是希拉里的基本盘,希拉里因此也没有在这里投入多少精力——但是谷歌的搜索就显示,搜 “特朗普 希拉里”的人数,多于搜 “希拉里 特朗普”的人。显然,如果你倾向于投票给谁,就可能把谁的名字放在前边。
同样,大数据分析对预测大选的投票率也比传统调研的方法要更准确。比如,传统调研调查投票率,会问选民 “你是否会投票”,这个数据不一定是准确的。但是在选举之前几周搜索 “如何投票”或者 “在哪儿投票”的人,最有可能真正在大选日去投票。一个地区这样的搜索越多,这个地区的投票率就越高。
除了在大选中预测民意,大数据分析还能挑战一些常识,推翻我们固有的认知。看到一个问题时,我们经常用直觉去判断,但是大数据告诉我们,很多直觉不靠谱。
先举一个美国 “吃瓜群众”的常识。很多美国人认为,穷人更容易入选NBA,也就是美国男子职业篮球联赛,特别是黑人的孩子,因为在NBA球员里,黑人的比例非常大。这种传统的想法认为,NBA给了穷人家的孩子一条出人头地的出路,因此穷人家的孩子会特别努力,肯吃苦,而中产家庭的孩子缺乏这样的努力与吃苦精神。
现实是这样么?对过去几十年所有NBA选手的家世背景的大数据分析显示,恰恰是中产家庭的孩子更有可能参加 NBA 选秀。因为首先, NBA 需要个子高的球员,而家境比较好的孩子更容易长高,那些吃救济、单亲家庭的孩子很可能成长阶段营养不够,不容易长高。其次, NBA 不仅需要高个子和体能,也需要团队配合能力,需要比较高的情商。而美国的穷人很可能生长在单亲家庭,缺乏情商教育,不合群。现实很残酷。“吃瓜群众”对苦孩子 “能吃苦更努力”的一厢情愿,在大数据面前不堪一击。
再举一个教育方面的例子。我们知道,有个群体叫虎妈,也就是严格管教孩子,要求孩子考名校的妈妈们。虎妈们有一种常识——高中进名校是未来进好大学、找到好工作的敲门砖。纽约就有这么一所特别著名特别难进的公立高中,能上这所高中,基本上就等于拿到了进入常春藤大学的录取通知书,也拥有了进入上层中产的入门券。
大数据的研究者就问了,到底是学校优秀让学生可以有更多机会,塑造了孩子的未来,还是在激烈竞争里脱颖而出的学生本身就很优秀?大数据给了解答这一问题的机会,因为这所高中的录取完全看分数,有人恰巧超过了分数线,就被录取了,有人却因为一两分的差距而落榜。研究者对比在分数线上下差别不大的两组人未来的发展情况,发现是否进入顶级高中对于这两组人的未来没有太大的影响,决定一个人未来最大的因素是他的才智和冲劲。这个研究结果让虎妈们大跌眼镜。
小结一下:个人的直觉,传统的调研,大众的常识,在大数据时代都可能被证明并不是真实世界的反映。大数据分析可以给我们带来的洞察,让我们能了解这个世界到底在怎么运作,比传统的方法要有效得多。
那么下面,我就来为你讲述最后一个重点:当我们有了海量数据之后,可以更精准地对特定地区和特定人群做出分析,我们甚至有机会精准地对某个特定的人进行画像。换句话说,未来可以利用大数据做到各种各样的 “私人定制”。这听起来到底是好事还是坏事?
其实自从大数据产生第一天起,对大数据被 “滥用”的风险,以及在数字时代如何保护个人的隐私,就不断被提醒。作者告诉我们,利用大数据研究来预测未来,一旦涉及到特定的个人的时候,一定要慎之又慎。
在书中就举了这样一个可能造福所有人的例子。未来医学发展中利用大数据的一个重要发展领域就是,找到一个病史记录上跟你的身体信息类似的人,或者跟你的某种身体体征类似的人,比如说血脂和血糖水平、家族心血管疾病病史,当然也包括特定的基因等等,这在大数据时代很快就会成为可能。作者把这定义为每个人的数据分身,或者说数据影子。这么做的好处很多。医生可以根据你的数据分身的病史记录,预测你未来接受治疗的反应,并可能提出更稳妥的诊疗方案,真正做到医疗的私人定制。
因为现代医药测试仍然是统计学上的数字,也就是某种药物对某种病情的治疗效果,在统计学意义上有效,对于一个比较大的群体是管用的,但是这些对不同的人并不一定有效,有时甚至有负面作用,因为每个人的其他体征千差万别,对药物的反应也会不同。这样,从病史记录上找到你的数字分身,就可以知道他的身体对特定药物和特定医疗方法的反应,医生也就可以根据这一点来推荐更适合你的诊疗方案。同样,你的数字分身在治疗过程中的各种表现以及病情发展的记录,也可以帮助医生判断你的病情发展,尝试使用更新的药物和科技手段来治疗。
从大数据分析发展的角度来看,找到每个人的数据分身会越来越容易,但是是否应该允许在各个行业都能轻易使用你的数据分身,却需要特别慎重。比如,如果允许在保险业里找到你的数据分身,也就是找到跟你的风险喜好相同的人,保险公司就能更好判断你能够承受多高的保费,因此定价更精准,宰你也就更没商量。
同样,赌场也非常想找到一个人的痛点在哪里。赌场的所谓痛点,就是到底多大损失会让一个赌徒元气大伤,从而立志戒赌。每个人的痛点都不同。赌场非常想在每个赌徒越过痛点之前打住,比如免费邀请吃大餐,或者免费升级住豪华套间,保证每个赌徒还会成为回头客。大数据分析就非常容易帮助赌场去分析你的数据分身,推断出你的痛点,让你对赌博欲罢不能。
所以,“私人定制”的大数据分析优点和问题都非常明显。但是大数据被 “滥用”的最大风险,恰恰是依赖大数据模型去判断具体个人的行为,并侵犯个人权益。可以从两点来理解这样的风险。
首先,这是一个道德问题。比如,政府是不是应该监管分析个人的 “数据尾气”的行为?企业能不能利用大数据的 “私人定制”牟利?政府可能希望用数字预测模型来预防犯罪,但是政府是不是真的可以在犯罪行为还没有发生的时候就把嫌疑犯逮捕,理由是大数据预测他会犯罪?同样,对于企业而言,大数据分析的 “私人定制”也给了他们最好的牟利机会。前边提到的保险业就是一个例子,如果能够根据不同人的风险偏好来定不同的保险价格,保险公司的收益将有大幅提升。同样,不同人对同一种商品,能接受的价格也不一样,如果可以根据这个来定价的话,商家也可以利润最大化。但这么做,都直接侵犯到了每个人的隐私。现在已经有专家提出,个人数据也是产权。大数据分析一旦侵害了私人产权,就成了大问题。
其次,这也是一个统计学的问题。大数据分析可以让研究者测试许多变量。但是当你测试特别多的变量的时候,很有可能某个特定变量在统计学意义上有效,这并不意味着这一变量真的能预测未来的结果。举一个例子,有大数据调查研究,人们喜欢什么与人的智商相关。研究就发现,喜欢哈雷摩托车的人,与低智商有关联性。如果有人据此就确定,某个喜欢哈雷摩托的人就智商低,就会出大问题。同样,你的数据分身无论跟你多像,也不是你。如果基于对你的数据分身的分析,就去推论你的其他一些特质,肯定会出问题。
总结一下,大数据让 “私人定制”成为可能,这会带来巨大的福利,但是也暴露出极大的风险。未来无论消费还是医疗,大数据分析都能提供根据个人特点的定制化服务,不过这种大数据分析需要有严格的监管,不然非常容易被用于牟取暴利。
说到这儿,《人人都会说谎》的重点内容就为你介绍的差不多了,下面来为你简单回顾一下。
第一,我们进入了一个数字时代,无论是手持智能移动设备的个人还是联网的机器,每时每刻都在创造海量的数字尾气,这让我们有可能发掘出更多新鲜的大数据。很多新的大数据是我们之前没有办法去研究的,比如说文本、图片或者视频,这些数据跟表格信息非常不同。大数据给了我们认识普罗大众真实想法的机会,随着移动互联与物联网的发展,每个人的行动都可以被捕捉,这种行动的数据比起一般人回答调研题目给出的答案要真实得多。带着问题去利用大数据解答,常常会得出一些反常识的答案,大数据分析可以更好地帮助你洞察这个世界到底怎么运作。
第二,大数据研究能告诉你一个更真实的世界,这是我们做出正确决策的第一步。如果希拉里团队能够更早认识到美国中部地区对大选相关问题搜索的研究,就可能加强在这些地区的竞选投入,不会意外落选。同样,如果虎妈们意识到,高中上不上名校,并不能决定孩子的未来,她们就会对孩子的成长更淡然一些。
第三,当然,大数据研究最吸引人也最具风险的一点是,很快它就能为每个人创造出他的数据分身,从大数据集里找到跟他的特征、偏好、习惯相同的人。这样大数据的 “私人定制”能够带来开创性的研究,比如在医疗领域的 “定制化”治疗,但也可能严重侵犯隐私并成为无良企业的摇钱树,比如保险公司在按照你的风险偏好来定价。科技是中性的,最终结果取决于为谁所用,或者怎么去用。
作者说自己在大学毕业时读了《魔鬼经济学》,发现运用好奇心、创造力和数据就能极大提升我们对这个世界的认知,就立志要从数据的海洋中找出现实世界到底如何运作的真相。我也很希望你读了斯蒂芬斯-大卫德维茨的这本书,也能够开始用好奇心去打量我们所处的世界,依靠大数据来挖掘更多真相。
书中两个挑战常识的大数据研究例子就发人深省,因为类似的常识在中国更多,你可以去思考,比如因为一分之差没有考入北大的同学,和那些幸运过线的同学,十年之后到底会有多大的差距?还是他们未来前途的差距可以忽略不计?或者用大数据来分析一下,“穷人的孩子早当家”这句话,在当下的中国,还是否成立?
同样,我们在赞叹科技的进步的同时,也需要了解科技的两面性。大数据研究本身是中性的,但是怎么去使用,尤其涉及到预测个人行为的时候,一定要慎重。不然,我们很容易会陷入到一个“透明人”的危险境地。想象一下,如果每个人的一举一动都可以被预测,那会是什么样的世界?
撰稿:吴晨 脑图:摩西 转述:孙潇